Recognition: 2 theorem links
· Lean TheoremTIE: Time Interval Encoding for Video Generation over Events
Pith reviewed 2026-05-12 04:22 UTC · model grok-4.3
The pith
TIE encodes time as intervals rather than points inside diffusion transformers, allowing overlapping events to be represented natively in attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within RoPE-compatible bilinear attention, TIE is characterized by Temporal Integrability, which requires an event to aggregate positional evidence over its full duration, and Duration Invariance, which removes the trivial bias toward longer intervals. Under a uniform kernel this characterization yields an efficient closed-form sinc-based solution that preserves the standard attention interface and naturally attenuates boundary noise through interval integration.
What carries the argument
Time Interval Encoding (TIE), a plug-and-play generalization of rotary embeddings obtained from the pair of temporal integrability and duration invariance under a uniform kernel.
If this is right
- Diffusion transformers can now accept prompts that describe concurrent or extended actions without architectural changes.
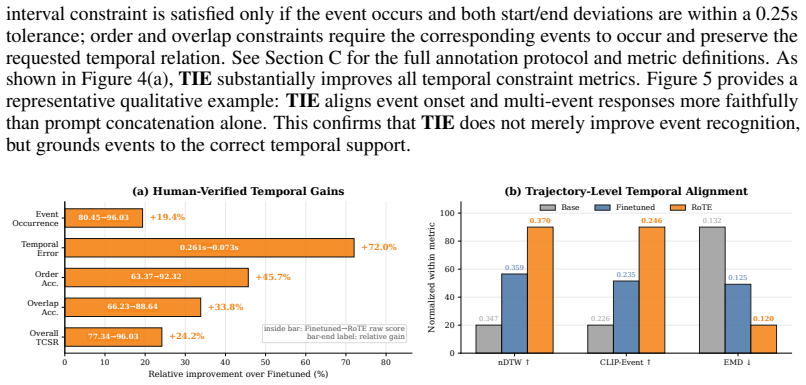
- Temporal boundary error drops from 0.261 s to 0.073 s on the OmniEvents dataset.
- Human-verified temporal constraint satisfaction rises from 77.34 % to 96.03 %.
- Trajectory-level alignment metrics improve while the base model’s visual quality is retained.
- The same attention interface remains unchanged, so TIE can be swapped in as a drop-in replacement.
Where Pith is reading between the lines
- The same interval-first logic could be tested in audio or text generation models that must handle overlapping sound events or narrative timelines.
- Robotics planners that output concurrent actions might benefit from replacing point-wise time encodings with TIE-style intervals.
- An ablation that replaces the uniform kernel with a learned kernel would show whether the closed-form sinc solution is optimal or merely convenient.
Load-bearing premise
The uniform kernel together with the two stated principles is enough to produce a general, artifact-free interval encoding that works across diverse video domains without further tuning.
What would settle it
A controlled evaluation on a held-out set of videos containing many overlapping events in which TIE either fails to raise temporal constraint satisfaction above the point-encoding baseline or introduces measurable drops in visual fidelity.
Figures







read the original abstract
Director-style prompting, robotic action prediction, and interactive video agents demand temporal grounding over concurrent events -- a regime in which 68% of general clips and over 99% of robotics/gameplay clips contain overlapping events, yet existing multi-event generators rest on a single-active-prompt assumption. However, modern video generators, such as Diffusion Transformers (DiT), represent time as discrete points through point-wise positional encodings. This formulation creates a fundamental dimension mismatch: temporally extended intervals and overlapping events are mathematically unrepresentable to the attention mechanism. In this paper, we propose Time Interval Encoding (TIE), a principled, plug-and-play interval-aware generalization of rotary embeddings that elevates time intervals to first-class primitives inside DiT cross-attention. Rather than introducing another heuristic interval embedding, we show that, within RoPE-compatible bilinear attention, TIE is characterized by two basic principles: Temporal Integrability, which requires an event to aggregate positional evidence over its full duration, and Duration Invariance, which removes the trivial bias toward longer intervals. Under a uniform kernel, this characterization yields an efficient closed-form sinc-based solution that preserves the standard attention interface and naturally attenuates boundary noise through interval integration. Empirically, TIE preserves the visual quality of the base DiT model while substantially improving temporal controllability. In our experiments on the OmniEvents dataset, it improves human-verified Temporal Constraint Satisfaction Rate from 77.34% to 96.03% and reduces temporal boundary error from 0.261s to 0.073s, while also improving trajectory-level temporal alignment metrics. The code and dataset are available at https://github.com/MatrixTeam-AI/TIE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Time Interval Encoding (TIE), a plug-and-play generalization of rotary embeddings (RoPE) for Diffusion Transformers (DiT) in video generation. It characterizes TIE via two principles—Temporal Integrability (aggregating positional evidence over an event's full duration) and Duration Invariance (removing bias toward longer intervals)—and derives a closed-form sinc-based encoding under a uniform kernel that integrates into standard bilinear attention while attenuating boundary noise. On the OmniEvents dataset, TIE raises human-verified Temporal Constraint Satisfaction Rate from 77.34% to 96.03%, reduces boundary error from 0.261s to 0.073s, and improves trajectory alignment metrics while preserving base-model visual quality; code and data are released.
Significance. If the central characterization holds, TIE supplies a principled, parameter-free interval primitive for attention-based video models, directly addressing the point-wise time representation mismatch that prevents native handling of overlapping events (common in 68%+ of clips). The open release of code and the OmniEvents dataset is a clear strength for reproducibility. The approach could meaningfully advance controllable generation for robotics, gameplay, and director-style prompting.
major comments (3)
- [§3] §3 (Method): The manuscript states that the two principles plus a uniform kernel yield the closed-form sinc TIE, but provides no comparative derivation or argument showing why the uniform kernel is the minimal or unique choice that satisfies Temporal Integrability and Duration Invariance without introducing domain-specific artifacts; alternatives (e.g., Gaussian or triangular kernels) are not examined.
- [§4] §4 (Experiments): All quantitative results and human evaluations are confined to the OmniEvents dataset; no cross-dataset tests, ablations on varying event densities, motion complexity, or frame rates are reported, leaving the claim of general, artifact-free generalization unsupported.
- [§3.3] §3.3 / Eq. (7)–(9): The claim that interval integration “naturally attenuates boundary noise” is asserted from the sinc form, yet no separate quantitative boundary-noise metric, ablation, or visualization isolates this effect from the overall TCS-rate and boundary-error gains.
minor comments (2)
- [Figures 3–4] Figure 3 and 4 captions should explicitly state the number of samples and the exact human-evaluation protocol (e.g., number of raters, inter-rater agreement) rather than referring only to “visual quality.”
- [Eq. (10)] Notation: the transition from the continuous integral form to the discrete sinc implementation in Eq. (10) would benefit from an explicit discretization step or reference to the sampling rate used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment point-by-point below with clarifications and commitments to revisions that strengthen the manuscript without misrepresenting the current results.
read point-by-point responses
-
Referee: [§3] §3 (Method): The manuscript states that the two principles plus a uniform kernel yield the closed-form sinc TIE, but provides no comparative derivation or argument showing why the uniform kernel is the minimal or unique choice that satisfies Temporal Integrability and Duration Invariance without introducing domain-specific artifacts; alternatives (e.g., Gaussian or triangular kernels) are not examined.
Authors: The uniform kernel is the minimal choice that yields a parameter-free closed-form solution under the two principles: its constant weight allows direct integration over the interval to produce the sinc function while exactly satisfying Duration Invariance (normalization removes length bias) and Temporal Integrability (full-duration aggregation). Other kernels (Gaussian, triangular) would either require additional hyperparameters or lose the closed-form property, introducing artifacts or breaking RoPE compatibility. We will revise §3 to include an explicit derivation subsection showing this minimality and briefly contrast the uniform case with alternatives, noting that empirical comparison of kernels is reserved for future work given the computational cost of retraining DiT variants. revision: partial
-
Referee: [§4] §4 (Experiments): All quantitative results and human evaluations are confined to the OmniEvents dataset; no cross-dataset tests, ablations on varying event densities, motion complexity, or frame rates are reported, leaving the claim of general, artifact-free generalization unsupported.
Authors: OmniEvents was constructed precisely to isolate the multi-event temporal constraint problem that standard datasets do not emphasize. Because TIE is a plug-and-play replacement for positional encodings inside existing DiT attention, the architecture-level generalization argument holds, yet we agree broader empirical support is desirable. In the revision we will add qualitative results and limited quantitative checks on at least one additional public video dataset (e.g., a subset of WebVid or a robotics clip collection) together with an ablation on event density, to better substantiate the generalization claim. revision: yes
-
Referee: [§3.3] §3.3 / Eq. (7)–(9): The claim that interval integration “naturally attenuates boundary noise” is asserted from the sinc form, yet no separate quantitative boundary-noise metric, ablation, or visualization isolates this effect from the overall TCS-rate and boundary-error gains.
Authors: The reported boundary-error reduction (0.261 s → 0.073 s) and TCS improvement already reflect the net effect of interval integration. The sinc kernel’s low-pass character theoretically suppresses high-frequency boundary discontinuities; we will strengthen the presentation by adding a dedicated figure in §3.3 that visualizes per-boundary attention weights and error histograms with/without TIE, thereby isolating the attenuation mechanism from the aggregate metrics. revision: yes
Circularity Check
No circularity: derivation proceeds from stated principles plus kernel choice to closed-form solution without reduction to inputs.
full rationale
The paper states two principles (Temporal Integrability and Duration Invariance) that characterize TIE inside RoPE-compatible bilinear attention, then shows that a uniform kernel yields a closed-form sinc solution. This is a forward derivation from assumptions to result rather than any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or text in the abstract or described chain exhibit the specific reduction required to flag circularity. The uniform kernel is an explicit modeling choice whose consequences are derived, not smuggled in via prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporal Integrability: an event must aggregate positional evidence over its full duration
- domain assumption Duration Invariance: the encoding must remove trivial bias toward longer intervals
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under a uniform kernel, this characterization yields an efficient closed-form sinc-based solution... Ai,c,r = sinc(θir) [cos(θic) −sin(θic); sin(θic) cos(θic)]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Temporal Integrability... Duration Invariance... TIE(k, I) = 1/C(μ_I) E_τ∼μ_I [RoPE(k, τ)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for Physical AI, 2025
NVIDIA: Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Huffman, Pooya Jannaty, 12 Ji...
work page 2025
-
[2]
Align your latents: high-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: high-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[3]
Jake Bruce, Michael D. Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Maria Elis- abeth Bechtle, Feryal Behbahani, Stephanie C. Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, N...
work page 2024
-
[4]
StoryBench: A Multifaceted Benchmark for Continuous Story Visualization
Emanuele Bugliarello, Hernan Moraldo, Ruben Villegas, Mohammad Babaeizadeh, Mohammad Taghi Saffar, Han Zhang, Dumitru Erhan, Vittorio Ferrari, Pieter-Jan Kindermans, and Paul V oigtlaender. StoryBench: A Multifaceted Benchmark for Continuous Story Visualization. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[5]
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. DiTCtrl: exploring attention control in multi-modal diffusion trans- former for tuning-free multi-prompt longer video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[6]
arXiv preprint arXiv:2305.13840 (2023)
Weifeng Chen, Jie Wu, Pan Xie, Hefeng Wu, Jiashi Li, Xin Xia, Xuefeng Xiao, and Liang Lin. Control-A-Video: controllable text-to-video generation with diffusion models.arXiv preprint arXiv:2305.13840, 2023
-
[7]
AgiBot World Colosseum contributors. AgiBot world colosseum. https://github.com/ OpenDriveLab/AgiBot-World, 2024
work page 2024
-
[8]
Tenenbaum, Dale Schuurmans, and Pieter Abbeel
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[9]
AnimateDiff: animate your personalized text-to-image diffu- sion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. AnimateDiff: animate your personalized text-to-image diffu- sion models without specific tuning. InInternational Conference on Learning Representations, 2024
work page 2024
-
[10]
VideoScore: building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, Kai Wang, Quy Duc Do, Yuansheng Ni, Bohan Lyu, Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Yuchen Lin, and Wenhu Chen. VideoScore: building automatic metrics to simulate fine-grained human feedback for video generation. In Procee...
work page 2024
-
[11]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, Günter Klambauer, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[12]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: a generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023. 13
work page internal anchor Pith review arXiv 2023
-
[13]
EnerVerse: envisioning embodied future space for robotics manipulation
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yue Hu, Yue Liao, Peng Gao, Hongsheng Li, Maoqing Yao, et al. EnerVerse: envisioning embodied future space for robotics manipulation. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[14]
VBench: comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[15]
V ACE: all-in- one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. V ACE: all-in- one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
work page 2025
-
[16]
Diederik P. Kingma and Jimmy Ba. Adam: a method for stochastic optimization. InInternational Conference on Learning Representations, 2015
work page 2015
-
[17]
MultiSports: a multi-person video dataset of spatio-temporally localized sports actions
Yixuan Li, Lei Chen, Runyu He, Zhenzhi Wang, Gangshan Wu, and Limin Wang. MultiSports: a multi-person video dataset of spatio-temporally localized sports actions. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[18]
VideoDirectorGPT: consistent multi- scene video generation via LLM-guided planning
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. VideoDirectorGPT: consistent multi- scene video generation via LLM-guided planning. InProceedings of the First Conference on Language Modeling, 2024
work page 2024
-
[19]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[20]
VDT: general-purpose video diffusion transformers via mask modeling
Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. VDT: general-purpose video diffusion transformers via mask modeling. InInternational Conference on Learning Representations, 2024
work page 2024
-
[21]
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
work page 2025
-
[22]
MEVG: multi-event video generation with text-to-video models
Gyeongrok Oh, Jaehwan Jeong, Sieun Kim, Wonmin Byeon, Jinkyu Kim, Sungwoong Kim, and Sangpil Kim. MEVG: multi-event video generation with text-to-video models. InEuropean Conference on Computer Vision. Springer, 2024
work page 2024
-
[23]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[24]
FreeNoise: tuning-free longer video diffusion via noise rescheduling
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, and Ziwei Liu. FreeNoise: tuning-free longer video diffusion via noise rescheduling. InInternational Conference on Learning Representations, 2024
work page 2024
- [25]
-
[26]
Hiroaki Sakoe and Seibi Chiba. Dynamic programming algorithm optimization for spoken word recognition.IEEE Transactions on Acoustics, Speech, and Signal Processing, 1978
work page 1978
-
[27]
Make-A-Video: text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-A-Video: text-to-video generation without text-video data. InInternational Conference on Learning Representations, 2023
work page 2023
-
[28]
Roformer: Enhanced transformer with rotary position embedding.Neurocom- puting, 2024
Jianlin Su et al. Roformer: Enhanced transformer with rotary position embedding.Neurocom- puting, 2024
work page 2024
-
[29]
Towards accurate generative models of video: a new metric and challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: a new metric and challenges. ArXiv, 2018. 14
work page 2018
-
[30]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InInternational Conference on Learning Representations, 2025
work page 2025
-
[31]
Phenaki: variable length video generation from open-domain textual descriptions
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: variable length video generation from open-domain textual descriptions. InInternational Conference on Learning Representations, 2023
work page 2023
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Fu-Yun Wang, Wenshuo Chen, Guanglu Song, Han-Jia Ye, Yu Liu, and Hongsheng Li. Gen- L-Video: multi-text to long video generation via temporal co-denoising.arXiv preprint arXiv:2305.18264, 2023
-
[34]
VideoComposer: compositional video synthesis with motion controllability
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. VideoComposer: compositional video synthesis with motion controllability. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[35]
Yiping Wang, Xuehai He, Kuan Wang, Luyao Ma, Jianwei Yang, Shuohang Wang, Si- mon Shaolei Du, and Yelong Shen. Is your world simulator a good story presenter? a consecutive events-based benchmark for future long video generation.arXiv preprint arXiv:2412.16211, 2024
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, F. Xia, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[37]
Mind the time: temporally-controlled multi-event video generation
Ziyi Wu, Aliaksandr Siarohin, Willi Menapace, Ivan Skorokhodov, Yuwei Fang, Varnith Chordia, Igor Gilitschenski, and Sergey Tulyakov. Mind the time: temporally-controlled multi-event video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[38]
Zhifei Xie, Daniel Tang, Dingwei Tan, Jacques Klein, Tegawend F Bissyand, and Saad Ezzini. DreamFactory: pioneering multi-scene long video generation with a multi-agent framework. arXiv preprint arXiv:2408.11788, 2024
-
[39]
Learning interactive real-world simulators
Sherry Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In International Conference on Learning Representations, 2024
work page 2024
-
[40]
Direct-a-Video: customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-Video: customized video generation with user-directed camera movement and object motion. InACM SIGGRAPH 2024 Conference Papers, 2024
work page 2024
-
[41]
LongLive: real-time interactive long video generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. LongLive: real-time interactive long video generation. InInternational Conference on Learning Representations, 2026
work page 2026
-
[42]
CogVideoX: text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, 2025. 15
work page 2025
-
[43]
NUW A-XL: diffusion over diffusion for eXtremely long video generation
Shengming Yin, Chenfei Wu, Huan Yang, Jianfeng Wang, Xiaodong Wang, Minheng Ni, Zhengyuan Yang, Linjie Li, Shuguang Liu, Fan Yang, Jianlong Fu, Ming Gong, Lijuan Wang, Zicheng Liu, Houqiang Li, and Nan Duan. NUW A-XL: diffusion over diffusion for eXtremely long video generation. InProceedings of the 61st Annual Meeting of the Association for Computational...
work page 2023
-
[44]
TS-Attn: temporal-wise separable attention for multi-event video generation
Hongyu Zhang, Yufan Deng, Zilin Pan, Peng-Tao Jiang, Bo Li, Qibin Hou, Zhiyang Dou, Zhen Dong, and Daquan Zhou. TS-Attn: temporal-wise separable attention for multi-event video generation. InInternational Conference on Learning Representations, 2026
work page 2026
-
[45]
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Shu, Yatian Pang, Feilong Tang, Qifeng Chen, Harry Yang, et al. VideoGen-of-Thought: step-by-step generating multi-shot video with minimal manual intervention.arXiv preprint arXiv:2412.02259, 2024
-
[46]
Pexels-400k: a large-scale dataset for video and image generation
Zhou Zhi-Min. Pexels-400k: a large-scale dataset for video and image generation. https: //huggingface.co/datasets/jovianzm/Pexels-400k, 2023
work page 2023
-
[47]
Robo- Dreamer: learning compositional world models for robot imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robo- Dreamer: learning compositional world models for robot imagination. InProceedings of the International Conference on Machine Learning, 2024
work page 2024
-
[48]
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. IRASim: a fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. A Details and Proofs for TIE A.1 Proofs for Section 3 This subsection provides the full formalization and proofs for the principle-based chara...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.