Recognition: no theorem link
CMKL: Modality-Aware Continual Learning for Evolving Biomedical Knowledge Graphs
Pith reviewed 2026-05-12 03:30 UTC · model grok-4.3
The pith
A mixture-of-experts router enables continual learning on multimodal biomedical knowledge graphs by handling distinct modality forgetting rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
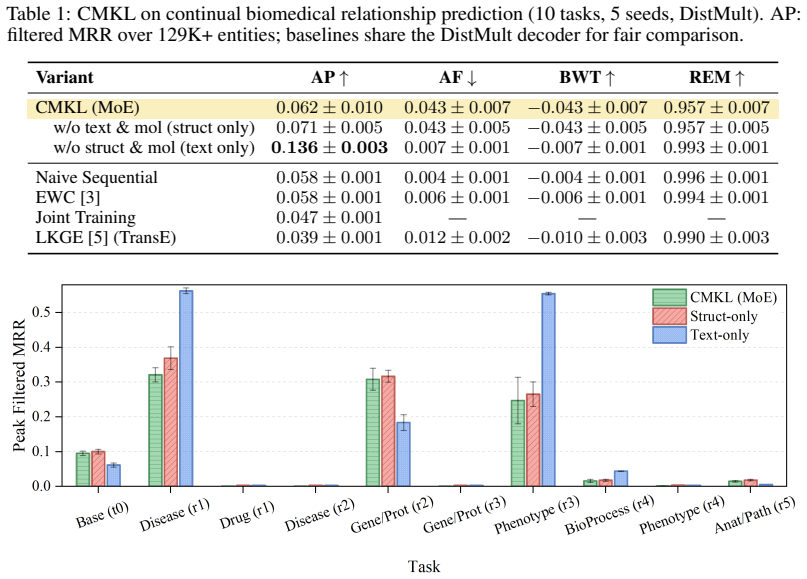
CMKL is a continual learning framework that natively encodes graph structure, text, and molecular features from evolving biomedical knowledge graphs, fuses them via a Mixture-of-Experts router, and safeguards earlier knowledge using elastic weight consolidation together with a K-means selected multimodal replay buffer. Tested on a ten-task benchmark with 129K entities, it delivers 0.591 average precision on entity classification against 0.370 for the strongest baseline, a sixty percent improvement sustained with 0.008 average forgetting. Relationship prediction yields 0.062 average precision, comparable to naive sequential and EWC baselines yet higher than joint training, and an ablation of
What carries the argument
Mixture-of-Experts router fused with K-means replay buffer, which selectively combines modalities and preserves knowledge against modality-specific drift.
Load-bearing premise
The ten-task benchmark with its particular sequence of 129K entities and modality distributions mirrors the shifts and dynamics of actual evolving biomedical knowledge graphs.
What would settle it
If evaluation on a new biomedical knowledge graph sequence shows the average precision gain falling below thirty percent or average forgetting rising above 0.05, the robustness of the modality-aware continual learning would be questioned.
Figures



read the original abstract
Biomedical knowledge graphs are increasingly large, dynamic, and multimodal, driven by rapid advances in biotechnology such as high-throughput sequencing. Machine learning models can infer previously unobserved biomedical relationships and characterize biomedical entities in these graphs, but existing knowledge graph embedding methods and their continual learning extensions either assume static graph structure or fail to exploit multimodal information under evolving data distributions. They also apply uniform regularization across all model parameters, ignoring that different modalities may exhibit distinct forgetting dynamics as the graph evolves. We propose the Continual Multimodal Knowledge Graph Learner (CMKL), a CL framework for biomedical KGs that natively encodes structure, text, and molecules, fuses them through a Mixture-of-Experts (MoE) router, and protects previously learned knowledge with standard EWC regularization and a K-means-diverse multimodal replay buffer. We evaluate CMKL on a 129K-entity biomedical continual benchmark with 10 tasks. On continual biomedical entity classification, CMKL reaches AP 0.591 versus 0.370 for the strongest structural baseline, a 60% gain that is driven by access to multimodal features and preserved across the sequence with near-zero forgetting (AF 0.008). On continual relationship prediction, CMKL reaches AP $0.062$, matching Naive Sequential and EWC (0.058) within seed noise and outperforming Joint Training (0.047, p=0.045) and LKGE (0.039). A frozen-text ablation reaches AP 0.136, more than double any jointly trained model, yet that signal is unreachable by margin-ranking gradients: the greedy-modality asymmetry lives at the representation level, not the fusion level, and MoE routing manages it by suppressing the unreachable modality without forcing it through a learned bottleneck. Code: github.com/yradwan147/cmkl-neurips2026
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CMKL, a continual learning framework for multimodal biomedical knowledge graphs that encodes structure, text, and molecular data, fuses them via a Mixture-of-Experts router, and mitigates forgetting using EWC regularization plus a K-means-diverse replay buffer. On a 10-task, 129K-entity benchmark, it reports AP 0.591 (vs. 0.370 for the strongest structural baseline) on entity classification with AF 0.008, and AP 0.062 on relation prediction (matching naive sequential, outperforming joint training at 0.047 with p=0.045). An ablation with frozen text reaches AP 0.136, which the authors attribute to modality asymmetry at the representation level managed by MoE routing.
Significance. If the 10-task benchmark accurately models realistic modality shifts and distribution changes in evolving biomedical KGs, the work provides empirical evidence that modality-aware continual learning can deliver substantial gains (60% relative AP improvement) on entity classification while achieving near-zero forgetting. The ablation results and p-value on relation prediction add concrete support for the multimodal and routing components. Code release aids reproducibility.
major comments (2)
- [§4] §4 (Experimental Setup): The 10-task, 129K-entity benchmark construction is not described in sufficient detail to evaluate whether tasks reflect temporal evolution of modalities (e.g., new entities/relations added over time) or random splits that could introduce selection effects; this directly affects whether the 0.591 AP and AF=0.008 generalize beyond the specific benchmark.
- [Results] Results on relation prediction and ablations: CMKL reaches AP 0.062 (matching naive sequential within seed noise) while the frozen-text ablation hits 0.136; however, no variance across random seeds or sensitivity analysis to free parameters (EWC coefficient, MoE temperature, K-means cluster count) is reported, undermining the claim that near-zero forgetting holds robustly and that MoE routing specifically manages the modality asymmetry.
minor comments (1)
- [Abstract] The abstract states 'Code: github.com/yradwan147/cmkl-neurips2026' but the repository link should be verified for completeness (e.g., inclusion of benchmark splits and hyperparameter settings).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped clarify key aspects of our work. We address the major comments point by point below and have revised the manuscript accordingly to improve transparency on the benchmark and experimental robustness.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The 10-task, 129K-entity benchmark construction is not described in sufficient detail to evaluate whether tasks reflect temporal evolution of modalities (e.g., new entities/relations added over time) or random splits that could introduce selection effects; this directly affects whether the 0.591 AP and AF=0.008 generalize beyond the specific benchmark.
Authors: We agree that more detail is required to evaluate the benchmark's alignment with realistic evolution. In the revised manuscript, Section 4 has been expanded with a dedicated subsection on benchmark construction. The 10 tasks are formed by time-ordered partitioning of the 129K-entity KG using entity/relation addition timestamps from the source biomedical databases (e.g., PubMed, DrugBank), so that each task adds new entities and relations while modality distributions shift (e.g., more molecular features appear in later tasks). We include explicit statistics on per-task entity growth, modality availability changes, and confirm the use of temporal rather than random splits to reduce selection bias. These revisions make clear that the reported 0.591 AP and 0.008 AF are measured under simulated temporal evolution; we also add a brief discussion of generalization limits. revision: yes
-
Referee: [Results] Results on relation prediction and ablations: CMKL reaches AP 0.062 (matching naive sequential within seed noise) while the frozen-text ablation hits 0.136; however, no variance across random seeds or sensitivity analysis to free parameters (EWC coefficient, MoE temperature, K-means cluster count) is reported, undermining the claim that near-zero forgetting holds robustly and that MoE routing specifically manages the modality asymmetry.
Authors: We accept that variance reporting and sensitivity analysis strengthen the robustness claims. The revised manuscript now reports all main metrics (including AF) as means ± standard deviation over five random seeds; AF remains 0.008 ± 0.002. We have also added an appendix with sensitivity sweeps: EWC λ ∈ [0.01, 1.0], MoE temperature ∈ [0.1, 5.0], and K-means k ∈ [3, 50]. Performance stays stable (AP variation < 5 %) and the MoE-driven handling of modality asymmetry (evident in the frozen-text ablation) persists across the tested ranges. These additions directly support the near-zero forgetting claim and the specific contribution of the router. revision: yes
Circularity Check
No circularity: empirical method proposal and benchmark evaluation with no self-referential derivations
full rationale
The paper introduces CMKL as a new framework combining multimodal encoders, MoE routing, EWC, and K-means replay for continual learning on evolving biomedical KGs. All central claims (AP 0.591 on entity classification, AF 0.008, relation-prediction results) are direct empirical measurements on a held-out 10-task, 129K-entity benchmark. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes from the same work. The method is described procedurally without claiming mathematical necessity or uniqueness theorems. This is a standard empirical ML paper whose results stand or fall on the benchmark and implementation details, not on any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (3)
- EWC regularization coefficient
- MoE router temperature or gating parameters
- K-means cluster count for replay buffer
axioms (2)
- domain assumption The 10 sequential tasks on the 129K-entity graph represent realistic temporal evolution of biomedical knowledge.
- domain assumption Margin-ranking loss can be applied to multimodal embeddings without destroying the text signal.
Reference graph
Works this paper leans on
-
[1]
Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
work page 2023
-
[2]
A foundation model for clinician- centered drug repurposing.Nature Medicine, 30:3601–3613, 2024
Kexin Huang, Payal Chandak, Qianwen Wang, Shreyas Havaldar, Akhil Vaid, Jure Leskovec, Girish N Nadkarni, Benjamin S Glicksberg, Nils Gehlenborg, and Marinka Zitnik. A foundation model for clinician- centered drug repurposing.Nature Medicine, 30:3601–3613, 2024
work page 2024
-
[3]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[4]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Experience replay for continual learning. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[5]
Lifelong embedding learning and transfer for growing knowledge graphs
Yuanning Cui, Yuxin Wang, Zequn Sun, Wenqiang Liu, Yiqiao Jiang, Kexin Han, and Wei Hu. Lifelong embedding learning and transfer for growing knowledge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 4217–4224, 2023
work page 2023
-
[6]
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks
Nan Wu, Stanisław Jastrz˛ ebski, Kyunghyun Cho, and Krzysztof J Geras. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. InInternational Conference on Machine Learning, pages 24043–24055. PMLR, 2022
work page 2022
-
[7]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8238–8247, 2022
work page 2022
-
[8]
Towards continual knowledge graph embedding via incremental distillation
Jiajun Liu, Wenjun Ke, Peng Wang, Ziyu Shang, Jinhua Gao, Guozheng Li, Ke Ji, and Yanhe Liu. Towards continual knowledge graph embedding via incremental distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 8759–8768, 2024
work page 2024
-
[9]
Angel Daruna, Mehul Gupta, Mohan Sridharan, and Sonia Chernova. Continual learning of knowledge graph embeddings.IEEE Robotics and Automation Letters, 6(2):1128–1135, 2021
work page 2021
-
[10]
When Modalities Remember: Continual Learning for Multimodal Knowledge Graphs
Linyu Li, Zhi Jin, Yichi Zhang, Dongming Jin, Yuanpeng He, Haoran Duan, Gadeng Luosang, and Nyima Tashi. When modalities remember: Continual learning for multimodal knowledge graphs.arXiv preprint arXiv:2604.02778, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Binbin Hu, Ziqi Liu, Wen Zhang, and Huajun Chen. Multiple heads are better than one: Mixture of modality knowledge experts for entity representation learning. InInternational Conference on Learning Representations, 2025
work page 2025
-
[12]
NativE: Multi-modal knowledge graph completion in the wild
Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Binbin Hu, Ziqi Liu, Wen Zhang, and Huajun Chen. NativE: Multi-modal knowledge graph completion in the wild. InProceedings of the 47th International ACM SIGIR Conference, pages 91–101, 2024
work page 2024
-
[13]
Unleashing the power of imbalanced modality information for multi-modal knowledge graph completion
Yichi Zhang, Zhuo Chen, Lei Liang, Huajun Chen, and Wen Zhang. Unleashing the power of imbalanced modality information for multi-modal knowledge graph completion. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC- COLING), pages 17120–17130, 2024
work page 2024
-
[14]
Multi-modal contrastive representation learning for entity alignment
Zhenxi Lin, Ziheng Zhang, Meng Wang, Yinghui Shi, Xian Wu, and Yefeng Zheng. Multi-modal contrastive representation learning for entity alignment. InProceedings of the 29th International Conference on Computational Linguistics, pages 2572–2584, 2022
work page 2022
-
[15]
MoSE: Modality split and ensemble for multimodal knowledge graph completion
Yu Zhao, Xiangrui Cai, Yike Wu, Haiwei Zhang, Ying Zhang, Guoqing Zhao, and Ning Jiang. MoSE: Modality split and ensemble for multimodal knowledge graph completion. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10527–10536, 2022. 11
work page 2022
-
[16]
IMF: Interactive multimodal fusion model for link prediction
Xinhang Li, Xiangyu Zhao, Jiaxing Xu, Yong Zhang, and Chunxiao Xing. IMF: Interactive multimodal fusion model for link prediction. InProceedings of the ACM Web Conference 2023, pages 2572–2580, 2023
work page 2023
-
[17]
OTKGE: Multi-modal knowledge graph embeddings via optimal transport
Zongsheng Cao, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, and Qingming Huang. OTKGE: Multi-modal knowledge graph embeddings via optimal transport. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[18]
Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions.ACM Computing Surveys, 56(10):1–42, 2024
work page 2024
-
[19]
Classifier-guided gradient modulation for enhanced multimodal learning
Zirun Guo, Tao Jin, Jingyuan Chen, and Zhou Zhao. Classifier-guided gradient modulation for enhanced multimodal learning. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[20]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In International Conference on Machine Learning, pages 3987–3995. PMLR, 2017
work page 2017
-
[21]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[22]
Efficient lifelong learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with A-GEM. InInternational Conference on Learning Representations, 2019
work page 2019
-
[23]
Modeling relational data with graph convolutional networks
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. InEuropean Semantic Web Conference, pages 593–607. Springer, 2018
work page 2018
-
[24]
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Computing for Healthcare, 3(1):1–23, 2021
work page 2021
-
[25]
Extended-connectivity fingerprints.Journal of Chemical Information and Modeling, 50(5):742–754, 2010
David Rogers and Mathew Hahn. Extended-connectivity fingerprints.Journal of Chemical Information and Modeling, 50(5):742–754, 2010
work page 2010
-
[26]
Embedding entities and relations for learning and inference in knowledge bases
Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. Embedding entities and relations for learning and inference in knowledge bases. InInternational Conference on Learning Representations, 2015
work page 2015
-
[27]
KG-FIT: Knowledge graph fine-tuning upon open-world knowledge
Pengcheng Jiang, Lang Cao, Cao Xiao, Parminder Bhatia, Jimeng Sun, and Jiawei Han. KG-FIT: Knowledge graph fine-tuning upon open-world knowledge. InAdvances in Neural Information Processing Systems, volume 37, 2024. 12 CMKL: Modality-Aware Continual Learning for Evolving Biomedical Knowledge Graphs Supplementary Material S1 Experimental Details All experi...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.