Recognition: no theorem link
Accelerating Compound LLM Training Workloads with Maestro
Pith reviewed 2026-05-12 05:07 UTC · model grok-4.3
The pith
Maestro reduces GPU consumption by about 40 percent on compound LLM workloads by restructuring them into section graphs and applying wavefront scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
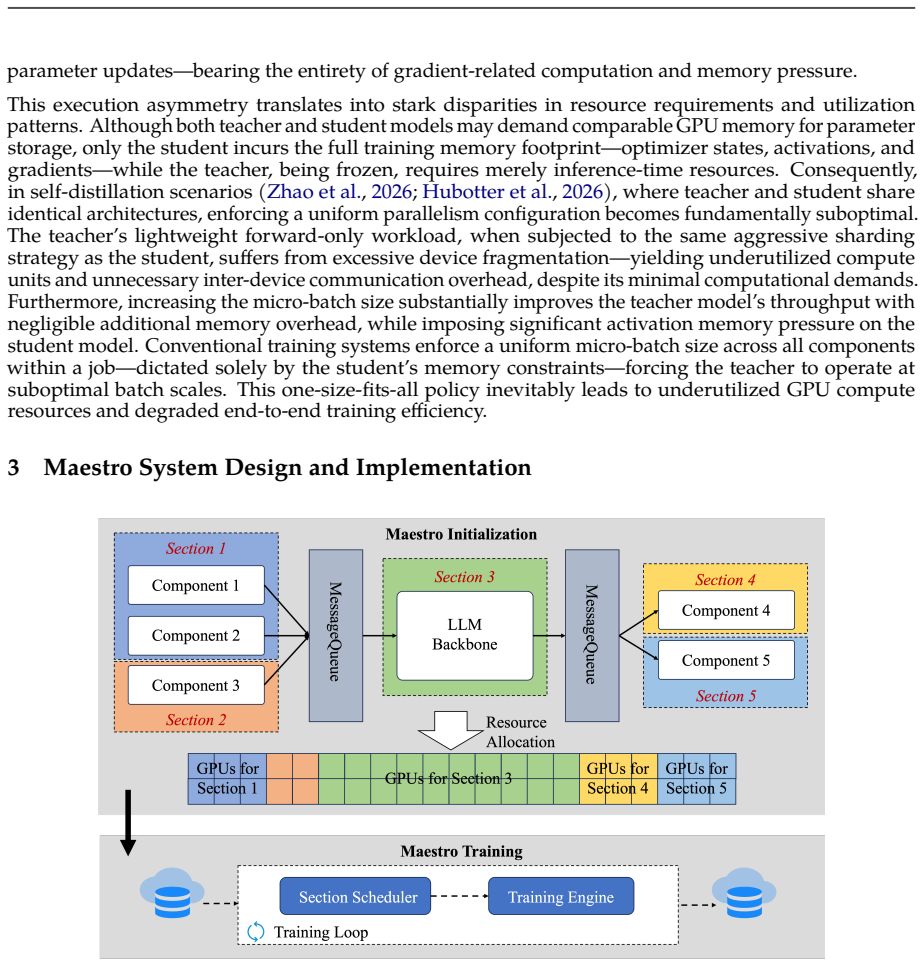
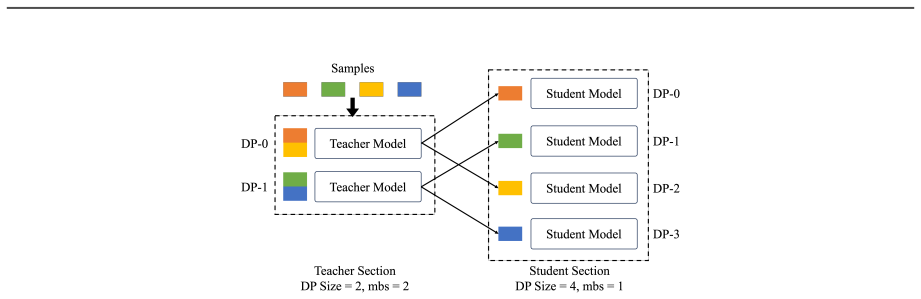
Maestro is a section-centric framework that first represents a compound LLM workload as a graph of independent sections, each free to select its parallelism strategy, micro-batch size, and data-parallel degree to match its specific scale and execution mode. To handle input-dependent activation that produces irregular runtime paths, Maestro adds a wavefront scheduling algorithm that dynamically reorders input samples to maximize concurrent section execution without violating cross-section dependencies. The combination directly tackles both static heterogeneity across components and dynamic heterogeneity at runtime, raising hardware utilization and throughput.
What carries the argument
The section graph representation, which decomposes the workload into independently configurable coarse-grained sections, together with the wavefront scheduling algorithm that reorders input samples to orchestrate inter-section parallelism while preserving dependencies.
If this is right
- Each heterogeneous component can receive its own optimal parallelism and batch settings instead of a single compromise configuration.
- Runtime stalls shrink because wavefront reordering keeps multiple sections busy even when activation patterns shift with input data.
- The same framework handles both knowledge distillation pipelines and multimodal training without separate code paths.
- Overall GPU utilization rises while the original loss and convergence behavior stay unchanged.
- Production-scale runs confirm the gains hold across millions of GPU hours on real distillation and MLLM jobs.
Where Pith is reading between the lines
- The section-graph approach may generalize to other conditional-computation settings such as mixture-of-experts training where expert activation also varies with input.
- Scheduling overhead measurements on smaller clusters would clarify whether the gains remain attractive below production scale.
- Similar graph restructuring could be applied to inference serving systems that must route requests through variable model subpaths.
Load-bearing premise
Turning the workload into a section graph and running the wavefront scheduler adds negligible overhead and never breaks data dependencies or training convergence even when computational paths change with each input.
What would settle it
A head-to-head run of the same compound workload showing that total GPU hours or wall-clock time with Maestro is no lower than a carefully tuned single-configuration baseline, or that final model accuracy falls because of violated dependencies.
Figures








read the original abstract
Compound LLM training workloads-such as knowledge distillation and multimodal LLM (MLLM) training-are gaining prominence. These typically comprise heterogeneous components differing in parameter scale, execution mode (forward-only or full forward-backward), and sequence length. Besides, component activation can be data-dependent: in MLLM training, modality-specific parts activate only when inputs contain corresponding modalities, causing dynamic computational paths and irregular runtime workloads. Conventional frameworks, designed for monolithic models, cannot handle the dual heterogeneity-static (across components) and dynamic (runtime). By enforcing one-size-fits-all training configurations across components and ignoring input-induced variations, they suffer suboptimal throughput and poor GPU utilization. In this paper, we introduce Maestro, a section-centric training framework that addresses both challenges. Maestro first restructures the workload into a coarse-grained section graph. Each section independently configures its parallelism strategy, micro-batch size, and data-parallel degree-enabling fine-grained, component-aware resource allocation to tackle static heterogeneity. To tackle runtime irregularity, Maestro introduces a wavefront scheduling algorithm that dynamically reorders input samples to orchestrate concurrent section execution while preserving cross-section data dependencies. This maximizes inter-section parallelism and minimizes stalls, boosting hardware utilization. Deployed in production for millions of GPU hours, Maestro reduces GPU consumption by ~40% on key workloads-including knowledge distillation and MLLM training-validating its real-world impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Maestro, a section-centric training framework for compound LLM workloads such as knowledge distillation and multimodal LLM (MLLM) training. It restructures workloads into coarse-grained section graphs allowing independent parallelism strategies, micro-batch sizes, and data-parallel degrees per component to address static heterogeneity. A wavefront scheduling algorithm is proposed to dynamically reorder input samples for concurrent section execution while preserving cross-section data dependencies, aiming to maximize inter-section parallelism and GPU utilization under dynamic, input-dependent activation paths. The central claim is a ~40% reduction in GPU consumption, validated through production deployment across millions of GPU hours on key workloads.
Significance. If the performance claims and convergence preservation hold under scrutiny, this work could meaningfully advance systems support for heterogeneous and dynamic training workloads that are increasingly common in modern LLM pipelines. The emphasis on production deployment and real-world GPU-hour savings is a strength for practical impact. However, the absence of detailed benchmarks, baselines, ablation studies, or analysis of training dynamics limits the ability to assess broader significance or generalizability beyond the specific deployments described.
major comments (2)
- [Abstract] Abstract: The central claim of ~40% GPU consumption reduction from production use on knowledge distillation and MLLM training is stated without any accompanying benchmarks, baselines, tables, figures, error analysis, or implementation details. This directly undermines verification of the stated gains and is load-bearing for the real-world impact assertion.
- [Wavefront scheduling description] Wavefront scheduling description: The claim that reordering samples to maximize inter-section parallelism preserves all data dependencies and training convergence (including for dynamic modality-specific paths in MLLM) lacks any concrete validation, experiments, or analysis showing that the reordering does not alter gradient statistics, effective batch composition, or convergence behavior. This is load-bearing for the correctness of the dynamic scheduling approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will make targeted revisions to strengthen the presentation of our claims and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of ~40% GPU consumption reduction from production use on knowledge distillation and MLLM training is stated without any accompanying benchmarks, baselines, tables, figures, error analysis, or implementation details. This directly undermines verification of the stated gains and is load-bearing for the real-world impact assertion.
Authors: We agree that the abstract would benefit from additional context to help readers locate the supporting evidence. The full manuscript contains a dedicated evaluation section (Section 5) that describes the production deployment across millions of GPU hours on knowledge distillation and MLLM workloads, including workload characteristics, measured GPU savings, and deployment scale. We will revise the abstract to briefly reference the evaluation methodology and the ~40% reduction observed in real deployments, while maintaining conciseness and pointing readers to the detailed benchmarks and analysis in the evaluation section. revision: yes
-
Referee: [Wavefront scheduling description] Wavefront scheduling description: The claim that reordering samples to maximize inter-section parallelism preserves all data dependencies and training convergence (including for dynamic modality-specific paths in MLLM) lacks any concrete validation, experiments, or analysis showing that the reordering does not alter gradient statistics, effective batch composition, or convergence behavior. This is load-bearing for the correctness of the dynamic scheduling approach.
Authors: The manuscript describes the wavefront scheduling algorithm as preserving data dependencies by construction: reordering occurs only within dependency-safe windows, and the set of samples contributing to each global gradient step remains identical to the baseline. This ensures no change to effective batch composition or gradient aggregation. We acknowledge that explicit empirical validation would strengthen the claim. In the revised version, we will add a dedicated subsection in the evaluation with experiments comparing training loss curves, final model quality metrics, and gradient statistics (where measurable) between the wavefront scheduler and a non-reordering baseline, covering both knowledge distillation and MLLM workloads with dynamic modality paths. revision: yes
Circularity Check
No circularity: systems paper with empirical claims, no equations or fitted predictions
full rationale
The paper describes a systems framework (section graphs, wavefront scheduling) for compound LLM training. It makes no mathematical derivations, uniqueness theorems, or parameter fits. The ~40% GPU reduction is presented as a production deployment result, not a prediction derived from fitted inputs or self-citations. No load-bearing steps reduce by construction to prior definitions or citations; the work is self-contained engineering with external validation via real-world usage. Reader's assessment of 0.0 is confirmed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compound LLM workloads exhibit both static heterogeneity (across components in parameter scale, execution mode, sequence length) and dynamic heterogeneity (data-dependent component activation causing irregular runtime paths).
Reference graph
Works this paper leans on
-
[1]
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for 12 perception and generation.arXiv preprint arXiv:2506.09344,
-
[2]
URLhttps://arxiv.org/abs/2511.21631. Weilin Cai, Juyong Jiang, Le Qin, Junwei Cui, Sunghun Kim, and Jiayi Huang. Shortcut-connected expert parallelism for accelerating mixture-of-experts.arXiv preprint arXiv:2404.05019,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Li-Wen Chang, Wenlei Bao, Qi Hou, Chengquan Jiang, Ningxin Zheng, Yinmin Zhong, Xuanrun Zhang, Zuquan Song, Chengji Yao, Ziheng Jiang, et al. Flux: Fast software-based communication overlap on gpus through kernel fusion.arXiv preprint arXiv:2406.06858,
-
[4]
13 Xing Chen, Zhenliang Xue, Zeyu Mi, Hanpeng Hu, Yibo Zhu, Daxin Jiang, Yimin Jiang, Yixin Song, Yubin Xia, and Haibo Chen. Pipeweaver: Addressing data dynamicity in large multimodal model training with dynamic interleaved pipeline.arXiv preprint arXiv:2504.14145,
-
[5]
Distilling the Knowledge in a Neural Network
GeoffreyHinton,OriolVinyals,andJeffDean. Distillingtheknowledgeinaneuralnetwork.arXivpreprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2006.15704 , author =
URLhttps://api.semanticscholar.org/CorpusID:285102353. Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704,
-
[7]
Accessed: 2026-02-10. Qwen3-VL-Team. Qwen3-vl.https://huggingface.co/Qwen/Qwen3-VL-235B-A22B-Instruct ,
work page 2026
-
[8]
SamyamRajbhandari,JeffRasley,OlatunjiRuwase,andYuxiongHe
Accessed: 2026-02-05. SamyamRajbhandari,JeffRasley,OlatunjiRuwase,andYuxiongHe. Zero: Memoryoptimizationstoward training trillion parameter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE,
work page 2026
-
[9]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Trainingmulti-billionparameterlanguagemodelsusingmodelparallelism.arXivpreprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[10]
Longcat-flash-omni technical report.ArXiv, abs/2511.00279,
Meituan LongCat Team. Longcat-flash-omni technical report.ArXiv, abs/2511.00279,
-
[11]
URLhttps: //api.semanticscholar.org/CorpusID:282740018. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://api.semanticscholar.org/CorpusID:280710824. 14 Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report. ArXiv, abs/2503.20215, 2025a. URLhttps://api.semanticscholar.org/CorpusID:277322543. Jin Xu, Zhifang Guo,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps://api.semanticsc holar.org/CorpusID:282203145. Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, et al. Jenga: Effective memory management for serving llm with heterogeneity. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, pp. 446–461, 2025a...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.