Recognition: 2 theorem links
· Lean TheoremEvolving-RL: End-to-End Optimization of Experience-Driven Self-Evolving Capability within Agents
Pith reviewed 2026-05-12 05:10 UTC · model grok-4.3
The pith
Evolving-RL jointly optimizes experience extraction and utilization in language-model agents through separate reinforcement-learning signals from task evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
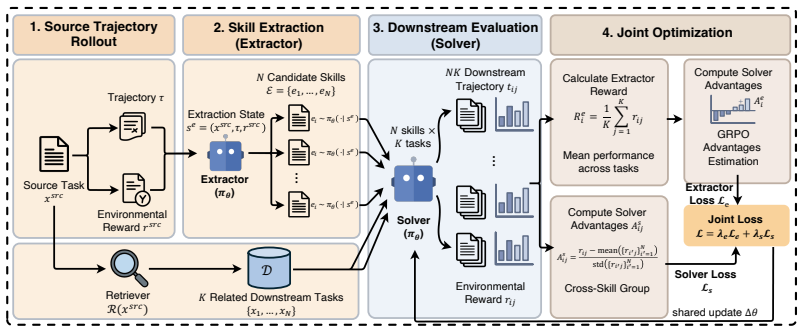
Evolving-RL centers the learning process on experience extraction and evaluation. It uses two supervisory signals derived from task evaluation to optimize the experience extractor and the solver separately, enabling their coordinated co-evolution. This produces strong performance gains on out-of-distribution tasks, reaching up to 98.7 percent relative improvement over the GRPO baseline on ALFWorld unseen tasks and 35.8 percent on Mind2Web. The gains require the coordinated co-evolution; separate optimization of either component alone does not unlock them. In addition, by internalizing reusable experience patterns into model parameters, Evolving-RL functions as an experience-augmented RL that
What carries the argument
Dual supervisory signals from task evaluation that separately optimize the experience extractor and the solver for coordinated co-evolution.
Load-bearing premise
Task evaluation can supply two distinct and reliable supervisory signals that improve the extractor and solver without one component dominating the other or the signals becoming misaligned.
What would settle it
Ablating one of the two supervisory signals during training and measuring whether the relative improvement on unseen tasks falls back to the level of the GRPO baseline.
Figures



read the original abstract
Experience-driven self-evolving agents aim to overcome the static nature of large language models by distilling reusable experience from past interactions, thus enabling adaptation to novel tasks at deployment time. This process places substantial demands on the foundation model's capacities for abstraction, generalization, and in-context learning. However, most existing studies focus primarily on system-level design choices, such as how experience is represented and managed, neglecting the inherent capabilities of the underlying model. While some recent works have started to optimize the experience utilization stage via reinforcement learning, they still fail to treat self-evolution as a unified process to be jointly optimized. To this end, we propose Evolving-RL, an efficient algorithmic framework that jointly improves the experience extraction and utilization capabilities required for self-evolution. Specifically, we center the learning process on experience extraction and evaluation, using the two supervisory signals derived from evaluation to optimize the extractor and solver separately and thus enable their coordinated co-evolution. Experiments on ALFWorld and Mind2Web show that Evolving-RL effectively enhances LLMs' ability to extract and reuse experience, leading to strong performance gains on out-of-distribution tasks (up to 98.7% relative improvement over the GRPO baseline on ALFWorld unseen tasks and 35.8% on Mind2Web), and these gains are fully unlocked only through the coordinated co-evolution of experience extraction and utilization. Furthermore, Evolving-RL inherently functions as an experience-augmented RL algorithm. By internalizing reusable experience patterns directly into model parameters, it achieves remarkable performance gains over standard baselines on both seen and unseen tasks, even in the absence of test-time experience accumulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Evolving-RL, a framework that jointly optimizes experience extraction and utilization for self-evolving LLM agents via reinforcement learning. It centers learning on experience extraction and evaluation, deriving two supervisory signals from task evaluation to optimize the extractor and solver separately, thereby enabling their coordinated co-evolution. On ALFWorld and Mind2Web, it reports large relative gains on out-of-distribution tasks (98.7% over GRPO on ALFWorld unseen, 35.8% on Mind2Web) that are asserted to be unlocked only by this coordination; the method is also presented as an experience-augmented RL algorithm that internalizes reusable patterns into parameters.
Significance. If the central empirical claims and the necessity of coordinated co-evolution hold after proper controls and ablations, the work would be significant for shifting self-evolving agent research from system-level design to end-to-end optimization of the underlying model's abstraction and reuse capabilities, with potential impact on generalization in embodied and web-agent domains.
major comments (3)
- [Abstract] Abstract: the assertion that gains 'are fully unlocked only through the coordinated co-evolution of experience extraction and utilization' is load-bearing for the central claim yet unsupported by any described ablation (e.g., freezing the extractor while continuing to train the solver, or vice versa) or explicit mechanism (distinct reward shaping, auxiliary losses, or gradient isolation) that would prevent credit-assignment failure or one component dominating the shared downstream task signal.
- [Abstract] Abstract / Experiments section: the reported relative improvements (98.7 % on ALFWorld unseen, 35.8 % on Mind2Web) are presented without any information on number of runs, statistical tests, variance, or the precise implementation of the GRPO baseline, rendering it impossible to assess whether the gains are robust or attributable to the proposed coordination rather than independent improvements.
- [Method] Method description: the use of 'two supervisory signals derived from evaluation to optimize the extractor and solver separately' is described at a high level but lacks concrete detail on how the upstream extraction decisions receive informative, non-sparse feedback from the downstream task reward, leaving the credit-assignment concern unaddressed in the optimization procedure.
minor comments (2)
- The paper would benefit from an explicit equation or pseudocode block showing how the two evaluation-derived signals are computed and back-propagated to each component.
- Clarify whether the 'experience-augmented RL' interpretation is a post-hoc observation or an intended design property, and provide a direct comparison to standard RL baselines without experience accumulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the empirical support and methodological clarity. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that gains 'are fully unlocked only through the coordinated co-evolution of experience extraction and utilization' is load-bearing for the central claim yet unsupported by any described ablation (e.g., freezing the extractor while continuing to train the solver, or vice versa) or explicit mechanism (distinct reward shaping, auxiliary losses, or gradient isolation) that would prevent credit-assignment failure or one component dominating the shared downstream task signal.
Authors: We agree that the strong claim in the abstract requires direct empirical backing via ablations. The current manuscript describes separate optimization via two supervisory signals derived from task evaluation to enable coordinated co-evolution, but does not include the requested freezing ablations. We will add these experiments (freezing the extractor while training the solver and vice versa) to the experiments section and update the abstract to reference the results showing that joint optimization is required for the full gains. revision: yes
-
Referee: [Abstract] Abstract / Experiments section: the reported relative improvements (98.7 % on ALFWorld unseen, 35.8 % on Mind2Web) are presented without any information on number of runs, statistical tests, variance, or the precise implementation of the GRPO baseline, rendering it impossible to assess whether the gains are robust or attributable to the proposed coordination rather than independent improvements.
Authors: This is a valid concern; the current version omits these details. In the revision we will report the number of independent runs, performance variance (standard deviations), results of statistical significance tests, and a precise description of the GRPO baseline implementation including hyperparameters and adaptation details. revision: yes
-
Referee: [Method] Method description: the use of 'two supervisory signals derived from evaluation to optimize the extractor and solver separately' is described at a high level but lacks concrete detail on how the upstream extraction decisions receive informative, non-sparse feedback from the downstream task reward, leaving the credit-assignment concern unaddressed in the optimization procedure.
Authors: The manuscript explains that the two signals come from downstream task evaluation, with the extractor's signal based on the utility of extracted experience for the solver. We acknowledge the description is high-level and does not fully detail the reward computation or gradient isolation. We will expand the method section with concrete reward formulations, equations showing how the extractor receives non-sparse feedback, and pseudocode for the separate optimization procedure. revision: yes
Circularity Check
No circularity: optimization uses external signals and presents co-evolution gains as empirical.
full rationale
The paper's framework centers on using two separate supervisory signals derived from task evaluation to optimize the extractor and solver. This is a standard RL setup with external task success/failure feedback rather than any self-referential definition or fitted input renamed as prediction. The assertion that gains are 'fully unlocked only through coordinated co-evolution' is framed as an experimental outcome on ALFWorld and Mind2Web (with reported relative improvements), not a mathematical reduction to inputs by construction. No equations, uniqueness theorems, or self-citations are invoked in a load-bearing way that collapses the derivation. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models possess capacities for abstraction, generalization, and in-context learning sufficient to support experience-driven self-evolution
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe center the learning process on experience extraction and evaluation, using the two supervisory signals derived from evaluation to optimize the extractor and solver separately and thus enable their coordinated co-evolution
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe final training objective is a weighted combination of the extractor and solver losses: L=λeLe + λsLs
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026. URLhttps://arxi...
work page internal anchor Pith review arXiv 2026
-
[2]
Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766,
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems, 2026. URLhttps://arxiv.org/abs/2603.02766
-
[3]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of se...
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[5]
arXiv preprint arXiv:2511.06449 , year=
Zhicheng Cai, Xinyuan Guo, Yu Pei, Jiangtao Feng, Jinsong Su, Jiangjie Chen, Ya-Qin Zhang, Wei-Ying Ma, Mingxuan Wang, and Hao Zhou. FLEX: Continuous agent evolution via forward learning from experience.arXiv preprint arXiv:2511.06449, 2025. doi: 10.48550/arXiv.2511.06449
-
[6]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution, 2026. URL https://arxiv.org/abs/2512.10696
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.arXiv preprint arXiv:2306.06070, 2023. doi: 10.48550/arXiv.2306.06070
-
[8]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V . Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024. URLhttps://arxiv.org/abs/2402.01680
work page internal anchor Pith review arXiv 2024
-
[9]
doi: 10.18653/v1/2023.findings-acl.67
Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. InFindings of the Association for Computational Linguistics: ACL 2023, pages 1049–1065, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.67. URL https://aclanthology.org/2023.findings-acl.67/
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_ files/paper/2022/file/8bb0d291acd4acf06ef112099c16f326-Paper-Conference.pdf
work page 2022
-
[12]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning, 2026. URLhttps://arxiv.org/abs/2603.16060
-
[13]
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[14]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver, 2026. URL https: //arxiv.org/abs/2604.08377
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
arXiv preprint arXiv:2603.17621 , year=
Dilxat Muhtar, Jiashun Liu, Wei Gao, Weixun Wang, Shaopan Xiong, Ju Huang, Siran Yang, Wenbo Su, Jiamang Wang, Ling Pan, and Bo Zheng. Complementary reinforcement learning, 2026. URL https://arxiv.org/abs/2603.17621. 10
-
[16]
Reasoningbank: Scaling agent self-evolving with reasoning memory
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory. InThe F ourteenth International Conference on Learning Represen...
work page 2026
-
[17]
Reasoning with language model prompting: A survey
Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. Reasoning with language model prompting: A survey. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5368–5393, Toronto, Canada, 2023. Association for Computational Ling...
-
[18]
Shuai Shao, Qihan Ren, Chen Qian, Boyi Wei, Dadi Guo, Jingyi Yang, Xinhao Song, Linfeng Zhang, Weinan Zhang, Dongrui Liu, and Jing Shao. Your agent may misevolve: Emergent risks in self-evolving llm agents, 2026. URLhttps://arxiv.org/abs/2509.26354
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, Daya Guo, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URL https://arxiv.org/abs/2402. 03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources
Shuaike Shen, Wenduo Cheng, Mingqian Ma, Alistair Turcan, Martin Jinye Zhang, and Jian Ma. Skill- foundry: Building self-evolving agent skill libraries from heterogeneous scientific resources, 2026. URL https://arxiv.org/abs/2604.03964
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. Experiential reinforce- ment learning, 2026. URLhttps://arxiv.org/abs/2602.13949
-
[22]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neu- ral Information Processing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ 1b44b878bb782e6954cd888628510e90-...
work page 2023
-
[23]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2021. doi: 10.48550/arXiv.2010.03768
work page internal anchor Pith review doi:10.48550/arxiv.2010.03768 2010
-
[24]
Xiangru Tang, Ge Zhang, Sirui Hong, Chenglin Wu, Hao Cheng, Jiaheng Liu, Wangchunshu Zhou, Xingyao Wang, He Zhu, Chi Wang, Peng Xia, Daniel Shao, Fang Wu, Xinming Wei, Tianhao Peng, Ziyang Zhou, Tingting Du, and Tianrui Qin. Agent kb: Leveraging cross-domain experience for agentic problem solving, 2025. URLhttps://arxiv.org/abs/2507.06229
-
[25]
Dynamic dual-granularity skill bank for agentic rl, 2026
Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao. Dynamic dual-granularity skill bank for agentic rl, 2026. URL https://arxiv.org/abs/2603. 28716
work page 2026
-
[26]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Ji- akai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345,
-
[27]
A survey on large language model based autonomous agents,
doi: 10.1007/s11704-024-40231-1. URL https://link.springer.com/article/10.1007/ s11704-024-40231-1
-
[28]
arXiv preprint arXiv:2409.07429 , year=
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory, 2024. URL https://arxiv.org/abs/2409.07429
-
[29]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Asso- ciates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/...
work page 2022
-
[30]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. Evolver: Self-evolving llm agents through an experience- driven lifecycle, 2025. URLhttps://arxiv.org/abs/2510.16079. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026. doi: 10.48550/arXiv.2602.08234
work page internal anchor Pith review doi:10.48550/arxiv.2602.08234 2026
-
[32]
Zhishang Xiang, Chengyi Yang, Zerui Chen, Zhimin Wei, Yunbo Tang, Zongpei Teng, Zexi Peng, Zongxia Li, Chengsong Huang, Yicheng He, Chang Yang, Xinrun Wang, Xiao Huang, Qinggang Zhang, and Jinsong Su. A systematic survey of self-evolving agents: From model-centric to environment-driven co-evolution, February 2026. URLhttps://doi.org/10.36227/techrxiv.1772...
-
[33]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Cops: Empowering llm agents with provable cross-task experience sharing, 2024
Chen Yang, Quanquan Gu, Chenyang Zhao, and Dongruo Zhou. Cops: Empowering llm agents with provable cross-task experience sharing, 2024. URLhttps://arxiv.org/abs/2410.16670
-
[35]
Cheng Yang, Xuemeng Yang, Licheng Wen, Daocheng Fu, Jianbiao Mei, Rong Wu, Pinlong Cai, Yufan Shen, Nianchen Deng, Botian Shi, Yu Qiao, and Haifeng Li. Learning on the job: An experience-driven self-evolving agent for long-horizon tasks, 2025. URLhttps://arxiv.org/abs/2510.08002
-
[36]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210. 03629
work page 2023
-
[37]
arXiv preprint arXiv:2603.08561 , year=
Xiaoying Zhang, Zichen Liu, Yipeng Zhang, Xia Hu, and Wenqi Shao. Retroagent: From solving to evolving via retrospective dual intrinsic feedback, 2026. URLhttps://arxiv.org/abs/2603.08561
-
[38]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. URL https://arxiv. org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Expel: Llm agents are experiential learners.arXiv preprint arXiv:2308.10144, 2023
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners.arXiv preprint arXiv:2308.10144, 2023. doi: 10.48550/arXiv.2308.10144
-
[40]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. Skillweaver: Web agents can self-improve by discovering and honing skills, 2025. URLhttps://arxiv.org/abs/2504.07079
work page internal anchor Pith review arXiv 2025
-
[41]
arXiv preprint arXiv:2508.16153 , year=
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and Jun Wang. Memento: Fine-tuning LLM agents without fine-tuning LLMs. arXiv preprint arXiv:2508.16153, 2025. doi: 10.48550/arXiv.2508.16153
-
[42]
Memento-skills: Let agents design agents
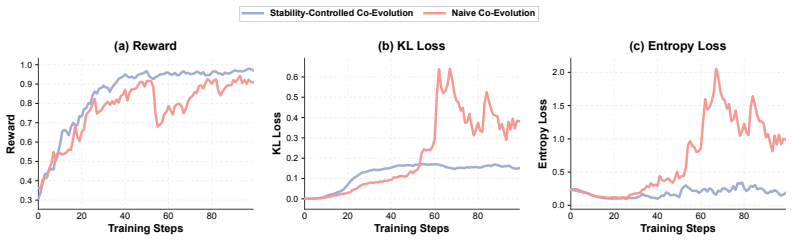
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, Runyu Yang, Qiangbin Liu, Xinlei Yu, Jianmin Zhou, Na Wang, Chunyang Sun, and Jun Wang. Memento-skills: Let agents design agents, 2026. URL https://arxiv. org/abs/2603.18743. 12 A Co-Evolution Stability A.1 Reliability of skill ev...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.