Recognition: 1 theorem link
· Lean TheoremMulti-domain Multi-modal Document Classification Benchmark with a Multi-level Taxonomy
Pith reviewed 2026-05-15 05:44 UTC · model grok-4.3
The pith
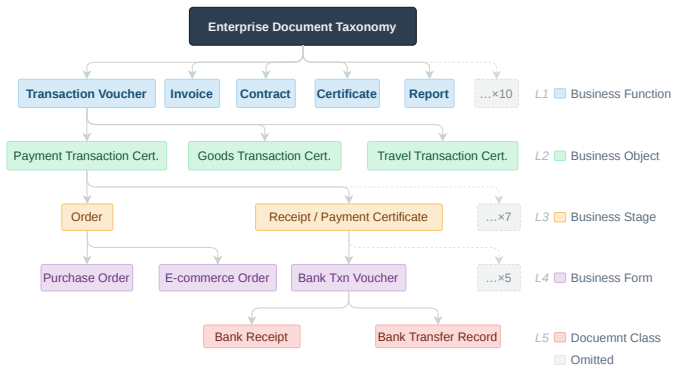
MMM-Bench supplies the first benchmark with a five-level hierarchical taxonomy, twelve commercial domains, and multi-modal documents for classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce MMM-Bench as the first multi-level, multi-domain, multi-modal document classification benchmark. It consists of a deeply hierarchical taxonomy spanning five levels that mirrors business-document organization logic, paired with 5,990 real-world documents curated from twelve commercial domains; each document receives a full hierarchical path annotation from domain experts. Systematic baselines establish performance numbers and isolate four fundamental challenges that arise under these conditions.
What carries the argument
The MMM-Bench dataset itself, whose five-level hierarchical taxonomy and multi-modal documents from multiple domains force models to predict complete label paths rather than flat categories.
If this is right
- Models must output complete five-level paths instead of single flat labels.
- Fusion of textual and visual signals within each document becomes necessary for competitive accuracy.
- Cross-domain generalization must be measured explicitly because performance varies across the twelve domains.
- Evaluation protocols need to account for taxonomy depth when reporting error rates.
- The four identified challenges provide concrete targets for architectural improvements in document intelligence systems.
Where Pith is reading between the lines
- The benchmark could serve as a testbed for transfer-learning methods that move knowledge from one commercial domain to another.
- Future extensions might add temporal versions of the same documents to study how classification changes over document revisions.
- The hierarchical structure invites research on label-embedding techniques that respect parent-child relationships.
- Enterprise systems could adopt the taxonomy as a shared schema to reduce manual tagging costs across organizations.
Load-bearing premise
The 5,990 manually selected and annotated documents from Alibaba accurately represent the hierarchical, multi-modal, and cross-domain complexity of real-world business documents.
What would settle it
Re-annotating a held-out subset of the documents by an independent group of experts and finding substantial disagreement on the hierarchical paths, or observing that top-performing models on MMM-Bench drop sharply on documents drawn from non-Alibaba organizations, would falsify the claim that the benchmark captures representative complexity.
Figures





read the original abstract
Document classification forms the backbone of modern enterprise content management, yet existing benchmarks remain trapped in oversimplified paradigms -- single domain settings with flat label structures -- that bear little resemblance to the hierarchical, multi-modal, and cross-domain nature of real-world business documents. This gap not only misrepresents practical complexity but also stifles progress toward industrially viable document intelligence. To bridge this gap, we construct the first Multi-level, Multi-domain, Multi-modal document classification Benchmark (MMM-Bench). MMM-Bench includes (1) a deeply hierarchical taxonomy spanning five levels that capture the authentic organizational logic of business documentation; and (2) 5,990 real-world multi-modal documents meticulously curated from 12 commercial domains in Alibaba. Each document is manually annotated with a complete hierarchical path by domain experts. We establish comprehensive baselines on MMM-Bench, which consists of open-weight models and API-based models. Through systematic experiments, we identify four fundamental challenges within MMM-Bench and propose corresponding insights. To provide a solid foundation for advancing research in multi-level, multi-domain document classification, we release all of the data and the evaluation toolkit of MMM-Bench at https://github.com/MMMDC-Bench/MMMDC-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MMM-Bench, claimed to be the first multi-level (5-level taxonomy), multi-domain (12 domains), multi-modal document classification benchmark. It consists of 5,990 documents curated from Alibaba's commercial domains, manually annotated by domain experts with complete hierarchical paths, provides baselines from open-weight and API models, identifies four fundamental challenges, and releases the dataset and evaluation toolkit.
Significance. Should the dataset faithfully capture the complexities of real-world enterprise documents, MMM-Bench would address a significant gap in existing benchmarks that are limited to single-domain and flat label structures, potentially driving progress in industrially relevant document intelligence research. The public release of data and toolkit is a positive step for reproducibility.
major comments (1)
- Abstract: the claim that the 5,990 documents 'meticulously curated' from 12 Alibaba domains 'accurately represent' the hierarchical, multi-modal, and cross-domain nature of real-world business documents is not supported by any reported inter-annotator agreement, selection criteria, or coverage statistics. This directly undermines the central assertion that MMM-Bench provides a faithful real-world benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concern regarding the support for claims about dataset curation and representativeness below, and we will incorporate additional details in the revised version to strengthen the paper.
read point-by-point responses
-
Referee: [—] Abstract: the claim that the 5,990 documents 'meticulously curated' from 12 Alibaba domains 'accurately represent' the hierarchical, multi-modal, and cross-domain nature of real-world business documents is not supported by any reported inter-annotator agreement, selection criteria, or coverage statistics. This directly undermines the central assertion that MMM-Bench provides a faithful real-world benchmark.
Authors: We agree that the abstract's phrasing could be tightened and that the manuscript would benefit from explicit reporting of supporting evidence for the curation claims. The full paper describes annotation by domain experts following Alibaba's internal organizational taxonomy, but we acknowledge the absence of quantified inter-annotator agreement (IAA), detailed selection criteria, and coverage statistics in the current version. In the revision we will add a new subsection under Dataset Construction that reports: (1) IAA scores computed on a 10% overlap subset using Cohen's kappa for hierarchical path agreement; (2) explicit selection criteria (e.g., document length, modality completeness, and domain balance thresholds); and (3) coverage statistics (e.g., document counts per domain and per taxonomy level). We will also revise the abstract to state that the documents are 'curated to reflect' rather than 'accurately represent' real-world conditions, aligning the language with the evidence provided. revision: yes
Circularity Check
No circularity: benchmark is constructed dataset with baselines
full rationale
The paper presents a new dataset MMM-Bench built from 5,990 manually selected and expert-annotated Alibaba documents plus baseline model evaluations. No equations, fitted parameters, predictions, or derivations appear in the provided text. The claim of being the 'first' multi-level multi-domain multi-modal benchmark is a direct statement of the construction performed, not a result derived from prior fitted quantities or self-citations. All load-bearing elements (taxonomy design, document curation, annotation) are presented as explicit human choices rather than reductions to inputs by construction. This matches the expected non-circular outcome for a dataset paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curated documents from 12 commercial domains and their 5-level hierarchical annotations by domain experts accurately reflect authentic business document organization.
Reference graph
Works this paper leans on
-
[1]
Jianlyu Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , editor =. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.137 , timestamp =
-
[2]
Junjie Ye and Yuming Yang and Yang Nan and Shuo Li and Qi Zhang and Tao Gui and Xuanjing Huang and Peng Wang and Zhongchao Shi and Jianping Fan , editor =. Analyzing the Effects of Supervised Fine-Tuning on Model Knowledge from Token and Parameter Levels , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.25 , timestamp =
-
[3]
Organic transformation of ERP documentation practices: Moving from archival records to dialogue-based, agile throwaway documents , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.ijinfomgt.2023.102717 , url =
-
[4]
Evaluating Out-of-Distribution Performance on Document Image Classifiers , url =
Larson, Stefan and Lim, Yi Yang Gordon and Ai, Yutong and Kuang, David and Leach, Kevin , booktitle =. Evaluating Out-of-Distribution Performance on Document Image Classifiers , url =
-
[5]
2019 International Conference on Document Analysis and Recognition (ICDAR) , year=
PubLayNet: Largest Dataset Ever for Document Layout Analysis , author=. 2019 International Conference on Document Analysis and Recognition (ICDAR) , year=
work page 2019
-
[6]
Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S. and Staar, Peter , title =. 2022 , isbn =. doi:10.1145/3534678.3539043 , booktitle =
-
[7]
Structural similarity for document image classification and retrieval , author=. Pattern Recognit. Lett. , year=
-
[8]
Hauptmann and Hanjun Dai and Wei Wei , editor =
Lijun Yu and Jin Miao and Xiaoyu Sun and Jiayi Chen and Alexander G. Hauptmann and Hanjun Dai and Wei Wei , editor =. DocumentNet: Bridging the Data Gap in Document Pre-training , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-INDUSTRY.66 , timestamp =
-
[9]
T able B ank: Table Benchmark for Image-based Table Detection and Recognition
Li, Minghao and Cui, Lei and Huang, Shaohan and Wei, Furu and Zhou, Ming and Li, Zhoujun. T able B ank: Table Benchmark for Image-based Table Detection and Recognition. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
work page 2020
-
[10]
A Realistic Dataset for Performance Evaluation of Document Layout Analysis , year=
Antonacopoulos, Apostolos and Bridson, David and Papadopoulos, Christos and Pletschacher, Stefan , booktitle=. A Realistic Dataset for Performance Evaluation of Document Layout Analysis , year=
-
[11]
and Löser, Alexander , title =
Arnold, Sebastian and Schneider, Rudolf and Cudré-Mauroux, Philippe and Gers, Felix A. and Löser, Alexander , title =. Transactions of the Association for Computational Linguistics , volume =. 2019 , doi =
work page 2019
-
[12]
Junyi Jessy Li and Kapil Thadani and Amanda Stent , title =. Proceedings of the. 2016 , url =. doi:10.18653/V1/W16-3617 , timestamp =
-
[13]
LEDGAR : A Large-Scale Multi-label Corpus for Text Classification of Legal Provisions in Contracts
Tuggener, Don and von D. LEDGAR : A Large-Scale Multi-label Corpus for Text Classification of Legal Provisions in Contracts. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
work page 2020
-
[14]
Facta universitatis - series: Electronics and Energetics , year=
Hierarchical text classification for web of science scientific fields , author=. Facta universitatis - series: Electronics and Energetics , year=
- [15]
-
[16]
Maikel Le. Inf. Syst. , volume =. 2026 , url =. doi:10.1016/J.IS.2025.102620 , timestamp =
-
[17]
Amit P. Sheth , editor =. Workflow Automation: Applications, Technology, and Research (Tutorial) , booktitle =. 1995 , url =. doi:10.1145/223784.223882 , timestamp =
- [18]
-
[19]
Gian Piero Zarri , editor =. Some Remarks About the Inference Techniques of RESEDA, an "Intelligent" Information Retrieval System , booktitle =. 1984 , url =
work page 1984
-
[20]
Subband domain coding of binary textual images for document archiving , journal =. 1999 , url =. doi:10.1109/83.791969 , timestamp =
-
[21]
Proceedings of the 29th International Conference on Intelligent User Interfaces , year=
PDFChatAnnotator: A Human-LLM Collaborative Multi-Modal Data Annotation Tool for PDF-Format Catalogs , author=. Proceedings of the 29th International Conference on Intelligent User Interfaces , year=
- [22]
-
[23]
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
work page 2026
-
[24]
An Independent Safety Evaluation of Kimi K2.5 , author=. 2026 , eprint=
work page 2026
-
[25]
Gemini: A family of multimodal AI models , year =
-
[26]
Hierarchical Selective Classification , booktitle =
Shani Goren and Ido Galil and Ran El. Hierarchical Selective Classification , booktitle =. 2024 , url =
work page 2024
-
[27]
ChatGPT-Powered Hierarchical Comparisons for Image Classification , booktitle =
Zhiyuan Ren and Yiyang Su and Xiaoming Liu , editor =. ChatGPT-Powered Hierarchical Comparisons for Image Classification , booktitle =. 2023 , url =
work page 2023
-
[28]
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding , booktitle =
Haoli Bai and Zhiguang Liu and Xiaojun Meng and Wentao Li and Shuang Liu and Yifeng Luo and Nian Xie and Rongfu Zheng and Liangwei Wang and Lu Hou and Jiansheng Wei and Xin Jiang and Qun Liu , editor =. Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.748 , ti...
-
[29]
Yi Tu and Ya Guo and Huan Chen and Jinyang Tang , editor =. LayoutMask: Enhance Text-Layout Interaction in Multi-modal Pre-training for Document Understanding , booktitle =. 2023 , url =. doi:10.18653/V1/2023.ACL-LONG.847 , timestamp =
-
[30]
2026 , howpublished =
work page 2026
-
[31]
Claude Opus 4.7: Anthropic’s New Best (Available) Model , author =. DataCamp Blog , year =
-
[32]
and Heidarysafa, Mojtaba and Jafari Meimandi, Kiana and Gerber, Matthew S
Kowsari, Kamran and Brown, Donald E. and Heidarysafa, Mojtaba and Jafari Meimandi, Kiana and Gerber, Matthew S. and Barnes, Laura E. , booktitle=. HDLTex: Hierarchical Deep Learning for Text Classification , year=
-
[33]
A systematic analysis of performance measures for classification tasks , journal =. 2009 , issn =. doi:https://doi.org/10.1016/j.ipm.2009.03.002 , url =
-
[34]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Jia Deng and Wei Dong and Richard Socher and Li. ImageNet:. 2009. 2009 , url =. doi:10.1109/CVPR.2009.5206848 , timestamp =
-
[35]
The Differences and Similarities Between Two-Sample
Xu, Manfei and Fralick, Drew and Zheng, Julia Z and Wang, Bokai and Tu, Xin M and Feng, Changyong , DOI =. The Differences and Similarities Between Two-Sample. 2017 , Journal =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.