Recognition: no theorem link
Privacy-preserving Chunk Scheduling in a BitTorrent Implementation of Federated Learning
Pith reviewed 2026-05-12 05:13 UTC · model grok-4.3
The pith
FLTorrent uses a BitTorrent warm-up phase to drive source attribution in decentralized federated learning close to neighborhood random guessing while preserving aggregation semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
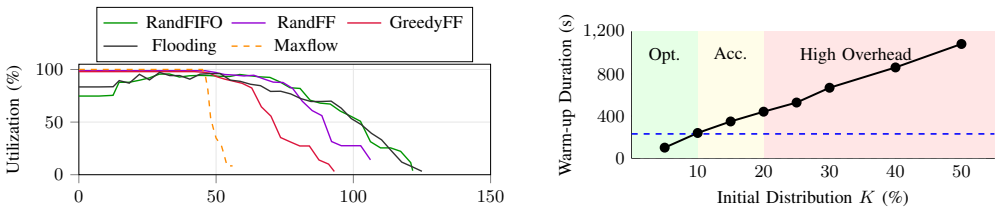
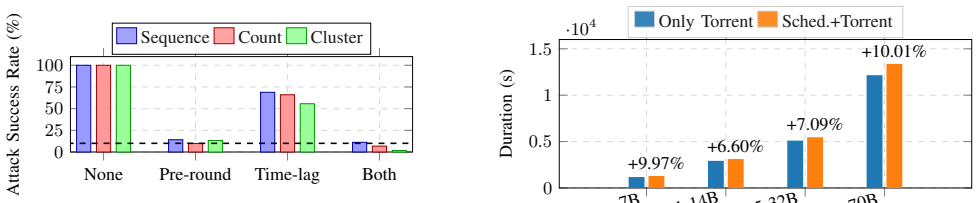
FLTorrent achieves within-round source unlinkability in serverless federated learning by inserting a warm-up phase of pre-round obfuscation, randomized lags, and coordination-only non-owner-first scheduling before standard BitTorrent swarming. It upper-bounds the per-transfer attribution posterior by the fraction of owner chunks inside a sender's eligible cover set and derives a stricter high-probability bound that improves with early non-owner mass. A GreedyFastestFirst heuristic reaches approximately 92% of the bandwidth-optimal max-flow upper bound, the warm-up occupies a stable 12% of each round for 100-500 peers, and under an observation-only local adversary attribution success falls to
What carries the argument
The warm-up phase using coordination-only non-owner-first scheduling together with the per-transfer attribution posterior bound expressed as the owner-chunk fraction in the sender's eligible cover set.
Load-bearing premise
The warm-up phase preserves FedAvg-style aggregation semantics over updates that remain reconstructable by the round deadline and the stated bounds hold only against observation-only local adversaries.
What would settle it
An experiment in which local observers attribute chunk sources with success probability significantly above the neighborhood random-guessing baseline for typical nodes would disprove the unlinkability claim.
Figures





read the original abstract
Traditional federated learning (FL) relies on a central aggregator server, which can create performance bottlenecks and privacy risks. Decentralized mix-and-forward designs remove the server, but repeated local mixing can attenuate global information under heterogeneity and exposes peer-to-peer neighborhoods as a privacy attack surface. To preserve FedAvg-style aggregation semantics (over updates reconstructable by the round deadline) while scaling dissemination, we present FLTorrent, a BitTorrent-based dissemination layer for serverless FL with a short warm-up. Warm-up hardens within-round source unlinkability -- a dissemination-layer goal orthogonal to content protections (e.g., DP or secure aggregation) -- via (i) pre-round obfuscation, (ii) randomized lags, and (iii) coordination-only non-owner-first scheduling (tracker off the data path), before switching to vanilla BitTorrent swarming. We upper-bound the per-transfer attribution posterior by the fraction of owner chunks in a sender's eligible cover set, and derive a tighter high-probability bound that improves with early non-owner mass. A simple heuristic, GreedyFastestFirst, attains approximately 92% of a bandwidth-optimal max-flow upper bound, while warm-up remains a stable approximately 12% share of a round across 100--500 peers. Under an observation-only local adversary, FLTorrent drives attribution success close to neighborhood-level random guessing for typical nodes, improves with network size, and remains robust under collusion. In LLM-scale stress tests (Gemma-7B, DeepSeek-R1-14B, Qwen2.5-32B, and Llama-3.3-70B) over 7--10 Gbps access links, FLTorrent adds only approximately 6--10% end-to-end overhead relative to BitTorrent-only. Overall, FLTorrent shows that within-round unlinkability and BitTorrent-level efficiency can co-exist with predictable, low overheads at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FLTorrent, a BitTorrent-based dissemination layer for serverless federated learning. It incorporates a short warm-up phase using pre-round obfuscation, randomized lags, and coordination-only non-owner-first scheduling (with the tracker off the data path) before reverting to standard swarming, in order to harden within-round source unlinkability while preserving FedAvg-style aggregation semantics over updates reconstructable by the round deadline. The paper states an upper bound on the per-transfer attribution posterior equal to the fraction of owner chunks in a sender's eligible cover set, derives a tighter high-probability bound that improves with early non-owner mass, shows that the GreedyFastestFirst heuristic attains approximately 92% of a bandwidth-optimal max-flow upper bound, reports that the warm-up occupies a stable ~12% share of each round for 100-500 peers, and demonstrates that attribution success approaches neighborhood-level random guessing (improving with network size and remaining robust to collusion) under an observation-only local adversary. LLM-scale experiments with Gemma-7B, DeepSeek-R1-14B, Qwen2.5-32B, and Llama-3.3-70B over 7-10 Gbps links report 6-10% end-to-end overhead relative to BitTorrent-only.
Significance. If the stated bounds hold under the observation-only adversary model and the warm-up phase preserves convergence, the work shows that within-round unlinkability can be achieved at BitTorrent-level efficiency with predictable low overheads at scale. The concrete, reproducible efficiency figures (92% of max-flow, ~12% warm-up share, 6-10% overhead) together with the LLM-scale stress tests constitute a clear empirical strength.
major comments (1)
- [Theoretical analysis of attribution bounds] The central theoretical claim upper-bounds the per-transfer attribution posterior by the fraction of owner chunks in the sender's eligible cover set and derives a tighter high-probability improvement with early non-owner mass. However, the manuscript provides only a high-level statement of these bounds as direct consequences of the scheduling rules without the intermediate steps or assumptions required for independent verification of the high-probability tightening.
minor comments (1)
- [Experimental evaluation] The experimental section reports concrete overhead numbers for the LLM-scale tests but does not include the precise network topology, chunk-size distribution, or reconstruction-deadline enforcement details needed for full reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly to improve clarity and verifiability.
read point-by-point responses
-
Referee: The central theoretical claim upper-bounds the per-transfer attribution posterior by the fraction of owner chunks in a sender's eligible cover set and derives a tighter high-probability bound that improves with early non-owner mass. However, the manuscript provides only a high-level statement of these bounds as direct consequences of the scheduling rules without the intermediate steps or assumptions required for independent verification of the high-probability tightening.
Authors: We agree that the manuscript would benefit from expanded detail on the derivation to support independent verification. In the revised version we will add a dedicated subsection (or appendix) with the full steps. The upper bound follows directly from the warm-up scheduling rule: each sender maintains an eligible cover set consisting of its own chunks plus non-owner chunks received to date; the scheduler (coordination-only, non-owner-first) selects exclusively from this set, so the posterior that any given transferred chunk originates from the sender's local data is at most the owner fraction in the set. For the high-probability tightening we will explicitly state the assumptions (observation-only local adversary, independence of chunk arrivals induced by randomized lags and pre-round obfuscation) and insert the intermediate concentration argument: the expected non-owner mass grows exponentially under the lag distribution, after which a standard Chernoff or Azuma-Hoeffding bound shows that the owner fraction falls below any fixed epsilon with probability 1-delta after O(log(1/eps)) transfers. These additions will be placed without altering the stated claims or results. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives its attribution bounds directly from the stated warm-up scheduling rules, cover-set fractions, and observation-only adversary model without reducing them to fitted parameters or self-referential inputs. The per-transfer posterior upper bound is explicitly a function of owner-chunk fraction in the eligible cover set, the tighter high-probability bound follows from early non-owner mass, and the GreedyFastestFirst heuristic performance (92% of max-flow) plus warm-up share (~12%) and attribution rates are presented as consequences of the BitTorrent modifications and experimental measurements rather than by-construction renamings or self-citation chains. No load-bearing ansatz, uniqueness theorem, or self-definition appears in the central claims, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption FedAvg-style aggregation semantics can be preserved when updates are reconstructable by the round deadline
- domain assumption An observation-only local adversary is the relevant threat model for attribution attacks
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inAISTATS, 2017
work page 2017
-
[2]
Incentive mechanism design for unbiased federated learning with randomized client participation,
B. Luo, Y . Feng, S. Wang, J. Huang, and L. Tassiulas, “Incentive mechanism design for unbiased federated learning with randomized client participation,” inICDCS, 2023
work page 2023
-
[3]
Embedding communication for federated graph neural networks with privacy guarantees,
X. Wu, Z. Ji, and C.-L. Wang, “Embedding communication for federated graph neural networks with privacy guarantees,” inICDCS, 2023
work page 2023
-
[4]
Fedlth: A privacy-preserving federated learning framework with model pruning on edge clients,
H. Zhang, Y . Xie, S. Hu, M. He, P. He, J. Zheng, and D. Feng, “Fedlth: A privacy-preserving federated learning framework with model pruning on edge clients,” inICDCS, 2025
work page 2025
-
[5]
Accelerating and securing federated learning with stateless in-network aggregation at the edge,
J. Xia, W. Wu, L. Luo, G. Cheng, D. Guo, and Q. Nian, “Accelerating and securing federated learning with stateless in-network aggregation at the edge,” inICDCS, 2024
work page 2024
-
[6]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” inIEEE S&P, 2017
work page 2017
-
[7]
L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,”NeurIPS, 2019
work page 2019
-
[8]
Inverting gradients-how easy is it to break privacy in federated learning?,
J. Geiping, H. Bauermeister, H. Dr ¨oge, and M. Moeller, “Inverting gradients-how easy is it to break privacy in federated learning?,” NeurIPS, 2020
work page 2020
-
[9]
Cutting through privacy: A hyperplane-based data reconstruction attack in federated learning,
F. Diana, A. Nusser, C. Xu, and G. Neglia, “Cutting through privacy: A hyperplane-based data reconstruction attack in federated learning,”
-
[10]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inACM CCS, 2017
work page 2017
-
[11]
Eluding secure aggregation in federated learning via model inconsistency,
D. Pasquini, D. Francati, and G. Ateniese, “Eluding secure aggregation in federated learning via model inconsistency,” inACM CCS, 2022
work page 2022
-
[12]
Secure aggregation is not private against membership inference attacks,
K.-H. Ngo, J. ¨Ostman, G. Durisi, and A. Graell i Amat, “Secure aggregation is not private against membership inference attacks,” 2024. arXiv:2403.17775
-
[13]
Stochastic gradient push for distributed deep learning,
M. Assran, N. Loizou, N. Ballas, and M. Rabbat, “Stochastic gradient push for distributed deep learning,” inICML, 2019
work page 2019
-
[14]
A unified theory of decentralized sgd with changing topology and local updates,
A. Koloskova, N. Loizou, S. Boreiri, M. Jaggi, and S. Stich, “A unified theory of decentralized sgd with changing topology and local updates,” inICML, 2020
work page 2020
-
[15]
Decentralized federated learning: A survey and perspective,
L. Yuan, Z. Wang, L. Sun, P. S. Yu, and C. G. Brinton, “Decentralized federated learning: A survey and perspective,”IEEE Internet Things J., vol. 11, no. 21, 2024
work page 2024
-
[16]
On the (in)security of peer- to-peer decentralized machine learning,
D. Pasquini, M. Raynal, and C. Troncoso, “On the (in)security of peer- to-peer decentralized machine learning,” inIEEE S&P, 2023
work page 2023
-
[17]
Incentives build robustness in bittorrent,
B. Cohen, “Incentives build robustness in bittorrent,” inWorkshop on Economics of P2P Systems, 2003
work page 2003
-
[18]
Deep diving into bittorrent locality,
R. Cuevas, N. Laoutaris, X. Yang, G. Siganos, and P. Rodriguez, “Deep diving into bittorrent locality,”ACM SIGMETRICS Perform. Eval. Rev., vol. 38, no. 1, 2010
work page 2010
-
[19]
Source inference attacks in federated learning,
H. Hu, Z. Salcic, L. Sun, G. Dobbie, and X. Zhang, “Source inference attacks in federated learning,” inICDM, 2021
work page 2021
-
[20]
Where does this data come from? enhanced source inference attacks in federated learning,
H. Chen, X. Xu, X. Zhu, X. Zhou, F. Dai, Y . Gao, X. Chen, S. Wang, and H. Hu, “Where does this data come from? enhanced source inference attacks in federated learning,” inIJCAI, 2025
work page 2025
-
[21]
Quality inference in federated learning with secure aggregation,
B. Pej ´o and G. Bicz ´ok, “Quality inference in federated learning with secure aggregation,”IEEE Trans. Big Data, vol. 9, no. 5, 2023
work page 2023
-
[22]
Bep 0003: The bittorrent protocol specification
BitTorrent Enhancement Proposals, “Bep 0003: The bittorrent protocol specification.” https://www.bittorrent.org/beps/bep 0003.html, 2003
work page 2003
-
[23]
Np-complete scheduling problems,
J. D. Ullman, “Np-complete scheduling problems,”J. Comput. Syst. Sci., vol. 10, no. 3, 1975
work page 1975
-
[24]
M. R. Garey and D. S. Johnson,Computers and Intractability: A Guide to the Theory of NP-Completeness. W.H. Freeman, 1979
work page 1979
-
[25]
If-cnn: Image-aware inference framework for cnn with the collaboration of mobile devices and cloud,
G. Shu, W. Liu, X. Zheng, and J. Li, “If-cnn: Image-aware inference framework for cnn with the collaboration of mobile devices and cloud,” IEEE Access, vol. 6, 2018
work page 2018
-
[26]
“Oecd.” https://www.oecd.org, 2024
work page 2024
-
[27]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,”NeurIPS, 2017
work page 2017
-
[28]
Decentralized stochastic opti- mization and gossip algorithms with compressed communication,
A. Koloskova, S. Stich, and M. Jaggi, “Decentralized stochastic opti- mization and gossip algorithms with compressed communication,” in ICML, 2019
work page 2019
-
[29]
“Gemma open models.” https://blog.google/technology/developers/ gemma-open-models/, 2024
work page 2024
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang,et al., “Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning,”arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Qwen Team, “Qwen2 technical report,”arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
A. Dubey, A. Jauhri, A. Pandey,et al., “The llama 3 herd of models,” arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Relaysum for decentralized deep learning on heterogeneous data,
T. V ogels, L. He, A. Koloskova, S. P. Karimireddy, T. Lin, S. U. Stich, and M. Jaggi, “Relaysum for decentralized deep learning on heterogeneous data,” inNeurIPS, 2021
work page 2021
-
[34]
Exponential graph is provably efficient for decentralized deep training,
B. Ying, K. Yuan, Y . Chen, H. Hu, P. Pan, and W. Yin, “Exponential graph is provably efficient for decentralized deep training,”NeurIPS, 2021
work page 2021
-
[35]
Get more for less in decentralized learning systems,
A. Dhasade, A.-M. Kermarrec, R. Pires, R. Sharma, M. Vujasinovic, and J. Wigger, “Get more for less in decentralized learning systems,” in ICDCS, 2023
work page 2023
-
[36]
C. Chen, M. Li, and C. Yang, “bbtopk: Bandwidth-aware sparse allre- duce with blocked sparsification for efficient distributed training,” in ICDCS, 2023
work page 2023
-
[37]
Bittorrent-based gossip learning,
O. Carl and T. Weis, “Bittorrent-based gossip learning,” inACM IoT, 2024
work page 2024
-
[38]
S. Le Blond, A. Legout, F. Lefessant, W. Dabbous, and M. A. Kaafar, “Spying the world from your laptop: identifying and profiling content providers and big downloaders in bittorrent,” inUSENIX LEET, 2010
work page 2010
-
[39]
Anofel: Supporting anonymity for privacy-preserving federated learning,
G. Almashaqbeh and Z. Ghodsi, “Anofel: Supporting anonymity for privacy-preserving federated learning,”PoPETs, 2025
work page 2025
-
[40]
Anonymous federated learning via named-data networking,
A. Agiollo, E. Bardhi, M. Conti, N. Dal Fabbro, and R. Lazzeretti, “Anonymous federated learning via named-data networking,”Future Gener. Comput. Syst., vol. 152, 2024. APPENDIXA NP-COMPLETENESS OF THECHUNKSCHEDULING PROBLEM INFLTorrent We establish NP-completeness by formulating the decision version of the Chunk Scheduling Problem (CSP), arguing that it ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.