Recognition: no theorem link
UniRank: Unified List-wise Reranking via Confidence-Ordered Denoising
Pith reviewed 2026-05-12 04:56 UTC · model grok-4.3
The pith
UniRank unifies autoregressive and non-autoregressive list-wise reranking by filling the most confident slot in each step of an iterative denoising process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
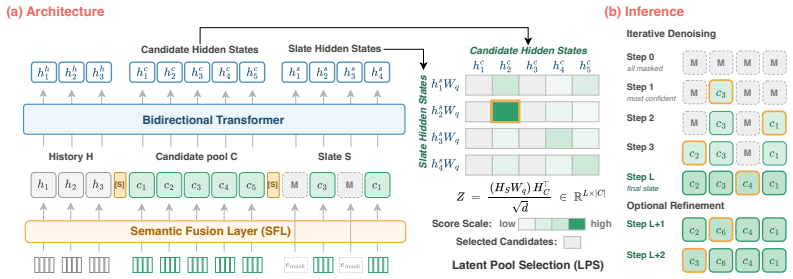
UniRank integrates bidirectional slate modeling into an iterative denoising process and fills the most confident slot at each step. To instantiate the framework for reranking, the Task Grounded Diffusion Interface performs denoising at the item level, restricts prediction to the request-specific candidate pool, aggregates each item's semantic tokens into a single embedding, and scores each slot directly against the candidate pool. This unified architecture recovers AR and NAR rerankers as special cases and consistently outperforms state-of-the-art baselines on Amazon Books, MovieLens-1M, an industrial short video dataset, and online A/B tests yielding +0.159% app-time and +1.016% share-rate.
What carries the argument
The confidence-ordered iterative denoising process with bidirectional slate modeling, instantiated via the Task Grounded Diffusion Interface (TGD) that aggregates semantic tokens into item embeddings and scores slots against the candidate pool.
If this is right
- UniRank recovers existing autoregressive and non-autoregressive rerankers as inference-time special cases of the same model.
- The method produces stronger ranked slates than prior approaches across public and industrial datasets.
- Live deployment of the framework yields measurable lifts in user engagement metrics such as average app-time and share-rate.
- Bidirectional modeling plus iterative filling captures inter-item dependencies while sidestepping both error propagation and slot-independence assumptions.
Where Pith is reading between the lines
- The same confidence-ordered denoising loop could be tested on other generative sequencing tasks such as query suggestion or session-based recommendation.
- Grounding diffusion steps to a fixed candidate pool via an interface like TGD might reduce hallucinations in other retrieval or ranking models.
- Production systems could maintain a single trained model and switch between AR-like and NAR-like behavior simply by changing the inference schedule.
Load-bearing premise
Ordering the denoising steps by descending model confidence accurately identifies correct slot assignments without introducing new instabilities or biases.
What would settle it
Re-running the offline experiments and online A/B tests while replacing confidence-ordered slot selection with random or fixed order and finding no performance drop would show that the ordering mechanism is not responsible for the reported gains.
Figures





read the original abstract
List-wise reranking arranges a request-specific pool of candidate items into an ordered slate that maximizes user satisfaction. Existing generative rerankers fall into two paradigms: Autoregressive (AR) rerankers construct the slate left to right and capture inter-item dependencies in the exposure list, but they suffer from error propagation because early mistakes affect subsequent slots. Non-autoregressive (NAR) rerankers predict all slots in parallel and avoid error propagation, but they weaken inter-item interaction modeling under a slot independence assumption. This raises a central question: is there a unified architecture that combines the strengths of both paradigms and delivers stronger reranking performance? We answer this question with UniRank, a unified list-wise reranking framework whose inference time variants recover AR and NAR rerankers as special cases. UniRank integrates bidirectional slate modeling into an iterative denoising process and fills the most confident slot at each step. To instantiate this framework for reranking, we introduce the Task Grounded Diffusion Interface (TGD), which performs denoising at the item level and restricts prediction to the request-specific candidate pool. TGD aggregates each item's semantic tokens into a single item embedding and scores each slot directly against the candidate pool. Experiments on Amazon Books, MovieLens-1M, and an industrial short video dataset show that UniRank consistently outperforms state-of-the-art baselines. Online A/B tests on a real-world industrial platform further validate its effectiveness, yielding significant improvements of +0.159% in user average app-time and +1.016% in share-rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniRank, a unified list-wise reranking framework that integrates bidirectional slate modeling into an iterative denoising process, filling the most confident slot at each step. Inference variants recover autoregressive (AR) and non-autoregressive (NAR) rerankers as special cases. It introduces the Task Grounded Diffusion Interface (TGD) for item-level denoising restricted to the request-specific candidate pool, with semantic token aggregation into item embeddings and direct slot-vs-pool scoring. Experiments on Amazon Books, MovieLens-1M, an industrial short video dataset, and online A/B tests report consistent outperformance over SOTA baselines, with lifts of +0.159% app-time and +1.016% share-rate.
Significance. If the unification claim holds and the confidence-ordered denoising demonstrably captures inter-item dependencies without introducing new propagation or bias issues, UniRank would provide a flexible architecture resolving the AR/NAR trade-off in generative reranking. The inclusion of online A/B test results with concrete metric improvements strengthens the case for practical relevance in industrial recommendation systems.
major comments (2)
- [Method (TGD instantiation and inference variants)] The central unification claim—that filling the most confident slot at each denoising step recovers AR/NAR as special cases while capturing bidirectional dependencies and avoiding both error propagation and slot-independence—is not supported by any explicit algorithmic reduction, parameter settings, or derivation in the method description. Without these, it is impossible to verify that TGD's item-level denoising and slot-vs-pool scoring enforce cross-slot interactions beyond the ordering heuristic.
- [Experiments and Online A/B Tests] The experimental claims of consistent outperformance lack supporting details on controls, error bars, ablation studies, or statistical significance tests. This undermines the load-bearing assertion that UniRank outperforms baselines on the three datasets and online platform, as the reported metric lifts cannot be assessed for robustness.
minor comments (1)
- [Abstract and Method] The abstract and method sections introduce the 'Task Grounded Diffusion Interface (TGD)' as a new entity without a clear high-level diagram or pseudocode showing the iterative process, which would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested clarifications and additional details.
read point-by-point responses
-
Referee: [Method (TGD instantiation and inference variants)] The central unification claim—that filling the most confident slot at each denoising step recovers AR/NAR as special cases while capturing bidirectional dependencies and avoiding both error propagation and slot-independence—is not supported by any explicit algorithmic reduction, parameter settings, or derivation in the method description. Without these, it is impossible to verify that TGD's item-level denoising and slot-vs-pool scoring enforce cross-slot interactions beyond the ordering heuristic.
Authors: We acknowledge that an explicit algorithmic reduction and derivation would strengthen the unification claim. In the revised manuscript, we will add a new subsection (e.g., 3.4) that formally derives the special cases: (1) NAR recovery occurs when the process runs in a single parallel denoising step over all slots with uniform confidence initialization; (2) AR recovery occurs when the process is restricted to sequential single-slot filling with the most confident position always chosen as the next left-to-right slot. We will include pseudocode for both variants and explain how the bidirectional diffusion backbone (which scores against the full pool at every step) ensures cross-slot interactions even under the ordering heuristic, distinguishing it from pure slot-independence. This addition will make the reductions verifiable without altering the core method. revision: yes
-
Referee: [Experiments and Online A/B Tests] The experimental claims of consistent outperformance lack supporting details on controls, error bars, ablation studies, or statistical significance tests. This undermines the load-bearing assertion that UniRank outperforms baselines on the three datasets and online platform, as the reported metric lifts cannot be assessed for robustness.
Authors: We agree that the current experimental section would benefit from greater rigor. In the revision, we will expand Section 5 to include: error bars computed over 5 independent runs with different random seeds; ablation studies isolating the contribution of confidence-ordered denoising versus TGD; and statistical significance tests (paired t-tests with p-values) for all reported improvements on Amazon Books, MovieLens-1M, and the industrial dataset. For the online A/B tests, we will add details on experimental controls (e.g., traffic allocation, test duration, and user cohort matching) and report confidence intervals for the +0.159% app-time and +1.016% share-rate lifts, while omitting any proprietary platform specifics. These changes will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity in UniRank unification claim
full rationale
The paper presents UniRank as an architectural framework that unifies autoregressive and non-autoregressive rerankers by integrating bidirectional slate modeling into a confidence-ordered iterative denoising process instantiated via the Task Grounded Diffusion Interface (TGD). TGD is described as performing item-level denoising restricted to the candidate pool, with semantic token aggregation into embeddings and direct slot-vs-pool scoring. The abstract states that inference-time variants recover AR and NAR as special cases, but no equations, derivations, or fitted parameters are shown that reduce the claimed performance gains or unification to self-referential definitions or inputs by construction. No self-citation load-bearing premises, uniqueness theorems, or ansatz smuggling via prior work are evident. Validation rests on empirical results across datasets and A/B tests rather than tautological reductions. The derivation chain is self-contained as a proposed interface without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Task Grounded Diffusion Interface (TGD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep neural networks for youtube recommenda- tions
Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommenda- tions. In Shilad Sen, Werner Geyer, Jill Freyne, and Pablo Castells, editors,Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, September 15-19, 2016, pages 191–198. ACM, 2016
work page 2016
-
[2]
Recflow: An industrial full flow recommendation dataset
Qi Liu, Kai Zheng, Rui Huang, Wuchao Li, Kuo Cai, Yuan Chai, Yanan Niu, Yiqun Hui, Bing Han, Na Mou, Hongning Wang, Wentian Bao, Yunen Yu, Guorui Zhou, Han Li, Yang Song, Defu Lian, and Kun Gai. Recflow: An industrial full flow recommendation dataset. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,...
work page 2025
-
[3]
Qingyao Ai, Keping Bi, Jiafeng Guo, and W. Bruce Croft. Learning a deep listwise context model for ranking refinement. In Kevyn Collins-Thompson, Qiaozhu Mei, Brian D. Davison, Yiqun Liu, and Emine Yilmaz, editors,The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, July 08-12, 201...
work page 2018
-
[4]
Personalized re-ranking for recommendation
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, et al. Personalized re-ranking for recommendation. InProceed- ings of the 13th ACM conference on recommender systems, pages 3–11, 2019
work page 2019
-
[6]
Seq2slate: Re-ranking and slate optimization with rnns.arXiv preprint arXiv:1810.02019, 2018
Irwan Bello, Sayali Kulkarni, Sagar Jain, Craig Boutilier, Ed Chi, Elad Eban, Xiyang Luo, Alan Mackey, and Ofer Meshi. Seq2slate: Re-ranking and slate optimization with rnns.arXiv preprint arXiv:1810.02019, 2018
-
[7]
McAuley, Dong Zheng, Peng Jiang, and Kun Gai
Shuchang Liu, Qingpeng Cai, Zhankui He, Bowen Sun, Julian J. McAuley, Dong Zheng, Peng Jiang, and Kun Gai. Generative flow network for listwise recommendation. In Ambuj K. Singh, Yizhou Sun, Leman Akoglu, Dimitrios Gunopulos, Xifeng Yan, Ravi Kumar, Fatma Ozcan, and Jieping Ye, editors,Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery a...
work page 2023
-
[8]
Goalrank: Group-relative optimization for a large ranking model
Kaike Zhang, Xiaobei Wang, Shuchang Liu, HailanYang, Xiang Li, Lantao Hu, Han Li, Qi Cao, Fei Sun, and Kun Gai. Goalrank: Group-relative optimization for a large ranking model. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[9]
BEAR: towards beam-search-aware optimization for recom- mendation with large language models
Weiqin Yang, Bohao Wang, Zhenxiang Xu, Jiawei Chen, Shengjia Zhang, Jingbang Chen, Canghong Jin, and Can Wang. BEAR: towards beam-search-aware optimization for recom- mendation with large language models. InThe 49st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2026, Melbourne, VIC, Australia, July 20-24, 202...
work page 2026
-
[10]
Non- autoregressive generative models for reranking recommendation
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang. Non- autoregressive generative models for reranking recommendation. In Ricardo Baeza-Yates and Francesco Bonchi, editors,Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29, 2024, pages 5625–
work page 2024
-
[11]
Denoising neural reranker for rec- ommender systems
Wenyu Mao, Shuchang Liu, HailanYang, Xiaobei Wang, Xiaoyu Yang, Xu Gao, Xiang Li, Lantao Hu, Han Li, Kun Gai, An Zhang, and Xiang Wang. Denoising neural reranker for rec- ommender systems. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[12]
Discrete conditional diffusion for reranking in recommendation
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. Discrete conditional diffusion for reranking in recommendation. In Tat-Seng Chua, Chong-Wah Ngo, Roy Ka-Wei Lee, Ravi Kumar, and Hady W. Lauw, editors,Companion Proceedings of 10 the ACM on Web Conference 2024, WWW 2024, Singapore, Singapore, May 13-17, 2024, pages 1...
work page 2024
-
[13]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. Recommender systems with generative retrieval. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in N...
work page 2023
-
[14]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.CoRR, abs/2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian J. McAuley. Generating long semantic ids in parallel for recommendation. In Luiza Antonie, Jian Pei, Xiaohui Yu, Flavio Chierichetti, Hady W. Lauw, Yizhou Sun, and Srinivasan Parthasarathy, editors,Proceedings of the 31st ACM SIGKDD Confer...
work page 2025
-
[16]
Image-based recommendations on styles and substitutes
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, pages 43–52, 2015
work page 2015
-
[17]
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015
work page 2015
-
[18]
Pengyue Jia, Xiaobei Wang, Yingyi Zhang, Shuchang Liu, Yupeng Hou, Hailan Yang, Xu Gao, Xiaopeng Li, Yejing Wang, Julian McAuley, Xiang Li, Lantao Hu, Yongqi Liu, Kaiqiao Zhan, Han Li, Kun Gai, and Xiangyu Zhao. From local indices to global identifiers: Generative reranking for recommender systems via global action space, 2026
work page 2026
-
[19]
Pier: Permutation-level interest-based end-to-end re-ranking framework in e-commerce
Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Wang Yongkang, Xingxing Wang, and Dong Wang. Pier: Permutation-level interest-based end-to-end re-ranking framework in e-commerce. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4823–4831, 2023
work page 2023
-
[20]
Comprehensive list generation for multi-generator reranking
Hailan Yang, Zhenyu Qi, Shuchang Liu, Xiaoyu Yang, Xiaobei Wang, Xiang Li, Lantao Hu, Han Li, and Kun Gai. Comprehensive list generation for multi-generator reranking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2298–2308, 2025
work page 2025
-
[21]
Teng Shi, Chenglei Shen, Weijie Yu, Shen Nie, Chongxuan Li, Xiao Zhang, Ming He, Yan Han, and Jun Xu. Llada-rec: Discrete diffusion for parallel semantic id generation in generative recommendation.arXiv preprint arXiv:2511.06254, 2025
-
[22]
Kesen Zhao, Shuchang Liu, Qingpeng Cai, Xiangyu Zhao, Ziru Liu, Dong Zheng, Peng Jiang, and Kun Gai. Kuaisim: A comprehensive simulator for recommender systems.Advances in Neural Information Processing Systems, 36:44880–44897, 2023
work page 2023
-
[23]
Neural re-ranking in multi-stage recommender systems: A review
Weiwen Liu, Yunjia Xi, Jiarui Qin, Fei Sun, Bo Chen, Weinan Zhang, Rui Zhang, and Ruiming Tang. Neural re-ranking in multi-stage recommender systems: A review. In Luc De Raedt, editor,Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pages 5512–5520. ijcai.org, 2022
work page 2022
-
[24]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. A survey of generative recommendation from a tri-decoupled perspective: Tokenization, architecture, and optimization. 2025. 11
work page 2025
-
[25]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In Jennifer Golbeck, F. Maxwell Harper, Vanessa Murdock, Michael D. Ekstrand, Bracha Shapira, Justin Basilico, Keld T. Lundgaard, and Even Oldridge, editors,RecSys ’22: Sixtee...
work page 2022
-
[26]
Zeyu Cui, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. M6-rec: Gener- ative pretrained language models are open-ended recommender systems.arXiv preprint arXiv:2205.08084, 2022
-
[27]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. In Jie Zhang, Li Chen, Shlomo Berkovsky, Min Zhang, Tommaso Di Noia, Justin Basilico, Luiz Pizzato, and Yang Song, editors,Proceedings of the 17th ACM Conference on Recommender...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.