Recognition: 2 theorem links
· Lean TheoremSurviving Partial Rank Failures in Wide Expert-Parallel MoE Inference
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
Representing expert-parallel membership as mutable runtime state lets wide MoE inference recover from single rank failures through targeted state repairs instead of full restarts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
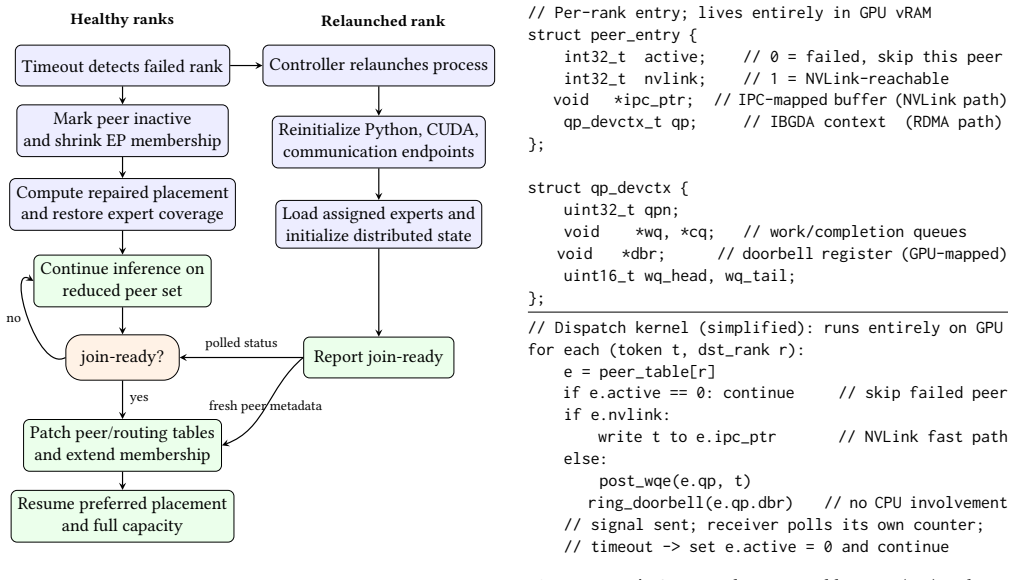
The central claim is that partial-failure tolerance in wide expert-parallel MoE inference is best solved as a live validity problem rather than a restart problem. Explicit mutable membership lets the system restore peer reachability without rebuilding the full communication substrate, repair lost expert coverage through a bandwidth-aware hierarchy, and reintegrate repaired ranks without forcing healthy ranks to recapture their CUDA graphs, thereby keeping the instance valid after a fault.
What carries the argument
Explicit mutable membership state, which tracks and updates the set of active ranks at runtime so that only the state invalidated by a fault needs repair.
If this is right
- Steady-state serving performance remains within a small margin of fixed-membership designs under normal conditions.
- A local rank fault produces only an 11-second recovery pause followed by an 8-second reintegration pause.
- Throughput returns to within 95 percent of the pre-fault level within 52 seconds after the fault.
- The instance avoids the multi-minute unavailability that occurs when the entire configuration must be restarted.
Where Pith is reading between the lines
- The same mutable-membership idea could be tested on workloads with simultaneous failures of two or more ranks to see whether the bandwidth-aware hierarchy still suffices.
- Other distributed inference systems that bake rank sets into communicator and graph state at initialization might adopt similar live repair techniques to reduce fault-induced downtime.
- The approach implies that future MoE hardware clusters could be built with cheaper, less redundant networking if software can reliably heal partial losses.
Load-bearing premise
That repairing peer reachability, expert coverage via a bandwidth-aware hierarchy, and rank reintegration without forcing healthy ranks to recapture execution graphs is always possible and sufficient to keep the instance valid.
What would settle it
A single-rank failure experiment in which the repairs either fail to restore expert coverage, require healthy ranks to rebuild their execution graphs, or leave the instance unavailable for more than a minute.
Figures








read the original abstract
Mixture-of-Experts (MoE) serving relies on wide expert parallelism (EP) to aggregate the memory capacity and bandwidth of many GPUs within one inference instance. This efficiency comes with a systems cost: every decoding step depends on token dispatch and combination across all active EP ranks, so even one rank failure can disrupt the entire service. Existing EP stacks handle such failures poorly because they treat membership as a fixed configuration established at initialization. The same rank set determines communicator state, expert placement, and the routing metadata baked into CUDA execution graphs, leaving the system with no way to shrink around a failure while keeping the instance valid. This paper argues that partial-failure tolerance should instead be formulated as a live EP validity problem. We present EEP, a communication and runtime substrate that represents membership as explicit, mutable runtime state. EEP repairs the specific state invalidated by a fault: it restores peer reachability without rebuilding the communication substrate, repairs lost expert coverage through a bandwidth-aware hierarchy, and reintegrates repaired ranks without forcing healthy ranks to recapture their CUDA graphs. We implement EEP in an EP serving stack integrated with SGLang and evaluate it under steady-state serving, failure recovery, and rank reintegration. The results show that explicit mutable membership preserves the steady-state fast path, staying within 4.4% of a fixed-membership DeepEP baseline under static serving, while turning a local rank fault from whole-instance downtime into two bounded interruptions. On a single-rank failure workload, EEP incurs an 11s recovery pause and an 8s reintegration pause, and restores throughput to within 95% of the pre-fault level within 52s, whereas a fixed-membership full-restart baseline remains unavailable until 348s.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that partial rank failures in wide expert-parallel (EP) MoE inference can be survived by reformulating the problem as live EP validity maintenance. It introduces EEP, a substrate that represents membership as explicit mutable runtime state and performs targeted repairs: restoring peer reachability without rebuilding the full communication substrate, repairing expert coverage via a bandwidth-aware hierarchy, and reintegrating ranks without forcing healthy ranks to recapture CUDA graphs. Evaluation integrated with SGLang shows that this preserves the steady-state fast path (within 4.4% of a fixed-membership DeepEP baseline) while converting a single-rank fault into bounded interruptions (11s recovery pause, 8s reintegration pause, 95% throughput restored in 52s) versus 348s unavailability for a full-restart baseline.
Significance. If the reported recovery metrics hold under scrutiny, the work is significant for production MoE serving systems, where wide EP is essential for memory capacity but creates single points of failure. By demonstrating that mutable membership can be maintained with low steady-state overhead and fast partial recovery, it offers a practical path to higher availability without sacrificing the performance of the common case. The implementation in an existing stack (SGLang) and concrete comparison to DeepEP strengthen its applicability.
major comments (1)
- Evaluation section: the central performance claims rest on specific numbers (11s recovery pause, 8s reintegration pause, 52s to 95% throughput recovery, 348s full-restart baseline, and ≤4.4% steady-state overhead). These are presented without any description of the experimental setup, hardware configuration, number of trials, variance or error bars, workload details, or the exact mechanism used to inject and detect rank failures. This omission is load-bearing because the soundness of the 'bounded interruptions' claim cannot be assessed without it.
minor comments (2)
- Abstract: the acronym 'EEP' is introduced without expansion or definition; provide a brief parenthetical on first use.
- Abstract: the phrase 'bandwidth-aware hierarchy' for expert coverage is used without a forward reference to the section that defines or evaluates it.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of mutable-membership EP for production MoE serving. We agree that the Evaluation section must supply the missing methodological details so that the reported recovery and overhead numbers can be properly assessed. We will revise the manuscript to address this point.
read point-by-point responses
-
Referee: Evaluation section: the central performance claims rest on specific numbers (11s recovery pause, 8s reintegration pause, 52s to 95% throughput recovery, 348s full-restart baseline, and ≤4.4% steady-state overhead). These are presented without any description of the experimental setup, hardware configuration, number of trials, variance or error bars, workload details, or the exact mechanism used to inject and detect rank failures. This omission is load-bearing because the soundness of the 'bounded interruptions' claim cannot be assessed without it.
Authors: We agree that the current manuscript does not provide sufficient detail on the experimental methodology. In the revised version we will add a new subsection (or substantially expand the existing Evaluation section) that explicitly describes: (1) the hardware platform, including GPU model, count, interconnect topology, and node configuration; (2) the workload characteristics, model sizes, batching policies, and request traces used for steady-state and fault-injection experiments; (3) the precise failure-injection and detection mechanism (e.g., process kill, CUDA context destruction, or network partition, together with the monitoring hooks that trigger EEP repair); (4) the number of independent trials performed for each metric and any reported variance, standard deviation, or error bars. These additions will allow readers to evaluate the reliability of the 11 s / 8 s / 52 s / 348 s and 4.4 % figures. The core experimental results themselves remain unchanged. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents EEP as a systems implementation for mutable EP membership that repairs peer reachability, expert coverage via bandwidth-aware hierarchy, and CUDA-graph-preserving reintegration. All central claims (steady-state overhead ≤4.4% vs DeepEP, 11s/8s pauses, 95% throughput recovery in 52s vs 348s restart) are supported solely by empirical measurements on a single-rank failure workload; no equations, fitted parameters, predictions, or self-citations appear in the derivation chain. The work is therefore self-contained as an engineering substrate whose validity rests on direct experimental comparison rather than any reduction to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing EP stacks treat membership as fixed configuration established at initialization.
- domain assumption CUDA execution graphs and routing metadata are baked in at initialization and cannot be updated without recapture.
invented entities (1)
-
EEP substrate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EEP repairs the specific state invalidated by a fault: it restores peer reachability without rebuilding the communication substrate, repairs lost expert coverage through a bandwidth-aware hierarchy, and reintegrates repaired ranks without forcing healthy ranks to recapture their CUDA graphs.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An EP instance is valid iff three conditions hold simultaneously: Peer-set validity, Expert-coverage validity, Graph-visible routing validity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, Runxin Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, Zhenda Xie, Y.K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wen- feng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Specializa- tion in Mixture-of-Experts Language Models. arXiv:2401.06066 [cs.CL] https://arxiv.org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-AI. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL]https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
DeepSeek-AI. 2025. Expert Parallelism Load Balancer (EPLB). GitHub. https://github.com/deepseek-ai/EPLB
work page 2025
-
[4]
DeepSeek-AI, Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y. Wu, Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai, Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bing-Li Wang, Jun-Mei Song, Deli Chen, Xin Xie, Kang Guan, Yu mei You, Aixin Liu, Qiushi Du, Wenjun Gao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39. http://jmlr.org/papers/v23/21-0998.html
work page 2022
-
[6]
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia
-
[7]
arXiv:2211.15841 [cs.LG]https://arxiv.org/abs/2211.15841
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts. arXiv:2211.15841 [cs.LG]https://arxiv.org/abs/2211.15841
-
[8]
Amos Goldman, Nimrod Boker, Maayan Sheraizin, Nimrod Admoni, Artem Polyakov, Subhadeep Bhattacharya, Fan Yu, Kai Sun, Geor- gios Theodorakis, Hsin-Chun Yin, Peter-Jan Gootzen, Aamir Shafi, Assaf Ravid, Salvatore Di Girolamo, Manjunath Gorentla Venkata, and Gil Bloch. 2026. NCCL EP: Towards a Unified Expert Paral- lel Communication API for NCCL. arXiv:2603...
-
[9]
Alan Gray. 2019. Getting Started with CUDA Graphs.https://developer. nvidia.com/blog/cuda-graphs/. NVIDIA Technical Blog
work page 2019
- [10]
-
[11]
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, Joe Chau, Peng Cheng, Fan Yang, Mao Yang, and Yongqiang Xiong. 2023. Tutel: Adaptive Mixture-of-Experts at Scale. arXiv:2206.03382 [cs.DC]https: //arxiv.org/abs/2206.03382
-
[12]
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary DeVito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. 2025. Revisiting Reliability in Large- Scale Machine Learning Research Clusters. In2025 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE
work page 2025
-
[13]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[14]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. arXiv:2309.06180 [cs.LG]https://arxiv.org/ abs/2309.06180
work page internal anchor Pith review arXiv
-
[15]
Ziming Liu, Boyu Tian, Guoteng Wang, Zhen Jiang, Peng Sun, Zhenhua Han, Tian Tang, Xiaohe Hu, Yanmin Jia, Yan Zhang, He Liu, Mingjun Zhang, Yiqi Zhang, Qiaoling Chen, Shenggan Cheng, Mingyu Gao, Yang You, and Siyuan Feng. 2025. Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving. arXiv:2509.17863 [cs.DC]https://arxiv.org/a...
- [16]
-
[17]
Pak Markthub, Jim Dinan, Sreeram Potluri, and Seth Howell. 2022. Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async. NVIDIA Technical Blog.https://developer.nvidia.com/blog/improving-network- performance-of-hpc-systems-using-nvidia-magnum-io-nvshmem- and-gpudirect-async/
work page 2022
-
[18]
NVIDIA. 2025. Building Scalable and Fault-Tolerant NCCL Applica- tions.https://developer.nvidia.com/blog/building-scalable-and-fault- tolerant-nccl-applications/. NVIDIA Technical Blog
work page 2025
-
[19]
NVIDIA. 2025. GPUDirect RDMA.https://docs.nvidia.com/cuda/ gpudirect-rdma. CUDA documentation
work page 2025
-
[20]
NVIDIA. 2025. RAS.https://docs.nvidia.com/deeplearning/nccl/user- guide/docs/troubleshooting/ras.html. NCCL documentation
work page 2025
-
[21]
NVIDIA. 2026. CUDA C Programming Guide.https://docs.nvidia.com/ cuda/cuda-programming-guide/. CUDA documentation
work page 2026
-
[22]
PyTorch. 2026. Gloo: Collective Communications Library.https:// github.com/pytorch/gloo. GitHub repository
work page 2026
-
[23]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed-MoE: Advancing Mixture-of- Experts Inference and Training to Power Next-Generation AI Scale. arXiv:2201.05596 [cs.LG]https://arxiv.org/abs/2201.05596
-
[24]
Feng Ren, Ruoyu Qin, Teng Ma, Shangming Cai, Zheng Liu, Chao Lei, Dejiang Zhu, Ke Yang, Zheming Li, Jialei Cui, Weixiao Huang, Yikai Zhao, Yineng Zhang, Hao Wu, Xiang Gao, Yuhao Fu, Jinlei Jiang, Yongwei Wu, and Mingxing Zhang. 2026. TENT: A Declarative Slice Spraying Engine for Performant and Resilient Data Movement in Disaggregated LLM Serving. arXiv:26...
-
[25]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538 [cs.LG]https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Gursimran Singh, Timothy Yu, Haley Li, Cheng Chen, Hanieh Sadri, Qintao Zhang, Yu Zhang, Ying Xiong, Yong Zhang, and Zhenan Fan
-
[27]
arXiv:2510.02613 [cs.DC]https://arxiv.org/abs/2510
ElasticMoE: An Efficient Auto Scaling Method for Mixture-of- Experts Models. arXiv:2510.02613 [cs.DC]https://arxiv.org/abs/2510. 02613
-
[28]
vLLM Team. 2026. Elastic EP.https://docs.vllm.ai/en/latest/examples/ online_serving/elastic_ep/. vLLM example documentation
work page 2026
-
[29]
vLLM Team. 2026. Expert Parallel Deployment.https://docs.vllm.ai/ en/latest/serving/expert_parallel_deployment/. vLLM documentation
work page 2026
-
[30]
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai
-
[31]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of- Experts. arXiv:2408.15664 [cs.LG]https://arxiv.org/abs/2408.15664
work page internal anchor Pith review arXiv
-
[32]
Morley Mao, Matthew Lentz, Danyang Zhuo, and Ion Stoica
Yongji Wu, Wenjie Qu, Xueshen Liu, Tianyang Tao, Yifan Qiao, Zhuang Wang, Wei Bai, Yuan Tian, Jiaheng Zhang, Z. Morley Mao, Matthew Lentz, Danyang Zhuo, and Ion Stoica. 2024. Lazarus: Resilient and Elastic Training of Mixture-of-Experts Models with Adaptive Expert Placement. arXiv:2407.04656 [cs.DC]https://arxiv.org/abs/2407.04656
-
[33]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library.https://github.com/ deepseek-ai/DeepEP
work page 2025
-
[34]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Sto- ica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. arXiv:2312.07104 [cs.AI]https://arxiv.org/abs/2312.07104
work page internal anchor Pith review arXiv 2024
-
[35]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. 2025. MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggre- gated Expert Parallelism. arXiv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.