Recognition: no theorem link
PrimeKG-CL: A Continual Graph Learning Benchmark on Evolving Biomedical Knowledge Graphs
Pith reviewed 2026-05-12 04:32 UTC · model grok-4.3
The pith
Real updates to biomedical knowledge graphs show that decoder and continual learning strategy must be matched to avoid performance loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
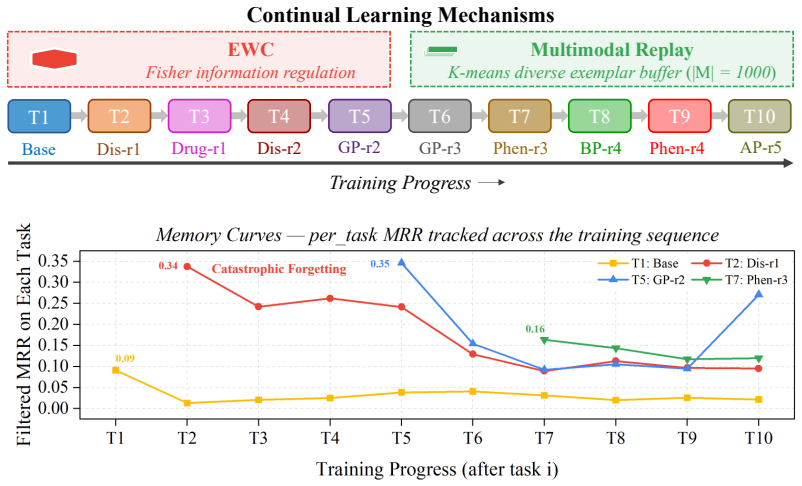
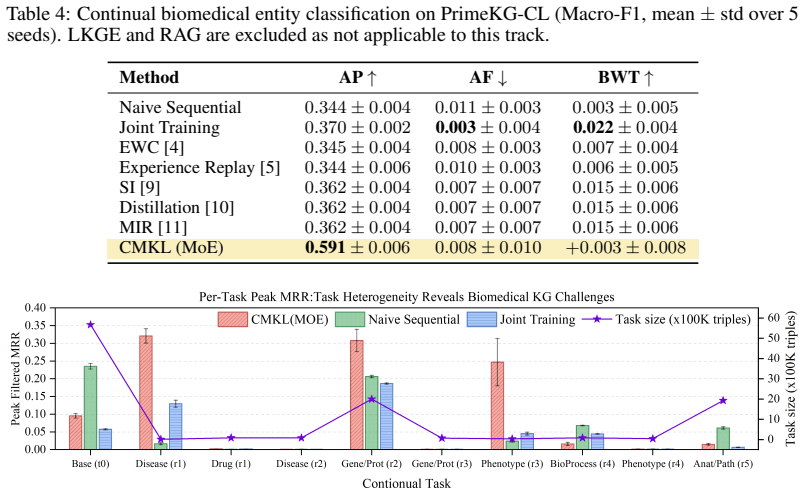
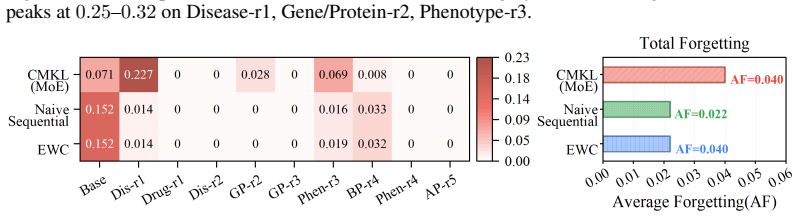
The core discovery is that decoder choice and continual learning strategy interact strongly on this benchmark: mismatched combinations degrade performance, and only DistMult shows clear separation between persistent and deprecated knowledge, while standard metrics conflate the two; multimodal features improve entity-level performance by up to 60%.
What carries the argument
PrimeKG-CL benchmark with its two temporal snapshots from June 2021 and July 2023, 10 entity-type-grouped tasks, and per-task persistent/added/removed test stratification.
If this is right
- No single continual learning strategy performs best across all knowledge graph embedding decoders.
- Mismatched decoder-strategy pairs can significantly degrade performance on biomedical tasks.
- Only the DistMult decoder exhibits separation between persistent and deprecated knowledge.
- Multimodal node features improve entity classification and related tasks by up to 60%.
- Certain continual knowledge graph embedding frameworks fail to scale to the 5.67 million triple base task.
Where Pith is reading between the lines
- This suggests that practical systems for drug repurposing or clinical support using knowledge graphs will require careful pairing of embedding methods with update strategies.
- The findings point to a need for new evaluation metrics that explicitly measure retention versus forgetting in evolving graphs.
- The benchmark could be extended with more frequent snapshots to study longer-term continual learning dynamics.
Load-bearing premise
The two chosen snapshots and the entity-type-grouped task definitions sufficiently represent the asynchronous, structured evolution that real biomedical KGs undergo in practice.
What would settle it
If evaluations on this benchmark showed similar performance for all decoder and strategy combinations on the persistent versus removed triples, or if DistMult failed to separate them, the claims about interactions and metric issues would be falsified.
Figures


read the original abstract
Biomedical knowledge graphs underwrite drug repurposing and clinical decision support, yet the upstream ontologies they depend on update on independent cycles that add millions of edges and deprecate hundreds of thousands more between releases. Yet existing continual graph learning has been studied almost exclusively on synthetic random splits of static, generic KGs, a regime that cannot reproduce the asynchronous, structured evolution real biomedical KGs undergo. To this end, we introduce PrimeKG-CL, a CGL benchmark built from nine authoritative biomedical databases (129K+ nodes, 8.1M+ edges, 10 node types, 30 relation types) with two genuine temporal snapshots (June 2021, July 2023; 5.83M edges added, 889K removed, 7.21M persistent), 10 entity-type-grouped tasks, multimodal node features, and a per-task persistent/added/removed test stratification. On three tasks (biomedical relationship prediction, entity classification, KGQA), we evaluate six CL strategies across four KGE decoders, plus LKGE, an LLM-RAG agent, and CMKL. We find that decoder choice and continual learning strategy interact strongly: no single strategy performs best across all decoders, and mismatched combinations can significantly degrade performance. Moreover, only DistMult exhibits a clear separation between persistent and deprecated knowledge, indicating that standard metrics conflate retention of still-valid facts with failure to forget outdated ones; this effect is absent under RotatE. In addition, multimodal features improve entity-level tasks by up to 60%, and a recent CKGE framework (IncDE) failed to scale to our 5.67M-triple base task across five attempts up to 350GB RAM. Data, pipeline, baselines, and the stratified split are released openly. Dataset:huggingface.co/datasets/yradwan147/PrimeKGCL|Code:github.com/yradwan147/primekg-cl-neurips2026
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrimeKG-CL, a continual graph learning benchmark constructed from the PrimeKG biomedical knowledge graph using two temporal snapshots (June 2021 and July 2023). It features 129K+ nodes, 8.1M+ edges, 10 node types, and 30 relation types, with 10 entity-type-grouped tasks, multimodal node features, and stratified test sets for persistent, added, and removed knowledge. Experiments on biomedical relationship prediction, entity classification, and KGQA evaluate six CL strategies across four KGE decoders, plus additional baselines like LKGE and CMKL. The key results are strong interactions between decoder choice and CL strategy, with mismatched combinations degrading performance, and only DistMult showing clear separation between persistent and deprecated knowledge. Multimodal features improve performance by up to 60%, and some frameworks fail to scale. The dataset, code, and splits are released openly.
Significance. If these results hold, the benchmark fills an important gap by providing a realistic setting for CGL on evolving biomedical KGs, unlike prior work on synthetic splits. The findings on decoder-CL interactions and the inadequacy of standard metrics for distinguishing retention from forgetting are valuable for guiding future method development. The open data and code release is a notable strength that promotes reproducibility and community use. This could have implications for applications in drug repurposing and clinical decision support where KGs evolve over time.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The benchmark relies on only two snapshots, corresponding to a single transition from June 2021 to July 2023. This setup does not capture cumulative effects, repeated updates, or varying change magnitudes typical in real biomedical KGs with independent ontology cycles. Consequently, the observed strong decoder-CL strategy interactions and the DistMult-specific separation between persistent and deprecated knowledge may be artifacts of this one-step regime rather than general properties.
- [§4 (Experiments)] §4 (Experiments): Full details on hyperparameter choices, statistical significance testing across runs, and the precise construction of the 10 entity-type-grouped tasks with per-task persistent/added/removed stratification are not elaborated, which is load-bearing for assessing whether the reported decoder-strategy interactions are robust.
minor comments (2)
- [Abstract] Abstract: The dataset and code links are concatenated without spaces or separators ('Dataset:huggingface.co/datasets/yradwan147/PrimeKGCL|Code:github.com/yradwan147/primekg-cl-neurips2026').
- [Throughout] Throughout: Terminology for 'persistent', 'added', and 'removed' knowledge should be used consistently in text, tables, and figure captions to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript on PrimeKG-CL. We address each major comment below and will incorporate revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: The benchmark relies on only two snapshots, corresponding to a single transition from June 2021 to July 2023. This setup does not capture cumulative effects, repeated updates, or varying change magnitudes typical in real biomedical KGs with independent ontology cycles. Consequently, the observed strong decoder-CL strategy interactions and the DistMult-specific separation between persistent and deprecated knowledge may be artifacts of this one-step regime rather than general properties.
Authors: We acknowledge that the use of only two snapshots captures a single transition rather than multi-step cumulative evolution. This design was necessitated by the availability of temporally aligned, high-quality releases from the nine source databases; additional intermediate snapshots with consistent schema and coverage are not publicly available for the full PrimeKG construction. The observed decoder-CL interactions hold consistently across three distinct tasks (relationship prediction, entity classification, and KGQA) and multiple metrics, which we interpret as evidence of robustness rather than an artifact of the one-step regime. Nevertheless, we agree this is a genuine limitation of the current benchmark. In the revised manuscript we will add an explicit limitations subsection in the discussion that quantifies the scale of the single transition (5.83 M added / 889 K removed edges) and outlines concrete directions for extending the benchmark with future data releases. revision: partial
-
Referee: Full details on hyperparameter choices, statistical significance testing across runs, and the precise construction of the 10 entity-type-grouped tasks with per-task persistent/added/removed stratification are not elaborated, which is load-bearing for assessing whether the reported decoder-strategy interactions are robust.
Authors: We apologize for the insufficient detail in the original submission. In the revised version we will expand Section 4 (Experiments) with: (i) complete hyperparameter grids and selection criteria for all four KGE decoders and six CL strategies, (ii) the exact statistical procedure (five random seeds, paired t-tests with reported p-values and standard deviations), and (iii) a step-by-step description of how the 10 entity-type-grouped tasks were derived, including the per-task rules for persistent/added/removed test stratification. These additions will be accompanied by new tables in the appendix. revision: yes
Circularity Check
Empirical benchmark release with no derivation chain or fitted predictions
full rationale
The paper introduces a new continual graph learning benchmark (PrimeKG-CL) constructed from two real temporal snapshots of biomedical KGs, defines 10 entity-type-grouped tasks with persistent/added/removed stratification, and reports empirical performance of six CL strategies across four KGE decoders plus additional baselines. No equations, first-principles derivations, or parameter-fitting steps are presented whose outputs are then relabeled as predictions. The central claims (decoder-CL interactions and DistMult-specific separation) are direct observations from the released experiments rather than reductions to self-defined quantities or self-citations. Self-citations, if any, are not load-bearing for any claimed result. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine.Scientific Data, 10(1):67, 2023
work page 2023
-
[2]
A foundation model for clinician-centered drug repurposing.Nature Medicine, 30(12):3601–3613, 2024
Kexin Huang, Payal Chandak, Qianwen Wang, Shreyas Haber, and Marinka Zitnik. A foundation model for clinician-centered drug repurposing.Nature Medicine, 30(12):3601–3613, 2024
work page 2024
-
[3]
Angel Daruna, Mehul Gupta, Mohan Sridharan, and Sonia Chernova. Continual learning of knowledge graph embeddings.IEEE Robotics and Automation Letters, 6(2):1128–1135, 2021
work page 2021
-
[4]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[5]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P Lillicrap, and Gregory Wayne. Experience replay for continual learning. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[6]
Lifelong embedding learning and transfer for growing knowledge graphs
Yuanning Cui, Yuxin Wang, Zequn Sun, Wenqiang Liu, Yiqiao Jiang, Kexin Han, and Wei Hu. Lifelong embedding learning and transfer for growing knowledge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 4218–4226, 2023. 10
work page 2023
-
[7]
Towards continual knowledge graph embedding via incremental distillation
Jiajun Liu, Wenjun Ke, Peng Wang, Ziyu Shang, Jinhua Gao, Guozheng Li, Ke Ji, and Yanhe Liu. Towards continual knowledge graph embedding via incremental distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 8759–8768, 2024
work page 2024
-
[8]
Extended-connectivity fingerprints.Journal of Chemical Information and Modeling, 50(5):742–754, 2010
David Rogers and Mathew Hahn. Extended-connectivity fingerprints.Journal of Chemical Information and Modeling, 50(5):742–754, 2010
work page 2010
-
[9]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In Proceedings of the 34th International Conference on Machine Learning, pages 3987–3995. PMLR, 2017
work page 2017
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Online continual learning with maximally interfered retrieval
Rahaf Aljundi, Lucas Caccia, Eugene Belilovsky, Massimo Caccia, Min Lin, Laurent Charlin, and Tinne Tuytelaars. Online continual learning with maximally interfered retrieval. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[12]
RotatE: Knowledge graph embedding by relational rotation in complex space
Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. RotatE: Knowledge graph embedding by relational rotation in complex space. InProceedings of the 7th International Conference on Learning Representations, 2019
work page 2019
-
[13]
Learning sequence encoders for temporal knowledge graph completion
Alberto García-Durán, Sebastijan Duman ˇci´c, and Mathias Niepert. Learning sequence encoders for temporal knowledge graph completion. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4816–4821, 2018
work page 2018
-
[14]
When Modalities Remember: Continual Learning for Multimodal Knowledge Graphs
Linyu Li, Zhi Jin, Yichi Zhang, Dongming Jin, Yuanpeng He, Haoran Duan, Gadeng Luosang, and Nyima Tashi. When modalities remember: Continual learning for multimodal knowledge graphs.arXiv preprint arXiv:2604.02778, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Translat- ing embeddings for modeling multi-relational data
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. Translat- ing embeddings for modeling multi-relational data. InAdvances in Neural Information Processing Systems, volume 26, 2013
work page 2013
-
[16]
Embedding entities and relations for learning and inference in knowledge bases
Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. Embedding entities and relations for learning and inference in knowledge bases. InProceedings of the 3rd International Conference on Learning Representations, 2015
work page 2015
-
[17]
Fast and continual knowledge graph embedding via incremental LoRA
Jiajun Liu, Wenjun Ke, Peng Wang, Jiahao Wang, Jinhua Gao, Ziyu Shang, Guozheng Li, Zijie Xu, Ke Ji, and Yining Li. Fast and continual knowledge graph embedding via incremental LoRA. InProceedings of the 33rd International Joint Conference on Artificial Intelligence, pages 2159–2167, 2024
work page 2024
-
[18]
Jing Yang, Xinfa Jiang, Xiaowen Jiang, Yuan Gao, Laurence T Yang, Shaojun Zou, and Shundong Yang. From knowledge forgetting to accumulation: Evolutionary relation path passing for lifelong knowledge graph embedding. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1197–1206, 2025
work page 2025
-
[19]
SAGE: Scale- aware gradual evolution for continual knowledge graph embedding
Yifei Li, Lingling Zhang, Hang Yan, Tianzhe Zhao, Zihan Ma, Muye Huang, and Jun Liu. SAGE: Scale- aware gradual evolution for continual knowledge graph embedding. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025
work page 2025
-
[20]
DebiasedKGE: Towards mitigating spurious forgetting in continual knowledge graph embedding
Junlin Zhu, Bo Fu, and Guiduo Duan. DebiasedKGE: Towards mitigating spurious forgetting in continual knowledge graph embedding. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM), 2025
work page 2025
-
[21]
Gaganpreet Jhajj and Fuhua Lin. Elastic weight consolidation for knowledge graph continual learning: An empirical evaluation.arXiv preprint arXiv:2512.01890, 2025
-
[22]
Rethinking continual knowledge graph embedding: Benchmarks and analysis
Tianzhe Zhao, Jiaoyan Chen, Yanchi Ru, Qika Lin, Yuxia Geng, Haiping Zhu, Yudai Pan, and Jun Liu. Rethinking continual knowledge graph embedding: Benchmarks and analysis. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025
work page 2025
-
[23]
Cglb: Benchmark tasks for continual graph learning
Xikun Zhang, Dongjin Song, and Dacheng Tao. Cglb: Benchmark tasks for continual graph learning. In Advances in Neural Information Processing Systems, volume 35, pages 13006–13021, 2022
work page 2022
-
[24]
Daniel Scott Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, and Sergio E Baranzini. Systematic integration of biomedical knowledge prioritizes drugs for repurposing.eLife, 6:e26726, 2017. 11
work page 2017
-
[25]
Tien Dang, Viet Thanh Duy Nguyen, Minh Tuan Le, and Truong-Son Hy. Multimodal contrastive representation learning in augmented biomedical knowledge graphs.arXiv preprint arXiv:2501.01644, 2025
-
[26]
Bridging the gap: Generating a comprehensive biomedical knowledge graph question answering dataset
Xi Yan, Patrick Westphal, Jan Seliger, and Ricardo Usbeck. Bridging the gap: Generating a comprehensive biomedical knowledge graph question answering dataset. InProceedings of the 27th European Conference on Artificial Intelligence (ECAI), volume 392 ofFrontiers in Artificial Intelligence and Applications, pages 1198–1205, 2024
work page 2024
-
[27]
MMKGR: Multi-hop multi-modal knowledge graph reasoning
Shangfei Zheng, Weiqing Wang, Jianfeng Qu, Hongzhi Yin, Wei Chen, and Lei Zhao. MMKGR: Multi-hop multi-modal knowledge graph reasoning. InProceedings of the 39th IEEE International Conference on Data Engineering (ICDE), pages 96–109, 2023
work page 2023
-
[28]
Multi-modal contrastive representation learning for entity alignment
Zhenxi Lin, Ziheng Zhang, Meng Wang, Yinghui Shi, Xian Wu, and Yefeng Zheng. Multi-modal contrastive representation learning for entity alignment. InProceedings of the 29th International Conference on Computational Linguistics, pages 2572–2584, 2022
work page 2022
-
[29]
Mose: Modality split and ensemble for multimodal knowledge graph completion
Yu Zhao, Xiangrui Cai, Yike Wu, Haiwei Zhang, Ying Zhang, Guoqing Zhao, and Ning Jiang. Mose: Modality split and ensemble for multimodal knowledge graph completion. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10527–10536, 2022
work page 2022
-
[30]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8238–8247, 2022
work page 2022
-
[31]
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks
Nan Wu, Stanisław Jastrzebski, Kyunghyun Cho, and Krzysztof J Geras. Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks. InProceedings of the 39th International Conference on Machine Learning, pages 24043–24055. PMLR, 2022
work page 2022
-
[32]
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36(7):3580–3599, 2024
work page 2024
-
[33]
Retrieval-augmented generation for knowledge- intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
work page 2020
-
[34]
Three scenarios for continual learning
Gido M van de Ven and Andreas S Tolias. Three scenarios for continual learning.arXiv preprint arXiv:1904.07734, 2019
work page Pith review arXiv 1904
-
[35]
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Computing for Healthcare, 3(1):1–23, 2021
work page 2021
-
[36]
Modeling relational data with graph convolutional networks
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. InThe Semantic Web: 15th International Conference (ESWC 2018), pages 593–607. Springer, 2018
work page 2018
-
[37]
Complex embeddings for simple link prediction
Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. Complex embeddings for simple link prediction. InProceedings of the 33rd International Conference on Machine Learning, pages 2071–2080, 2016
work page 2071
-
[38]
KG-FIT: Knowledge graph fine-tuning upon open-world knowledge
Pengcheng Jiang, Lang Cao, Cao Xiao, Parminder Bhatia, Jimeng Sun, and Jiawei Han. KG-FIT: Knowledge graph fine-tuning upon open-world knowledge. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[39]
You CAN teach an old dog new tricks! on training knowledge graph embeddings
Daniel Ruffinelli, Samuel Broscheit, and Rainer Gemulla. You CAN teach an old dog new tricks! on training knowledge graph embeddings. InProceedings of the 8th International Conference on Learning Representations, 2020
work page 2020
-
[40]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InAdvances in Neural Information Processing Systems, volume 33, pages 5824–5836, 2020
work page 2020
-
[41]
Matthew Riemer, Ignacio Cases, Robert Ajemian, Miao Liu, Irina Rish, Yuhai Tu, and Gerald Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference. InInternational Conference on Learning Representations, 2019. 12 PrimeKG-CL: A Continual Graph Learning Benchmark on Evolving Biomedical Knowledge Graphs Supplementary M...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.