Recognition: 2 theorem links
· Lean TheoremHigher Resolution, Better Generalization: Unlocking Visual Scaling in Deep Reinforcement Learning
Pith reviewed 2026-05-12 05:24 UTC · model grok-4.3
The pith
Higher-resolution visual inputs improve deep RL performance and generalization when the network architecture decouples parameter count from resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
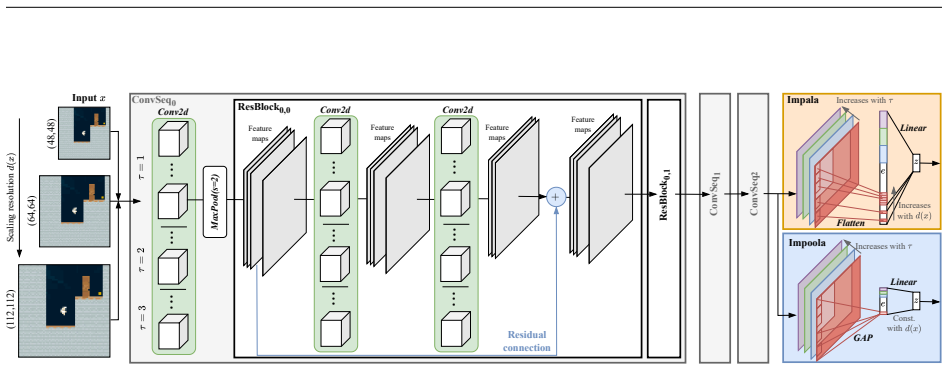
The central claim is that the Impala encoder's flattening operation ties parameter count to resolution squared and therefore cannot exploit higher-resolution observations, while the Impoola architecture's global average pooling removes this dependence, unlocking consistent performance and generalization improvements that reach 28 percent over Impala at matched best conditions, most strongly in environments requiring perception of small or distant objects.
What carries the argument
The Impoola architecture, which substitutes global average pooling for the flattening operation used in the Impala encoder to keep parameter count independent of input resolution.
If this is right
- Performance and generalization improvements are strongest in environments that require precise perception of small or distant objects.
- Gradient saliency analysis shows policies develop more spatially localized visual attention at higher resolutions.
- The approach challenges the standard practice of aggressive input downsampling in visual deep RL.
- Releasing the Procgen-HD benchmark enables systematic study of resolution scaling effects.
Where Pith is reading between the lines
- Low-resolution training conventions in existing benchmarks may be understating the capabilities of visual RL policies.
- Resolution-independent encoders could be paired with other scaling methods such as wider networks or more training data for additive benefits.
- The same architectural change may improve sample efficiency in real-world vision-based control tasks that naturally supply high-resolution sensor data.
Load-bearing premise
That performance gains arise specifically from the architecture's ability to leverage additional visual detail at higher resolutions rather than from differences in training dynamics or environment selection.
What would settle it
A controlled experiment in which raising resolution with Impoola produces no performance gain or produces worse saliency localization than the same architecture at lower resolution.
Figures




















read the original abstract
Pixel-based deep reinforcement learning agents are typically trained on heavily downsampled visual observations, a convention inherited from early benchmarks rather than grounded in principled design. In this work, we show that observation resolution is a critical yet overlooked variable for policy learning: higher-resolution inputs can substantially improve both performance and generalization, provided the network architecture can process them effectively. We find that the widely used Impala encoder, which flattens spatial features into a vector, suffers from quadratic parameter growth as resolution increases and fails to leverage the additional visual detail. Replacing this operation with global average pooling, as in the Impoola architecture, decouples parameter count from resolution and yields consistent improvements across resolutions and network widths - at their respective best conditions, visual scaling unlocks a 28 % performance gain for Impoola over Impala. These gains are strongest in environments that require precise perception of small or distant objects, and gradient saliency analysis confirms that the underlying mechanism is a more spatially localized visual attention of the policy at higher resolutions. Our results challenge the prevailing practice of aggressive input downsampling and position resolution-independent architectures as a simple, effective path toward scalable visual deep RL. To facilitate future research on resolution scaling in deep RL, we publicly release the open-source code for the Procgen-HD benchmark: https://github.com/raphajaner/procgen-hd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that higher-resolution visual observations can substantially improve performance and generalization in deep RL, but only if the network architecture avoids quadratic parameter growth with resolution. The standard Impala encoder flattens spatial features, causing parameter count to scale with H×W; the proposed Impoola architecture replaces this with global average pooling, decoupling parameters from resolution. Experiments on the released Procgen-HD benchmark show consistent gains across resolutions and widths, culminating in a 28% performance improvement for Impoola over Impala at each architecture's respective best conditions. Gains are largest in environments requiring perception of small or distant objects, and gradient saliency maps indicate that higher resolutions produce more spatially localized policy attention.
Significance. If the performance gains can be shown to arise specifically from better utilization of visual detail rather than from differences in effective model capacity, the result would be significant: it would challenge the long-standing convention of aggressive downsampling in visual RL benchmarks and identify a minimal architectural change that enables resolution scaling. The public release of the Procgen-HD benchmark and associated code is a clear strength that supports reproducibility and future work on this dimension.
major comments (2)
- [Abstract] Abstract: the 28% gain is reported only 'at their respective best conditions.' Because Impala's first fully-connected layer receives a flattened feature map whose size grows quadratically with spatial resolution while Impoola's global-average-pooled input size is resolution-independent, the best width for Impala at high resolution is necessarily smaller than the best width for Impoola. Without an explicit fixed-width or fixed-parameter-count control, it is impossible to determine how much of the reported gap is attributable to resolution scaling versus to the capacity difference that the architecture change itself creates.
- [Experimental results] Experimental results (presumably §4 or §5): the manuscript states that gains are 'consistent across resolutions and network widths,' yet the only headline number is the 28% figure obtained at unmatched best conditions. A table or figure that reports performance for both architectures at identical widths (or identical total parameter counts) across the same set of resolutions is required to isolate the claimed visual-scaling effect.
minor comments (1)
- [Abstract] The abstract refers to 'Procgen-HD' without defining how the environments or observation preprocessing differ from the original Procgen suite; a short methods paragraph or table should make this explicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the contribution of higher-resolution observations from capacity differences. We agree that matched-width and matched-parameter-count comparisons would strengthen the evidence for visual scaling and will revise the manuscript to include them. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 28% gain is reported only 'at their respective best conditions.' Because Impala's first fully-connected layer receives a flattened feature map whose size grows quadratically with spatial resolution while Impoola's global-average-pooled input size is resolution-independent, the best width for Impala at high resolution is necessarily smaller than the best width for Impoola. Without an explicit fixed-width or fixed-parameter-count control, it is impossible to determine how much of the reported gap is attributable to resolution scaling versus to the capacity difference that the architecture change itself creates.
Authors: We appreciate this clarification. The manuscript already varies network width for both architectures across resolutions and reports consistent gains (Section 4.2 and Figure 3), but the 28% headline figure is computed at each architecture's individually optimized width. To directly address the capacity confound, we will add a new table in the revised manuscript that reports performance for Impala and Impoola at identical widths (e.g., widths 1, 2, 4) and at comparable total parameter counts across the same resolution settings. This will allow readers to separate the effects of resolution scaling from the architectural change in parameter scaling. revision: yes
-
Referee: [Experimental results] Experimental results (presumably §4 or §5): the manuscript states that gains are 'consistent across resolutions and network widths,' yet the only headline number is the 28% figure obtained at unmatched best conditions. A table or figure that reports performance for both architectures at identical widths (or identical total parameter counts) across the same set of resolutions is required to isolate the claimed visual-scaling effect.
Authors: We agree that a single, clearly presented matched-capacity comparison is needed to isolate the visual-scaling claim. While the current experiments already sweep widths and show gains at multiple matched widths (not only at best conditions), these results are distributed across figures rather than consolidated. We will add an explicit table (or extended figure) in the revision that tabulates both architectures side-by-side at fixed widths and fixed parameter budgets for each resolution, thereby providing the direct control the referee requests. revision: yes
Circularity Check
No circularity; purely empirical architecture comparison
full rationale
The paper reports direct experimental results from training RL agents on the released Procgen-HD benchmark, comparing Impala (flattening) versus Impoola (global average pooling) encoders at varying resolutions and widths. The 28% performance gain is a measured outcome under 'respective best conditions,' not a quantity derived from any equation, fitted parameter, or self-referential definition. No mathematical derivation chain, uniqueness theorem, ansatz, or self-citation load-bearing step appears in the abstract or described claims. The result is externally falsifiable via the open-source code and benchmark, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Impoola architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Replacing this operation with global average pooling, as in the Impoola architecture, decouples parameter count from resolution
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
visual scaling unlocks a 28 % performance gain for Impoola over Impala
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[3]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
International conference on machine learning , pages=
Leveraging procedural generation to benchmark reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[5]
The benchmark lottery , author=. arXiv preprint arXiv:2107.07002 , year=
- [6]
-
[7]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[8]
Conference on robot learning , pages=
Scalable deep reinforcement learning for vision-based robotic manipulation , author=. Conference on robot learning , pages=. 2018 , organization=
work page 2018
-
[9]
2019 international conference on robotics and automation (ICRA) , pages=
Learning to drive in a day , author=. 2019 international conference on robotics and automation (ICRA) , pages=. 2019 , organization=
work page 2019
-
[10]
State representation learning for control: An overview , volume=
Lesort, Timothée and Díaz-Rodríguez, Natalia and Goudou, Jean-Frano̧is and Filliat, David , year=. State representation learning for control: An overview , volume=. doi:10.1016/j.neunet.2018.07.006 , journal=
-
[11]
Network in network.CoRR, abs/1312.4400, 2013
Network in network , author=. arXiv preprint arXiv:1312.4400 , year=
-
[12]
IEEE/CVF conference on computer vision and pattern recognition , pages=
A convnet for the 2020s , author=. IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
International conference on learning representations , year=
Understanding and Preventing Capacity Loss in Reinforcement Learning , author=. International conference on learning representations , year=
-
[14]
Journal of Artificial Intelligence Research , volume=
Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents , author=. Journal of Artificial Intelligence Research , volume=
-
[15]
Human-level control through deep reinforcement learning , author=. Nature , year=
-
[16]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[17]
International journal of computer vision , volume=
Imagenet large scale visual recognition challenge , author=. International journal of computer vision , volume=. 2015 , publisher=
work page 2015
-
[18]
International conference on machine learning , pages=
The dormant neuron phenomenon in deep reinforcement learning , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[19]
IEEE conference on computer vision and pattern recognition , pages=
Going deeper with convolutions , author=. IEEE conference on computer vision and pattern recognition , pages=
-
[20]
International conference on machine learning , pages=
Efficientnet: Rethinking model scaling for convolutional neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[21]
International conference on machine learning , pages=
Efficientnetv2: Smaller models and faster training , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[22]
Advances in neural information processing systems , volume=
Fixing the train-test resolution discrepancy , author=. Advances in neural information processing systems , volume=
-
[23]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[24]
Conference on neural information processing systems datasets and benchmarks Track (Round 2) , year=
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research , author=. Conference on neural information processing systems datasets and benchmarks Track (Round 2) , year=
-
[25]
Bender and Alex Hanna and Amandalynne Paullada , booktitle=
Inioluwa Deborah Raji and Emily Denton and Emily M. Bender and Alex Hanna and Amandalynne Paullada , booktitle=
-
[26]
IEEE conference on computer vision and pattern recognition , pages=
Feature pyramid networks for object detection , author=. IEEE conference on computer vision and pattern recognition , pages=
-
[27]
Advances in neural information processing systems , publisher =
ImageNet Classification with Deep Convolutional Neural Networks , author =. Advances in neural information processing systems , publisher =
-
[28]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Penatti, Otávio A. B. and Nogueira, Keiller and dos Santos, Jefersson A. , booktitle=. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? , year=
-
[30]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
work page 2019
-
[31]
arXiv preprint arXiv:1711.05225 , year=
Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning , author=. arXiv preprint arXiv:1711.05225 , year=
-
[32]
Dermatologist-level classification of skin cancer with deep neural networks , author=. Nature , volume=. 2017 , publisher=
work page 2017
-
[33]
Journal of Machine Learning Research , volume=
End-to-end training of deep visuomotor policies , author=. Journal of Machine Learning Research , volume=
-
[34]
Learning to perceive and act by trial and error , author=. Machine Learning , volume=. 1991 , publisher=
work page 1991
-
[35]
Journal of artificial intelligence research , volume=
The arcade learning environment: An evaluation platform for general agents , author=. Journal of artificial intelligence research , volume=
-
[36]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
work page 2020
-
[37]
Gabriel Dulac-Arnold, Daniel Mankowitz, and Todd Hester
Challenges of real-world reinforcement learning , author=. arXiv preprint arXiv:1904.12901 , year=
-
[38]
The International Journal of Robotics Research , volume=
How to train your robot with deep reinforcement learning: lessons we have learned , author=. The International Journal of Robotics Research , volume=. 2021 , publisher=
work page 2021
-
[39]
International conference on learning representations , year=
Observational Overfitting in Reinforcement Learning , author=. International conference on learning representations , year=
-
[40]
arXiv preprint arXiv:1804.06893 , year=
A study on overfitting in deep reinforcement learning , author=. arXiv preprint arXiv:1804.06893 , year=
-
[41]
AAAI workshop: Learning for general competency in video games , year=
Frame Skip Is a Powerful Parameter for Learning to Play Atari , author=. AAAI workshop: Learning for general competency in video games , year=
-
[42]
dm\_control: Software and tasks for continuous control , author=. Software Impacts , volume=. 2020 , publisher=
work page 2020
-
[43]
AAAI conference on artificial intelligence , volume=
Improving sample efficiency in model-free reinforcement learning from images , author=. AAAI conference on artificial intelligence , volume=
-
[44]
International conference on learning representations , year=
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels , author=. International conference on learning representations , year=
-
[45]
International conference on learning representations , year=
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference , author=. International conference on learning representations , year=
-
[46]
International conference on learning representations , year=
Recurrent Experience Replay in Distributed Reinforcement Learning , author=. International conference on learning representations , year=
-
[47]
International conference on machine learning , pages=
The primacy bias in deep reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[48]
Conference on lifelong learning agents , pages=
Loss of plasticity in continual deep reinforcement learning , author=. Conference on lifelong learning agents , pages=. 2023 , organization=
work page 2023
-
[49]
International conference on learning representations , year=
Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning , author=. International conference on learning representations , year=
-
[50]
Mixtures of Experts Unlock Parameter Scaling for Deep
Johan Samir Obando Ceron and Ghada Sokar and Timon Willi and Clare Lyle and Jesse Farebrother and Jakob Nicolaus Foerster and Gintare Karolina Dziugaite and Doina Precup and Pablo Samuel Castro , booktitle=. Mixtures of Experts Unlock Parameter Scaling for Deep
-
[51]
Mixture of Experts in a Mixture of
Willi, Timon and Ceron, Johan Samir Obando and Foerster, Jakob Nicolaus and Dziugaite, Gintare Karolina and Castro, Pablo Samuel , journal=. Mixture of Experts in a Mixture of
-
[52]
International conference on machine learning , pages=
The state of sparse training in deep reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[53]
International joint conference on artificial intelligence , pages =
Dynamic Sparse Training for Deep Reinforcement Learning , author =. International joint conference on artificial intelligence , pages =. 2022 , month =
work page 2022
-
[54]
Don't flatten, tokenize! Unlocking the key to SoftMoE's efficacy in deep
Ghada Sokar and Johan Samir Obando Ceron and Aaron Courville and Hugo Larochelle and Pablo Samuel Castro , booktitle=. Don't flatten, tokenize! Unlocking the key to SoftMoE's efficacy in deep
-
[55]
Conference on neural information processing systems , year=
Hadamax Encoding: Elevating Performance in Model-Free Atari , author=. Conference on neural information processing systems , year=
-
[56]
Advances in neural information processing systems , volume=
Deep reinforcement learning at the edge of the statistical precipice , author=. Advances in neural information processing systems , volume=
-
[57]
International conference on machine learning , pages=
Dueling network architectures for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[58]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [59]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.