Recognition: unknown
Not Blind but Silenced: Rebalancing Vision and Language via Adversarial Counter-Commonsense Equilibrium
Pith reviewed 2026-05-12 04:43 UTC · model grok-4.3
The pith
Hallucinations in multimodal models stem from linguistic priors overpowering visual signals, which a training-free perturbation method can rebalance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
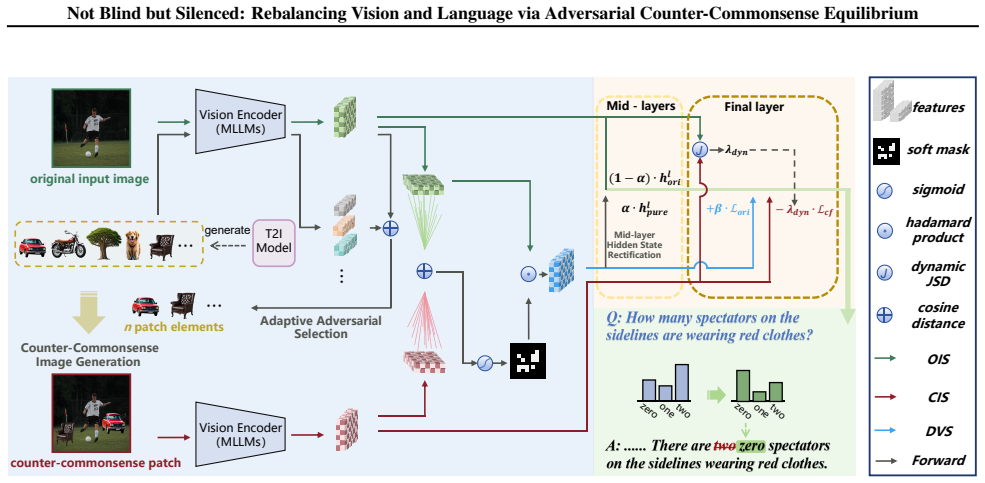
Hallucinations stem from an equilibrium imbalance between linguistic priors and visual information. The Adversarial Counter-Commonsense Equilibrium (ACE) is a training-free framework that perturbs visual context via counter-commonsense patches. Leveraging the fact that authentic visual features remain stable under perturbation while hallucinations fluctuate, ACE implements a dynamic game decoding strategy that precisely suppresses perturbation-sensitive priors while compensating for stable visual signals to restore balance.
What carries the argument
Adversarial Counter-Commonsense Equilibrium (ACE), a training-free framework that perturbs visual context with counter-commonsense patches and applies dynamic game decoding to suppress unstable priors.
If this is right
- - Enhances trustworthiness of MLLMs as a plug-and-play strategy
- - Requires negligible inference overhead
- - Suppresses perturbation-sensitive linguistic priors
- - Compensates for stable visual signals to restore vision-language balance
Where Pith is reading between the lines
- - The equilibrium framing could guide inference-time fixes for other types of multimodal over-reliance on priors.
- - Patch selection might be automated or adapted to specific image domains for broader use.
- - The approach suggests attention redirection can occur without retraining by exploiting response stability differences.
Load-bearing premise
Authentic visual features remain stable under perturbation while hallucinations fluctuate.
What would settle it
If counter-commonsense patches either fail to reduce hallucinations or cause authentic visual features to change substantially, the claim that the method restores balance through differential stability would be falsified.
Figures






read the original abstract
During MLLM decoding, attention often abnormally concentrates on irrelevant image tokens. While existing research dismisses this as invalid noise and forcibly redirects attention to compel focusing on key image information, we argue these tokens are critical carriers of visual and narrative logic, and such coercive corrections exacerbate visual-language imbalance. Adopting a "decoding-as-game" perspective, we reveal that hallucinations stem from an equilibrium imbalance between linguistic priors and visual information. We propose Adversarial Counter-Commonsense Equilibrium (ACE), a training-free framework that perturbs visual context via counter-commonsense patches. Leveraging the fact that authentic visual features remain stable under perturbation while hallucinations fluctuate, ACE implements a dynamic game decoding strategy. This approach precisely suppresses perturbation-sensitive priors while compensating for stable visual signals to restore balance. Extensive experiments demonstrate that ACE, as a plug-and-play strategy, enhances model trustworthiness with negligible inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations in multimodal large language models (MLLMs) arise during decoding from an equilibrium imbalance between linguistic priors and visual information, manifested as abnormal attention concentration on irrelevant image tokens. It proposes Adversarial Counter-Commonsense Equilibrium (ACE), a training-free plug-and-play framework that perturbs visual context with counter-commonsense patches. The method exploits the asserted differential that authentic visual features remain stable under perturbation while hallucinations fluctuate, implementing a dynamic game decoding strategy to suppress perturbation-sensitive priors and compensate stable visual signals, thereby restoring balance. Extensive experiments are claimed to show improved trustworthiness with negligible inference overhead.
Significance. If the differential stability assumption holds and is empirically isolated, ACE would offer a practical, training-free advance for mitigating hallucinations in MLLMs by reframing decoding as a game that selectively rebalances vision and language. The absence of retraining or extra data requirements is a notable strength for deployment. However, the current presentation provides insufficient quantitative grounding (baselines, metrics, error bars) to assess whether the claimed restoration of equilibrium delivers meaningful gains over existing attention-redirection or decoding-correction approaches.
major comments (1)
- [ACE framework description (method section)] The core operating principle (authentic visual features remain stable under perturbation while hallucinations fluctuate) is stated as a fact to be leveraged in the ACE framework description, yet no derivation, controlled measurement (e.g., cosine similarity or attention-map deltas on verified vs. hallucinated tokens), or ablation isolating the selectivity of counter-commonsense patches is provided. This assumption is load-bearing for the rebalancing claim: if patches induce global shifts in visual embeddings or attention, the dynamic game decoding cannot selectively suppress priors while compensating stable signals.
minor comments (2)
- [Abstract] The abstract asserts 'extensive experiments' demonstrating effectiveness but supplies no quantitative results, specific metrics, baselines, datasets, or error bars, which weakens the ability to evaluate the equilibrium-restoration claim from the summary alone.
- [Method] The term 'counter-commonsense patches' and the precise mechanics of the 'dynamic game decoding strategy' would benefit from an earlier formal definition or pseudocode to clarify how suppression and compensation are implemented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the justification of the core operating principle in the ACE framework below.
read point-by-point responses
-
Referee: [ACE framework description (method section)] The core operating principle (authentic visual features remain stable under perturbation while hallucinations fluctuate) is stated as a fact to be leveraged in the ACE framework description, yet no derivation, controlled measurement (e.g., cosine similarity or attention-map deltas on verified vs. hallucinated tokens), or ablation isolating the selectivity of counter-commonsense patches is provided. This assumption is load-bearing for the rebalancing claim: if patches induce global shifts in visual embeddings or attention, the dynamic game decoding cannot selectively suppress priors while compensating stable signals.
Authors: We acknowledge that the manuscript introduces the differential stability between authentic visual features and hallucinated linguistic priors as an observed property without providing explicit derivations or isolated measurements in the method section. While the full paper includes extensive experiments showing ACE's effectiveness in reducing hallucinations, we agree that this load-bearing assumption requires stronger empirical grounding to rule out global embedding shifts. In the revision, we will add a new subsection with controlled measurements, including cosine similarity and attention-map delta analyses comparing verified versus hallucinated tokens under counter-commonsense perturbations, plus targeted ablations on patch selectivity. These will quantify the differential stability and confirm that the dynamic game decoding selectively targets perturbation-sensitive priors. revision: yes
Circularity Check
No significant circularity detected.
full rationale
The paper frames hallucinations via a decoding-as-game perspective and an equilibrium imbalance between linguistic priors and visual signals, then introduces ACE as a training-free perturbation method that leverages the stated differential stability of authentic visual features versus fluctuating hallucinated content. This stability is presented as an empirical fact to be exploited rather than a quantity derived from or defined by the method itself. No equations reduce the framework's output to its inputs by construction, no parameters are fitted and then relabeled as predictions, and no self-citations or uniqueness theorems carry the central load. The derivation remains self-contained, with success claims resting on experimental validation rather than tautological redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Authentic visual features remain stable under perturbation while hallucinations fluctuate
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
SECOND: Mitigating Perceptual Hallucination in Vision-Language Models via Selective and Contrastive Decoding , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[2]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Don’t miss the forest for the trees: Attentional vision calibration for large vision language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Hallucinatory Image Tokens: A Training-free EAZY Approach to Detecting and Mitigating Object Hallucinations in LVLMs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[4]
arXiv preprint arXiv:2501.01926 , year=
Mitigating hallucination for large vision language model by inter-modality correlation calibration decoding , author=. arXiv preprint arXiv:2501.01926 , year=
-
[5]
Object Hallucination in Image Captioning
Rohrbach, Anna and Hendricks, Lisa Anne and Burns, Kaylee and Darrell, Trevor and Saenko, Kate. Object Hallucination in Image Captioning. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1437
-
[6]
Li, Yifan and Du, Yifan and Zhou, Kun and Wang, Jinpeng and Zhao, Xin and Wen, Ji-Rong. Evaluating Object Hallucination in Large Vision-Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.20
-
[7]
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Watermarking for Factuality: Guiding Vision-Language Models Toward Truth via Tri-layer Contrastive Decoding , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
work page 2025
-
[9]
Revisit What You See: Disclose Language Prior in Vision Tokens for LVLM Decoding , author=. 2025 , journal=
work page 2025
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
The Twelfth International Conference on Learning Representations , year=
Instructive Decoding: Instruction-Tuned Large Language Models are Self-Refiner from Noisy Instructions , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding
Wang, Xintong and Pan, Jingheng and Ding, Liang and Biemann, Chris. Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.937
-
[13]
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models , volume =
Huo, Fushuo and Xu, Wenchao and Zhang, Zhong and Wang, Haozhao and Chen, Zhicheng and Zhao, Peilin , booktitle =. Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models , volume =
-
[14]
Kim, Taehyeon and KIM, JOONKEE and Lee, Gihun and Yun, Se-Young , booktitle =. Instructive Decoding: Instruction-Tuned Large Language Models are Self-Refiner from Noisy Instructions , volume =
-
[15]
Park, Yeji and Lee, Deokyeong and Choe, Junsuk and Chang, Buru , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 , isbn =. doi:10.1609/aaai.v3...
-
[16]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , volume =
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James R and He, Pengcheng , booktitle =. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , volume =
-
[17]
arXiv preprint arXiv:2402.08680 , year=
Mitigating object hallucination in large vision-language models via image-grounded guidance , author=. arXiv preprint arXiv:2402.08680 , year=
-
[18]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Mitigating hallucinations in large vision-language models via summary-guided decoding , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[19]
The hidden life of tokens: Reducing hallucination of large vision-language models via visual information steering , author=. arXiv preprint arXiv:2502.03628 , year=
-
[20]
Forty-second International Conference on Machine Learning (ICML) , year=
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models , author=. Forty-second International Conference on Machine Learning (ICML) , year=
-
[21]
Zhang, Ce and Wan, Zifu and Kan, Zhehan and Ma, Martin Q. and Stepputtis, Simon and Ramanan, Deva and Salakhutdinov, Russ and Morency, Louis-Philippe and Sycara, Katia and Xie, Yaqi , booktitle =. Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models , volume =
-
[22]
Probing Visual Language Priors in
Luo, Tiange and Cao, Ang and Lee, Gunhee and Johnson, Justin and Lee, Honglak , booktitle =. Probing Visual Language Priors in. 2025 , editor =
work page 2025
-
[23]
arXiv preprint arXiv:2410.11779 , year=
Mllm can see? dynamic correction decoding for hallucination mitigation , author=. arXiv preprint arXiv:2410.11779 , year=
-
[24]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Deepseek-vl: towards real-world vision-language understanding , author=. arXiv preprint arXiv:2403.05525 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Instructdiffusion: A generalist modeling interface for vision tasks , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[27]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey , author=. arXiv preprint arXiv:2404.18930 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Towards injecting medical visual knowledge into multimodal llms at scale , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
work page 2024
-
[30]
A Survey on Hallucination in Large Vision-Language Models
A survey on hallucination in large vision-language models , author=. arXiv preprint arXiv:2402.00253 , year=
work page internal anchor Pith review arXiv
-
[31]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[32]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Shikra: Unleashing multimodal llm's referential dialogue magic , author=. arXiv preprint arXiv:2306.15195 , year=
work page internal anchor Pith review arXiv
-
[33]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites , author=. arXiv preprint arXiv:2404.16821 , year=
work page internal anchor Pith review arXiv
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
arXiv preprint arXiv:2403.00425 , year=
Halc: Object hallucination reduction via adaptive focal-contrast decoding , author=. arXiv preprint arXiv:2403.00425 , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Multi-modal hallucination control by visual information grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Detecting and preventing hallucinations in large vision language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exposing and mitigating spurious correlations for cross-modal retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Analyzing and Mitigating Object Hallucination in Large Vision-Language Models , volume =
Zhou, Yiyang and Cui, Chenhang and Yoon, Jaehong and Zhang, Linjun and Deng, Zhun and Finn, Chelsea and Bansal, Mohit and Yao, Huaxiu , booktitle =. Analyzing and Mitigating Object Hallucination in Large Vision-Language Models , volume =
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
Vision Transformers Need Registers , volume =
Darcet, Timoth\'. Vision Transformers Need Registers , volume =. International Conference on Representation Learning , editor =
-
[42]
Advances in Neural Information Processing Systems , volume=
Hyper-sd: Trajectory segmented consistency model for efficient image synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models , author=. arXiv preprint arXiv:2407.07895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[45]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
European Conference on Computer Vision , pages=
Paying more attention to image: A training-free method for alleviating hallucination in lvlms , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[49]
Vision Transformers Don't Need Trained Registers , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.