Recognition: no theorem link
Reconfigurable Computing Challenge: Real-Time Graph Neural Networks for Online Event Selection in Big Science
Pith reviewed 2026-05-12 05:14 UTC · model grok-4.3
The pith
A hybrid FPGA and AI Engine system runs dynamic graph neural networks for real-time event selection in collider experiments at 2.94 million events per second.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a hybrid reconfigurable platform of FPGA fabric and AI Engine tiles can host a dynamic graph neural network for strict-latency trigger applications in high-energy physics, delivering 2.94 million events per second at 7.15 microseconds latency, 53 percent higher throughput than an FPGA-only baseline, and sharply reduced DSP usage (19 percent versus 99 percent) at modest AI Engine tile occupancy (29 percent), with an interactive visualization pipeline for live monitoring of the physical hardware.
What carries the argument
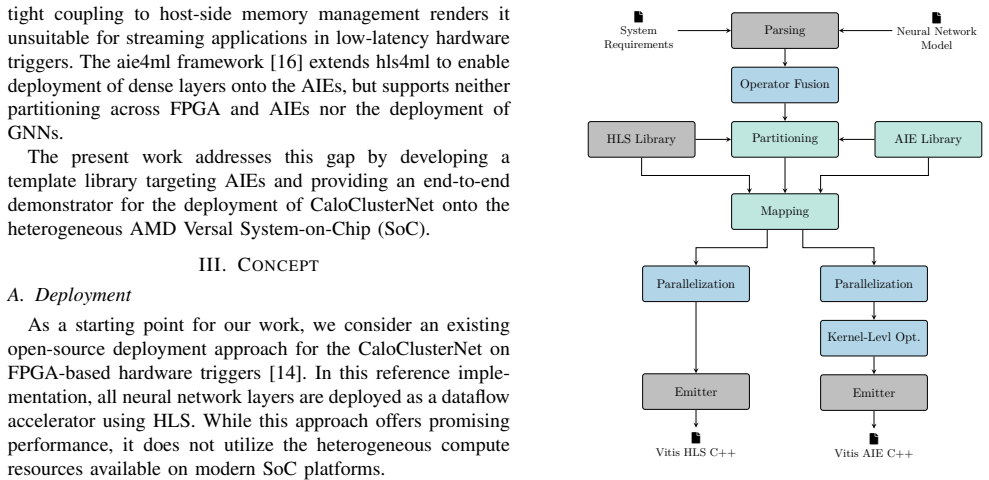
The semi-automated Python-based design flow that performs operator fusion, graph partitioning, hardware mapping, spatial parallelization, and kernel-level optimization to place the dynamic GNN across FPGA fabric and AI Engine tiles.
If this is right
- Detector upgrades that increase input granularity become feasible without exhausting FPGA resources.
- Lower DSP consumption leaves headroom for additional trigger logic on the same chip.
- Dynamic GNN models can adapt during operation because the architecture supports runtime reconfiguration.
- End-to-end latency under 8 microseconds fits inside typical collider trigger timing budgets.
- The visualization pipeline supports rapid debugging and validation on live hardware.
Where Pith is reading between the lines
- The same hybrid mapping approach could apply to other real-time inference tasks in large scientific instruments where data rates outstrip pure FPGA capacity.
- If accuracy remains intact, this work indicates that combining programmable logic with AI accelerators offers a scalable route for embedding complex models in embedded scientific systems.
- Extending the flow to larger graphs or alternative GNN layers would test whether the performance gains generalize beyond the Belle II calorimeter case.
Load-bearing premise
The hardware version of the graph neural network produces the same event-selection decisions as the original software implementation without measurable loss of accuracy.
What would settle it
Running the identical input dataset through both the software GNN and the deployed hardware version and comparing the fraction of events each selects would directly test whether decision quality is preserved.
Figures




read the original abstract
Graph neural networks are increasingly adopted in trigger systems for collider experiments, where strict latency and throughput constraints render deployment on embedded platforms challenging. As detectors move towards higher granularity, the number of inputs per inference increase and FPGA-only solutions face resource bottlenecks. This work presents an end-to-end demonstrator for the real-time deployment of a dynamic Graph Neural Network for the Belle II electromagnetic calorimeter hardware trigger on the AMD Versal VCK190, leveraging both FPGA fabric and AI Engine tiles. We develop a Python-based semi-automated design flow covering operator fusion, partitioning, mapping, spatial parallelization, and kernel-level optimization. Our design achieves a throughput of 2.94 million events per second at an end-to-end latency of 7.15 microseconds. Compared to the FPGA-only baseline, this represents a 53% throughput improvement while reducing DSP utilization from 99% to 19% at 29% AI Engine tile utilization. To validate the deployment, an interactive visualization pipeline enables real-time monitoring of inference results on the physical demonstrator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end hardware demonstrator for real-time deployment of a dynamic Graph Neural Network (GNN) for online event selection in the Belle II electromagnetic calorimeter trigger. It introduces a Python-based semi-automated design flow that performs operator fusion, partitioning, mapping, spatial parallelization, and kernel optimization to target the AMD Versal VCK190 platform, which integrates FPGA fabric and AI Engine tiles. Key measured results include a throughput of 2.94 million events per second at 7.15 µs end-to-end latency, a 53% throughput improvement over an FPGA-only baseline, DSP utilization reduced from 99% to 19%, and 29% AI Engine tile utilization. Validation consists of an interactive visualization pipeline for monitoring inference outputs on the physical hardware.
Significance. If the hardware GNN preserves the accuracy and decision quality of the floating-point software reference, the work would demonstrate a viable path to scaling complex ML models in latency-constrained big-science triggers by exploiting heterogeneous reconfigurable architectures. The empirical throughput, latency, and resource numbers obtained on physical hardware, together with the semi-automated Python flow, constitute concrete, reproducible engineering contributions that could guide future designs for higher-granularity detectors.
major comments (2)
- Abstract: the reported performance numbers (2.94 M events/s, 7.15 µs latency, 53% throughput gain, DSP reduction from 99% to 19%) are presented without any model accuracy, signal efficiency, background rejection, or software-to-hardware numerical comparison. Because the central claim is a usable real-time trigger deployment, the absence of ROC curves, efficiency plots, quantization-error analysis, or bit-exact validation leaves the physics utility of the results unsupported.
- Validation pipeline description: the interactive visualization is stated to enable real-time monitoring of inference results, yet it is described only as monitoring outputs and supplies no quantitative assessment of degradation, no comparison metrics against the original software GNN, and no error bars or fidelity checks after operator fusion and mapping.
minor comments (2)
- Abstract: the phrase 'dynamic Graph Neural Network' is used without a concise definition or reference to the specific architectural features (e.g., variable graph size or adaptive message passing) that distinguish it from static GNNs.
- The manuscript would benefit from an explicit statement of the event sample size, trigger decision threshold, and software baseline configuration used for the 53% throughput comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where explicit validation of physics performance would strengthen the presentation of our hardware deployment results. We address each major comment below and will incorporate revisions to provide the requested quantitative comparisons.
read point-by-point responses
-
Referee: Abstract: the reported performance numbers (2.94 M events/s, 7.15 µs latency, 53% throughput gain, DSP reduction from 99% to 19%) are presented without any model accuracy, signal efficiency, background rejection, or software-to-hardware numerical comparison. Because the central claim is a usable real-time trigger deployment, the absence of ROC curves, efficiency plots, quantization-error analysis, or bit-exact validation leaves the physics utility of the results unsupported.
Authors: We agree that the abstract and main text would be improved by explicitly linking the hardware metrics to preserved physics performance. The deployment uses quantization and mapping that maintain decision quality equivalent to the floating-point reference, as confirmed through our internal bit-exact checks, but these details were not highlighted to emphasize the engineering flow. In the revised manuscript we will update the abstract and add a new subsection with ROC curves, signal efficiency, background rejection rates, software-to-hardware numerical comparisons, quantization-error analysis, and bit-exact validation results. revision: yes
-
Referee: Validation pipeline description: the interactive visualization is stated to enable real-time monitoring of inference results, yet it is described only as monitoring outputs and supplies no quantitative assessment of degradation, no comparison metrics against the original software GNN, and no error bars or fidelity checks after operator fusion and mapping.
Authors: The interactive visualization serves as a monitoring interface for live hardware operation. We acknowledge that the current description does not include quantitative fidelity metrics. We will expand this section in the revision to report quantitative assessments, including direct comparison metrics between hardware and software GNN outputs, fidelity checks after each stage of the design flow (fusion, partitioning, mapping), and error bars derived from repeated measurements on the physical platform. revision: yes
Circularity Check
Empirical hardware measurements with no derivation chain
full rationale
The manuscript reports direct physical measurements of throughput (2.94M events/s), latency (7.15 µs), DSP utilization (19%), and AI Engine tile utilization (29%) on the Versal VCK190 after implementing a GNN via a Python flow for fusion/partitioning/mapping. No equations, first-principles predictions, fitted parameters, or uniqueness theorems are invoked; the central claims are benchmark numbers obtained from the deployed hardware. Self-citations, if present, are not load-bearing for any result. The lack of accuracy/ROC comparison is a completeness issue, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Testing a Neural Network for Anomaly Detection in the CMS GlobalTrigger Test Crate during Run 3
N. Zipper et al. “Testing a Neural Network for Anomaly Detection in the CMS GlobalTrigger Test Crate during Run 3”. In:Journal of Instrumentation19.03 (Mar. 2024), p. C03029.ISSN: 1748-0221.DOI: 10 . 1088 / 1748-0221/19/03/C03029.URL: https://iopscience.iop. org/article/10.1088/1748-0221/19/03/C03029 (visited on 01/05/2026)
-
[2]
The neural network first-level hardware track trigger of the Belle IIexperiment
S. B ¨ahr et al. “The neural network first-level hardware track trigger of the Belle IIexperiment”. In:Nucl. In- strum. Meth. A1073 (2025), p. 170279.DOI: 10.1016/ j.nima.2025.170279. arXiv: 2402.14962[hep-ex]
-
[3]
Development of deep neural network first-level hardware track trigger for the Belle II ex- periment
Y .-X. Liu et al. “Development of deep neural network first-level hardware track trigger for the Belle II ex- periment”. en. In:Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spec- trometers, Detectors and Associated Equipment1084 (Apr. 2026), p. 171248.ISSN: 01689002.DOI: 10 . 1016 / j . nima . 2025 . 171248.URL: https : / /...
work page 2026
-
[4]
Applications and Techniques for Fast Machine Learning in Science
A. M. Deiana et al. “Applications and Techniques for Fast Machine Learning in Science”. In:Frontiers in Big Data5 (Apr. 2022), p. 787421.ISSN: 2624-909X. DOI: 10.3389/fdata.2022.787421.URL: https://www. frontiersin.org/articles/10.3389/fdata.2022.787421/full (visited on 09/25/2023)
-
[5]
Graph neural networks in particle physics
J. Shlomi et al. “Graph neural networks in particle physics”. In:Machine Learning: Science and Technol- ogy2.2 (Jan. 2021), p. 021001.DOI: 10.1088/2632- 2153/abbf9a
-
[6]
Computing Graph Neural Networks: A Survey from Algorithms to Accelerators
S. Abadal et al. “Computing Graph Neural Networks: A Survey from Algorithms to Accelerators”. In:ACM Computing Surveys54.9 (Jan. 2022), pp. 1–38.ISSN: 0360-0300.DOI: 10.1145/3477141
-
[7]
Design of the Global Reconstruction Logic in the Belle II Level-1 Trigger system
Y .-T. Lai et al. “Design of the Global Reconstruction Logic in the Belle II Level-1 Trigger system”. In: Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment1078 (2025), p. 170577.ISSN: 0168-9002.DOI: https://doi.org/10.1016/j.nima.2025. 170577.URL: https://www.sciencedirect.com/sc...
-
[8]
CMS. The TriDAS project. Technical design report, vol. 1: The trigger systems
S. Dasu et al. “CMS. The TriDAS project. Technical design report, vol. 1: The trigger systems”. In: (Dec. 2000)
work page 2000
-
[9]
Belle II Technical Design Report
T. Abe et al. “Belle II Technical Design Report”. In: (Nov. 2010). arXiv: 1011 . 0352 [physics.ins-det]
work page 2010
-
[10]
Haide et al.Real-time graph neural networks on FPGAs for the Belle II electromagnetic calorimeter
I. Haide et al.Real-time graph neural networks on FPGAs for the Belle II electromagnetic calorimeter
-
[11]
arXiv: 2602 . 15118[physics.ins-det]. URL: https://arxiv.org/abs/2602.15118
-
[12]
Measuring the Gap Between FPGAs and ASICs
I. Kuon et al. “Measuring the Gap Between FPGAs and ASICs”. In:IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems26.2 (2007), pp. 203–215.DOI: 10.1109/TCAD.2006.884574
-
[13]
Yaman Umuroglu et al. “FINN”. In:Proceedings of the 2017 ACM/SIGDA International Symposium on Field- Programmable Gate Arrays. Ed. by Jonathan Greene and Jason H. Anderson. New York, NY , USA: ACM, Jan. 2017, pp. 65–74.ISBN: 978-1-4503-4354-1.DOI: 10.1145/3020078.3021744
-
[14]
Jan-Frederik Schulte et al.Hls4ml: A Flexible, Open- Source Platform for Deep Learning Acceleration on Re- configurable Hardware. 2025.DOI: 10.48550/ARXIV. 2512.01463. (Visited on 02/18/2026)
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[15]
Real-Time Graph-based Point Cloud Networks on FPGAs via Stall-Free Deep Pipelining
M. Neu et al. “Real-Time Graph-based Point Cloud Networks on FPGAs via Stall-Free Deep Pipelining”. In:2025 38th SBC/SBMicro/IEEE Symposium on In- tegrated Circuits and Systems Design (SBCCI). 2025, pp. 1–5.DOI: 10.1109/SBCCI66862.2025.11218652
-
[16]
Erwei Wang et al.From Loop Nests to Silicon: Mapping AI Workloads onto AMD NPUs with MLIR-AIR. Oct. 2025.DOI: 10.48550/arXiv.2510.14871. arXiv: 2510. 14871[cs]. (Visited on 12/15/2025)
-
[17]
2025.DOI: 10.48550/ ARXIV .2512.15946
Dimitrios Danopoulos et al.AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines. 2025.DOI: 10.48550/ ARXIV .2512.15946
-
[18]
Claudionor N. Coelho et al. “Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors”. en. In:Na- ture Machine Intelligence3.8 (Aug. 2021), pp. 675–686. ISSN: 2522-5839.DOI: 10.1038/s42256-021-00356-5. URL: https : / / www. nature . com / articles / s42256 - 021 - 00356-5
-
[19]
https://github.com/Xilinx/Vitis Libraries
AMD.Vitis Libraries. https://github.com/Xilinx/Vitis Libraries. Version 2024.2. 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.