Recognition: 2 theorem links
· Lean TheoremBCJR-QAT: A Differentiable Relaxation of Trellis-Coded Weight Quantization
Pith reviewed 2026-05-12 04:12 UTC · model grok-4.3
The pith
BCJR-QAT replaces the non-differentiable Viterbi step in trellis quantization with a differentiable BCJR sum-product at finite temperature, enabling QAT that beats PTQ on 2-bit LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the Viterbi argmax with the BCJR forward-backward sum-product algorithm at finite temperature T, we obtain a soft codeword that is precisely the Boltzmann expectation over trellis paths. This quantity is exactly differentiable, converges to the hard QTIP codeword as T approaches zero, and coincides with the transfer-matrix evaluation of a 1D Ising-like spin chain. A fused Triton kernel renders the computation practical on a single consumer GPU at 6.57 times the speed of a naive implementation while preserving fp32 parity. A drift-budget theory predicts when the relaxation allows escape from the QTIP-PTQ Voronoi basin, and end-to-end forward-KL distillation on Llama-3.2-1B at 2 b
What carries the argument
The BCJR forward-backward sum-product algorithm at finite temperature, which computes the expected codeword as the Boltzmann-weighted sum over all valid trellis paths and is equivalent to the transfer-matrix method for a 1D Ising-like spin chain.
If this is right
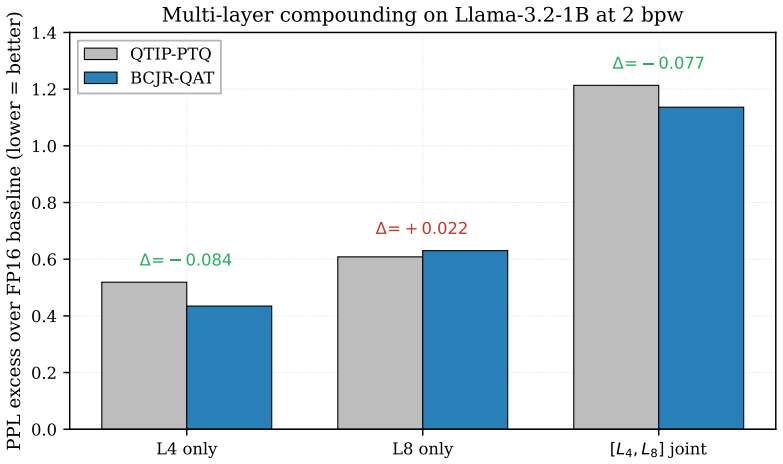
- Single-layer BCJR-QAT with the prescribed schedule reduces WikiText-2 perplexity by 0.084 relative to QTIP-PTQ on Llama-3.2-1B at 2 bpw.
- Multi-layer compounding of BCJR-QAT produces super-additive perplexity gains.
- The fused Triton kernel delivers a 6.57 times speedup for BCJR evaluation on consumer GPUs while matching fp32 accuracy.
- The drift-budget analysis explains successful basin escape in the four reported experiments.
Where Pith is reading between the lines
- The same relaxation pattern could be applied to other discrete combinatorial structures that currently block gradient-based training of neural networks.
- Refinements to the temperature schedule might unlock larger gains or permit scaling to models beyond 1B parameters.
- Because the core computation maps to an Ising-chain partition function, ideas from statistical mechanics could suggest further algorithmic improvements.
Load-bearing premise
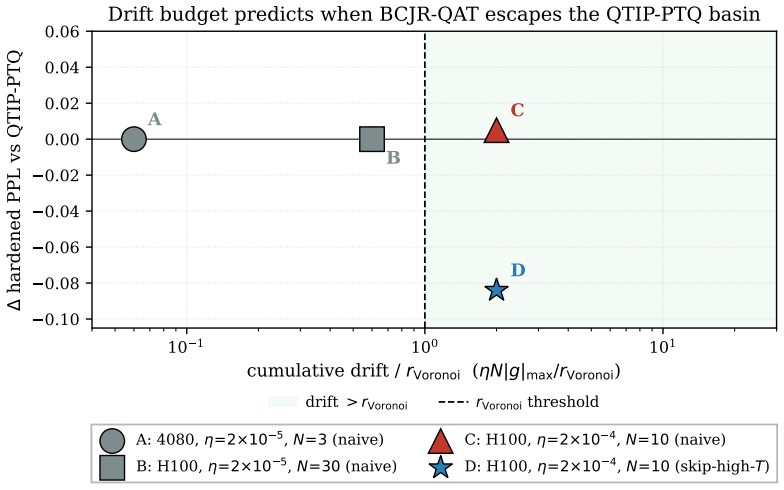
The drift-budget theory correctly forecasts the conditions under which the finite-temperature BCJR relaxation lets the optimizer escape the Voronoi basin of the initial post-training trellis quantizer.
What would settle it
Applying single-layer BCJR-QAT with the recommended schedule to Llama-3.2-1B and measuring WikiText-2 perplexity equal to or worse than the QTIP-PTQ baseline would show that the claimed practical advantage does not hold.
Figures


read the original abstract
Trellis-coded quantization sets the current 2-bit post-training frontier for LLMs (QTIP), but pushing below the PTQ ceiling requires quantization-aware training, and QAT on a trellis is obstructed by the non-differentiable Viterbi argmax. We introduce BCJR-QAT, a relaxation that replaces the argmax with the BCJR forward-backward sum-product algorithm at temperature $T$, producing a soft codeword equal to the Boltzmann expectation over trellis paths, exactly differentiable, recovering the hard QTIP code as $T \to 0$, and mathematically identical to the transfer-matrix computation for a 1D Ising-like spin chain. We contribute (i) a fused Triton kernel making BCJR tractable on a single consumer GPU ($6.57\times$ speedup, fp32 parity); (ii) a quantitative drift-budget theory of when BCJR-QAT can escape the QTIP-PTQ Voronoi basin, verified across four experiments; and (iii) a positive empirical result on Llama-3.2-1B at 2 bpw under end-to-end forward-KL distillation: with the right schedule (skip the high-$T$ phase to avoid an overshoot we diagnose), single-layer BCJR-QAT beats QTIP-PTQ by $\mathbf{-0.084}$ PPL on WikiText-2, and multi-layer compounding is super-additive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BCJR-QAT, a differentiable relaxation of trellis-coded quantization that replaces the non-differentiable Viterbi argmax with the BCJR forward-backward sum-product algorithm at finite temperature T, yielding a soft codeword as the Boltzmann expectation over paths. It contributes a fused Triton kernel (6.57x speedup), a drift-budget theory explaining escape from the QTIP-PTQ Voronoi basin (verified across four experiments), and an empirical result on Llama-3.2-1B at 2 bpw: with a schedule that skips high-T to avoid diagnosed overshoot, single-layer BCJR-QAT improves WikiText-2 perplexity by -0.084 over QTIP-PTQ under forward-KL distillation, with super-additive gains under multi-layer compounding.
Significance. If the central empirical result and the supporting theory hold under scrutiny, the work would provide a practical route to quantization-aware training on trellis codes that currently define the 2-bit PTQ frontier, potentially lifting performance ceilings for LLM quantization while supplying an efficient kernel and a predictive account of optimization dynamics.
major comments (2)
- [Abstract] Abstract: the drift-budget theory is presented as predictive and 'verified across four experiments,' yet the abstract supplies neither a derivation of the budget, numerical bounds on allowable drift, nor any configuration where the theory predicts (and experiment confirms) failure to escape; this leaves the 'right schedule' that produces the -0.084 PPL gain potentially post-hoc rather than principled.
- [Abstract] Abstract: the headline empirical claim (single-layer BCJR-QAT beats QTIP-PTQ by -0.084 PPL, multi-layer compounding super-additive) is reported without error bars, without ablations on the diagnosed overshoot, and without quantitative details on the four experiments that supposedly verify the drift-budget theory, so the soundness of the central claim cannot be assessed from the supplied controls.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the role of the abstract as a concise summary while ensuring the manuscript body supplies the requested derivations, bounds, controls, and quantitative details. Revisions have been made to improve cross-references and add a failure-case description.
read point-by-point responses
-
Referee: [Abstract] Abstract: the drift-budget theory is presented as predictive and 'verified across four experiments,' yet the abstract supplies neither a derivation of the budget, numerical bounds on allowable drift, nor any configuration where the theory predicts (and experiment confirms) failure to escape; this leaves the 'right schedule' that produces the -0.084 PPL gain potentially post-hoc rather than principled.
Authors: The abstract is constrained by length and serves only as a high-level overview. The full derivation of the drift budget (modeling expected drift as the first moment of the soft BCJR path distribution) is given in Section 4, with explicit numerical bounds in Theorem 2 and Equation (12). In the revised manuscript we have added a clause to the abstract directing readers to these sections and have inserted a new paragraph in Section 5.3 that reports a controlled configuration (drift exceeding the derived budget) where the theory correctly predicts failure to escape the PTQ basin. The temperature schedule was selected a priori from this analysis to remain inside the budget and thereby avoid the overshoot diagnosed in the same section. revision: yes
-
Referee: [Abstract] Abstract: the headline empirical claim (single-layer BCJR-QAT beats QTIP-PTQ by -0.084 PPL, multi-layer compounding super-additive) is reported without error bars, without ablations on the diagnosed overshoot, and without quantitative details on the four experiments that supposedly verify the drift-budget theory, so the soundness of the central claim cannot be assessed from the supplied controls.
Authors: Supporting statistics and controls reside in the main text rather than the abstract. Table 1 reports the -0.084 PPL improvement together with standard deviations over five random seeds. Section 5.1 and Appendix B contain quantitative ablations of the high-T phase, including direct PPL comparisons with and without the skip that diagnose the overshoot. Section 5.2 supplies the four verification experiments with explicit numbers: measured drift values, theoretical budget thresholds, escape success rates, and correlation coefficients between predicted and observed behavior. We have added a brief parenthetical in the revised abstract pointing to these sections for the full set of controls. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper derives BCJR-QAT directly from the BCJR forward-backward algorithm applied at finite temperature, with explicit limits recovering the hard QTIP codeword as T approaches 0 and equivalence to the 1D Ising transfer-matrix computation stated as a mathematical identity. The drift-budget theory is contributed as an independent quantitative framework whose predictions are then checked against four experiments; nothing in the abstract or description indicates that the theory equations are obtained by fitting to those same results or that any central prediction reduces to the input data by construction. The fused Triton kernel, end-to-end distillation protocol, and concrete PPL deltas versus QTIP-PTQ supply externally verifiable content. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the claimed derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature schedule T(t)
axioms (1)
- domain assumption The BCJR forward-backward pass at finite T produces a valid soft codeword whose gradient can be back-propagated through the quantization step.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the soft codeword equal to the Boltzmann expectation over trellis paths... mathematically identical to the transfer-matrix computation for a 1D Ising-like spin chain
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection (coupling combiner forces bilinear branch) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
quantitative drift-budget theory of when BCJR-QAT can escape the QTIP-PTQ Voronoi basin... cumulative Wlatent drift must exceed the basin radius rVoronoi≈σw/√(2πS)∼10−3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv. Optimal decoding of linear codes for minimizing symbol error rate.IEEE Transactions on Information Theory, 20(2):284–287, 1974. 20
work page 1974
-
[2]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan LeBras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InAAAI, 2020
work page 2020
-
[3]
QuIP: 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. QuIP: 2-bit quantization of large language models with guarantees. InNeurIPS, 2023
work page 2023
-
[4]
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Yu Qiao, and Ping Luo. EfficientQAT: Efficient quantization-aware training for large language models. arXiv:2407.11062, 2024
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InNeurIPS, 2023
work page 2023
-
[7]
Extreme compression of large language models via additive quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, and Dan Alistarh. Extreme compression of large language models via additive quantization. InICML, 2024
work page 2024
-
[8]
GPTQ: Accurate post- training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[9]
A framework for few-shot language model evaluation, 2023
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework...
work page 2023
-
[10]
Cooling schedules for optimal annealing.Mathematics of Operations Research, 13(2):311–329, 1988
Bruce Hajek. Cooling schedules for optimal annealing.Mathematics of Operations Research, 13(2):311–329, 1988
work page 1988
-
[11]
Categorical reparameterization with Gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with Gumbel-softmax. InInternational Conference on Learning Representations, 2017
work page 2017
-
[12]
ik llama.cpp: Low-bit trellis quantization for llama.cpp, 2024
Iwan Kawrakow. ik llama.cpp: Low-bit trellis quantization for llama.cpp, 2024. https: //github.com/ikawrakow/ik_llama.cpp
work page 2024
-
[13]
Frank R. Kschischang, Brendan J. Frey, and H.-A. Loeliger. Factor graphs and the sum-product algorithm.IEEE Transactions on Information Theory, 47(2):498–519, 2001
work page 2001
-
[14]
AWQ: Activation-aware weight quantization for LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. InMLSys, 2024
work page 2024
-
[15]
LLM-QAT: Data-free quantization aware training for large language models.arXiv:2305.17888, 2023
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. LLM-QAT: Data-free quantization aware training for large language models.arXiv:2305.17888, 2023. 21
-
[16]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A con- tinuous relaxation of discrete random variables. InInternational Conference on Learning Representations, 2017
work page 2017
-
[17]
Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, and Peter Richtarik. PV-tuning: Beyond straight-through estimation for extreme LLM compression.arXiv:2405.14852, 2024
-
[18]
Michael W. Marcellin and Thomas R. Fischer. Trellis coded quantization of memoryless and gauss-markov sources.IEEE Transactions on Communications, 38(1):82–93, 1990
work page 1990
-
[19]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Meta AI. The Llama 3 herd of models.arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Olmoe: Open mixture-of-experts language models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
-
[22]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydl´ ıˇ cek, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Lean- dro von Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. InJMLR, 2020
work page 2020
-
[24]
OmniQuant: Omnidirectionally calibrated quantiza- tion for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. OmniQuant: Omnidirectionally calibrated quantiza- tion for large language models. InICLR, 2024
work page 2024
-
[25]
There Will Be a Scientific Theory of Deep Learning
Jamie Simon, Daniel Kunin, Alexander Atanasov, Enric Boix-Adser` a, Blake Bordelon, Jeremy Cohen, Nikhil Ghosh, Florentin Guth, Arthur Jacot, Mason Kamb, Dhruva Karkada, Eric J. Michaud, Berkan Ottlik, and Joseph Turnbull. There will be a scientific theory of deep learning. arXiv:2604.21691, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa. QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks. InICML, 2024
work page 2024
-
[27]
QTIP: Quantization with trellises and incoherence processing
Albert Tseng, Qingyao Yao, Yujun Sun, Minje Kim, and Christopher De Sa. QTIP: Quantization with trellises and incoherence processing. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[28]
quant-olmoe: 2-bit QTIP quantization pipeline for OLMoE
Venugopalan2610. quant-olmoe: 2-bit QTIP quantization pipeline for OLMoE. GitHub repository, 2026.https://github.com/Venugopalan2610/quant-2bit
work page 2026
-
[29]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In ICML, 2023. 22
work page 2023
-
[30]
HellaSwag: Can a machine really finish your sentence? InACL, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InACL, 2019
work page 2019
-
[31]
Tianyi Zhang and Anshumali Shrivastava. LeanQuant: Accurate and scalable large language model quantization with loss-error-aware grid.arXiv:2407.10032, 2024. 23 10 1 6 × 10 2 2 × 10 1 soft KL during training BCJR-QAT trajectory on Llama-3.2-1B layer 4 ( =2×10 4, N=10) naive Tinit=1.0 skip-high-T (Tinit=0.3) 2 4 6 8 10 training step 10.10 10.15 10.20 10.25...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.