Recognition: 1 theorem link
· Lean TheoremSlimSpec: Low-Rank Draft LM-Head for Accelerated Speculative Decoding
Pith reviewed 2026-05-12 04:15 UTC · model grok-4.3
The pith
Low-rank compression of the drafter's LM-head delivers 4-5× speedup in speculative decoding while preserving full vocabulary support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
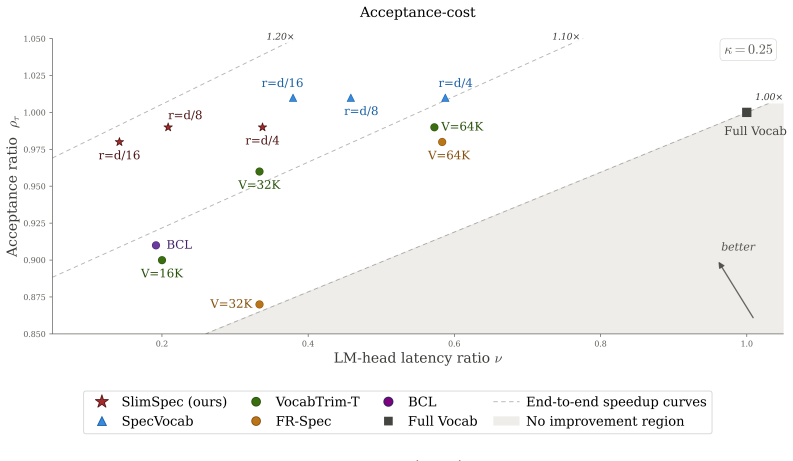
SlimSpec replaces the standard dense LM-head in the drafter with a low-rank version that still supports the full vocabulary. When evaluated with EAGLE-3 drafter on three target models across diverse benchmarks, it achieves 4-5× acceleration in both latency- and throughput-bound regimes while maintaining competitive acceptance lengths, resulting in up to 8-9% better end-to-end speedup than existing methods.
What carries the argument
Low-rank parameterization of the drafter's LM-head that compresses the inner representation to reduce computation while outputting to the full vocabulary.
Load-bearing premise
The low-rank structure sufficiently captures the necessary information for high-quality token proposals without degrading acceptance rates in speculative verification.
What would settle it
Running the method on a new model or benchmark and observing that the net speedup falls below that of vocabulary-truncation baselines due to lower acceptance lengths.
Figures


read the original abstract
Speculative decoding speeds up autoregressive generation in Large Language Models (LLMs) through a two-step procedure, where a lightweight draft model proposes tokens which the target model then verifies in a single forward pass. Although the drafter network is small in modern architectures, its LM-head still performs projection to a large vocabulary, becoming one of the major computational bottlenecks. In prior work this issue has been predominantly addressed via static or dynamic vocabulary truncation. Yet mitigating the bottleneck, these methods bring in extra complexity, such as special vocabulary curation, sophisticated inference-time logic or modifications of the training setup. In this paper, we propose SlimSpec, a low-rank parameterization of the drafter's LM-head that compresses the inner representation rather than the output, preserving full vocabulary support. We evaluate our method with EAGLE-3 drafter across three target models and diverse benchmarks in both latency- and throughput-bound inference regimes. SlimSpec achieves $4\text{-}5\times$ acceleration over the standard LM-head architecture while maintaining a competitive acceptance length, surpassing existing methods by up to $8\text{-}9\%$ of the end-to-end speedup. Our method requires minimal adjustments of training and inference pipelines. Combined with the aforementioned speedup improvements, it makes SlimSpec a strong alternative across wide variety of draft LM-head architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SlimSpec, a low-rank parameterization of the LM-head in draft models for speculative decoding. Instead of truncating the vocabulary, it compresses the inner hidden-state representation before the final projection while retaining a full-vocabulary output matrix. Evaluated with an EAGLE-3 drafter on three target LLMs across latency- and throughput-bound regimes, the method is reported to deliver 4-5× acceleration of the LM-head computation, preserve competitive acceptance lengths, and yield up to 8-9 % higher end-to-end speedup than prior vocabulary-truncation baselines, with only minimal changes to training and inference pipelines.
Significance. If the empirical preservation of acceptance length holds, SlimSpec supplies a structurally simple, training-light alternative to vocabulary curation or dynamic truncation for removing the LM-head bottleneck in speculative decoding. The approach is broadly applicable to existing drafter architectures and could become a default optimization once the quality-speed trade-off is quantified.
major comments (2)
- [Experiments] Experiments section: the central claim that acceptance length remains competitive (and thereby produces net 4-5× LM-head plus 8-9 % end-to-end gains) rests on quantitative comparison of acceptance lengths. The manuscript must include a table or figure that directly reports mean acceptance length (with standard deviation or error bars) for SlimSpec versus the unmodified full-rank EAGLE-3 head and versus the strongest vocabulary-truncation baseline on identical target models and benchmarks; without these numbers the speedup arithmetic cannot be verified.
- [Method] Method section, low-rank factorization: the paper introduces a free parameter (the inner rank dimension) whose value directly trades off compression against logit fidelity. An ablation showing acceptance length and wall-clock speedup as a function of this rank (e.g., rank = 128, 256, 512) on at least one target model is required to demonstrate that the chosen operating point is robust rather than tuned to a single benchmark.
minor comments (2)
- [Abstract] Abstract and §1: replace the range “4-5×” and “8-9 %” with the exact measured values and the precise models/benchmarks on which they were obtained.
- [Experiments] All latency and throughput figures should state the hardware platform, batch size, and whether KV-cache is enabled, to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of SlimSpec as a simple alternative to vocabulary truncation. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that acceptance length remains competitive (and thereby produces net 4-5× LM-head plus 8-9 % end-to-end gains) rests on quantitative comparison of acceptance lengths. The manuscript must include a table or figure that directly reports mean acceptance length (with standard deviation or error bars) for SlimSpec versus the unmodified full-rank EAGLE-3 head and versus the strongest vocabulary-truncation baseline on identical target models and benchmarks; without these numbers the speedup arithmetic cannot be verified.
Authors: We agree that explicit reporting of mean acceptance lengths with measures of variability is necessary to allow readers to verify the speedup calculations and the claim of competitive performance. The current manuscript states that acceptance lengths are competitive and reports the resulting end-to-end gains, but does not provide the requested side-by-side table with standard deviations. In the revised version we will add a table (or figure with error bars) in the Experiments section that directly compares mean acceptance length ± standard deviation for SlimSpec, the unmodified full-rank EAGLE-3 head, and the strongest vocabulary-truncation baseline, using the same target models and benchmarks. revision: yes
-
Referee: [Method] Method section, low-rank factorization: the paper introduces a free parameter (the inner rank dimension) whose value directly trades off compression against logit fidelity. An ablation showing acceptance length and wall-clock speedup as a function of this rank (e.g., rank = 128, 256, 512) on at least one target model is required to demonstrate that the chosen operating point is robust rather than tuned to a single benchmark.
Authors: We concur that an ablation over the rank hyper-parameter is important to demonstrate robustness rather than benchmark-specific tuning. The manuscript selects a single operating rank but does not present the requested sensitivity analysis. In the revised manuscript we will add an ablation study (in the Method or Experiments section) that reports acceptance length and wall-clock speedup for ranks 128, 256, and 512 on at least one target model, thereby illustrating the compression–fidelity trade-off and justifying the chosen value. revision: yes
Circularity Check
No circularity: architectural change evaluated on external benchmarks
full rationale
The paper proposes SlimSpec as a low-rank factorization of the drafter LM-head that compresses the hidden-state input to the final projection while retaining a full-vocabulary output matrix. This is presented as a direct structural modification requiring only minimal training/inference changes. No equations derive a 'prediction' that reduces to a fitted parameter by construction, no self-citation chain supplies the uniqueness or correctness of the low-rank form, and no ansatz is smuggled in. Speedup and acceptance-length results are obtained from direct latency/throughput measurements on three target models and standard benchmarks, furnishing an independent empirical check rather than a self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- low-rank dimension
axioms (1)
- domain assumption Low-rank factorization of the LM-head projection can approximate token logits sufficiently well for speculative decoding acceptance rates.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearSlimSpec replaces it with the low-rank factorization z = W_up W_down h ... cost reduces from O(V d) to O(r d + V r)
Reference graph
Works this paper leans on
-
[1]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding.arXiv preprint arXiv:2211.17192, 2023. doi: 10.48550/arXiv.2211.17192. URLhttps://arxiv.org/abs/2211.17192
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023. doi: 10.48550/arXiv.2302.01318. URL https: //arxiv.org/abs/2302.01318
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01318 2023
-
[3]
Rest: Retrieval-based speculative decoding
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason Lee, and Di He. Rest: Retrieval-based speculative decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1582–1595, 2024
work page 2024
-
[4]
Break the sequential dependency of llm inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, pages 14060–14079, 2024
work page 2024
-
[5]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, J. D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024. doi: 10.48550/arXiv.2401.10774. URL https: //arxiv.org/abs/2401.10774
work page internal anchor Pith review doi:10.48550/arxiv.2401.10774 2024
-
[6]
Hydra: Sequentially-dependent draft heads for medusa decoding.arXiv preprint arXiv:2402.05109, 2024
Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan-Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding.arXiv preprint arXiv:2402.05109, 2024. doi: 10.48550/arXiv.2402.05109. URL https://arxiv.org/abs/2402.05109
-
[7]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024. doi: 10.48550/ arXiv.2401.15077. URLhttps://arxiv.org/abs/2401.15077
-
[8]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-2: Faster inference of language models with dynamic draft trees.arXiv preprint arXiv:2406.16858, 2024. doi: 10.48550/arXiv.2406.16858. URLhttps://arxiv.org/abs/2406.16858
-
[9]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840,
-
[10]
doi: 10.48550/arXiv.2503.01840. URLhttps://arxiv.org/abs/2503.01840
-
[11]
Weilin Zhao, Tengyu Pan, Xu Han, Yudi Zhang, Ao Sun, Yuxiang Huang, Kaihuo Zhang, Weilun Zhao, Yuxuan Li, Jianyong Wang, Zhiyuan Liu, and Maosong Sun. Fr-spec: Accelerating large-vocabulary language models via frequency-ranked speculative sampling.arXiv preprint arXiv:2502.14856, 2025. doi: 10.48550/arXiv.2502.14856. URL https://arxiv.org/abs/ 2502.14856
-
[12]
Kwon, Rui Li, Alexandros Kouris, and Stylianos I
Miles Williams, Young D. Kwon, Rui Li, Alexandros Kouris, and Stylianos I. Venieris. Spec- ulative decoding with a speculative vocabulary.arXiv preprint arXiv:2602.13836, 2026. doi: 10.48550/arXiv.2602.13836. URLhttps://arxiv.org/abs/2602.13836
-
[13]
Raghavv Goel, Sudhanshu Agrawal, Mukul Gagrani, Junyoung Park, Yifan Zao, He Zhang, Tian Liu, Yiping Yang, Xin Yuan, Jiuyan Lu, Chris Lott, and Mingu Lee. V ocabtrim: V ocabulary pruning for efficient speculative decoding in llms.arXiv preprint arXiv:2506.22694, 2025. doi: 10.48550/arXiv.2506.22694. URLhttps://arxiv.org/abs/2506.22694
-
[14]
Ofir Ben Shoham. Balancing coverage and draft latency in vocabulary trimming for faster speculative decoding.arXiv preprint arXiv:2603.05210, 2026. doi: 10.48550/arXiv.2603.05210. URLhttps://arxiv.org/abs/2603.05210
-
[15]
Yepeng Weng, Dianwen Mei, Huishi Qiu, Xujie Chen, Li Liu, Jiang Tian, and Zhongchao Shi. Coral: Learning consistent representations across multi-step training with lighter speculative drafter.arXiv preprint arXiv:2502.16880, 2025. doi: 10.48550/arXiv.2502.16880. URL https://arxiv.org/abs/2502.16880. 10
-
[16]
Jinbin Zhang, Nasib Ullah, Erik Schultheis, and Rohit Babbar. Dynaspec: Context- aware dynamic speculative sampling for large-vocabulary language models.arXiv preprint arXiv:2510.13847, 2025. doi: 10.48550/arXiv.2510.13847. URL https://arxiv.org/abs/ 2510.13847
-
[17]
Lk losses: Direct acceptance rate optimization for speculative decoding
Alexander Samarin, Sergei Krutikov, Anton Shevtsov, Sergei Skvortsov, Filipp Fisin, and Alexander Golubev. Lk losses: Direct acceptance rate optimization for speculative decoding. arXiv preprint arXiv:2602.23881, 2026. doi: 10.48550/arXiv.2602.23881. URL https: //arxiv.org/abs/2602.23881
-
[18]
Out-of- vocabulary sampling boosts speculative decoding.arXiv preprint arXiv:2506.03206, 2025
Nadav Timor, Jonathan Mamou, Oren Pereg, Hongyang Zhang, and David Harel. Out-of- vocabulary sampling boosts speculative decoding.arXiv preprint arXiv:2506.03206, 2025. doi: 10.48550/arXiv.2506.03206. URLhttps://arxiv.org/abs/2506.03206
-
[19]
Efficient softmax approximation for GPUs
Edouard Grave, Armand Joulin, Moustapha Cissé, David Grangier, and Hervé Jégou. Efficient softmax approximation for GPUs. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1302–1310, 2017
work page 2017
-
[20]
Chen, Si Si, Yang Li, Ciprian Chelba, and Cho-Jui Hsieh
Patrick H. Chen, Si Si, Yang Li, Ciprian Chelba, and Cho-Jui Hsieh. GroupReduce: Block- wise low-rank approximation for neural language model shrinking. InAdvances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
work page 2018
-
[21]
Adaptive input representations for neural language modeling
Alexei Baevski and Michael Auli. Adaptive input representations for neural language modeling. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[22]
Vasileios Lioutas, Ahmad Rashid, Krtin Kumar, Md Akmal Haidar, and Mehdi Rezagholizadeh. Improving word embedding factorization for compression using distilled nonlinear neural decomposition.arXiv preprint arXiv:1910.06720, 2019. doi: 10.48550/arXiv.1910.06720. URL https://arxiv.org/abs/1910.06720
-
[23]
Oleksii Hrinchuk, Valentin Khrulkov, Leyla Mirvakhabova, Elena Orlova, and Ivan Oseledets. Tensorized embedding layers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4847–4860, 2020
work page 2020
-
[24]
ALBERT: A lite BERT for self-supervised learning of language representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[25]
Deep learning meets projective clustering
Alaa Maalouf, Harry Lang, Daniela Rus, and Dan Feldman. Deep learning meets projective clustering. InInternational Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/forum?id=EQfpYwF3-b
work page 2021
-
[26]
Slimpajama: A 627b token cleaned and deduplicated version of redpajama.Cerebras Systems, 2023
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob Robert Steeves, Joel Hest- ness, and Nolan Dey. Slimpajama: A 627b token cleaned and deduplicated version of redpajama.Cerebras Systems, 2023. URL https://www.cerebras.ai/blog/ slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama
work page 2023
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. doi: 10.48550/arXiv. 2407.21783. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[28]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. doi: 10.48550/arXiv.2508.10925. URL https://arxiv.org/ abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[29]
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. doi: 10.48550/ arXiv.2505.09388. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jijie Li, Li Du, Hanyu Zhao, Bo-wen Zhang, Liangdong Wang, Boyan Gao, Guang Liu, and Yonghua Lin. Infinity instruct: Scaling instruction selection and synthesis to enhance language models.arXiv preprint arXiv:2506.11116, 2025. doi: 10.48550/arXiv.2506.11116. URL https://arxiv.org/abs/2506.11116. 11
-
[31]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena.arXiv preprint arXiv:2306.05685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
doi: 10.48550/arXiv.2306.05685. URLhttps://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685
-
[33]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Evaluating Large Language Models Trained on Code
doi: 10.48550/arXiv.2107.03374. URLhttps://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[35]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Training Verifiers to Solve Math Word Problems
doi: 10.48550/arXiv.2110.14168. URLhttps://arxiv.org/abs/2110.14168. 12 A Training Configurations All draft models are trained for 10 epochs with batch size 64 and learning rate 4×10 −4. We use AdamW with (β1, β2) = (0.9,0.95) , ϵ= 10 −8, and no weight decay. The learning rate is scheduled with a cosine decay after100warmup steps, and gradients are clippe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.