Recognition: no theorem link
A Performance-Portable, Massively Parallel Distributed Nonuniform FFT
Pith reviewed 2026-05-12 05:12 UTC · model grok-4.3
The pith
The first distributed performance-portable NUFFT runs on NVIDIA and AMD GPUs and scales to 1024 units.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
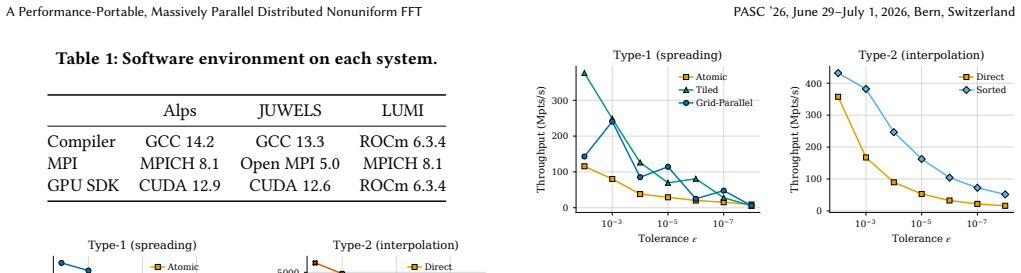
We present the first distributed, performance-portable NUFFT for heterogeneous supercomputers. Our Kokkos-based implementation runs without modification on NVIDIA and AMD GPUs. We develop multiple spreading and interpolation kernels optimized for different accuracy requirements and architectures. Our spreading kernels match or exceed the single-GPU throughput of the state-of-the-art CUDA-based NUFFT library cuFINUFFT at production particle densities, while our Kokkos-based implementation additionally supports AMD GPUs. Strong scaling experiments on Alps, JUWELS Booster, and LUMI demonstrate scaling up to 1024 GPUs. At scale, the distributed FFT is a significant part of the total runtime, and
What carries the argument
Kokkos abstractions for spreading, interpolation, and distributed FFT operations that enable the same source code to deliver competitive performance across GPU architectures.
Load-bearing premise
The Kokkos layer produces throughput comparable to hand-tuned vendor code on both NVIDIA and AMD GPUs without hidden architecture-specific changes, and the added communication cost of the distributed FFT does not prevent scaling.
What would settle it
A side-by-side benchmark at fixed particle density showing the Kokkos version on AMD MI250X GPUs delivers less than 60 percent of the throughput of the same code on NVIDIA GH200 or A100 GPUs, or a strong-scaling curve that flattens before 512 GPUs.
Figures








read the original abstract
The nonuniform fast Fourier transform (NUFFT) enables spectral methods for problems with irregularly spaced samples, with applications in medical imaging, molecular dynamics, and kinetic plasma simulations. Existing implementations are limited to shared-memory execution, restricting problem sizes to what fits on a single node. We present the first distributed, performance-portable NUFFT for heterogeneous supercomputers. Our Kokkos-based implementation runs without modification on NVIDIA and AMD GPUs. We develop multiple spreading and interpolation kernels optimized for different accuracy requirements and architectures. Our spreading kernels match or exceed the single-GPU throughput of the state-of-the-art CUDA-based NUFFT library cuFINUFFT at production particle densities, while our Kokkos-based implementation additionally supports AMD GPUs. Strong scaling experiments on Alps (NVIDIA GH200), JUWELS Booster (NVIDIA A100), and LUMI (AMD MI250X) demonstrate scaling up to 1024 GPUs. At scale, the distributed FFT is a significant part of the total runtime, making higher NUFFT accuracy less expensive. We apply the method to massively parallel Particle-in-Fourier simulations of Landau damping with up to $1024^3$ Fourier modes and 8.6 billion particles on Alps, JUWELS, and LUMI, demonstrating that distributed NUFFTs enable kinetic plasma simulations at resolutions previously inaccessible to spectral particle methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first distributed, performance-portable NUFFT implementation using Kokkos for heterogeneous supercomputers supporting both NVIDIA and AMD GPUs. The spreading kernels are said to match or exceed the single-GPU performance of cuFINUFFT at production densities, with strong scaling demonstrated up to 1024 GPUs on systems like Alps, JUWELS, and LUMI, and applied to large-scale Particle-in-Fourier simulations of Landau damping with up to 1024^3 Fourier modes and 8.6 billion particles.
Significance. This work could significantly advance the field by enabling spectral methods for very large problems on modern GPU-based supercomputers, particularly benefiting kinetic plasma simulations that require high resolution. The performance-portable aspect is valuable for users across different hardware platforms, and the scaling results suggest practical utility at exascale.
major comments (2)
- [Abstract] The abstract reports performance parity with cuFINUFFT and scaling to 1024 GPUs but provides no quantitative data, error bars, exact benchmark conditions, or methodology details, which is necessary to evaluate the claims.
- [Section 4] The kernel descriptions and performance results must explicitly demonstrate that only portable Kokkos primitives are used in the spreading and interpolation kernels, without architecture-specific tuning or vendor intrinsics, to support the claim of competitive performance on AMD GPUs without modification.
minor comments (1)
- [Abstract] Clarify the specific accuracy requirements for which the multiple spreading kernels were optimized.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work's significance and for the constructive major comments. We address each point below and will revise the manuscript to strengthen the presentation of our claims while respecting abstract length constraints.
read point-by-point responses
-
Referee: [Abstract] The abstract reports performance parity with cuFINUFFT and scaling to 1024 GPUs but provides no quantitative data, error bars, exact benchmark conditions, or methodology details, which is necessary to evaluate the claims.
Authors: We agree that including select quantitative details would help readers evaluate the claims more readily. Abstracts are subject to strict length limits, so we will add a concise sentence reporting key metrics (e.g., single-GPU spreading throughput in particles per second at representative densities and strong-scaling efficiency to 1024 GPUs) together with the primary benchmark platforms and particle densities used for the cuFINUFFT comparison. Full error bars, methodology, and per-run data will remain in Sections 4 and 5, but the added abstract sentence will provide the requested context without exceeding typical abstract word counts. revision: partial
-
Referee: [Section 4] The kernel descriptions and performance results must explicitly demonstrate that only portable Kokkos primitives are used in the spreading and interpolation kernels, without architecture-specific tuning or vendor intrinsics, to support the claim of competitive performance on AMD GPUs without modification.
Authors: We appreciate this clarification request. Our kernels were written exclusively with Kokkos portable abstractions (parallel_for, TeamPolicy, View, atomic_add, and Kokkos::complex) and contain no CUDA, HIP, or vendor-intrinsic code. In the revised Section 4 we will (i) list the exact Kokkos primitives employed in each kernel variant, (ii) include short pseudocode excerpts illustrating the portable implementation, and (iii) add an explicit statement that the identical source compiles and runs on both NVIDIA and AMD GPUs. These additions will directly substantiate the performance-portability claim while preserving the existing performance results. revision: yes
Circularity Check
No circularity: implementation and benchmarking paper with no derivations
full rationale
This is a software engineering and performance benchmarking paper describing a Kokkos-based distributed NUFFT implementation. It contains no mathematical derivation chain, no fitted parameters presented as predictions, no self-citation load-bearing uniqueness theorems, and no ansatz smuggling. All central claims (portability, throughput matching cuFINUFFT, strong scaling to 1024 GPUs) are supported by direct empirical measurements on multiple architectures and machines. The paper is self-contained against external benchmarks and therefore exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Axel Arnold, Florian Fahrenberger, Christian Holm, Olaf Lenz, Matthias Bolten, Holger Dachsel, Rene Halver, Ivo Kabadshow, Franz Gähler, Frederik Heber, Julian Iseringhausen, Michael Hofmann, Michael Pippig, Daniel Potts, and Godehard Sutmann. 2013. Comparison of scalable fast methods for long-range interactions. Physical Review E88, 6 (Dec. 2013), 063308...
-
[2]
Alan Ayala, Stanimire Tomov, Azzam Haidar, and Jack Dongarra. 2020. heFFTe: Highly Efficient FFT for Exascale. InComputational Science – ICCS 2020, Valeria V. Krzhizhanovskaya, Gábor Závodszky, Michael H. Lees, Jack J. Dongarra, Peter M. A. Sloot, Sérgio Brissos, and João Teixeira (Eds.). Vol. 12137. Springer Inter- national Publishing, Cham, 262–275. doi...
-
[3]
Alex H. Barnett. 2021. Aliasing error of theexp(𝛽 √ 1−𝑧 2 ) kernel in the nonuni- form fast Fourier transform.Applied and Computational Harmonic Analysis51 (March 2021), 1–16. doi:10.1016/j.acha.2020.10.002
-
[4]
Alexander H. Barnett, Jeremy Magland, and Ludvig af Klinteberg. 2019. A Parallel Nonuniform Fast Fourier Transform Library Based on an “Exponential of Semi- circle” Kernel.SIAM Journal on Scientific Computing41, 5 (Jan. 2019), C479–C504. doi:10.1137/18M120885X
-
[5]
C. K. Birdsall and A. B. Langdon. 1991.Plasma Physics via Computer Simulation. IOP Publishing, Bristol, UK. https://ui.adsabs.harvard.edu/abs/1991ppcs.book..... B ADS Bibcode: 1991ppcs.book.....B
work page 1991
-
[6]
H. Carter Edwards, Christian R. Trott, and Daniel Sunderland. 2014. Kokkos: Enabling manycore performance portability through polymorphic memory access patterns.J. Parallel and Distrib. Comput.74, 12 (Dec. 2014), 3202–3216. doi:10. 1016/j.jpdc.2014.07.003
work page 2014
- [7]
-
[8]
Kenneth Czechowski, Casey Battaglino, Chris McClanahan, Kartik Iyer, P.-K. Yeung, and Richard Vuduc. 2012. On the communication complexity of 3D FFTs and its implications for Exascale. InProceedings of the 26th ACM International Conference on Supercomputing. ACM, San Servolo Island, Venice, Italy, 205–214. doi:10.1145/2304576.2304604
-
[9]
A. Dutt and V. Rokhlin. 1993. Fast Fourier Transforms for Nonequispaced Data. SIAM Journal on Scientific Computing14, 6 (Nov. 1993), 1368–1393. doi:10.1137/ 0914081
work page 1993
-
[10]
A. Dutt and V. Rokhlin. 1995. Fast Fourier Transforms for Nonequispaced Data, II.Applied and Computational Harmonic Analysis2, 1 (Jan. 1995), 85–100. doi:10. 1006/acha.1995.1007
-
[11]
Chaolu Feng and Dazhe Zhao. 2015. CUDA accelerated uniform re-sampling for non-Cartesian MR reconstruction.Bio-Medical Materials and Engineering26 Suppl 1 (2015), S983–989. doi:10.3233/BME-151393
-
[12]
J. A. Fessler and B. P. Sutton. 2003. Nonuniform fast Fourier transforms using min-max interpolation.IEEE Transactions on Signal Processing51, 2 (Feb. 2003), 560–574. doi:10.1109/TSP.2002.807005
-
[13]
Matthias Frey, Alessandro Vinciguerra, Sriramkrishnan Muralikrishnan, Sonali, vmontanaro, Mohsen, Andreas Adelmann, manuel5975p, and Felix Schurk. 2024. IPPL-framework/ippl: IPPL-3.2.0. doi:10.5281/ZENODO.10878166
-
[14]
Holtrop, Xiao-Long Wu, Fan Lam, Maojing Fu, Justin P
Jiading Gai, Nady Obeid, Joseph L. Holtrop, Xiao-Long Wu, Fan Lam, Maojing Fu, Justin P. Haldar, Wen-mei W. Hwu, Zhi-Pei Liang, and Bradley P. Sutton
-
[15]
More IMPATIENT: A Gridding-Accelerated Toeplitz-based Strategy for Non-Cartesian High-Resolution 3D MRI on GPUs.J. Parallel and Distrib. Comput. 73, 5 (May 2013), 686–697. doi:10.1016/j.jpdc.2013.01.001
-
[16]
Leslie Greengard and June-Yub Lee. 2004. Accelerating the Nonuniform Fast Fourier Transform.SIAM Rev.46, 3 (Jan. 2004), 443–454. doi:10.1137/ S003614450343200X
work page 2004
-
[17]
Roger W. Hockney and J. W. Eastwood. 1981.Computer Simulation using particles. McGraw-Hill, New York, NY
work page 1981
-
[18]
James F. Kaiser. 1966. Digital Filters. InSystem Analysis by Digital Computer, Franklin F. Kuo and James F. Kaiser (Eds.). John Wiley and Sons, New York, Chapter 7, 218–285
work page 1966
-
[19]
Jens Keiner, Stefan Kunis, and Daniel Potts. 2009. Using NFFT 3—A Software Library for Various Nonequispaced Fast Fourier Transforms.ACM Trans. Math. Software36, 4 (Aug. 2009), 1–30. doi:10.1145/1555386.1555388
- [20]
-
[21]
InProceedings of the International Society for Magnetic Resonance in Medicine(Milan, Italy), Vol
gpuNUFFT – An Open Source GPU Library for 3D Regridding with Direct Matlab Interface. InProceedings of the International Society for Magnetic Resonance in Medicine(Milan, Italy), Vol. 22. International Society for Magnetic Resonance in Medicine, Berkeley, CA, USA, 4297. https://archive.ismrm.org/2014/4297.html
work page 2014
-
[22]
Susanne Kunis and Stefan Kunis. 2012. The nonequispaced FFT on graphics processing units.PAMM12, 1 (Dec. 2012), 7–10. doi:10.1002/pamm.201210003
-
[23]
Jyh-Miin Lin. 2018. Python Non-Uniform Fast Fourier Transform (PyNUFFT): An Accelerated Non-Cartesian MRI Package on a Heterogeneous Platform (CPU/GPU).Journal of Imaging4, 3 (March 2018), 51. doi:10.3390/ jimaging4030051
work page 2018
-
[24]
J. Markel. 1971. FFT pruning.IEEE Transactions on Audio and Electroacoustics19, 4 (Dec. 1971), 305–311. doi:10.1109/TAU.1971.1162205
-
[25]
Matthew S. Mitchell, Matthew T. Miecnikowski, Gregory Beylkin, and Scott E. Parker. 2019. Efficient Fourier basis particle simulation.J. Comput. Phys.396 (Nov. 2019), 837–847. doi:10.1016/j.jcp.2019.07.023
-
[26]
Guy M. Morton. 1966.A Computer Oriented Geodetic Data Base and a New Tech- nique in File Sequencing. Technical Report. IBM Ltd., Ottawa, Ontario, Canada
work page 1966
-
[27]
M. J. Muckley, R. Stern, T. Murrell, and F. Knoll. 2020. TorchKbNufft: A High- Level, Hardware-Agnostic Non-Uniform Fast Fourier Transform. ISMRM Work- shop on Data Sampling & Image Reconstruction. https://mmuckley.github. io/assets/publications/2020muckleytorchkbnufft.pdf Source code available at https://github.com/mmuckley/torchkbnufft
work page 2020
-
[28]
Cerfon, Miroslav Stoyanov, Rahulkumar Gayatri, and Andreas Adelmann
Sriramkrishnan Muralikrishnan, Matthias Frey, Alessandro Vinciguerra, Michael Ligotino, Antoine J. Cerfon, Miroslav Stoyanov, Rahulkumar Gayatri, and Andreas Adelmann. 2024. Scaling and performance portability of the particle-in-cell scheme for plasma physics applications through mini-apps targeting exascale architectures. InProceedings of the 2024 SIAM C...
-
[29]
Sriramkrishnan Muralikrishnan and Robert Speck. 2025. Error Analysis and Parallel Scaling Study of a Parareal Parallel-in-Time Integration Algorithm for Particle-in-Fourier Schemes.SIAM Journal on Scientific Computing(Oct. 2025), S311–S336. doi:10.1137/24M1673097
-
[30]
2026.NVIDIA Hopper Tuning Guide
NVIDIA Corporation. 2026.NVIDIA Hopper Tuning Guide. NVIDIA Corporation. https://docs.nvidia.com/cuda/hopper-tuning-guide/index.html Last updated April 2, 2026
work page 2026
-
[31]
Andrei Osipov, Vladimir Rokhlin, and Hong Xiao. 2013.Prolate Spheroidal Wave Functions of Order Zero: Mathematical Tools for Bandlimited Approxi- mation. Applied Mathematical Sciences, Vol. 187. Springer US, Boston, MA. doi:10.1007/978-1-4614-8259-8
-
[32]
2016.Massively Parallel, Fast Fourier Transforms and Particle-Mesh Methods
Michael Pippig. 2016.Massively Parallel, Fast Fourier Transforms and Particle-Mesh Methods. PhD thesis. Technische Universität Chemnitz, Chemnitz, Germany
work page 2016
-
[33]
Michael Pippig and Daniel Potts. 2013. Parallel Three-Dimensional Noneq- uispaced Fast Fourier Transforms and Their Application to Particle Simula- tion.SIAM Journal on Scientific Computing35, 4 (Jan. 2013), C411–C437. doi:10.1137/120888478
-
[34]
Juan Ignacio Polanco. 2024.NonuniformFFTs.jl. doi:10.5281/zenodo.14637606
-
[35]
Daniel Potts, Gabriele Steidl, and M. Tasche. 2001. Fast Fourier transforms for nonequispaced data: a tutorial.Mod. Sampl. theory23 (Jan. 2001), 19–25
work page 2001
-
[36]
Daniel Potts and Manfred Tasche. 2021. Continuous window functions for NFFT. Advances in Computational Mathematics47, 4 (Aug. 2021), 53. doi:10.1007/s10444- 021-09873-8
-
[37]
Daniel Potts and Manfred Tasche. 2021. Uniform error estimates for nonequi- spaced fast Fourier transforms.Sampling Theory, Signal Processing, and Data Analysis19, 2 (Dec. 2021), 17. doi:10.1007/s43670-021-00017-z
-
[38]
Changxiao Nigel Shen, Antoine Cerfon, and Sriramkrishnan Muralikrishnan
-
[39]
A particle-in-Fourier method with semi-discrete energy conservation for non-periodic boundary conditions.J. Comput. Phys.519 (Dec. 2024), 113390. doi:10.1016/j.jcp.2024.113390
-
[40]
Yu-hsuan Shih, Garrett Wright, Joakim Anden, Johannes Blaschke, and Alex H. Barnett. 2021. cuFINUFFT: a load-balanced GPU library for general-purpose nonuniform FFTs. In2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, Portland, OR, USA, 688–697. doi:10.1109/ IPDPSW52791.2021.00105
-
[41]
H. V. Sorensen and C. S. Burrus. 1993. Efficient computation of the DFT with only a subset of input or output points.IEEE Transactions on Signal Processing41, 3 (March 1993), 1184–1200. doi:10.1109/78.205723
-
[42]
Jingzhu Yang, Chaolu Feng, and Dazhe Zhao. 2013. A CUDA-based reverse gridding algorithm for MR reconstruction.Magnetic Resonance Imaging31, 2 (Feb. 2013), 313–323. doi:10.1016/j.mri.2012.06.038
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.