Recognition: 2 theorem links
· Lean TheoremProvable Sparse Inversion and Token Relabel Enhanced One-shot Federated Learning with ViTs
Pith reviewed 2026-05-12 04:39 UTC · model grok-4.3
The pith
Sparse foreground inversion and token relabeling deliver tighter generalization bounds for one-shot federated ViT learning under non-IID data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
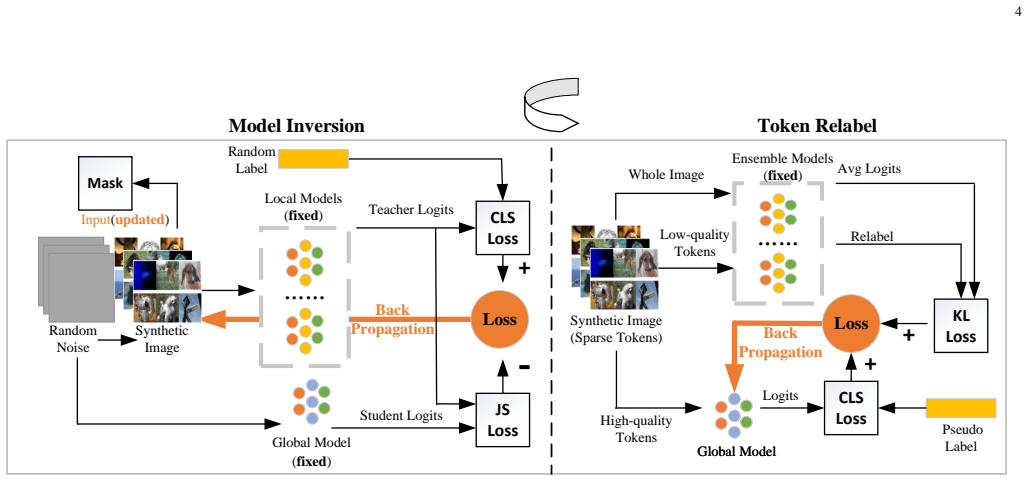
The FedMITR framework trains the global model by fully exploiting all patches of synthetic images through sparse model inversion that selectively inverts semantic foregrounds and halts background inversion, paired with a token relabel strategy that uses generated pseudo-labels for high-information-density patches and ensemble relabeling for low-density patches, which the stability analysis proves eliminates gradient instability from background noise and reduces gradient variance to guarantee a tighter generalization bound.
What carries the argument
Sparse Model Inversion combined with the differentiated Token Relabel strategy inside the FedMITR framework, which isolates foreground semantics during data synthesis and applies ensemble distillation only to uninformative ViT tokens.
If this is right
- All patches of the synthetic images can be used for ViT training instead of being discarded when they carry low information.
- Gradient instability arising from background noise is removed by the sparse inversion step.
- Gradient variance during distillation is reduced by switching to ensemble relabeling on low-density tokens.
- The resulting generalization bound is provably tighter than that of prior data-free one-shot methods.
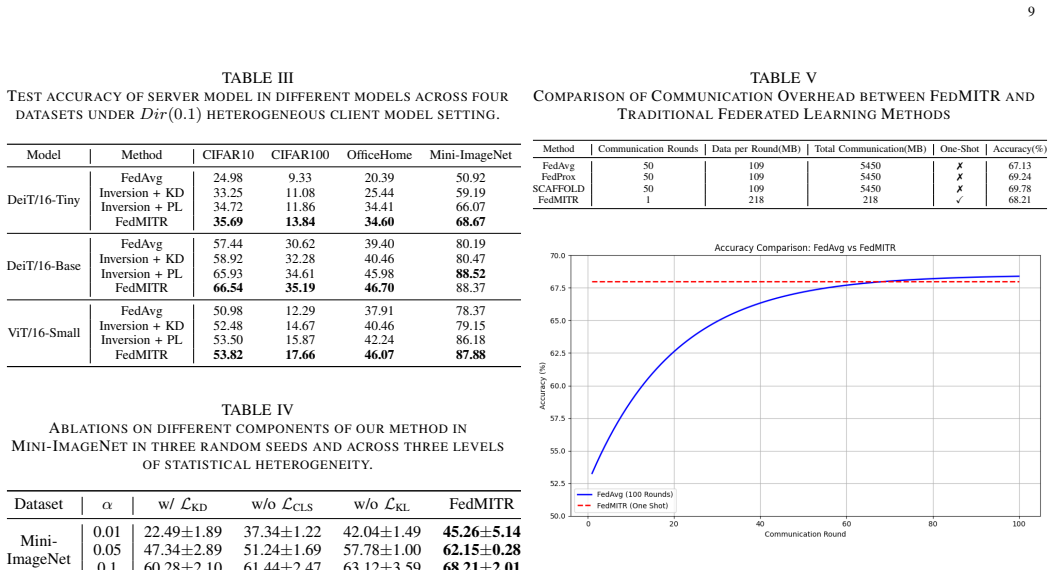
- Empirical accuracy exceeds existing baselines across multiple non-IID partitions and ViT architectures.
Where Pith is reading between the lines
- The same foreground-focused inversion plus density-aware relabeling pattern could be tested on other transformer families beyond ViTs to check whether the stability benefit generalizes.
- The stability analysis supplies a concrete recipe for designing regularization terms that penalize background leakage in any data-free federated setting.
- Measuring per-patch information density at inference time might yield a lightweight way to decide which tokens need relabeling without retraining ensembles.
Load-bearing premise
Sparse inversion of synthetic images can reliably isolate semantic foregrounds without discarding information needed for accurate ViT predictions, and ensemble relabeling of low-density patches produces labels that remain sufficiently robust under extreme non-IID partitions.
What would settle it
An ablation that disables sparse inversion while keeping the rest of the pipeline fixed and measures whether gradient instability from background noise increases and the empirical generalization gap widens on a standard non-IID benchmark.
Figures




read the original abstract
One-Shot Federated Learning, where a central server learns a global model in a single communication round, has emerged as a promising paradigm. However, under extremely non-IID settings, existing data-free methods often generate low-quality data that suffers from severe semantic misalignment with ground-truth labels. To overcome these issues, we propose a novel Federated Model Inversion and Token Relabel (FedMITR) framework, which trains the global model by fully exploiting all patches of synthetic images. Specifically, FedMITR employs sparse model inversion during data generation, selectively inverting semantic foregrounds while halting the inversion of uninformative backgrounds. To address semantically meaningless tokens that hinder ViT predictions, we implement a differentiated strategy: patches with high information density utilize generated pseudo-labels, while patches with low information density are relabeled via ensemble models for robust distillation. Theoretically, our analysis based on algorithmic stability reveals that Sparse Model Inversion eliminates gradient instability arising from background noise, while Token Relabel effectively reduces gradient variance, collectively guaranteeing a tighter generalization bound. Empirically, extensive experimental results demonstrate that FedMITR substantially outperforms existing baselines under various settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the FedMITR framework for one-shot federated learning with Vision Transformers. It introduces Sparse Model Inversion to selectively invert semantic foregrounds of synthetic images while halting background inversion, paired with a Differentiated Token Relabel strategy that applies generated pseudo-labels to high-density patches and ensemble relabeling to low-density patches. The paper claims that an algorithmic stability analysis shows these steps eliminate background-induced gradient instability and reduce variance, yielding a tighter generalization bound, and reports substantial empirical gains over baselines under extreme non-IID partitions.
Significance. If the stability bound is rigorously established, the work would offer a principled mechanism for improving synthetic data quality in data-free one-shot FL, with particular relevance to ViT architectures that are sensitive to token-level noise. The explicit credit for the sparse-inversion-plus-relabel combination as a way to exploit all patches is a constructive contribution, but its impact depends on whether the theoretical tightening is independent of the method's own hyperparameters.
major comments (1)
- Abstract (theoretical claim): the assertion that Sparse Model Inversion 'eliminates gradient instability arising from background noise' and thereby guarantees a tighter generalization bound assumes that standard algorithmic stability results extend to the non-smooth sparse selection operator. Sparse inversion performs a hard threshold or argmax on patch information density, which is discontinuous and non-Lipschitz; uniform stability bounds for SGD require Lipschitz continuity of the loss in the data and small continuous perturbations. No auxiliary lemma bounding the sensitivity of the selected foreground subset to inversion-model perturbations is referenced, so the claimed elimination of instability and the resulting bound tightness do not follow from the stated premises.
minor comments (1)
- Abstract: the single-paragraph presentation interleaves method, theory, and results so densely that the logical flow from sparse inversion to stability improvement is difficult to parse on first reading.
Simulated Author's Rebuttal
We thank the referee for the careful and technically precise comment on the stability analysis. We agree that the non-smooth nature of the sparse selection step requires an auxiliary result to rigorously extend standard algorithmic stability bounds, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract (theoretical claim): the assertion that Sparse Model Inversion 'eliminates gradient instability arising from background noise' and thereby guarantees a tighter generalization bound assumes that standard algorithmic stability results extend to the non-smooth sparse selection operator. Sparse inversion performs a hard threshold or argmax on patch information density, which is discontinuous and non-Lipschitz; uniform stability bounds for SGD require Lipschitz continuity of the loss in the data and small continuous perturbations. No auxiliary lemma bounding the sensitivity of the selected foreground subset to inversion-model perturbations is referenced, so the claimed elimination of instability and the resulting bound tightness do not follow from the stated premises.
Authors: We thank the referee for highlighting this important technical gap. The sparse inversion indeed applies a hard selection on patch information density, which is discontinuous. In the revised manuscript we will insert an auxiliary lemma (new Lemma 3.2) that bounds the sensitivity of the foreground subset to perturbations in the inversion model. Under the assumption that the information-density scoring function is Lipschitz continuous with respect to model parameters (satisfied by the convolutional or ViT-based inversion networks used), the symmetric difference between selected subsets is controlled by O(perturbation magnitude). This allows the composite loss to remain Lipschitz with a modified constant, so that the standard uniform-stability argument for SGD carries through with an additive term that vanishes as the perturbation goes to zero. Consequently, the background-induced gradient instability is provably suppressed and the generalization bound tightens as claimed. We will also update the abstract and Section 3 to reference the new lemma explicitly. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central theoretical claim applies standard algorithmic stability analysis to the effects of Sparse Model Inversion (foreground selection) and Token Relabel (ensemble distillation on low-density patches), asserting that these steps eliminate background-induced gradient instability and reduce variance to yield a tighter generalization bound. No equations are presented in which the stability constants are defined in terms of the target bound itself, nor is the bound obtained by fitting parameters to the same data used for the claim. The analysis is not shown to rely on self-citations whose authors overlap and whose uniqueness results are unverified; the derivation therefore remains independent of its own outputs and does not reduce to a tautology or renaming of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Algorithmic stability analysis yields a valid generalization bound when applied to the proposed sparse inversion and token relabel training dynamics
invented entities (2)
-
Sparse Model Inversion
no independent evidence
-
Differentiated Token Relabel strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial Intelligence and statistics. PMLR, 2017, pp. 1273–1282
work page 2017
-
[2]
Federated Learning: Strategies for Improving Communication Efficiency
J. Konecn `y, H. B. McMahan, F. X. Yu, P. Richt´arik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,”arXiv preprint arXiv:1610.05492, vol. 8, 2016
work page internal anchor Pith review arXiv 2016
-
[3]
Fedrec++: Lossless federated recommendation with explicit feedback,
F. Liang, W. Pan, and Z. Ming, “Fedrec++: Lossless federated recommendation with explicit feedback,” in Proceedings of the AAAI conference on artificial intel- ligence, vol. 35, no. 5, 2021, pp. 4224–4231
work page 2021
-
[4]
Fedct: Federated collaborative transfer for recommen- dation,
S. Liu, S. Xu, W. Yu, Z. Fu, Y . Zhang, and A. Marian, “Fedct: Federated collaborative transfer for recommen- dation,” inProceedings of the 44th international ACM SIGIR conference on research and development in infor- mation retrieval, 2021, pp. 716–725
work page 2021
-
[5]
Q. Liu, C. Chen, J. Qin, Q. Dou, and P.-A. Heng, “Feddg: Federated domain generalization on medical image seg- mentation via episodic learning in continuous frequency space,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1013–1023
work page 2021
-
[6]
Feddad: Federated domain adaptation for object detection,
P. J. Lu, C.-Y . Jui, and J.-H. Chuang, “Feddad: Federated domain adaptation for object detection,”IEEE Access, 2023. 11
work page 2023
-
[7]
Visual object de- tection for privacy-preserving federated learning,
J. Zhang, J. Zhou, J. Guo, and X. Sun, “Visual object de- tection for privacy-preserving federated learning,”IEEE Access, vol. 11, pp. 33 324–33 335, 2023
work page 2023
-
[8]
A secure and efficient federated learning framework for nlp,
J. Deng, C. Wang, X. Meng, Y . Wang, J. Li, S. Lin, S. Han, F. Miao, S. Rajasekaran, and C. Ding, “A secure and efficient federated learning framework for nlp,”arXiv preprint arXiv:2201.11934, 2022
-
[9]
Federated learning: Challenges, methods, and future directions,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Federated learning: Challenges, methods, and future directions,” IEEE signal processing magazine, vol. 37, no. 3, pp. 50– 60, 2020
work page 2020
-
[10]
Dfedadmm: Dual constraint controlled model inconsistency for de- centralize federated learning,
Q. Li, L. Shen, G. Li, Q. Yin, and D. Tao, “Dfedadmm: Dual constraint controlled model inconsistency for de- centralize federated learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 4803–4815, 2025
work page 2025
-
[11]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Ben- nis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummingset al., “Advances and open problems in federated learning,”Foundations and Trends® in Ma- chine Learning, vol. 14, no. 1–2, pp. 1–210, 2021
work page 2021
-
[12]
R. Dai, L. Shen, F. He, X. Tian, and D. Tao, “Dispfl: Towards communication-efficient personalized federated learning via decentralized sparse training,” inInterna- tional Conference on Machine Learning. PMLR, 2022, pp. 4587–4604
work page 2022
-
[13]
Man- in-the-middle attacks against machine learning classifiers via malicious generative models,
D. Wang, C. Li, S. Wen, S. Nepal, and Y . Xiang, “Man- in-the-middle attacks against machine learning classifiers via malicious generative models,”IEEE Transactions on Dependable and Secure Computing, vol. 18, no. 5, pp. 2074–2087, 2021
work page 2074
-
[14]
A survey on se- curity and privacy of federated learning,
V . Mothukuri, R. M. Parizi, S. Pouriyeh, Y . Huang, A. Dehghantanha, and G. Srivastava, “A survey on se- curity and privacy of federated learning,”Future Gener- ation Computer Systems, vol. 115, pp. 619–640, 2021
work page 2021
-
[15]
See through gradients: Image batch recovery via gradinversion,
H. Yin, A. Mallya, A. Vahdat, J. M. Alvarez, J. Kautz, and P. Molchanov, “See through gradients: Image batch recovery via gradinversion,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2021, pp. 16 337–16 346
work page 2021
-
[16]
N. Guha, A. Talwalkar, and V . Smith, “One-shot feder- ated learning,”arXiv preprint arXiv:1902.11175, 2019
-
[17]
Modeldb: a system for machine learning model management,
M. Vartak, H. Subramanyam, W.-E. Lee, S. Viswanathan, S. Husnoo, S. Madden, and M. Zaharia, “Modeldb: a system for machine learning model management,” in Proceedings of the Workshop on Human-In-the-Loop Data Analytics, 2016, pp. 1–3
work page 2016
-
[18]
Parametric feature transfer: One-shot federated learning with foundation models,
M. Beitollahi, A. Bie, S. Hemati, L. M. Brunswic, X. Li, X. Chen, and G. Zhang, “Parametric feature transfer: One-shot federated learning with foundation models,” arXiv preprint arXiv:2402.01862, 2024
-
[19]
Dense: Data-free one-shot fed- erated learning,
J. Zhang, C. Chen, B. Li, L. Lyu, S. Wu, S. Ding, C. Shen, and C. Wu, “Dense: Data-free one-shot fed- erated learning,”Advances in Neural Information Pro- cessing Systems, vol. 35, pp. 21 414–21 428, 2022
work page 2022
-
[20]
Fine-tuning global model via data-free knowledge dis- tillation for non-iid federated learning,
L. Zhang, L. Shen, L. Ding, D. Tao, and L.-Y . Duan, “Fine-tuning global model via data-free knowledge dis- tillation for non-iid federated learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 174–10 183
work page 2022
-
[21]
Distilled one-shot federated learning,
Y . Zhou, G. Pu, X. Ma, X. Li, and D. Wu, “Distilled one-shot federated learning,”arXiv preprint arXiv:2009.07999, 2020
-
[22]
Practical one-shot federated learning for cross-silo setting,
Q. Li, B. He, and D. Song, “Practical one-shot federated learning for cross-silo setting,” inProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2021, pp. 1484–1490, main Track. [Online]. Available: https://doi.org/10.24...
-
[23]
Towards addressing label skews in one-shot federated learning,
Y . Diao, Q. Li, and B. He, “Towards addressing label skews in one-shot federated learning,” inThe Eleventh International Conference on Learning Representations,
-
[24]
Available: https://openreview.net/forum? id=rzrqh85f4Sc
[Online]. Available: https://openreview.net/forum? id=rzrqh85f4Sc
-
[25]
Data-free one-shot federated learning under very high statistical heterogeneity,
C. E. Heinbaugh, E. Luz-Ricca, and H. Shao, “Data-free one-shot federated learning under very high statistical heterogeneity,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id= hb4vM3jspB
work page 2023
-
[26]
Exploring one- shot semi-supervised federated learning with pre-trained diffusion models,
M. Yang, S. Su, B. Li, and X. Xue, “Exploring one- shot semi-supervised federated learning with pre-trained diffusion models,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 38, no. 15, 2024, pp. 16 325–16 333
work page 2024
-
[27]
Model in- version attacks that exploit confidence information and basic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model in- version attacks that exploit confidence information and basic countermeasures,” inProceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1322–1333
work page 2015
-
[28]
Model inversion attacks against collaborative inference,
Z. He, T. Zhang, and R. B. Lee, “Model inversion attacks against collaborative inference,” inProceedings of the 35th Annual Computer Security Applications Conference, 2019, pp. 148–162
work page 2019
-
[29]
Adversarial neural network inversion via auxiliary knowledge alignment,
Z. Yang, E.-C. Chang, and Z. Liang, “Adversarial neural network inversion via auxiliary knowledge alignment,” arXiv preprint arXiv:1902.08552, 2019
-
[30]
Data-free knowl- edge distillation via feature exchange and activation region constraint,
S. Yu, J. Chen, H. Han, and S. Jiang, “Data-free knowl- edge distillation via feature exchange and activation region constraint,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 266–24 275
work page 2023
-
[31]
Deep classifier mimicry without data access,
S. Braun, M. Mundt, and K. Kersting, “Deep classifier mimicry without data access,” inInternational Confer- ence on Artificial Intelligence and Statistics. PMLR, 2024, pp. 4762–4770
work page 2024
-
[32]
G. Patel, K. R. Mopuri, and Q. Qiu, “Learning to retain while acquiring: combating distribution-shift in adver- sarial data-free knowledge distillation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7786–7794
work page 2023
-
[33]
Dreaming to distill: Data-free knowledge transfer via deepinversion,
H. Yin, P. Molchanov, J. M. Alvarez, Z. Li, A. Mallya, D. Hoiem, N. K. Jha, and J. Kautz, “Dreaming to distill: Data-free knowledge transfer via deepinversion,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020, pp. 8715–8724. 12
work page 2020
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural informa- tion processing systems, vol. 30, 2017
work page 2017
-
[36]
Training data-efficient image trans- formers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablay- rolles, and H. J´egou, “Training data-efficient image trans- formers & distillation through attention,” inInternational conference on machine learning. PMLR, 2021, pp. 10 347–10 357
work page 2021
-
[37]
Enhancing one-shot federated learning through data and ensemble co-boosting,
R. Dai, Y . Zhang, A. Li, T. Liu, X. Yang, and B. Han, “Enhancing one-shot federated learning through data and ensemble co-boosting,”arXiv preprint arXiv:2402.15070, 2024
-
[38]
Inverting visual represen- tations with convolutional networks,
A. Dosovitskiy and T. Brox, “Inverting visual represen- tations with convolutional networks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4829–4837
work page 2016
-
[39]
Ensemble distillation for robust model fusion in federated learning,
T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 2351–2363, 2020
work page 2020
-
[40]
All tokens matter: Token labeling for training better vision transformers,
Z.-H. Jiang, Q. Hou, L. Yuan, D. Zhou, Y . Shi, X. Jin, A. Wang, and J. Feng, “All tokens matter: Token labeling for training better vision transformers,”Advances in neu- ral information processing systems, vol. 34, pp. 18 590– 18 602, 2021
work page 2021
-
[41]
Not all patches are what you need: Expediting vision transformers via token reorganizations
Y . Liang, C. Ge, Z. Tong, Y . Song, J. Wang, and P. Xie, “Not all patches are what you need: Expediting vision transformers via token reorganizations,”arXiv preprint arXiv:2202.07800, 2022
-
[42]
Stability and generaliza- tion,
O. Bousquet and A. Elisseeff, “Stability and generaliza- tion,”Journal of machine learning research, vol. 2, no. Mar, pp. 499–526, 2002
work page 2002
-
[43]
Train faster, gener- alize better: Stability of stochastic gradient descent,
M. Hardt, B. Recht, and Y . Singer, “Train faster, gener- alize better: Stability of stochastic gradient descent,” in International conference on machine learning. PMLR, 2016, pp. 1225–1234
work page 2016
-
[44]
A. Blum, J. Hopcroft, and R. Kannan,Foundations of data science. Cambridge University Press, 2020
work page 2020
-
[45]
A statistical perspective on distillation,
A. K. Menon, A. S. Rawat, S. Reddi, S. Kim, and S. Kumar, “A statistical perspective on distillation,” in International Conference on Machine Learning. PMLR, 2021, pp. 7632–7642
work page 2021
-
[46]
Dreaming to dis- till: Data-free knowledge transfer via deepinversion,
H. Yin, P. Molchanov, J. M. Alvarez, Z. Li, A. Mallya, D. Hoiem, N. K. Jha, and J. Kautz, “Dreaming to dis- till: Data-free knowledge transfer via deepinversion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[47]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,”Master thesis, 2009
work page 2009
-
[48]
Deep hashing network for unsupervised do- main adaptation,
H. Venkateswara, J. Eusebio, S. Chakraborty, and S. Pan- chanathan, “Deep hashing network for unsupervised do- main adaptation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5018–5027
work page 2017
-
[49]
Matching networks for one shot learning,
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstraet al., “Matching networks for one shot learning,”Advances in neural information processing systems, vol. 29, 2016
work page 2016
-
[50]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bern- steinet al., “Imagenet large scale visual recognition challenge,”International journal of computer vision, vol. 115, pp. 211–252, 2015
work page 2015
-
[51]
M. Mohri, A. Rostamizadeh, and A. Talwalkar,Founda- tions of machine learning. MIT press, 2018. 13 APPENDIX A. More details about the Experiment Datasets and partitions.Our experiments are conducted on the following four popular real-world datasets: CIFAR10 [46], CIFAR100 [46], OfficeHome [47] and Mini-ImageNet [48]. CIFAR10 [46] consists of 60,000 color ...
work page 2018
-
[52]
train a generator that considers similarity, stability, and transferability and performe federated distillation on the server side. Co-Boosting [36] uses the current Ensemble to synthesize higher-quality samples in an adversarial manner. These hard samples are then employed to promote the quality of the Ensemble by adjusting the ensembling weights for eac...
-
[53]
Gradient Formulation in Vision Transformers:Let the input sequenceX∈R N×D be partitioned into a set of semantic foreground indicesI h and background noise indicesI l. The Multi-Head Self-Attention (MSA) layer computes the outputZ as: Z=MSA(X) =AXW V ,whereA=Softmax XW QW T KX T √ d (25) Here,A∈R N×N is the attention matrix andW V is the value projection w...
-
[54]
The error signal isδ DI =p(X)−y, wherep(X)is the softmax probability
Instability of Dense Inversion (DI):In Dense Inversion, the objective is the cross-entropy loss against a hard labely: LDI =ℓ CE(f(X), y). The error signal isδ DI =p(X)−y, wherep(X)is the softmax probability. We analyze the gradient contribution from background noise tokens (j∈ I l). Substituting into Eq. (26): ∇(noise) WV LDI = X j∈Il (Xj)T (AT ):,jδDI (...
-
[55]
Stability of FedMITR:FedMITR decouples the loss function: LF ed =ℓ CE(f(X h), y)| {z } Term 1: Sparsity +λ ℓKL(f(X l), E(Xl))| {z } Term 2: Relabeling (28) We prove that FedMITR strictly reduces the gradient norm via two mechanisms: gradient elimination (Sparsity) and gradient variance reduction (Relabeling). Mechanism 1: Sparsity as Gradient Elimination....
-
[56]
Main Theorem and Conclusion:We formally establish the inequality of Lipschitz constants. Theorem 1(Lipschitz Constant Reduction).LetL DI andL F ed be the Lipschitz constants of the loss gradients with respect to model parameters for Dense Inversion and FedMITR, respectively. Under Assumption 1, Assumption 2, and Lemma 3, we have: LF ed < L DI (33) Proof.T...
-
[57]
Analysis of Dense Inversion (L DI ):The noise component is driven by the interaction between the high-energy noise inputX noise and the hard-label error signalδ hard. L(noise) DI ∝sup (∥X noise∥ · ∥δhard∥) Under Assumption 2,∥δ hard∥is saturated (large) due to orthogonality. Thus, the product∥X noise∥ · ∥δhard∥constitutes a large gradient upper bound
-
[58]
Analysis of FedMITR (L F ed):The noise component is decoupled into two terms: •Sparsity Term:The effective input is masked to zero ( ˜X= 0). Consequently, the backpropagated gradient norm is: ∥ ˜X T AT δhard∥=∥0·A T δhard∥= 0 •Relabeling Term:The input isX noise, but the error signal isδ sof t. The gradient norm is: L(relabel) F ed ∝λsup (∥X noise∥ · ∥δsof t∥)
-
[59]
Comparison:Combining the components, we compare the upper bounds: LDI ≈L f g +C·E[∥δ hard∥] LF ed ≈L f g + 0 +λC·E[∥δ sof t∥] whereCrepresents the common factor involving input and attention norms. According to Lemma 3, the expected norm of the error signal from soft labels is strictly smaller than that from hard labels due to variance reduction:E[∥δ sof ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.