Recognition: 2 theorem links
· Lean TheoremAmortizing Causal Sensitivity Analysis via Prior Data-Fitted Networks
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
Prior-data fitted networks amortize causal sensitivity analysis for rapid in-context bound computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
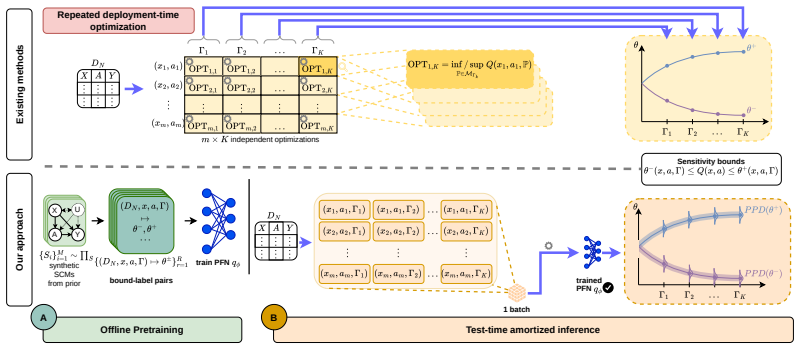
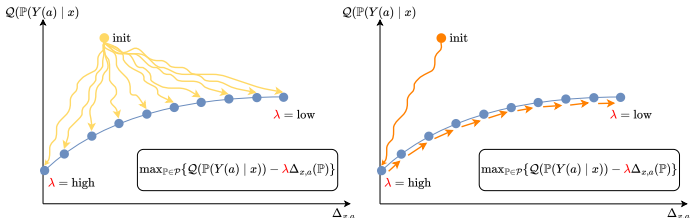
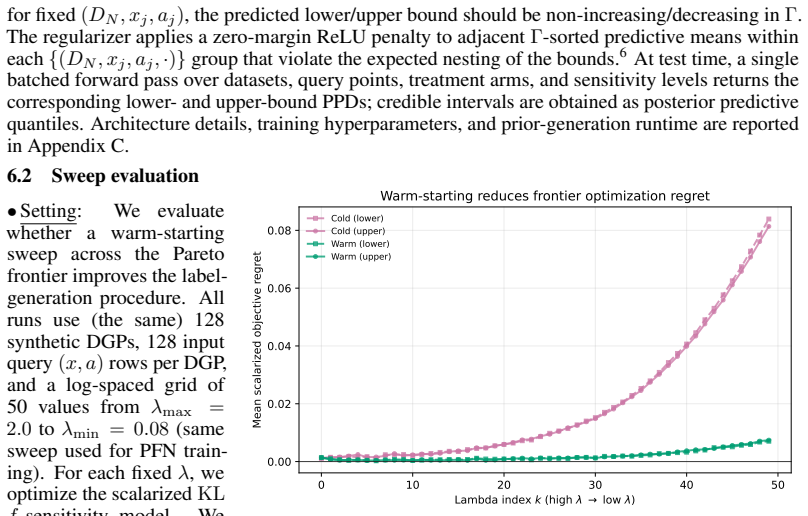
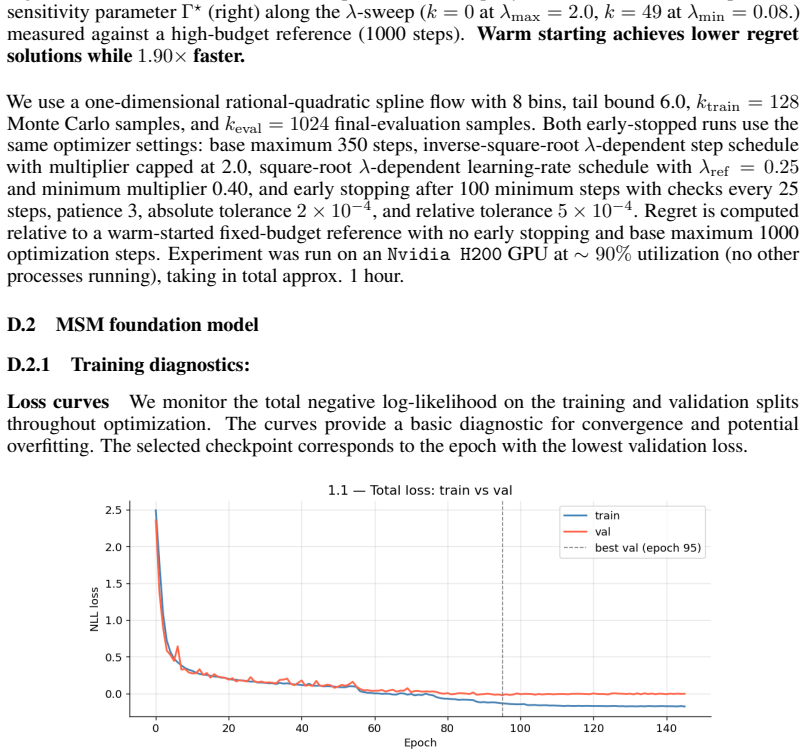
We propose an amortized approach to causal sensitivity analysis based on prior-data fitted networks. A general prior-data construction is developed that applies across the class of generalized treatment sensitivity models by using Lagrangian scalarization of the min/max causal effect objective to generate training labels through a tradeoff against sensitivity model violation. This avoids model-specific analytical derivations. Under standard convexity and linearity conditions, the objective recovers the full Pareto frontier of solutions. The approach achieves test-time computation orders of magnitude faster than per-instance methods and constitutes the first foundation model for in-context学习
What carries the argument
Prior-data fitted network trained with Lagrangian scalarization that trades off causal effect optimization against sensitivity-model violation to produce bounds without per-model analytical derivations.
If this is right
- Delivers causal sensitivity bounds orders of magnitude faster at test time than per-instance optimization.
- Applies without modification to any generalized treatment sensitivity model.
- Recovers the complete Pareto frontier of bound solutions under convexity and linearity.
- Supports in-context evaluation for arbitrary new datasets, queries, and sensitivity levels after a single training run.
Where Pith is reading between the lines
- The same prior-data construction could be adapted to amortize other robustness or uncertainty calculations in causal inference.
- Integration into interactive or real-time decision systems becomes feasible once bounds are available in milliseconds.
- The approach suggests a route toward specialized foundation models that handle families of causal robustness tasks through in-context examples.
Load-bearing premise
The Lagrangian scalarization of the min/max causal effect objective against sensitivity-model violation produces valid training labels for the bounds without requiring model-specific analytical derivations.
What would settle it
Train the network and compare its predicted bounds against exact per-instance optimization results on a low-dimensional causal model whose sensitivity bounds are known in closed form; large systematic discrepancy would show the labels or amortization are invalid.
Figures





read the original abstract
Causal sensitivity analysis aims to provide bounds for causal effect estimates in the presence of unobserved confounding. However, existing methods for causal sensitivity analysis are per-instance procedures, meaning that changes to the dataset, causal query, sensitivity level, or treatment require new computation. Here, we instead present an in-context learning approach. Specifically, we propose an amortized approach to causal sensitivity analysis based on prior-data fitted networks. A key challenge is that the sensitivity bounds are not directly available when sampling training data. To address this, we develop a general prior-data construction that is applicable across the class of generalized treatment sensitivity models. Our construction involves a Lagrangian scalarization of the objective to generate training labels for the bounds through a tradeoff between causal effect min/max-imization and sensitivity model violation, which avoids model-specific analytical derivations. We further show that, under standard convexity and linearity conditions, our objective recovers the full Pareto frontier of solutions. Empirically, we demonstrate our amortized approach across various datasets, causal queries, and sensitivity levels, where our approach achieves a test-time computation that is orders of magnitude faster than per-instance methods. To the best of our knowledge, ours is the first foundation model for in-context learning for causal sensitivity analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first foundation model for in-context learning in causal sensitivity analysis by using prior-data fitted networks (PFNs). It develops a general amortized approach applicable to generalized treatment sensitivity models, where training labels for sensitivity bounds are generated via a Lagrangian scalarization of the min/max causal effect objective subject to sensitivity-model violation. The authors state that under convexity and linearity this recovers the full Pareto frontier of solutions, avoiding the need for model-specific analytical derivations. Empirically, the method achieves orders-of-magnitude faster test-time computation than per-instance solvers across datasets, queries, and sensitivity levels.
Significance. If the Lagrangian construction produces accurate bounds without systematic approximation error relative to exact per-instance solutions, the work would be significant: it would amortize a currently expensive family of computations, enabling rapid sensitivity analysis at scale and supporting in-context adaptation to new datasets or queries. The empirical speedups and the self-supervised label generation strategy would constitute a practical advance in causal inference tooling.
major comments (2)
- [Abstract and §3] Abstract and §3 (Lagrangian scalarization): the claim that the scalarized objective recovers the full Pareto frontier under convexity and linearity is not demonstrated against closed-form analytical bounds available for standard cases (e.g., Rosenbaum or marginal sensitivity models with binary treatment). Without such verification, it remains possible that the generated training labels contain systematic bias relative to the exact extremal points used by existing solvers, which would undermine the correctness of the amortized PFN predictions.
- [§4] §4 (training data construction): the self-supervised label generation re-uses the same min/max objective that the network is later asked to predict. While the paper argues this is valid under the stated convexity conditions, no ablation or diagnostic is provided showing that the resulting PFN outputs match or bound the solutions of established per-instance methods on held-out instances where ground-truth bounds are known.
minor comments (2)
- [Abstract] The abstract states the method is 'applicable across the class of generalized treatment sensitivity models' but does not list the precise class of models for which the Lagrangian construction is guaranteed to be valid.
- [Experiments] Figure captions and experimental tables should explicitly report the number of training instances, the range of sensitivity levels, and the exact per-instance baseline solvers used for timing comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, outlining the revisions we will make to strengthen the presentation and empirical validation.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Lagrangian scalarization): the claim that the scalarized objective recovers the full Pareto frontier under convexity and linearity is not demonstrated against closed-form analytical bounds available for standard cases (e.g., Rosenbaum or marginal sensitivity models with binary treatment). Without such verification, it remains possible that the generated training labels contain systematic bias relative to the exact extremal points used by existing solvers, which would undermine the correctness of the amortized PFN predictions.
Authors: We appreciate the referee pointing this out. In §3 we provide a theoretical argument establishing that, under the stated convexity and linearity conditions, the Lagrangian scalarization is equivalent to the original multi-objective problem and therefore recovers the full Pareto frontier without requiring model-specific closed forms. To address the concern about potential systematic bias in the generated labels, we will add an empirical verification subsection in the revised manuscript. This will compare the scalarized labels against known closed-form analytical bounds for standard cases (Rosenbaum sensitivity model and marginal sensitivity models with binary treatment) on synthetic and real datasets, confirming alignment with the exact extremal points used by per-instance solvers. revision: yes
-
Referee: [§4] §4 (training data construction): the self-supervised label generation re-uses the same min/max objective that the network is later asked to predict. While the paper argues this is valid under the stated convexity conditions, no ablation or diagnostic is provided showing that the resulting PFN outputs match or bound the solutions of established per-instance methods on held-out instances where ground-truth bounds are known.
Authors: We agree that explicit diagnostics on held-out data would provide stronger reassurance. Although the self-supervised construction is justified theoretically by the convexity argument in §3, we will include a new ablation study in the revised §4 and experimental section. This study will evaluate the trained PFN on held-out instances for which ground-truth bounds are available from established per-instance solvers (both analytical and numerical), reporting how closely the amortized predictions match or bound those exact solutions across datasets, queries, and sensitivity levels. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs training labels for the PFN via a Lagrangian scalarization of the min/max causal effect objective under sensitivity constraints, then trains the network to predict those labels for new in-context inputs. This is a standard self-supervised amortization procedure rather than a reduction by construction: the scalarization is justified by a claimed recovery of the Pareto frontier under convexity/linearity (presented as a separate mathematical argument), and the network's role is to generalize the resulting bounds at test time. No quoted step equates the final output to the input labels by definition, no load-bearing self-citation chain is used to justify uniqueness, and the approach remains independent of the target causal queries once the label generator is fixed. The method is therefore self-contained against external benchmarks for the amortization claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard convexity and linearity conditions hold for the sensitivity models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLagrangian scalarization of the objective to generate training labels for the bounds through a tradeoff between causal effect min/max-imization and sensitivity model violation
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearunder standard convexity and linearity conditions, our objective recovers the full Pareto frontier
Reference graph
Works this paper leans on
-
[1]
V . Balazadeh, H. Kamkari, V . Thomas, B. Li, J. Ma, J. C. Cresswell, and R. G. Krishnan. CausalPFN: Amortized Causal Effect Estimation via In-Context Learning.arXiv preprint, arXiv:2506.07918, 2025
-
[2]
D. Bär, N. Pröllochs, and S. Feuerriegel. The role of social media ads for election outcomes: Evidence from the 2021 German election.PNAS Nexus, 4(3):pgaf073, 2025
work page 2021
-
[3]
L. E. J. Bynum, A. M. Puli, D. Herrero-Quevedo, N. Nguyen, C. Fernandez-Granda, K. Cho, and R. Ranganath. Black Box Causal Inference: Effect Estimation via Meta Prediction, 2025
work page 2025
-
[4]
J. Dorn and K. Guo. Sharp Sensitivity Analysis for Inverse Propensity Weighting via Quantile Balancing.Journal of the American Statistical Association, 118(544):2645–2657, 2023
work page 2023
-
[5]
S. Feuerriegel, D. Frauen, V . Melnychuk, J. Schweisthal, K. Hess, A. Curth, S. Bauer, N. Kil- bertus, I. S. Kohane, and M. van der Schaar. Causal machine learning for predicting treatment outcomes.Nature Medicine, 30(4):958–968, 2024
work page 2024
- [6]
- [7]
-
[8]
Tabpfn-2.5: Advancing the state of the art in tabular foundation models, 2025
L. Grinsztajn, K. Flöge, O. Key, F. Birkel, P. Jund, B. Roof, B. Jäger, D. Safaric, S. Alessi, A. Hayler, M. Manium, R. Yu, F. Jablonski, S. B. Hoo, A. Garg, J. Robertson, M. Bühler, V . Moroshan, L. Purucker, C. Cornu, L. C. Wehrhahn, A. Bonetto, B. Schölkopf, S. Gambhir, N. Hollmann, and F. Hutter. TabPFN-2.5: Advancing the State of the Art in Tabular F...
-
[9]
N. Hollmann, S. Müller, K. Eggensperger, and F. Hutter. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InICLR, 2023
work page 2023
-
[10]
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeis- ter, and F. Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
work page 2025
-
[11]
S. B. Hoo, S. Müller, D. Salinas, and F. Hutter. From Tables to Time: Extending TabPFN-v2 to Time Series Forecasting, 2025
work page 2025
- [12]
-
[13]
A. Jesson, A. Douglas, P. Manshausen, M. Solal, N. Meinshausen, P. Stier, Y . Gal, and U. Shalit. Scalable Sensitivity and Uncertainty Analyses for Causal-Effect Estimates of Continuous- Valued Interventions.Advances in Neural Information Processing Systems, 35:13892–13907, 2022
work page 2022
-
[14]
Y . Jin, Z. Ren, and E. J. Candès. Sensitivity analysis of individual treatment effects: A robust conformal inference approach.Proceedings of the National Academy of Sciences, 120(6): e2214889120, 2023
work page 2023
-
[15]
Y . Jin, Z. Ren, and Z. Zhou. Sensitivity Analysis Under thef-Sensitivity Model: A Distributional Robustness Perspective.Operations Research, 74(2):860–878, 2026
work page 2026
- [16]
-
[17]
M. Kuzmanovic, D. Frauen, T. Hatt, and S. Feuerriegel. Causal Machine Learning for Cost- Effective Allocation of Development Aid. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, 2024. 10
work page 2024
- [18]
-
[19]
C. Manski. Nonparametric Bounds on Treatment Effects.The American Economic Review, 1989
work page 1989
-
[20]
M. G. Marmarelis, E. Haddad, A. Jesson, N. Jahanshad, A. Galstyan, and G. V . Steeg. Partial identification of dose responses with hidden confounders. InProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, 2023
work page 2023
-
[21]
M. G. Marmarelis, G. V . Steeg, A. Galstyan, and F. Morstatter. Ensembled Prediction Intervals for Causal Outcomes Under Hidden Confounding. InProceedings of the Third Conference on Causal Learning and Reasoning, 2024
work page 2024
-
[22]
V . Melnychuk, V . Balazadeh, S. Feuerriegel, and R. G. Krishnan. Frequentist Consistency of Prior-Data Fitted Networks for Causal Inference, 2026
work page 2026
- [23]
- [24]
-
[25]
M. Oprescu, J. Dorn, M. Ghoummaid, A. Jesson, N. Kallus, and U. Shalit. B-Learner: Quasi- Oracle Bounds on Heterogeneous Causal Effects Under Hidden Confounding. InProceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[26]
Pearl.Causality: Models, Reasoning, and Inference
J. Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge,
-
[27]
ed., repr. with corr edition, 2013. ISBN 978-0-521-77362-1 978-0-521-89560-6
work page 2013
-
[28]
Do-PFN: In-Context Learning for Causal Effect Estimation, 2025
J. Robertson, A. Reuter, S. Guo, N. Hollmann, F. Hutter, and B. Schölkopf. Do-PFN: In-Context Learning for Causal Effect Estimation.arXiv preprint, arXiv:2506.06039, 2025
-
[29]
P. R. Rosenbaum. Sensitivity analysis for certain permutation inferences in matched observa- tional studies.Biometrika, 74(1):13–26, 1987
work page 1987
-
[30]
D. B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 66(5):688–701, 1974
work page 1974
-
[31]
L. Skapetze, D. Koller, A. Zwergal, S. Feuerriegel, A. Rubinski, and E. Grill. Monitoring changes in vitamin D levels during the COVID-19 pandemic with routinely-collected laboratory data.Nature Communications, 16(1):8772, 2025
work page 2025
-
[32]
Z. Tan. A Distributional Approach for Causal Inference Using Propensity Scores.Journal of the American Statistical Association, 101(476):1619–1637, 2006
work page 2006
-
[33]
C. Winkler, D. Worrall, E. Hoogeboom, and M. Welling. Learning Likelihoods with Conditional Normalizing Flows, 2019
work page 2019
-
[34]
M. Yin, C. Shi, Y . Wang, and D. M. Blei. Conformal Sensitivity Analysis for Individual Treatment Effects.Journal of the American Statistical Association, 119(545):122–135, 2024
work page 2024
-
[35]
Q. Zhao, D. S. Small, and B. B. Bhattacharya. Sensitivity Analysis for Inverse Probability Weighting Estimators via the Percentile Bootstrap.Journal of the Royal Statistical Society Series B: Statistical Methodology, 81(4):735–761, 2019. 11 A Proofs A.1 Theorem 1 Theorem 1. The argument proceeds by establishing concavity of the upper frontier and then der...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.