Recognition: 2 theorem links
· Lean TheoremWhat should post-training optimize? A test-time scaling law perspective
Pith reviewed 2026-05-12 05:16 UTC · model grok-4.3
The pith
Best-of-N post-training can use far fewer rollouts than deployment by extrapolating upper-tail reward statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under structural assumptions on the reward tails, the policy gradient of the best-of-N objective can be approximated from a much smaller rollout group by extrapolating upper-tail statistics. This yields a family of Tail-Extrapolated estimators for best-of-N-oriented post-training: a simple direct estimator, Tail-Extrapolated Advantage (TEA), and a fixed-order debiased Prefix-TEA estimator based on moment cancellation.
What carries the argument
Tail-Extrapolated estimators that recover the best-of-N policy gradient by extrapolating upper-tail statistics from m much smaller than N rollouts per prompt.
If this is right
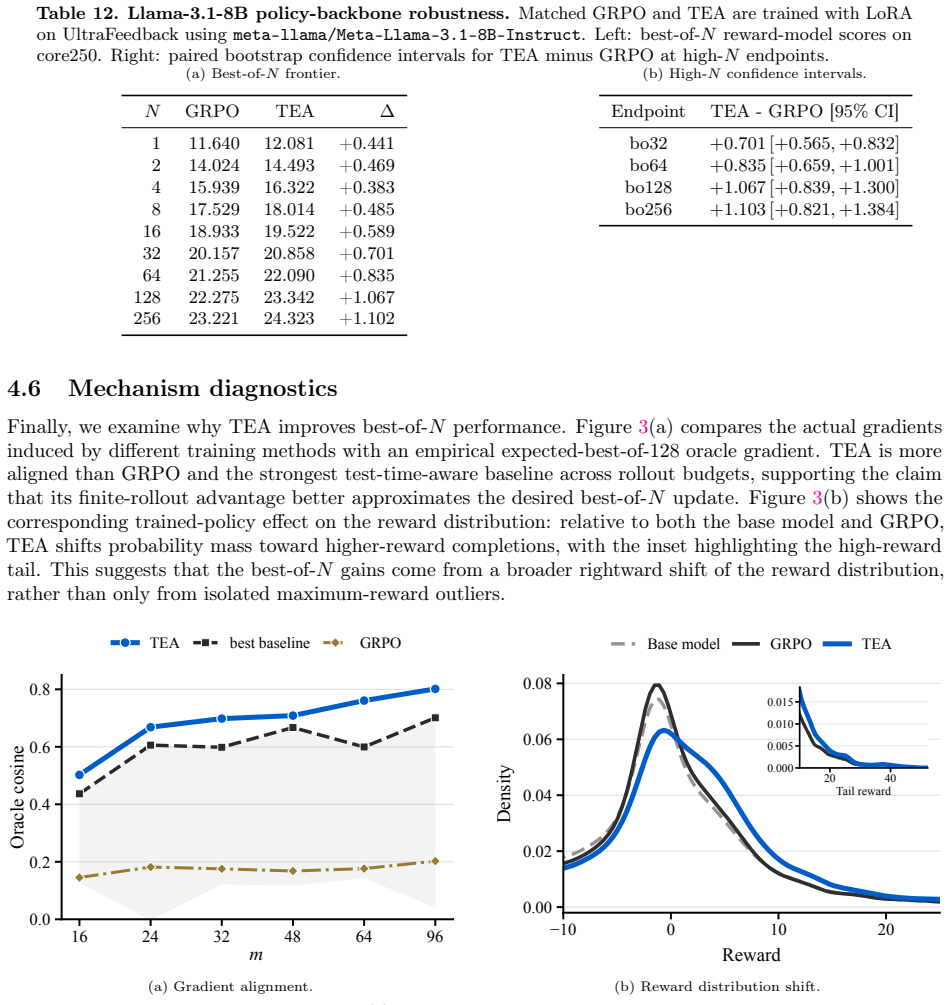
- TEA and Prefix-TEA raise best-of-N scores across instruction-following tasks, models, reward models, and budget regimes.
- Post-training can now target the actual deployment rule without requiring the same per-prompt sample count used at test time.
- The approach reduces the training compute needed to align with large-N inference strategies.
- Moment-cancellation in Prefix-TEA removes fixed-order bias while preserving the tail-extrapolation benefit.
Where Pith is reading between the lines
- Similar tail-extrapolation techniques could be applied to other test-time strategies such as tree search or multi-step reasoning.
- The reliability of the method will depend on how often real reward models exhibit the required tail regularity across different tasks and domains.
- One could derive explicit scaling relations that predict the minimal m needed for a target N given measured tail parameters.
- The estimators might transfer to non-LLM settings where optimization must focus on extreme rather than average outcomes.
Load-bearing premise
The upper tail of the reward distribution obeys structural properties that permit accurate extrapolation of the best-of-N gradient from a small number of samples.
What would settle it
Experiments in which the TEA estimators produce no gain in best-of-N performance or diverge sharply from full-N gradients on reward distributions whose tails violate the assumed structure.
Figures



read the original abstract
Large language models are increasingly deployed with test-time strategies: sample $N$ responses, score them with a reward model or verifier, and return the best. This deployment rule exposes a mismatch in post-training: standard objectives optimize the mean reward of a single response, whereas best-of-$N$ performance is governed by the upper tail of the reward distribution. Recent test-time-aware objectives partly address this mismatch, but typically assume that training can use the same per-prompt rollout budget as deployment, which is impractical when post-training must cover many prompts while deployment can allocate much larger per-prompt test-time compute. We study this budget-mismatch regime, where only $m\ll N$ per-prompt rollouts are available during training but the target objective is best-of-$N$ deployment. Under structural assumptions on the reward tails, we show that the policy gradient of the best-of-$N$ objective can be approximated from a much smaller rollout group by extrapolating upper-tail statistics. This yields a family of Tail-Extrapolated estimators for best-of-$N$-oriented post-training: a simple direct estimator, Tail-Extrapolated Advantage (TEA), and a fixed-order debiased Prefix-TEA estimator based on moment cancellation. Experiments on instruction-following tasks show that TEA and Prefix-TEA improve best-of-$N$ performance across different language models, reward models and datasets under various training and test-time budget settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the mismatch between standard post-training objectives (optimizing mean reward) and test-time best-of-N deployment in LLMs, where performance depends on the upper tail of the reward distribution. Under structural assumptions on reward tails, it derives that the best-of-N policy gradient can be approximated from m ≪ N per-prompt rollouts via extrapolation of upper-tail statistics. This yields a family of Tail-Extrapolated estimators, including a direct estimator, Tail-Extrapolated Advantage (TEA), and a debiased Prefix-TEA based on moment cancellation. Experiments on instruction-following tasks report improved best-of-N performance across models, reward models, datasets, and budget settings.
Significance. If the structural assumptions on reward tails hold and the estimators deliver low-bias approximations to the true best-of-N gradient, the work provides a principled method to optimize post-training for test-time scaling strategies without requiring matching rollout budgets. This could improve efficiency in aligning models for high-compute deployment regimes and shift focus from mean to tail performance in RLHF-style objectives.
major comments (2)
- [Abstract] Abstract and derivation sections: The central approximation of the best-of-N policy gradient via tail extrapolation is conditioned on unspecified structural assumptions about reward tails (e.g., domain of attraction, stability of extrapolation operator); these are load-bearing but receive no explicit statement or sensitivity analysis.
- [Experiments] Experimental results: Downstream best-of-N gains are reported, but there is no direct held-out validation that the TEA or Prefix-TEA gradient estimates match the true N-sample best-of-N gradient (or even the sign/direction) when m ≪ N; this leaves the approximation bias uncontrolled.
minor comments (2)
- Clarify the precise form of the tail assumptions (Gumbel, Fréchet, etc.) and any moment-matching or extreme-value conditions used in the extrapolation operator.
- Define rollout budgets m and N consistently with explicit notation in the problem setup.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without overstating the current results.
read point-by-point responses
-
Referee: [Abstract] Abstract and derivation sections: The central approximation of the best-of-N policy gradient via tail extrapolation is conditioned on unspecified structural assumptions about reward tails (e.g., domain of attraction, stability of extrapolation operator); these are load-bearing but receive no explicit statement or sensitivity analysis.
Authors: We agree that the assumptions are load-bearing and should be stated explicitly rather than referenced generically. In the revised manuscript we will add a dedicated paragraph in the derivation section that formally lists the assumptions: (i) per-prompt reward distributions belong to the domain of attraction of a non-degenerate extreme-value law, (ii) the upper-tail extrapolation operator is stable under the chosen parametric family (generalized Pareto), and (iii) the tail index is identifiable from the m-sample order statistics. We will also insert a short sensitivity subsection that varies the assumed tail index over a plausible range and reports the resulting change in estimator performance and best-of-N gains. revision: yes
-
Referee: [Experiments] Experimental results: Downstream best-of-N gains are reported, but there is no direct held-out validation that the TEA or Prefix-TEA gradient estimates match the true N-sample best-of-N gradient (or even the sign/direction) when m ≪ N; this leaves the approximation bias uncontrolled.
Authors: We acknowledge that downstream performance alone does not directly quantify approximation bias or sign agreement. Computing the exact best-of-N gradient at deployment-scale N is prohibitive for the full experimental suite. In the revision we will add a controlled small-scale study on a held-out subset of prompts: for each prompt we draw a very large number of additional rollouts (N = 512) to obtain a high-fidelity reference gradient, then compare it to the m-sample TEA and Prefix-TEA estimates via cosine similarity, sign agreement rate, and normalized bias. These metrics will be reported alongside the existing end-to-end results. revision: yes
Circularity Check
No significant circularity: derivation relies on explicit structural assumptions rather than self-referential reduction
full rationale
The paper states that under structural assumptions on reward tails, the best-of-N policy gradient can be approximated by extrapolating upper-tail statistics from m ≪ N rollouts, yielding TEA and Prefix-TEA estimators. This is an approximation derived from the stated assumptions, not a quantity fitted directly to the target best-of-N metric or defined in terms of itself. No equations, self-citations, or ansatzes in the provided text reduce the central claim to its inputs by construction. Experiments across models and datasets provide independent validation of downstream performance, confirming the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structural assumptions on the reward tails
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearUnder structural assumptions on the reward tails, we show that the policy gradient of the best-of-N objective can be approximated from a much smaller rollout group by extrapolating upper-tail statistics. This yields a family of Tail-Extrapolated estimators...
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclearAssumption 1. ... the upper 2α tail of the reward distribution is Gaussian, namely pθ,x(r) = ϕ(r; μθ(x), σ²θ(x)), r ≥ rθ,2α(x)
Reference graph
Works this paper leans on
-
[1]
Farid Bagirov, Mikhail Arkhipov, Ksenia Sycheva, Evgeniy Glukhov, and Egor Bogomolov. The best of n worlds: Aligning reinforcement learning with best-of-n sampling via max@ k optimisation.arXiv preprint arXiv:2510.23393, 2025
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
arXiv preprint arXiv:2412.19792 , year=
Ananth Balashankar, Ziteng Sun, Jonathan Berant, Jacob Eisenstein, Michael Collins, Adrian Hutter, Jong Lee, Chirag Nagpal, Flavien Prost, Aradhana Sinha, et al. Infalign: Inference-aware language model alignment.arXiv preprint arXiv:2412.19792, 2024
-
[4]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine-tuning for best-of-n sampling in large language models.arXiv preprint arXiv:2412.15287, 2024
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377,
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, et al. Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377, 2023
-
[8]
Bonbon alignment for large language models and the sweetness of best-of-n sampling
Lin Gui, Cristina Gârbacea, and Victor Veitch. Bonbon alignment for large language models and the sweetness of best-of-n sampling. volume 37, pages 2851–2885, 2024
work page 2024
-
[9]
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefen- stette, and Roberta Raileanu. Understanding the effects of rlhf on llm generalisation and diversity.arXiv preprint arXiv:2310.06452, 2023
-
[10]
Muheng Li, Jian Qian, and Wenlong Mou. Predicting and improving test-time scaling laws via reward tail-guided search.arXiv preprint arXiv:2602.01485, 2026
-
[11]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜ u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Compute Aligned Training: Optimizing for Test Time Inference
Adam Ousherovitch and Ambuj Tewari. Compute aligned training: Optimizing for test time inference. arXiv preprint arXiv:2604.24957, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[14]
Attributing mode collapse in the fine-tuning of large language models
Laura O’Mahony, Leo Grinsztajn, Hailey Schoelkopf, and Stella Biderman. Attributing mode collapse in the fine-tuning of large language models. InICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models, volume 2, page 2, 2024. 17
work page 2024
-
[15]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[16]
Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D Lee, and Sanjeev Arora. What makes a reward model a good teacher? an optimization perspective.arXiv preprint arXiv:2503.15477, 2025
-
[17]
Haskell P Rosenthal. On the subspaces of l p (p> 2) spanned by sequences of independent random variables.Israel Journal of Mathematics, 8(3):273–303, 1970
work page 1970
-
[18]
WR Schucany, HL Gray, and DB Owen. On bias reduction in estimation.Journal of the American Statistical Association, 66(335):524–533, 1971
work page 1971
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for llm reinforcement fine-tuning through difficulty-targeted online data selection and rollout replay.arXiv preprint arXiv:2506.05316, 2025
-
[22]
Yunhao Tang, Kunhao Zheng, Gabriel Synnaeve, and Rémi Munos. Optimizing language models for inference time objectives using reinforcement learning.arXiv preprint arXiv:2503.19595, 2025
-
[23]
Christian Walder and Deep Karkhanis. Pass@ k policy optimization: Solving harder reinforcement learning problems.arXiv preprint arXiv:2505.15201, 2025
-
[24]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
-
[26]
Jixiao Zhang and Chunsheng Zuo. Grpo-lead: A difficulty-aware reinforcement learning approach for concise mathematical reasoning in language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5642–5665, 2025. 18 A Additional related work Single-response post-training.Most LLM post-training methods are d...
work page 2025
-
[27]
Therefore, E ∥ˆηm −ˆη(−1) m ∥2 ⩽ C m2
By Cauchy–Schwarz, the empirical tail moment envelope in Lemma 5, andP(Ec 1)⩽Ce −cm, E h ∥ˆηm −ˆη(−1) m ∥2I{E c 1} i ⩽Ce −cm. Therefore, E ∥ˆηm −ˆη(−1) m ∥2 ⩽ C m2 . TheL 1 bound follows by Cauchy–Schwarz: E ∥ˆηm −ˆη(−1) m ∥ ⩽ E∥ˆηm −ˆη(−1) m ∥2 1/2 ⩽ C m . This completes the proof. The next lemma isolates the same-batch error of the direct plug-in estima...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.