Recognition: 2 theorem links
· Lean TheoremWhere Does Long-Context Supervision Actually Go? Effective-Context Exposure Balancing
Pith reviewed 2026-05-12 03:48 UTC · model grok-4.3
The pith
Long-context adaptation improves when training gives extra weight to target tokens whose effective context is long rather than short.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
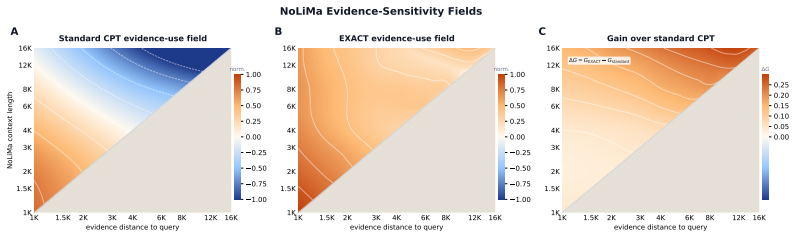
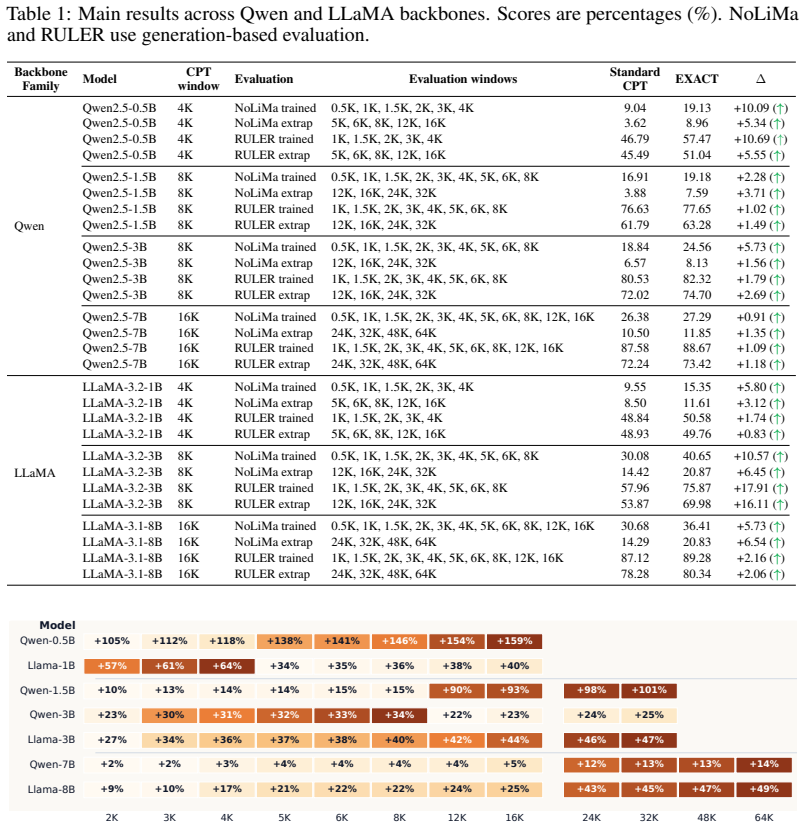
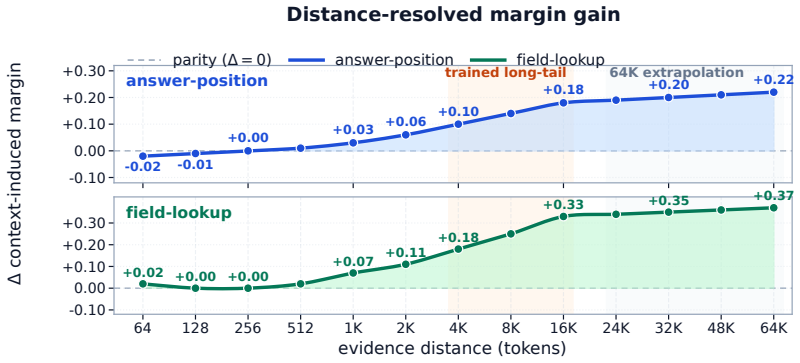
The central claim is that long-context adaptation in language models is determined by how strongly training supervises predictions that use long effective contexts. The EXACT objective corrects the natural imbalance by assigning higher loss weight to targets whose effective context length falls in the long tail, measured by inverse frequency. This produces consistent lifts on NoLiMa and RULER for both trained and extrapolated lengths, with the largest effects when evidence must be retrieved across thousands of tokens, while standard QA and reasoning tasks remain stable.
What carries the argument
EXACT, the supervision-allocation objective that reweights each training target by the inverse frequency of its effective context length in the long tail of the data distribution.
If this is right
- All 28 trained and extrapolated comparisons on NoLiMa and RULER show improvement.
- Gains are largest when the supporting evidence lies thousands of tokens away from the target.
- Standard QA and reasoning benchmarks exhibit no degradation.
- The pattern holds across Qwen2.5-0.5B and LLaMA-3.2-3B configurations.
Where Pith is reading between the lines
- Future long-context training runs could prioritize packing strategies that increase the share of long effective-context examples.
- The same inverse-frequency reweighting idea might be tested in non-text sequence tasks where context length also varies.
- Hardware budgets might be redirected from ever-longer context windows toward more careful loss weighting on existing data.
Load-bearing premise
The observed gains are produced by the effective-context reweighting itself rather than by incidental shifts in training dynamics or data distribution.
What would settle it
Run the same training setup but replace the inverse-frequency weights with uniform weights and check whether the gains on long-context benchmarks disappear while short-context results stay the same.
Figures


read the original abstract
Long-context adaptation is often viewed as window scaling, but this misses a token-level supervision mismatch: in packed training with document masking, each target token's effective context remains short. We introduce EXACT, a supervision-allocation objective that assigns extra weight to long effective-context targets by inverse frequency within the long tail. Across seven Qwen/LLaMA CPT configurations, EXACT improves all 28 trained/extrapolated NoLiMa and RULER comparisons. On Qwen2.5-0.5B, NoLiMa improves by +10.09 (trained) and +5.34 (extrapolated); RULER by +10.69 and +5.55. On LLaMA-3.2-3B, RULER improves by +17.91 and +16.11. Standard QA/reasoning are preserved (+0.24 macro change across six benchmarks). A distance-resolved probe shows gains arise when evidence is thousands of tokens away, while short cases remain unchanged. Results support a supervision-centric thesis: long-context adaptation depends on how strongly training supervises long-context predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that long-context adaptation is bottlenecked by a token-level supervision mismatch in packed training with document masking, where target tokens have short effective context. It introduces EXACT, a reweighting objective that boosts supervision weight on long effective-context targets via inverse frequency in the long tail. Across seven Qwen/LLaMA continued-pretraining configurations, EXACT yields consistent gains on all 28 NoLiMa and RULER comparisons (e.g., +10.09 NoLiMa and +10.69 RULER on Qwen2.5-0.5B trained; +17.91 RULER on LLaMA-3.2-3B), with a distance-resolved probe showing benefits concentrated on distant evidence while short-context cases are unchanged; standard QA/reasoning benchmarks remain stable.
Significance. If the reported gains are causally attributable to the effective-context reweighting, the work offers a supervision-centric alternative to window-scaling approaches for long-context adaptation. The consistent positive deltas across trained and extrapolated settings, plus the distance-resolved probe, provide concrete evidence that could shift research focus toward loss allocation rather than solely data or architecture scaling. The preservation of general capabilities is a practical strength.
major comments (1)
- [Experiments and Results] The central thesis—that performance lifts arise specifically because EXACT increases supervision weight on long effective-context targets—requires isolating this mechanism from incidental effects of any reweighting on loss magnitude, gradient norms, or optimization trajectory. No such controls (e.g., constant-loss reweighting baselines or gradient-statistic-matched ablations) are described in the experimental setup or results sections, leaving open the possibility that gains stem from altered training dynamics rather than the context-length dependence of the weights.
minor comments (1)
- [Abstract] The abstract and results would benefit from explicit reporting of statistical significance or variance across the 28 comparisons to strengthen the claim of consistent improvement.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation for major revision. We address the concern regarding experimental controls to isolate the mechanism of EXACT.
read point-by-point responses
-
Referee: The central thesis—that performance lifts arise specifically because EXACT increases supervision weight on long effective-context targets—requires isolating this mechanism from incidental effects of any reweighting on loss magnitude, gradient norms, or optimization trajectory. No such controls (e.g., constant-loss reweighting baselines or gradient-statistic-matched ablations) are described in the experimental setup or results sections, leaving open the possibility that gains stem from altered training dynamics rather than the context-length dependence of the weights.
Authors: We acknowledge that the manuscript does not include explicit controls such as constant-loss reweighting baselines to rule out generic effects of reweighting on optimization. However, the distance-resolved analysis in the paper shows that improvements occur selectively for long-distance evidence retrieval while short-context performance is unaffected. This pattern is inconsistent with broad changes in loss magnitude or gradient norms, which would likely impact all cases uniformly. To further strengthen the causal attribution, we will incorporate a uniform reweighting baseline (assigning weights without context-length dependence but preserving overall loss scale) in the revised manuscript. revision: yes
Circularity Check
Objective defined from training-data frequencies; no benchmark tuning evident
full rationale
The EXACT weighting rule is constructed directly from inverse-frequency statistics of effective-context lengths computed on the training corpus itself. The reported gains on NoLiMa and RULER are measured after applying the fixed rule and are not inputs to its definition or tuning. No self-citation chain, uniqueness theorem, or ansatz smuggling is required for the central claim, and the derivation does not reduce any prediction to a fitted parameter by construction. This yields only a minor (score-2) observation that the method is data-driven rather than result-driven.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
EXACT groups target tokens by logarithmic effective-context buckets: [0,7],[8,15],...,[2048,4095],... Inside this tail, EXACT forms the tail-local bucket probability, inverse-frequency score... wb = 1 + α rb / r̄
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901,
work page 2023
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Yuze He, Ji Qi, Lei Hou, Jie Tang, Yuxiao Dong, and Juanzi Li. LongAlign: A recipe for long context alignment of large language models.arXiv preprint arXiv:2401.18058, 2024a. Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingu...
-
[3]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023a. Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. LongLoRA: Efficient fine-tuning of long-context large language models.arXiv preprint a...
work page internal anchor Pith review arXiv 1904
-
[4]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794,
work page internal anchor Pith review arXiv 2009
-
[5]
Free dolly: Introducing the world’s first truly open instruction-tuned llm
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm. https://www.databricks.com/blog/2023/04/12/ dolly-first-open-commercially-viable-instruction-tuned-llm ,
work page 2023
-
[6]
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V
Accessed: 2023-06-30. Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V . Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics,
work page 2023
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
LongNet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. LongNet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
-
[9]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. LongRoPE: Extending LLM context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753,
work page internal anchor Pith review arXiv
-
[10]
11 Zican Dong, Tianyi Tang, Junyi Li, Wayne Xin Zhao, and Ji-Rong Wen. Bamboo: A comprehensive benchmark for evaluating long text modeling capacities of large language models. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 2086–2099,
work page 2024
-
[11]
What is wrong with perplexity for long-context language modeling?arXiv preprint arXiv:2410.23771,
Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, and Yisen Wang. What is wrong with perplexity for long-context language modeling?arXiv preprint arXiv:2410.23771,
-
[12]
Data engineering for scaling language models to 128K context.arXiv preprint arXiv:2402.10171, 2024
Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. Data engineering for scaling language models to 128k context.arXiv preprint arXiv:2402.10171,
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lm-infinite: Zero-shot extreme length generalization for large language models
Chi Han, Qifan Wang, Hao Peng, Wenhan Xiong, Yu Chen, Heng Ji, and Sinong Wang. Lm-infinite: Zero-shot extreme length generalization for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 3991–4008,
work page 2024
-
[15]
Token weighting for long-range language modeling
Falko Helm, Nico Daheim, and Iryna Gurevych. Token weighting for long-range language modeling. arXiv preprint arXiv:2503.09202,
-
[16]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Jia Fei, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv preprint arXiv:2401.01325 (2024)
Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. Llm maybe longlm: Self-extend llm context window without tuning.arXiv preprint arXiv:2401.01325,
-
[18]
Marzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit Iyyer. One thousand and one pairs: A “novel” challenge for long-context language models.arXiv preprint arXiv:2406.16264,
-
[19]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near- infinite context.arXiv preprint arXiv:2310.01889,
work page internal anchor Pith review arXiv
-
[20]
Nolima: Long-context evaluation beyond literal matching.arXiv preprint arXiv:2502.05167,
12 Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Seunghyun Yoon, and Hinrich Schütze. NoLiMa: Long-context evaluation beyond literal matching.arXiv preprint arXiv:2502.05167,
-
[21]
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143,
-
[22]
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. OpenWebMath: An open dataset of high-quality mathematical web text.arXiv preprint arXiv:2310.06786,
-
[23]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071,
work page internal anchor Pith review arXiv
-
[24]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review arXiv
-
[25]
URL https://arxiv.org/abs/2412.15115. Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[26]
Zeroscrolls: A zero-shot bench- mark for long text understanding
Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. Zeroscrolls: A zero-shot bench- mark for long text understanding. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 7977–7989,
work page 2023
-
[27]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
work page 2020
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Helmet: How to evaluate long-context language models effectively and thoroughly, 2025
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. HELMET: How to evaluate long-context language models effectively and thoroughly.arXiv preprint arXiv:2410.02694,
-
[31]
The only intended difference is the per-token loss weighting rule
14 A CPT Corpus Construction Details All reported standard-CPT andEXACTcomparisons are constructed as paired runs: within a backbone and CPT stage, the compared models share the same packed stream, document-boundary mask, train/validation split, token budget, optimizer schedule, QA-SFT corpus, and evaluation protocol. The only intended difference is the p...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.