Recognition: 2 theorem links
· Lean TheoremA Spectral Framework for Closed-Form Relative Density Estimation
Pith reviewed 2026-05-12 04:02 UTC · model grok-4.3
The pith
Relative log-density estimation reduces to closed-form spectral formulas from first and second feature moments in linear models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By expressing the KL divergence as an integral of weighted chi-squared divergences, the authors obtain an explicit spectral formula that depends solely on first- and second-order feature moments and directly supplies closed-form estimators for both divergences and log-density potentials in linearly parameterized models, including unnormalized and conditional cases.
What carries the argument
The spectral formula obtained by converting the integral representation of KL divergence into a sequence of least-squares problems whose solutions are expressed through feature moments.
If this is right
- Estimators for a broad class of f-divergences are obtained in the same closed-form manner.
- The method combines directly with kernelization or with features learned by neural networks.
- Convergence guarantees apply to the resulting moment-based estimators.
- Empirical performance can be compared against logistic and softmax regression baselines on synthetic data.
Where Pith is reading between the lines
- The same moment-based route may simplify training of energy-based models by replacing variational bounds with explicit formulas.
- Conditional models that currently rely on softmax normalization could be replaced by direct closed-form ratio estimators in some settings.
- The framework suggests a moment-matching route to density-ratio estimation that could be tested on high-dimensional data with learned features.
Load-bearing premise
The probabilistic models must be linear in the chosen features and the chosen integral representation of the KL divergence must hold without further restrictions on those features.
What would settle it
Compute the closed-form estimator on a pair of simple Gaussians with known closed-form KL value and check whether the numerical result matches the analytic KL to machine precision.
Figures

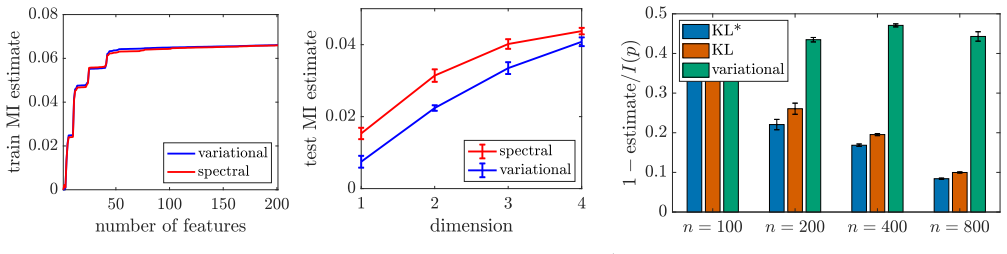


read the original abstract
We propose a closed-form spectral framework for relative log-density estimation in linearly parameterized probabilistic models, including unnormalized and conditional models. This is achieved by representing the Kullback-Leibler (KL) divergence as an integral of weighted chi-squared divergences, converting KL estimation into a family of least-squares problems. We derive an explicit spectral formula based only on first- and second-order feature moments, yielding closed-form estimators of both divergences and log-density potentials for fixed features. The framework extends to a broad class of f-divergences and can be combined with kernelization or feature learning with neural networks. We prove convergence guarantees for the resulting estimators and empirically compare them on synthetic data with optimization-based variational formulations, including logistic and softmax regression for normalized conditional models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a closed-form spectral framework for relative log-density estimation in linearly parameterized probabilistic models (including unnormalized and conditional ones). It represents the KL divergence as an integral of weighted chi-squared divergences, converts the problem into a family of least-squares problems, and derives an explicit spectral formula using only first- and second-order moments of fixed features. This yields closed-form estimators for divergences and log-density potentials. The framework extends to f-divergences, supports kernelization or neural feature learning, includes convergence guarantees, and is empirically compared to optimization-based variational methods on synthetic data.
Significance. If the central derivations hold, the work provides an efficient closed-form alternative to variational optimization for density ratio and divergence estimation in a broad class of models. The explicit use of moment-based spectral formulas, combined with proved convergence rates and direct empirical comparisons (including logistic/softmax regression), represents a practical and theoretically grounded contribution that could simplify computations in unnormalized models and integrate with modern feature learning techniques.
major comments (1)
- [§3] §3 (derivation of the spectral formula): The conversion of KL(p||q) into an integral of weighted chi-squared divergences is load-bearing for the closed-form claim, yet the manuscript does not explicitly state the required conditions on the feature functions (e.g., boundedness, completeness of the span, or absolute continuity to eliminate residual cross-terms). Without these, the subsequent least-squares spectral estimator may not be unbiased for the true KL, undermining the convergence guarantees stated in §4.
minor comments (2)
- [§3] Notation for the weighting measure in the integral representation (around Eq. (5)) is introduced without a clear definition of its support or normalization, which could confuse readers when extending to conditional models.
- [§5] The experimental section compares against logistic and softmax regression but does not report the exact feature dimension or regularization values used in the spectral estimator, making reproducibility of the reported error curves difficult.
Simulated Author's Rebuttal
We thank the referee for their detailed review and insightful comments on our manuscript. We address the major comment point by point below, and we will revise the paper to incorporate the necessary clarifications.
read point-by-point responses
-
Referee: [§3] §3 (derivation of the spectral formula): The conversion of KL(p||q) into an integral of weighted chi-squared divergences is load-bearing for the closed-form claim, yet the manuscript does not explicitly state the required conditions on the feature functions (e.g., boundedness, completeness of the span, or absolute continuity to eliminate residual cross-terms). Without these, the subsequent least-squares spectral estimator may not be unbiased for the true KL, undermining the convergence guarantees stated in §4.
Authors: We agree that explicitly stating the conditions on the feature functions is important for rigor. In the derivation of the spectral formula in §3, we implicitly rely on the feature functions being bounded to allow for the interchange of integration and expectation, and on the linear span of the features being complete in the L2 space with respect to the distribution q to ensure that the weighted chi-squared divergences fully represent the KL divergence without residual cross-terms. Absolute continuity is ensured by the setup of the probabilistic models considered. In the revised manuscript, we will add a dedicated paragraph in §3 to explicitly list these assumptions and discuss how they guarantee the unbiasedness of the estimator. This will also strengthen the justification for the convergence rates in §4. We do not believe this changes the main results but improves the clarity and completeness of the presentation. revision: yes
Circularity Check
No significant circularity; derivation self-contained from integral representation and moments
full rationale
The paper starts from the representation of KL as an integral of weighted chi-squared divergences, converts this to a family of least-squares problems over linearly parameterized models, and derives the explicit spectral formula directly from first- and second-order feature moments. No step reduces the final estimator or log-density potential to a fitted parameter by construction, nor relies on load-bearing self-citations or imported uniqueness theorems. The abstract and claimed chain treat the spectral solution as an algebraic consequence of the moment matrices, with convergence guarantees stated separately; this is a standard non-circular derivation from stated assumptions to closed-form output.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption KL divergence can be expressed as an integral of weighted chi-squared divergences
- domain assumption Models are linearly parameterized in the chosen features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; RCLCombiner_isCoupling_iff echoesf(t) = ½(t−1)²/(ρt+1−ρ) … D(p∥q) = ∫ … dν(ρ) … spectral formula F(p∥q,φ) = Σ f(λi)/(λi−1)² [(μp−μq)⊤vi]²
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection refinesoperator-convex functions … f(1)=f'(1)=0, f''(1)=1 … closed-form from first- and second-order feature moments
Reference graph
Works this paper leans on
-
[1]
Kullback-Leibler divergence estimation of continuous distributions
Fernando Pérez-Cruz. Kullback-Leibler divergence estimation of continuous distributions. InInterna- tional Symposium on Information Theory, pages 1666–1670, 2008.(cited on page 1)
work page 2008
-
[2]
Cambridge University Press, 2025
Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning. Cambridge University Press, 2025. (cited on pages 1, 7, and 50)
work page 2025
-
[3]
Minimization ofφ-divergences on sets of signed measures
Michel Broniatowski and Amor Keziou. Minimization ofφ-divergences on sets of signed measures. Studia Scientiarum Mathematicarum Hungarica, 43(4):403–442, 2006.(cited on pages 1 and 2)
work page 2006
-
[4]
XuanLong Nguyen, Martin J. Wainwright, and Michael I. Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010.(cited on pages 1, 2, and 51)
work page 2010
-
[5]
Qiang Liu, Jian Peng, Alexander Ihler, and John W. Fisher III. Estimating the partition function by discriminance sampling. InConference on Uncertainty in Artificial Intelligence, 2015. (cited on page 2)
work page 2015
-
[6]
Omar Chehab, Aapo Hyvarinen, and Andrej Risteski. Provable benefits of annealing for estimating normalizing constants: Importance sampling, noise-contrastive estimation, and beyond. InAdvances in Neural Information Processing Systems, 2023. (cited on page 2)
work page 2023
-
[7]
Penalized discriminant analysis.The Annals of Statistics, 23(1):73–102, 1995.(cited on page 2)
Trevor Hastie, Andreas Buja, and Robert Tibshirani. Penalized discriminant analysis.The Annals of Statistics, 23(1):73–102, 1995.(cited on page 2)
work page 1995
-
[8]
Testing for homogeneity with kernel Fisher discrimi- nant analysis
Zaid Harchaoui, Francis Bach, and Eric Moulines. Testing for homogeneity with kernel Fisher discrimi- nant analysis. Technical Report 0804.1026, arXiv, 2008.(cited on pages 2, 4, 5, 6, and 29)
-
[9]
A least-squares approach to direct importance estimation
Takafumi Kanamori, Shohei Hido, and Masashi Sugiyama. A least-squares approach to direct importance estimation. Journal of Machine Learning Research, 10:1391–1445, 2009.(cited on pages 2, 4, and 19)
work page 2009
-
[10]
Cambridge University Press, 2012.(cited on pages 2 and 4)
Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori.Density Ratio Estimation in Machine Learning. Cambridge University Press, 2012.(cited on pages 2 and 4)
work page 2012
-
[11]
MIT Press, 2024.(cited on pages 2, 30, 42, 44, 46, and 47) 13
Francis Bach.Learning Theory from First Principles. MIT Press, 2024.(cited on pages 2, 30, 42, 44, 46, and 47) 13
work page 2024
-
[12]
Bernhard Schölkopf and Alexander J. Smola. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press, 2002.(cited on pages 2 and 6)
work page 2002
-
[13]
Nelder.Generalized Linear Models
Peter McCullagh and John A. Nelder.Generalized Linear Models. Chapman & Hall, 1989.(cited on page 2)
work page 1989
-
[14]
Makoto Yamada, Taiji Suzuki, Takafumi Kanamori, Hirotaka Hachiya, and Masashi Sugiyama. Relative density-ratio estimation for robust distribution comparison.Neural Computation, 25(5):1324–1370,
-
[15]
Andrew Lesniewski and Mary Beth Ruskai. Monotone Riemannian metrics and relative entropy on noncommutative probability spaces.Journal of Mathematical Physics, 40(11):5702–5724, 1999.(cited on pages 3 and 24)
work page 1999
-
[16]
Francis Bach. Sum-of-squares relaxations for information theory and variational inference.Foundations of Computational Mathematics, 25(3):865–903, 2025.(cited on pages 3, 4, 5, 6, 7, 13, 18, 19, and 23)
work page 2025
-
[17]
Francis Bach. Information theory with kernel methods.IEEE Transactions on Information Theory, 69(2):752–775, 2023.(cited on pages 3, 4, 6, 7, 9, 13, 19, 22, 29, and 36)
work page 2023
-
[18]
On-line expectation–maximization algorithm for latent data models
Olivier Cappé and Eric Moulines. On-line expectation–maximization algorithm for latent data models. Journal of the Royal Statistical Society Series B: Statistical Methodology, 71(3):593–613, 2009.(cited on pages 3 and 8)
work page 2009
-
[19]
Francis Bach. Breaking the curse of dimensionality with convex neural networks.Journal of Machine Learning Research, 18(19):1–53, 2017.(cited on pages 3, 9, 10, 11, 35, 40, 41, and 43)
work page 2017
-
[20]
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(4), 2005.(cited on page 4)
work page 2005
-
[21]
Michael U. Gutmann and Aapo Hyvärinen. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics.Journal of Machine Learning Research, 13(11):307– 361, 2012. (cited on page 4)
work page 2012
-
[22]
Regularizedf-divergence kernel tests
Mónica Ribero, Antonin Schrab, and Arthur Gretton. Regularizedf-divergence kernel tests. Technical Report 2601.19755, arXiv, 2026.(cited on pages 4, 5, 13, 29, and 54)
-
[23]
Mark D. Reid and Robert C. Williamson. Information, divergence and risk for binary experiments. Journal of Machine Learning Research, 12(22):731–817, 2011.(cited on pages 4 and 20)
work page 2011
-
[24]
Didier Henrion, Milan Korda, and Jean Bernard Lasserre.The Moment-SOS Hierarchy: Lectures in Probability, Statistics, Computational Geometry, Control and Nonlinear PDEs. World Scientific, 2020. (cited on page 5)
work page 2020
-
[25]
Testing for homogeneity with kernel Fisher discrimi- nant analysis
Zaid Harchaoui, Francis Bach, and Eric Moulines. Testing for homogeneity with kernel Fisher discrimi- nant analysis. InAdvances in Neural Information Processing Systems, 2007. (cited on page 5)
work page 2007
-
[26]
Francis Bach and Michael I. Jordan. Kernel independent component analysis.Journal of Machine Learning Research, 3(Jul):1–48, 2002.(cited on pages 6, 13, 23, and 50) 14
work page 2002
-
[27]
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13(1):723–773, 2012.(cited on page 6)
work page 2012
-
[28]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in Neural Information Processing Systems, 2008. (cited on page 6)
work page 2008
-
[29]
Generalization properties of learning with random features
Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features. In Advances in Neural Information Processing Systems, 2017. (cited on page 6)
work page 2017
-
[30]
Michael W. Mahoney and Petros Drineas. CUR matrix decompositions for improved data analysis. Proceedings of the National Academy of Sciences, 106(3):697–702, 2009.(cited on page 6)
work page 2009
-
[31]
Per-Gunnar Martinsson and Joel A. Tropp. Randomized numerical linear algebra: Foundations and algorithms. Acta Numerica, 29:403–572, 2020.(cited on page 6)
work page 2020
-
[32]
Using the Nyström method to speed up kernel machines
Christopher Williams and Matthias Seeger. Using the Nyström method to speed up kernel machines. In Advances in Neural Information Processing Systems, 2000. (cited on page 6)
work page 2000
-
[33]
Less is more: Nyström computational regularization
Alessandro Rudi, Raffaello Camoriano, and Lorenzo Rosasco. Less is more: Nyström computational regularization. In Advances in Neural Information Processing Systems, 2015. (cited on page 6)
work page 2015
-
[34]
On the relationship between multivariate splines and infinitely-wide neural networks
Francis Bach. On the relationship between multivariate splines and infinitely-wide neural networks. Technical Report 2302.03459, arXiv, 2023.(cited on pages 6 and 10)
-
[35]
Information-type measures of difference of probability distributions and indirect observa- tion
Imre Csiszár. Information-type measures of difference of probability distributions and indirect observa- tion. Studia Scientiarum Mathematicarum Hungarica, 2:229–318, 1967.(cited on page 6)
work page 1967
-
[36]
Letizia, Nicola Novello, and Andrea M
Nunzio A. Letizia, Nicola Novello, and Andrea M. Tonello. Mutual information estimation viaf- divergence and data derangements. InAdvances in Neural Information Processing Systems, 2024. (cited on page 6)
work page 2024
-
[37]
Sufficient dimension reduction via squared-loss mutual information estimation
Taiji Suzuki and Masashi Sugiyama. Sufficient dimension reduction via squared-loss mutual information estimation. In International Conference on Artificial Intelligence and Statistics, 2010. (cited on page 6)
work page 2010
-
[38]
Mutual information neural estimation
Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. Mutual information neural estimation. InInternational Conference on Machine Learning, 2018. (cited on pages 6 and 54)
work page 2018
-
[39]
On variational bounds of mutual information
Ben Poole, Sherjil Ozair, Aaron van den Oord, Alex Alemi, and George Tucker. On variational bounds of mutual information. InInternational Conference on Machine Learning, 2019. (cited on pages 6 and 54)
work page 2019
-
[40]
Francis Bach, Gert R. G. Lanckriet, and Michael I. Jordan. Multiple kernel learning, conic duality, and the SMO algorithm. InInternational Conference on Machine Learning, 2004. (cited on page 7)
work page 2004
-
[41]
SimpleMKL.Journal of Machine Learning Research, 9:2491–2521, 2008.(cited on page 7)
Alain Rakotomamonjy, Francis Bach, Stéphane Canu, and Yves Grandvalet. SimpleMKL.Journal of Machine Learning Research, 9:2491–2521, 2008.(cited on page 7)
work page 2008
-
[42]
Mehmet Gönen and Ethem Alpaydın. Multiple kernel learning algorithms.Journal of Machine Learning Research, 12:2211–2268, 2011.(cited on page 7) 15
work page 2011
-
[43]
Bertille Follain and Francis Bach. Enhanced feature learning via regularisation: Integrating neural networks and kernel methods.Journal of Machine Learning Research, 26(172):1–56, 2025.(cited on page 7)
work page 2025
-
[44]
A tutorial on MM algorithms.The American Statistician, 58(1):30–37, 2004.(cited on page 8)
David R Hunter and Kenneth Lange. A tutorial on MM algorithms.The American Statistician, 58(1):30–37, 2004.(cited on page 8)
work page 2004
-
[45]
Stochastic majorization-minimization algorithms for large-scale optimization
Julien Mairal. Stochastic majorization-minimization algorithms for large-scale optimization. InAdvances in Neural Information Processing Systems, 2013. (cited on page 8)
work page 2013
-
[46]
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 1996. (cited on page 8)
work page 1996
-
[47]
Sriperumbudur, Kenji Fukumizu, and Gert R
Bharath K. Sriperumbudur, Kenji Fukumizu, and Gert R. G. Lanckriet. Universality, characteristic kernels and RKHS embedding of measures.Journal of Machine Learning Research, 12(70), 2011.(cited on page 9)
work page 2011
-
[48]
Béatrice Laurent. Efficient estimation of integral functionals of a density.The Annals of Statistics, 24(2):659–681, 1996.(cited on pages 9, 10, and 36)
work page 1996
-
[49]
Lee.U-Statistics: Theory and Practice
Alan J. Lee.U-Statistics: Theory and Practice. Routledge, 2019. (cited on pages 10 and 36)
work page 2019
-
[50]
On the global convergence of gradient descent for over-parameterized models using optimal transport
Lenaic Chizat and Francis Bach. On the global convergence of gradient descent for over-parameterized models using optimal transport. InAdvances in Neural Information Processing Systems, 2018. (cited on page 10)
work page 2018
-
[51]
Numerically stable parallel computation of (co-)variance
Erich Schubert and Michael Gertz. Numerically stable parallel computation of (co-)variance. In International Conference on Scientific and Statistical Database Management, 2018. (cited on page 13)
work page 2018
-
[52]
Rémi Gribonval, Antoine Chatalic, Nicolas Keriven, Vincent Schellekens, Laurent Jacques, and Philip Schniter. Sketching data sets for large-scale learning: Keeping only what you need.IEEE Signal Processing Magazine, 38(5):12–36, 2021.(cited on page 13)
work page 2021
-
[53]
Martin J. Wainwright and Michael I. Jordan. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning, 1(1-2):1–305, 2008.(cited on page 13)
work page 2008
-
[54]
Least-squaresindependentcomponentanalysis
TaijiSuzukiandMasashiSugiyama. Least-squaresindependentcomponentanalysis. Neural Computation, 23(1):284–301, 2011.(cited on page 13)
work page 2011
-
[55]
Direct importance estimation with model selection and its application to covariate shift adaptation
Masashi Sugiyama, Shinichi Nakajima, Hisashi Kashima, Paul von Bünau, and Motoaki Kawanabe. Direct importance estimation with model selection and its application to covariate shift adaptation. In Advances in Neural Information Processing Systems, 2007. (cited on page 19)
work page 2007
-
[56]
f-GAN: Training generative neural samplers using variational divergence minimization
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-GAN: Training generative neural samplers using variational divergence minimization. InAdvances in Neural Information Processing Systems, 2016. (cited on page 20)
work page 2016
-
[57]
Binary losses for density ratio estimation
Werner Zellinger. Binary losses for density ratio estimation. InInternational Conference on Learning Representations, 2025. (cited on page 21) 16
work page 2025
-
[58]
Werner Zellinger, Stefan Kindermann, and Sergei V. Pereverzyev. Adaptive learning of density ratios in RKHS. Journal of Machine Learning Research, 24(395):1–28, 2023.(cited on page 21)
work page 2023
-
[59]
Linking losses for density ratio and class-probability estimation
Aditya Menon and Cheng Soon Ong. Linking losses for density ratio and class-probability estimation. In International Conference on Machine Learning, 2016. (cited on page 21)
work page 2016
-
[60]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press, 2004. (cited on page 22)
work page 2004
-
[61]
Concavity of certain maps on positive definite matrices and applications to Hadamard products
Tsuyoshi Ando. Concavity of certain maps on positive definite matrices and applications to Hadamard products. Linear Algebra and its Applications, 26:203–241, 1979.(cited on page 22)
work page 1979
-
[62]
Adrian S. Lewis. Derivatives of spectral functions.Mathematics of Operations Research, 21(3):576–588,
-
[63]
Optimal rates for the regularized least-squares algorithm
Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics, 7(3):331–368, 2007.(cited on page 29)
work page 2007
-
[64]
Junhong Lin, Alessandro Rudi, Lorenzo Rosasco, and Volkan Cevher. Optimal rates for spectral algorithms with least-squares regression over Hilbert spaces.Applied and Computational Harmonic Analysis, 48(3):868–890, 2020.(cited on pages 29 and 30)
work page 2020
-
[65]
Sharp analysis of low-rank kernel matrix approximations
Francis Bach. Sharp analysis of low-rank kernel matrix approximations. InConference on Learning Theory, 2013. (cited on page 29)
work page 2013
-
[66]
Ahmed El Alaoui and Michael W. Mahoney. Fast randomized kernel ridge regression with statistical guarantees. InAdvances in Neural Information Processing Systems, 2015. (cited on page 29)
work page 2015
-
[67]
Joel A. Tropp. An introduction to matrix concentration inequalities.Foundations and Trends in Machine Learning, 8(1-2):1–230, 2015.(cited on page 30)
work page 2015
-
[68]
On converse and saturation results for Tikhonov regularization of linear ill-posed problems
Andreas Neubauer. On converse and saturation results for Tikhonov regularization of linear ill-posed problems. SIAM Journal on Numerical Analysis, 34(2):517–527, 1997.(cited on page 35)
work page 1997
-
[69]
Sobolev norm learning rates for regularized least-squares algorithms
Simon Fischer and Ingo Steinwart. Sobolev norm learning rates for regularized least-squares algorithms. Journal of Machine Learning Research, 21(205):1–38, 2020.(cited on page 35)
work page 2020
-
[70]
Bounds on rates of variable-basis and neural-network approxi- mation
Vera Kurková and Marcello Sanguineti. Bounds on rates of variable-basis and neural-network approxi- mation. IEEE Transactions on Information Theory, 47(6):2659–2665, 2001.(cited on page 41)
work page 2001
-
[71]
A vector-contraction inequality for Rademacher complexities
Andreas Maurer. A vector-contraction inequality for Rademacher complexities. In International Conference on Algorithmic Learning Theory, 2016. (cited on page 45)
work page 2016
-
[72]
Revisiting Frank-Wolfe: Projection-free sparse convex optimization
Martin Jaggi. Revisiting Frank-Wolfe: Projection-free sparse convex optimization. InInternational Conference on Machine Learning, 2013. (cited on page 47)
work page 2013
-
[73]
Anderson.An Introduction to Multivariate Statistical Analysis
Theodore W. Anderson.An Introduction to Multivariate Statistical Analysis. Wiley, 2003. (cited on page 50)
work page 2003
-
[74]
Harry Joe. Estimation of entropy and other functionals of a multivariate density.Annals of the Institute of Statistical Mathematics, 41(4):683–697, 1989.(cited on page 54) 17
work page 1989
-
[75]
Qing Wang, Sanjeev R. Kulkarni, and Sergio Verdú. Divergence estimation of continuous distributions based on data-dependent partitions.IEEE Transactions on Information Theory, 51(9):3064–3074, 2005. (cited on page 54)
work page 2005
-
[76]
Kirthevasan Kandasamy, Akshay Krishnamurthy, Barnabas Poczos, Larry Wasserman, and James M. Robins. Nonparametric von Mises estimators for entropies, divergences and mutual informations. In Advances in Neural Information Processing Systems, 2015. (cited on page 54) A Additional examples of f -divergences We provide in Table 1 below a list of operator-conv...
work page 2015
-
[77]
It has both multiplicative and additive terms
We have: E (Fλ(ˆp∥ˆq, φ) − D(p∥q))2 1/2 ⩽ 32df(λ) n + 8R2 φ λ √ 8 n2ξ + λ2r Z 1 0 ∥θρ∥2dν(ρ) (12) +16 p ξ r dfmax(λ) n p log(n) · D(p∥q) + 8 r 2D(p∥q) αn . It has both multiplicative and additive terms. Throughout the proof, we will use the notationΣ(ρ) = ρΣp + (1 − ρ)Σq, as well as its empirical counterpart ˆΣ(ρ) = ρˆΣp + (1 − ρ)ˆΣq. We will also useM(ρ)...
-
[78]
Then, with t = 4√ξ p dfmax(λ)/n p log(2n) ∈ (0, 3/4], we haveP(Ac) ⩽ 8 n4ξ. 30 Proof. We prove the bound forp; the proof forq is identical. Let A = (Σp + λI)−1/2(Σp − ˆΣp)(Σp + λI)−1/2 op ≤ t . By the intrinsic-dimension matrix Bernstein bound [67, Theorem 7.7.1] applied to (Σp + λI)−1/2 φ(x)φ(x)⊤ − Σp (Σp + λI)−1/2, provided t ≥ s dfmax p (λ) np + dfmax ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.