Recognition: no theorem link
Learning Less Is More: Premature Upper-Layer Attention Specialization Hurts Language Model Pretraining
Pith reviewed 2026-05-12 04:07 UTC · model grok-4.3
The pith
Temporarily slowing only upper-layer query and key projections in early pretraining prevents attention from collapsing onto immature lower-layer features and raises final perplexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Upper layers commit to sharp attention patterns before lower-layer features stabilize; this premature specialization can be corrected by temporarily slowing only upper-layer Q/K projections during early training, which improves final perplexity and downstream accuracy without altering other parameters.
What carries the argument
Premature upper-layer attention specialization, in which upper attention collapses onto an immature residual basis; the corrective mechanism is a temporary reduction in the learning-rate multiplier applied exclusively to upper-layer query and key projections.
If this is right
- The intervention improves final model quality by keeping upper attention from locking onto unstable lower representations.
- Multiplicative gated feed-forwards suppress the residual writes that trigger the failure, making the learning-rate fix nearly unnecessary in LLaMA-style blocks.
- Both the learning-rate change and the gated FFN act on the same growth pathway: one reduces step size, the other reduces residual energy.
- Upper-layer Q/K timing is a concrete, adjustable interaction point between decoder architecture and optimization schedule.
Where Pith is reading between the lines
- Training curricula may benefit from layer-specific learning-rate schedules that delay aggressive updates in upper blocks until lower residuals have matured.
- The same timing principle could be tested in other hierarchical sequence models where upper modules depend on lower residual streams.
- If the residual-energy factor dominates, further architectural tweaks that limit early residual magnitude might substitute for schedule changes.
Load-bearing premise
Decoder blocks are strictly hierarchical so that upper attention depends on a stable lower-layer residual basis, and the early slowing of upper Q/K updates affects only that timing without unintended side effects on other parameters or later training.
What would settle it
A controlled run in which the same upper-layer Q/K slowing is applied but final perplexity and downstream scores do not improve, or worsen, would falsify the central claim.
Figures

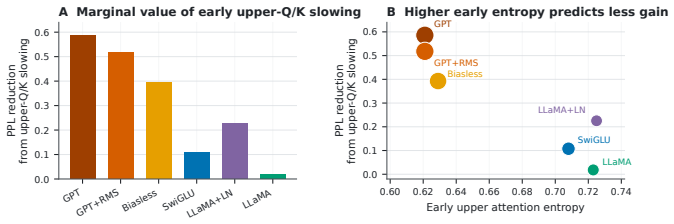
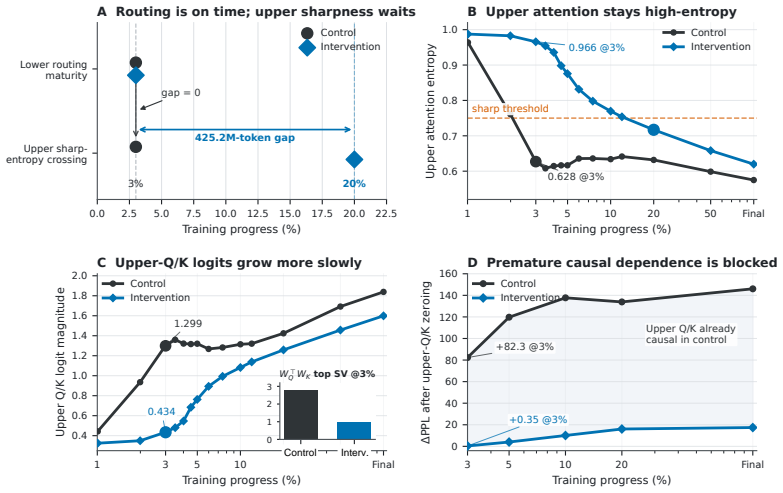
read the original abstract
A causal-decoder block is hierarchical: lower layers build the residual basis that upper layers attend over. We identify a failure mode in GPT pretraining: upper layers commit to sharp attention patterns before lower-layer features stabilize. We call this premature upper-layer attention specialization. Temporarily slowing only upper-layer Q/K projections during early training improves final perplexity and downstream accuracy without altering other parameters; it prevents upper attention from collapsing onto an immature residual basis. In LLaMA-style blocks, the same intervention is nearly unnecessary. Through ablations, we isolate multiplicative gated FFNs (not RMSNorm or bias removal) as the component that suppresses the upstream residual writes driving the failure. A pathwise analysis unifies both findings: the learning-rate intervention reduces a step-size factor, while gated FFNs reduce a residual-energy factor on the same growth pathway. Our results identify upper-layer Q/K timing as a concrete interaction point between decoder architecture and optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in GPT-style causal decoder pretraining, upper layers develop sharp attention patterns before lower layers stabilize the residual basis, a failure mode termed premature upper-layer attention specialization. Temporarily slowing only upper-layer Q/K projections early in training improves final perplexity and downstream accuracy; the same intervention is nearly unnecessary in LLaMA-style blocks. Ablations isolate multiplicative gated FFNs (not RMSNorm or bias removal) as suppressing the upstream residual writes that drive the failure. A pathwise analysis unifies the findings by showing the learning-rate intervention reduces a step-size factor while gated FFNs reduce a residual-energy factor on the same growth pathway.
Significance. If the results hold, the work supplies a concrete mechanistic link between decoder architecture and optimization dynamics, with explicit credit due to the targeted ablations isolating gated FFNs and the pathwise analysis that unifies the intervention effects. This could guide more stable pretraining schedules and architecture choices for large language models.
major comments (1)
- [Intervention description and ablation studies] The central claim requires that the temporary slowdown on upper-layer Q/K projections affects only the timing of attention specialization without unintended side effects on other parameters. Because transformer training is end-to-end, gradients from the loss flow backward through upper attention outputs into the shared residual stream, so any change in how quickly upper attention adapts necessarily modulates the gradient magnitudes and directions seen by lower-layer parameters during the critical early phase. The ablations isolating gated FFNs and the pathwise analysis do not quantify or control for this cross-layer gradient coupling, leaving open the possibility that observed perplexity gains arise from altered lower-layer training dynamics rather than from the hypothesized prevention of premature specialization.
minor comments (2)
- [Abstract] The abstract introduces 'pathwise analysis' without a brief definition of the analyzed path or the residual-energy and step-size factors; a short clarification would aid readability.
- [Experimental setup] Experimental details such as exact layer indices treated as 'upper layers,' the precise schedule for the temporary slowdown, number of random seeds, and error bars on perplexity improvements should be stated explicitly to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The concern about cross-layer gradient coupling is a substantive point that we address directly below.
read point-by-point responses
-
Referee: The central claim requires that the temporary slowdown on upper-layer Q/K projections affects only the timing of attention specialization without unintended side effects on other parameters. Because transformer training is end-to-end, gradients from the loss flow backward through upper attention outputs into the shared residual stream, so any change in how quickly upper attention adapts necessarily modulates the gradient magnitudes and directions seen by lower-layer parameters during the critical early phase. The ablations isolating gated FFNs and the pathwise analysis do not quantify or control for this cross-layer gradient coupling, leaving open the possibility that observed perplexity gains arise from altered lower-layer training dynamics rather than from the hypothesized prevention of premature specialization.
Authors: We agree that end-to-end training creates gradient coupling through the residual stream, so modulating upper-layer Q/K adaptation rates will influence the gradients received by lower layers. Our intervention is narrowly scoped to the learning rates of only the Q and K projections in upper layers; all other parameters (including lower-layer weights, upper-layer V and output projections, and FFN weights) retain the base schedule. The pathwise analysis isolates the effect to a specific step-size factor on the attention specialization pathway, while the gated-FFN ablations target the residual-energy factor on the same pathway. We will add new measurements of lower-layer gradient norms and residual-stream statistics during the early phase (with and without the intervention) to quantify the degree of coupling and to show that lower-layer feature development remains comparable. These additions will strengthen the claim that the primary benefit arises from delayed upper-layer specialization. revision: yes
Circularity Check
No significant circularity; claims rest on empirical interventions and ablations
full rationale
The paper advances its central claim through controlled training interventions (temporary slowdown of upper-layer Q/K projections) and architecture ablations (isolating gated FFNs), with results measured by perplexity and downstream accuracy. These are externally verifiable via replication on standard pretraining setups and do not reduce to any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The pathwise analysis is presented as a unifying interpretation of the observed factors rather than a derivation that presupposes its own outputs. No equations or uniqueness theorems are invoked that collapse the result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal-decoder blocks are hierarchical: lower layers build the residual basis that upper layers attend over.
Reference graph
Works this paper leans on
-
[1]
Controlling changes to attention logits.arXiv preprint arXiv:2511.21377,
Ben Anson and Laurence Aitchison. Controlling changes to attention logits.arXiv preprint arXiv:2511.21377,
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hal- lahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling.arXiv preprint arXiv:2304.01373,
-
[4]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagne, Alexandra Sasha Luccioni, François Yvon, et al. BLOOM: A 176b-parameter open-access multilingual language model.arXiv preprint arXiv:2211.05100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
work page 2021
-
[6]
H., Ivison, H., Magnusson, I., Wang, Y., et al
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. OLMo: Accelerat- ing the science of language models.arXiv preprint arXiv:2402.00838,
-
[7]
Gaussian Error Linear Units (GELUs)
10 Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
Sharan Narang, Hyung Won Chung, Yi Tay, Liam Fedus, Thibault Fevry, Michael Matena, Karishma Malkan, Noah Fiedel, Noam Shazeer, Zhenzhong Lan, et al. Do transformer modifications transfer across implementations and applications? InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5758–5773,
work page 2021
-
[11]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Prajit Ramachandran, Barret Zoph, and Quoc V . Le. Searching for activation functions.arXiv preprint arXiv:1710.05941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[14]
Normformer: Improved transformer pretraining with extra normalization
Sam Shleifer, Jason Weston, and Myle Ott. NormFormer: Improved transformer pretraining with extra normalization.arXiv preprint arXiv:2110.09456,
-
[15]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catan- zaro. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay B...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin R. Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Inter- pretability in the wild: A circuit for indirect object identification in GPT-2 small.arXiv preprint arXiv:2211.00593,
work page internal anchor Pith review arXiv
-
[18]
Shuangfei Zhai, Tatiana Likhomanenko, Etai Littwin, Dan Busbridge, Jason Ramapuram, Yizhe Zhang, Jiatao Gu, and Josh Susskind. Stabilizing transformer training by preventing attention entropy collapse.arXiv preprint arXiv:2303.06296,
-
[19]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
12 A Related Work Decoder pretraining and training-time analysis.Causal decoder pretraining is the standard setting for studying language-model scaling, from the Transformer and GPT-style decoders to GPT-3, Megatron-LM, PaLM, OPT, BLOOM, LLaMA, and LLaMA 2 [Vaswani et al., 2017, Radford et al., 2019, Brown et al., 2020, Shoeybi et al., 2019, Chowdhery et ...
work page 2017
-
[21]
Both λQ and λK remain below one, so the locality constants are not absorbing an uncontrolled blow-up
Settingλ Q λK RP /∥X∥ 2 F Control 0.63 0.58 0.18 Intervention 0.49 0.46 0.16 The measured ratios support the condition used by the localized theorem. Both λQ and λK remain below one, so the locality constants are not absorbing an uncontrolled blow-up. The control has larger ratios than the intervention, matching the mechanism evidence that default early u...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.