Recognition: 2 theorem links
· Lean TheoremGenMed: A Pairwise Generative Reformulation of Medical Diagnostic Tasks
Pith reviewed 2026-05-12 05:03 UTC · model grok-4.3
The pith
Medical diagnostic tasks can be reframed as generative modeling of the joint distribution of inputs and outputs using diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
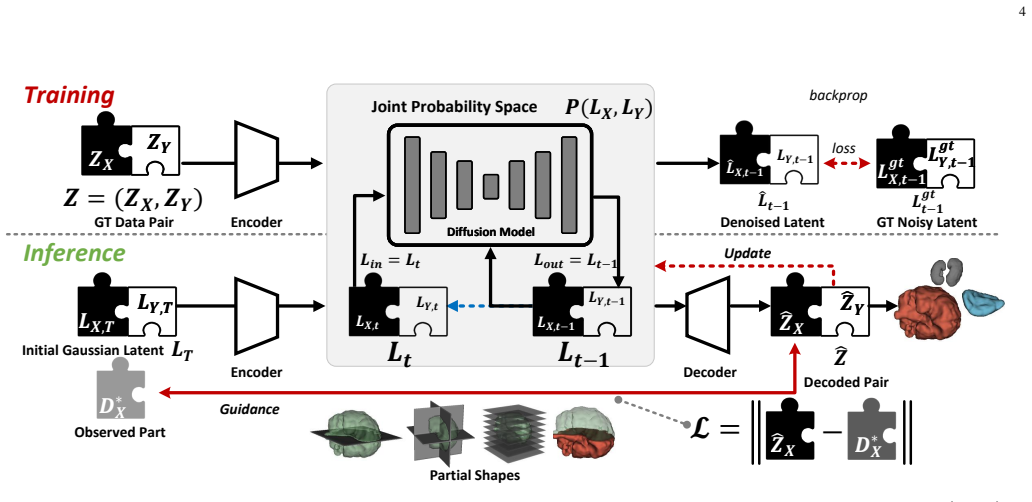
We model the joint distribution P(X,Y) using diffusion models and reframe inference as a test-time output optimization problem. By guiding the generative process to match observed inputs, our framework enables flexible, gradient-based conditioning at inference time without architectural changes or retraining, effectively supporting arbitrary and previously unseen combinations of observations.
What carries the argument
Diffusion models of the joint distribution P(X,Y) with gradient-based test-time optimization to condition on arbitrary observed inputs.
If this is right
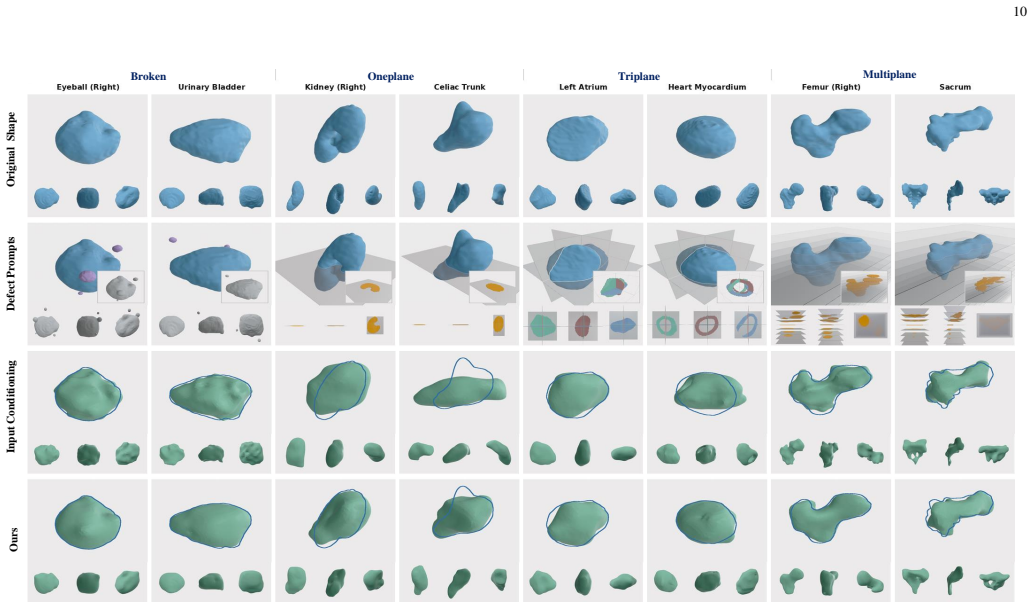
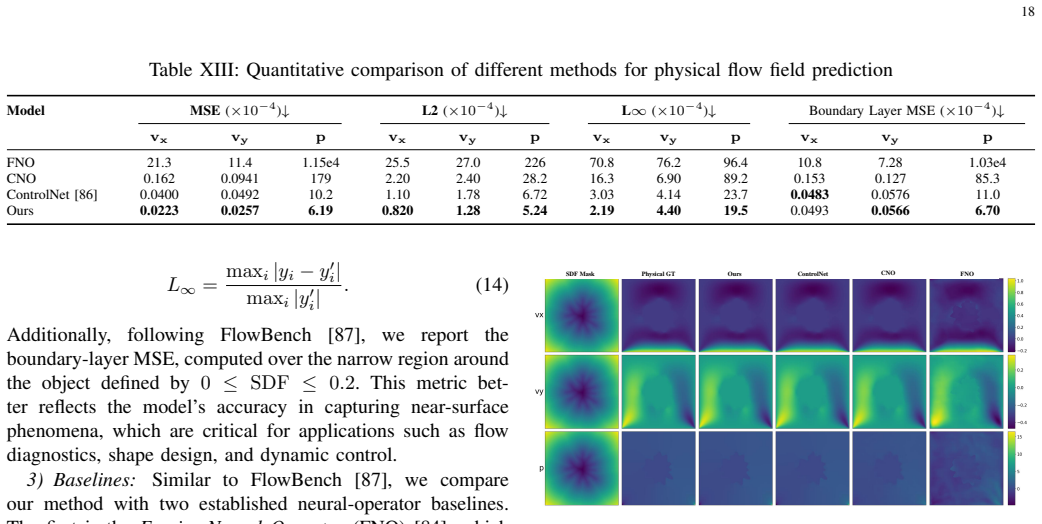
- Strong performance on standard and cross-modality medical image segmentation
- Few-shot segmentation succeeds with only 2 or 4 training samples
- Handles degraded-input segmentation and shape completion from sparse or partial observations
- Supports zero-shot application to new tasks and modalities
- Evaluation enabled by a new large-scale text-shape dataset derived from MedShapeNet
Where Pith is reading between the lines
- The same joint-modeling recipe could be tested on non-medical domains that also face heterogeneous inputs, such as autonomous driving or remote sensing.
- Test-time optimization might allow dynamic addition of entirely new sensor types without any further training or data collection.
- If the guidance remains stable, the approach could reduce reliance on task-specific labeled datasets by leveraging the generative prior for many downstream medical questions.
Load-bearing premise
A diffusion model trained on the joint distribution can be reliably guided at test time to produce accurate outputs for previously unseen combinations of observations and modalities.
What would settle it
Demonstrating failure or collapse when the model is applied to a modality combination or task type absent from its training data.
Figures




read the original abstract
Data-driven medical AI is traditionally formulated as a discriminative mapping from input $X$ to output $Y$ via a learned function $f$, which does not generalize well across heterogeneous data and modalities encountered in real-world clinical settings. In this work, we propose a fundamentally different, generative paradigm. We model the joint distribution $P(X,Y)$ using diffusion models and reframe inference as a test-time output optimization problem. By guiding the generative process to match observed inputs, our framework enables flexible, gradient-based conditioning at inference time without architectural changes or retraining, effectively supporting arbitrary and previously unseen combinations of observations. Extensive experiments demonstrate strong performance across standard and cross-modality medical image segmentation, few-shot segmentation with only 2 or 4 training samples, degraded-input segmentation, shape completion from sparse and partial observations, and zero-shot application to demonstrate generality. To support these evaluations, we curated and released a large-scale text-shape dataset derived from MedShapeNet. Our results highlight the versatility of generative joint modeling as a foundation for reusable, task-agnostic medical AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GenMed, a generative reformulation of medical diagnostic tasks. Rather than learning a discriminative mapping f: X → Y, it models the joint distribution P(X,Y) via diffusion models and reframes inference as a test-time optimization problem in which the generative process is guided (via gradients) to match observed inputs. This is claimed to enable flexible, architecture- and training-free conditioning for arbitrary and previously unseen combinations of observations and modalities. The approach is evaluated on standard and cross-modality segmentation, few-shot segmentation (2–4 samples), degraded-input segmentation, shape completion from sparse observations, and zero-shot tasks; a large-scale text-shape dataset derived from MedShapeNet is also released.
Significance. If the central test-time optimization procedure can be shown to converge reliably for out-of-support modality combinations, the work would offer a genuinely task-agnostic and reusable foundation for medical imaging AI, reducing the proliferation of specialized discriminative models. The public dataset release is a concrete community contribution. At present, however, the significance is limited by the absence of any analysis or ablation demonstrating that the learned score remains informative and the optimization landscape tractable when conditioning signals lie far from the training marginals.
major comments (2)
- [Abstract] Abstract: The central claim that the framework 'effectively supporting arbitrary and previously unseen combinations of observations' is load-bearing for the entire contribution, yet the manuscript provides no derivation, convergence analysis, or even empirical characterization of the test-time loss landscape when the observed inputs are heterogeneous or lie outside the support of the training joint P(X,Y). The skeptic note correctly identifies that nothing in the standard diffusion training objective guarantees recovery of accurate Y under such conditions.
- [Method] Method / Inference procedure (presumed §3): The description of gradient-based conditioning at inference time does not specify the precise form of the test-time loss, the number of optimization steps, or any regularization that would prevent the reverse process from drifting off the data manifold when multiple conflicting or novel observations must be satisfied simultaneously. Without these details or accompanying ablations, the zero-shot and cross-modality results cannot be interpreted as evidence that the claimed flexibility holds.
minor comments (2)
- [Method] The paper would benefit from an explicit statement of the test-time objective (e.g., an equation defining the matching loss between generated samples and observed inputs) rather than a high-level description.
- [Experiments] Quantitative results for the few-shot and zero-shot experiments should include standard deviations over multiple random seeds and a clear comparison against strong discriminative baselines trained under the same data constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential of a task-agnostic generative foundation as well as the value of the released MedShapeNet-derived dataset. We address each major comment below, clarifying our position and committing to revisions that strengthen the manuscript without overstating theoretical guarantees.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'effectively supporting arbitrary and previously unseen combinations of observations' is load-bearing for the entire contribution, yet the manuscript provides no derivation, convergence analysis, or even empirical characterization of the test-time loss landscape when the observed inputs are heterogeneous or lie outside the support of the training joint P(X,Y). The skeptic note correctly identifies that nothing in the standard diffusion training objective guarantees recovery of accurate Y under such conditions.
Authors: We agree that the manuscript does not contain a formal derivation or convergence proof for out-of-support conditioning, and that standard diffusion training alone does not guarantee recovery of Y. Our defense rests on the breadth of empirical evidence: the same trained model is applied without retraining to standard segmentation, cross-modality segmentation, few-shot (2–4 samples), degraded-input, sparse shape completion, and zero-shot tasks, all of which involve observation combinations absent from training. In revision we will add (i) an explicit characterization of the test-time loss landscape on held-out heterogeneous inputs and (ii) additional ablations that track optimization trajectories and final reconstruction fidelity when conditioning signals lie far from the training marginals. revision: partial
-
Referee: [Method] Method / Inference procedure (presumed §3): The description of gradient-based conditioning at inference time does not specify the precise form of the test-time loss, the number of optimization steps, or any regularization that would prevent the reverse process from drifting off the data manifold when multiple conflicting or novel observations must be satisfied simultaneously. Without these details or accompanying ablations, the zero-shot and cross-modality results cannot be interpreted as evidence that the claimed flexibility holds.
Authors: We accept that the current manuscript omits the exact mathematical form of the test-time loss, the optimization schedule, and any manifold-regularization terms. In the revised version we will (a) state the loss explicitly as a weighted sum of reconstruction errors on observed variables plus a small KL-regularizer on the latent code, (b) report the fixed number of gradient steps (200) and learning rate used across all experiments, and (c) include an ablation that varies step count and regularization strength on zero-shot and cross-modality cases to demonstrate stability. revision: yes
Circularity Check
No significant circularity in the generative reformulation
full rationale
The paper's core contribution is a methodological reframing: modeling the joint P(X,Y) via diffusion models and treating inference as test-time output optimization to enable flexible conditioning. This does not reduce any claimed result to its inputs by construction, nor does it rely on self-citations, fitted parameters renamed as predictions, or ansatzes smuggled from prior work. The abstract and described framework present an independent modeling choice evaluated on external benchmarks (including curated datasets), with no equations or steps that equate the output to the training objective or prior author results. The derivation chain remains self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models trained on paired medical data can model the joint distribution P(X,Y) accurately enough to support effective test-time conditioning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By guiding the generative process to match observed inputs, our framework enables flexible, gradient-based conditioning at inference time without architectural changes or retraining
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High-performance medicine: the convergence of human and artificial intelligence,
E. J. Topol, “High-performance medicine: the convergence of human and artificial intelligence,”Nature medicine, vol. 25, no. 1, pp. 44–56, 2019
work page 2019
-
[2]
Foundation models for generalist medical artificial intelligence,
M. Moor, O. Banerjee, Z. S. H. Abad, H. M. Krumholz, J. Leskovec, E. J. Topol, and P. Rajpurkar, “Foundation models for generalist medical artificial intelligence,”Nature, vol. 616, no. 7956, pp. 259–265, 2023
work page 2023
-
[3]
Reducing the workload of medical diagnosis through artificial intelligence: A narrative review,
J. Jeong, S. Kim, L. Pan, D. Hwang, D. Kim, J. Choi, Y . Kwon, P. Yi, J. Jeong, and S.-J. Yoo, “Reducing the workload of medical diagnosis through artificial intelligence: A narrative review,”Medicine, vol. 104, no. 6, p. e41470, 2025. 13
work page 2025
-
[4]
The clinical application of artificial intelligence in cancer precision treatment,
J. Wang, Z. Zeng, Z. Li, G. Liu, S. Zhang, C. Luo, S. Hu, S. Wan, and L. Zhao, “The clinical application of artificial intelligence in cancer precision treatment,”Journal of Translational Medicine, vol. 23, no. 1, p. 120, 2025
work page 2025
-
[5]
Ai-driven biomarker discovery: enhancing precision in cancer diagnosis and prognosis,
E. U. Alum, “Ai-driven biomarker discovery: enhancing precision in cancer diagnosis and prognosis,”Discover oncology, vol. 16, no. 1, p. 313, 2025
work page 2025
-
[6]
Optimal multiple surface segmentation with shape and context priors,
Q. Song, J. Bai, M. K. Garvin, M. Sonka, J. M. Buatti, and X. Wu, “Optimal multiple surface segmentation with shape and context priors,” IEEE transactions on medical imaging, vol. 32, no. 2, pp. 376–386, 2012
work page 2012
-
[7]
J. Zhu, B. Bolsterlee, Y . Song, and E. Meijering, “Improving cross- domain generalizability of medical image segmentation using uncer- tainty and shape-aware continual test-time domain adaptation,”Medical Image Analysis, vol. 101, p. 103422, 2025
work page 2025
-
[8]
Tuning vision foundation models for rectal cancer segmentation from ct scans,
H. Zhang, W. Guo, S. Wan, B. Zou, W. Wang, C. Qiu, K. Liu, P. Jin, and J. Yang, “Tuning vision foundation models for rectal cancer segmentation from ct scans,”Communications Medicine, vol. 5, no. 1, p. 256, 2025
work page 2025
-
[9]
Medshapenet–a large-scale dataset of 3d medical shapes for computer vision,
J. Li, Z. Zhou, J. Yang, A. Pepe, C. Gsaxner, G. Luijten, C. Qu, T. Zhang, X. Chen, W. Liet al., “Medshapenet–a large-scale dataset of 3d medical shapes for computer vision,”Biomedical Engineering/Biomedizinische Technik, vol. 70, no. 1, pp. 71–90, 2025
work page 2025
-
[10]
Clip-driven universal model for organ segmentation and tumor detection,
J. Liu, Y . Zhang, J.-N. Chen, J. Xiao, Y . Lu, B. A Landman, Y . Yuan, A. Yuille, Y . Tang, and Z. Zhou, “Clip-driven universal model for organ segmentation and tumor detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 21 152–21 164
work page 2023
-
[11]
Template-guided reconstruction of pulmonary segments with neural implicit functions,
K. Xie, Y . Zhu, K. Kuang, L. Zhang, H. B. Li, M. Gao, and J. Yang, “Template-guided reconstruction of pulmonary segments with neural implicit functions,”Medical Image Analysis, p. 103916, 2025
work page 2025
-
[12]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,”Nature methods, vol. 18, no. 2, pp. 203–211, 2021
work page 2021
-
[13]
Medsegdiff-v2: Diffusion- based medical image segmentation with transformer,
J. Wu, W. Ji, H. Fu, M. Xu, Y . Jin, and Y . Xu, “Medsegdiff-v2: Diffusion- based medical image segmentation with transformer,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 6, 2024, pp. 6030–6038
work page 2024
-
[14]
Multi-task learning for medical foundation models,
J. Yang, “Multi-task learning for medical foundation models,”Nature Computational Science, vol. 4, no. 7, pp. 473–474, 2024
work page 2024
-
[15]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inConference on Computer Vision and Pattern Recognition, 2023, pp. 4015–4026
work page 2023
-
[16]
Segment anything in medical images,
J. Ma, Y . He, F. Li, L. Han, C. You, and B. Wang, “Segment anything in medical images,”Nature Communications, vol. 15, no. 1, p. 654, 2024
work page 2024
-
[17]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[18]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inConference on Computer Vision and Pattern Recognition, 2022, pp. 10 684–10 695
work page 2022
-
[19]
B. Sauvalle and M. Salzmann, “Hybrid diffusion models: combining supervised and generative pretraining for label-efficient fine-tuning of segmentation models,”arXiv preprint arXiv:2408.03433, 2024
-
[20]
A simple approach to unifying diffusion-based conditional generation,
X. Li, C. Herrmann, K. C. Chan, Y . Li, D. Sun, C. Ma, and M.-H. Yang, “A simple approach to unifying diffusion-based conditional generation,” inInternational Conference on Learning Representations, 2025
work page 2025
-
[21]
DiffAtlas: Genai-Fying Atlas Segmentation via Image-Mask Diffusion,
H. Zhang, Y . Liu, J. Yang, W. Guo, X. Wang, and P. Fua, “DiffAtlas: Genai-Fying Atlas Segmentation via Image-Mask Diffusion,” inConfer- ence on Medical Image Computing and Computer Assisted Intervention, 2025
work page 2025
-
[22]
European respiratory society guidelines for the management of adult bronchiectasis,
E. Polverino, P. C. Goeminne, M. J. McDonnell, S. Aliberti, S. E. Mar- shall, M. R. Loebinger, M. Murris, R. Cant ´on, A. Torres, K. Dimakou et al., “European respiratory society guidelines for the management of adult bronchiectasis,”European Respiratory Journal, vol. 50, no. 3, 2017
work page 2017
-
[23]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- ference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241
work page 2015
-
[24]
H. Wang, P. Cao, J. Wang, and O. R. Zaiane, “Uctransnet: rethinking the skip connections in u-net from a channel-wise perspective with trans- former,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 3, 2022, pp. 2441–2449
work page 2022
-
[25]
D. T. Kushnure and S. N. Talbar, “Ms-unet: A multi-scale unet with fea- ture recalibration approach for automatic liver and tumor segmentation in ct images,”Computerized Medical Imaging and Graphics, vol. 89, p. 101885, 2021
work page 2021
-
[26]
Adversarial confidence learning for medical image segmentation and synthesis,
D. Nie and D. Shen, “Adversarial confidence learning for medical image segmentation and synthesis,”International journal of computer vision, vol. 128, no. 10, pp. 2494–2513, 2020
work page 2020
-
[27]
Interactive few-shot learning: Limited supervision, better medical im- age segmentation,
R. Feng, X. Zheng, T. Gao, J. Chen, W. Wang, D. Z. Chen, and J. Wu, “Interactive few-shot learning: Limited supervision, better medical im- age segmentation,”IEEE Transactions on Medical Imaging, vol. 40, no. 10, pp. 2575–2588, 2021
work page 2021
-
[28]
Cross-modality multi-atlas segmentation via deep registration and label fusion,
W. Ding, L. Li, X. Zhuang, and L. Huang, “Cross-modality multi-atlas segmentation via deep registration and label fusion,”IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 7, pp. 3104–3115, 2022
work page 2022
-
[29]
Medsegbench: A comprehensive benchmark for medical image segmentation in diverse data modalities,
Z. Kus ¸ and M. Aydin, “Medsegbench: A comprehensive benchmark for medical image segmentation in diverse data modalities,”Scientific Data, vol. 11, no. 1, p. 1283, 2024
work page 2024
-
[30]
Hidiff: hybrid dif- fusion framework for medical image segmentation,
T. Chen, C. Wang, Z. Chen, Y . Lei, and H. Shan, “Hidiff: hybrid dif- fusion framework for medical image segmentation,”IEEE Transactions on Medical Imaging, 2024
work page 2024
-
[31]
Diffuseg: domain-driven diffusion for medical image segmentation,
L. Zhang, F. Wu, K. Bronik, and B. W. Papiez, “Diffuseg: domain-driven diffusion for medical image segmentation,”IEEE Journal of Biomedical and Health Informatics, vol. 29, no. 5, pp. 3619–3631, 2025
work page 2025
-
[32]
X. Zhuang, L. Li, C. Payer, D. ˇStern, M. Urschler, M. P. Heinrich, J. Oster, C. Wang, ¨O. Smedby, C. Bianet al., “Evaluation of algorithms for multi-modality whole heart segmentation: an open-access grand challenge,”Medical image analysis, vol. 58, p. 101537, 2019
work page 2019
-
[33]
Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine,
Y . Xie, C. Zhou, L. Gao, J. Wu, X. Li, H.-Y . Zhou, S. Liu, L. Xing, J. Zou, C. Xieet al., “Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[34]
Saros: A dataset for whole-body region and organ segmentation in ct imaging,
S. Koitka, G. Baldini, L. Kroll, N. van Landeghem, O. B. Pollok, J. Haubold, O. Pelka, M. Kim, J. Kleesiek, F. Nensaet al., “Saros: A dataset for whole-body region and organ segmentation in ct imaging,” Scientific Data, vol. 11, no. 1, p. 483, 2024
work page 2024
-
[35]
W. Li, C. Qu, X. Chen, P. R. Bassi, Y . Shi, Y . Lai, Q. Yu, H. Xue, Y . Chen, X. Linet al., “Abdomenatlas: A large-scale, detailed-annotated, & multi-center dataset for efficient transfer learning and open algorith- mic benchmarking,”Medical Image Analysis, vol. 97, p. 103285, 2024
work page 2024
-
[36]
Medical image segmentation review: The success of u-net,
R. Azad, E. K. Aghdam, A. Rauland, Y . Jia, A. H. Avval, A. Bozorgpour, S. Karimijafarbigloo, J. P. Cohen, E. Adeli, and D. Merhof, “Medical image segmentation review: The success of u-net,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[37]
Image registration of whole-body mouse mri,
X. J. Chen, S. Maheswaran, D. Ruckert, and R. M. Henkelman, “Image registration of whole-body mouse mri,” in2010 IEEE International Symposium on Biomedical Imaging: From Nano to Macro. IEEE, 2010, pp. 1063–1064
work page 2010
-
[38]
W. Bai, W. Shi, A. de Marvao, T. J. Dawes, D. P. O’Regan, S. A. Cook, and D. Rueckert, “A bi-ventricular cardiac atlas built from 1000+ high resolution mr images of healthy subjects and an analysis of shape and motion,”Medical image analysis, vol. 26, no. 1, pp. 133–145, 2015
work page 2015
-
[39]
Sdfusion: Multimodal 3d shape completion, reconstruction, and gener- ation,
Y .-C. Cheng, H.-Y . Lee, S. Tulyakov, A. G. Schwing, and L.-Y . Gui, “Sdfusion: Multimodal 3d shape completion, reconstruction, and gener- ation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4456–4465
work page 2023
-
[40]
Diffusion-sdf: Text-to-shape via voxelized diffusion,
M. Li, Y . Duan, J. Zhou, and J. Lu, “Diffusion-sdf: Text-to-shape via voxelized diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 12 642–12 651
work page 2023
-
[41]
Octfusion: Octree-based diffusion models for 3d shape generation,
B. Xiong, S.-T. Wei, X.-Y . Zheng, Y .-P. Cao, Z. Lian, and P.-S. Wang, “Octfusion: Octree-based diffusion models for 3d shape generation,” in Computer Graphics Forum, vol. 44, no. 5. Wiley Online Library, 2025, p. e70198
work page 2025
-
[42]
High-fidelity medical shape generation via skeletal latent diffusion,
G. Zhang, J. Yang, S. Chen, A. Zhang, and Y . Li, “High-fidelity medical shape generation via skeletal latent diffusion,”arXiv preprint arXiv:2603.07504, 2026
-
[43]
H. Wang, Z. Liu, K. Sun, X. Wang, D. Shen, and Z. Cui, “3d meddiffusion: A 3d medical latent diffusion model for controllable and high-quality medical image generation,”IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[44]
Dora: Sampling and benchmarking for 3d shape variational auto-encoders,
R. Chen, J. Zhang, Y . Liang, G. Luo, W. Li, J. Liu, X. Li, X. Long, J. Feng, and P. Tan, “Dora: Sampling and benchmarking for 3d shape variational auto-encoders,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 251–16 261
work page 2025
-
[45]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Z. Zhao, Z. Lai, Q. Lin, Y . Zhao, H. Liu, S. Yang, Y . Feng, M. Yang, S. Zhang, X. Yanget al., “Hunyuan3d 2.0: Scaling diffusion mod- els for high resolution textured 3d assets generation,”arXiv preprint arXiv:2501.12202, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Topology- preserving shape reconstruction and registration via neural diffeomor- phic flow,
S. Sun, K. Han, D. Kong, H. Tang, X. Yan, and X. Xie, “Topology- preserving shape reconstruction and registration via neural diffeomor- phic flow,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 845–20 855
work page 2022
-
[47]
ShapeNet: An Information-Rich 3D Model Repository
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Suet al., “Shapenet: An information- rich 3d model repository,”arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[48]
Shape completion in the dark: completing vertebrae morphology from 3d ultrasound,
M.-A. Gafencu, Y . Velikova, M. Saleh, T. Ungi, N. Navab, T. Wendler, and M. F. Azampour, “Shape completion in the dark: completing vertebrae morphology from 3d ultrasound,”International Journal of Computer Assisted Radiology and Surgery, vol. 19, no. 7, pp. 1339– 1347, 2024
work page 2024
-
[49]
K. Xie, J. Yang, D. Wei, Z. Weng, and P. Fua, “Efficient anatomical la- beling of pulmonary tree structures via deep point-graph representation- based implicit fields,”Medical image analysis, vol. 99, p. 103367, 2025
work page 2025
-
[50]
Denoising Diffusion Implicit Models,
J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[51]
Flow Matching for Generative Modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow Matching for Generative Modeling,” inarXiv Preprint, 2022
work page 2022
-
[52]
Analysis of classifier-free guidance weight schedulers,
W. Xi, N. Dufour, N. Andreou, C. Marie-Paule, V . F. Abrevaya, D. Pi- card, and V . Kalogeiton, “Analysis of classifier-free guidance weight schedulers,”Transactions on Machine Learning Research, 2024
work page 2024
-
[53]
Eliminating oversaturation and artifacts of high guidance scales in diffusion models,
S. Sadat, O. Hilliges, and R. M. Weber, “Eliminating oversaturation and artifacts of high guidance scales in diffusion models,” inThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[54]
Rectified cfg++ for flow based models,
S. Saini, S. Gupta, and A. Bovik, “Rectified cfg++ for flow based models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[55]
Cfg-zero*: Improved classifier-free guidance for flow matching models,
W. Fan, A. Y . Zheng, R. A. Yeh, and Z. Liu, “Cfg-zero*: Improved classifier-free guidance for flow matching models,”arXiv preprint arXiv:2503.18886, 2025
-
[56]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
work page 2021
-
[57]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
arXiv preprint arXiv:2512.00422 , year=
Y . You, C. Zhao, H. Zhang, M. Xu, and P. Fua, “Physgen: Physically grounded 3d shape generation for industrial design,”arXiv preprint arXiv:2512.00422, 2025
-
[59]
Diffusion-based planning for autonomous driv- ing with flexible guidance,
Y . Zheng, R. Liang, K. ZHENG, J. Zheng, L. Mao, J. Li, W. Gu, R. Ai, S. E. Li, X. Zhanet al., “Diffusion-based planning for autonomous driv- ing with flexible guidance,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[60]
Diffusion-es: Gradient-free planning with diffusion for autonomous and instruction-guided driving,
B. Yang, H. Su, N. Gkanatsios, T.-W. Ke, A. Jain, J. Schneider, and K. Fragkiadaki, “Diffusion-es: Gradient-free planning with diffusion for autonomous and instruction-guided driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 342–15 353
work page 2024
-
[61]
Pidiff: Physics informed diffusion model for protein pocket-specific 3d molecular generation,
S. Choi, S. Seo, B. J. Kim, C. Park, and S. Park, “Pidiff: Physics informed diffusion model for protein pocket-specific 3d molecular generation,”Computers in Biology and Medicine, vol. 180, p. 108865, 2024
work page 2024
-
[62]
D-Flow: Differen- tiating through Flows for Controlled Generation, July 2024
H. Ben-Hamu, O. Puny, I. Gat, B. Karrer, U. Singer, and Y . Lipman, “D-flow: Differentiating through flows for controlled generation,”arXiv preprint arXiv:2402.14017, 2024
-
[63]
Loss-guided diffusion models for plug-and-play con- trollable generation,
J. Song, Q. Zhang, H. Yin, M. Mardani, M.-Y . Liu, J. Kautz, Y . Chen, and A. Vahdat, “Loss-guided diffusion models for plug-and-play con- trollable generation,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 32 483–32 498
work page 2023
-
[64]
A general framework for inference-time scaling and steering of diffusion models,
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath, “A general framework for inference-time scaling and steering of diffusion models,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[65]
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,” inInternational MICCAI brainlesion workshop. Springer, 2021, pp. 272–284
work page 2021
-
[66]
M. Gunawardhana and N. Zolek, “A comprehensive benchmarking and systematic analysis of deep learning models for sonomammogram seg- mentation,” inMedical Imaging with Deep Learning-Validation Papers, 2026
work page 2026
-
[67]
Mim: Mask in mask self-supervised pre-training for 3d medical image analysis,
J. Zhuang, L. Wu, Q. Wang, P. Fei, V . Vardhanabhuti, L. Luo, and H. Chen, “Mim: Mask in mask self-supervised pre-training for 3d medical image analysis,”IEEE transactions on medical imaging, 2025
work page 2025
-
[68]
Atlasnet: Multi-atlas non-linear deep networks for medical image segmentation,
M. Vakalopoulou, G. Chassagnon, N. Bus, R. Marini, E. I. Zacharaki, M.-P. Revel, and N. Paragios, “Atlasnet: Multi-atlas non-linear deep networks for medical image segmentation,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2018, pp. 658–666
work page 2018
-
[69]
Medical image segmentation with deep atlas prior,
H. Huang, H. Zheng, L. Lin, M. Cai, H. Hu, Q. Zhang, Q. Chen, Y . Iwamoto, X. Han, Y .-W. Chenet al., “Medical image segmentation with deep atlas prior,”IEEE transactions on medical imaging, vol. 40, no. 12, pp. 3519–3530, 2021
work page 2021
-
[70]
Diffatlas: Genai-fying atlas segmentation via image-mask diffusion,
H. Zhang, Y . Liu, J. Yang, W. Guo, X. Wang, and P. Fua, “Diffatlas: Genai-fying atlas segmentation via image-mask diffusion,” inInterna- tional Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2025, pp. 161–172
work page 2025
-
[71]
A comprehensive survey of foundation models in medicine,
W. Khan, S. Leem, K. B. See, J. K. Wong, S. Zhang, and R. Fang, “A comprehensive survey of foundation models in medicine,”IEEE Reviews in Biomedical Engineering, 2025
work page 2025
-
[72]
Dino-diffusion: Scaling medical diffu- sion models via self-supervised pre-training,
G. Jimenez-Perez, P. Os ´orio, J. Cersovsky, J. Montalt-Tordera, J. Hooge, S. V ogler, and S. Mohammadi, “Dino-diffusion: Scaling medical diffu- sion models via self-supervised pre-training,” inAnnual Conference on Medical Image Understanding and Analysis. Springer, 2025, pp. 257– 274
work page 2025
-
[73]
Multi-consistency for semi- supervised medical image segmentation via diffusion models,
Y . Chen, Y . Liu, M. Lu, L. Fu, and F. Yang, “Multi-consistency for semi- supervised medical image segmentation via diffusion models,”Pattern Recognition, vol. 161, p. 111216, 2025
work page 2025
-
[74]
Metrics reloaded: recommendations for image analysis validation,
L. Maier-Hein, A. Reinke, P. Godau, M. D. Tizabi, F. Buettner, E. Christodoulou, B. Glocker, F. Isensee, J. Kleesiek, M. Kozubeket al., “Metrics reloaded: recommendations for image analysis validation,” Nature methods, vol. 21, no. 2, pp. 195–212, 2024
work page 2024
-
[75]
DeepMind, “Surface-distance,” 2018. [Online]. Available: https://github. com/google-deepmind/surface-distance
work page 2018
-
[76]
Fundus2globe: Generative ai-driven 3d digital twins for personalized myopia management,
D. Shi, B. Liu, Z. Tian, Y . Wu, J. Yang, R. Chen, B. Yang, O. Xiao, and M. He, “Fundus2globe: Generative ai-driven 3d digital twins for personalized myopia management,”arXiv preprint arXiv:2502.13182, 2025
-
[77]
Lefusion: Synthesizing myocardial pathology on cardiac mri via lesion-focus diffusion models,
H. Zhang, J. Yang, S. Wan, and P. Fua, “Lefusion: Synthesizing myocardial pathology on cardiac mri via lesion-focus diffusion models,” arXiv e-prints, pp. arXiv–2403, 2024
work page 2024
-
[78]
Repaint: Inpainting Using Denoising Diffusion Probabilistic Models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. V . Gool, “Repaint: Inpainting Using Denoising Diffusion Probabilistic Models,” inConference on Computer Vision and Pattern Recognition, 2022, pp. 11 461–11 471
work page 2022
-
[79]
N. Heller, F. Isensee, D. Trofimova, R. Tejpaul, Z. Zhao, H. Chen, L. Wang, A. Golts, D. Khapun, D. Shatset al., “The kits21 challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase ct,”arXiv preprint arXiv:2307.01984, 2023
-
[80]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.