Recognition: 2 theorem links
· Lean TheoremRadThinking: A Dataset for Longitudinal Clinical Reasoning in Radiology
Pith reviewed 2026-05-12 03:50 UTC · model grok-4.3
The pith
RadThinking releases a VQA dataset that supplies explicit reasoning chains for cancer-screening radiology questions at three depths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
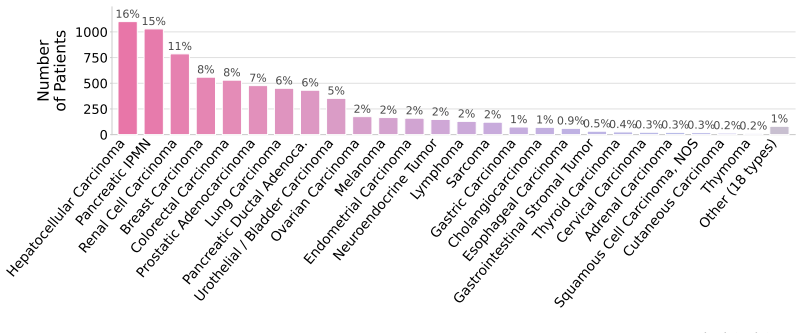
RadThinking is a Visual Question Answering corpus that stratifies questions by reasoning depth and grounds every compositional composition in the rules of the governing clinical reporting standard. Foundation VQAs test atomic perception. Single-step VQAs test one clinical rule. Compositional VQAs require multi-step chain-of-thought to reach a guideline category. For every compositional question the authors release the supporting chain of foundation questions. The corpus covers 20,362 CT scans from 9,131 patients across 43 cancer groups plus 2,077 verified healthy controls with more than one year of follow-up.
What carries the argument
The tiered VQA structure in which each compositional question is paired with its explicit chain of foundation questions that follows the rules of the governing clinical reporting standard.
If this is right
- The foundation tier supplies atomic perception supervision that can be used to train perception modules.
- The compositional tier supplies chain-of-thought traces that can serve as verifiable rewards for reinforcement-learning recipes.
- Models trained on the dataset can be evaluated on whether they reach the same guideline category as the reference chain.
- The longitudinal span across multiple scans per patient enables training that compares current findings to prior examinations.
- The dataset can be used to measure whether an AI system merely detects lesions or actually performs the multi-step reasoning required by screening guidelines.
Where Pith is reading between the lines
- If the chains prove reliable, the same construction method could be applied to other imaging modalities or organ systems that use standardized reporting lexicons.
- Success on the compositional tier would indicate that an AI system can produce auditable intermediate steps rather than black-box diagnoses.
- The dataset's size and stratification allow controlled experiments that isolate the contribution of each reasoning depth to final diagnostic accuracy.
Load-bearing premise
The automatically or semi-automatically generated VQA pairs and reasoning chains accurately reflect genuine clinical reasoning without introducing systematic errors or inconsistencies with real radiologist practice.
What would settle it
A panel of radiologists reviews a random sample of the released reasoning chains and finds that more than 15 percent of the compositional chains contain a clinically incorrect step or violate the cited reporting guideline.
Figures

read the original abstract
Cancer screening is a reasoning task. A radiologist observes findings, compares them to prior scans, integrates clinical context, and reaches a diagnostic conclusion confirmed by pathology. We present RadThinking, a Visual Question Answering (VQA) dataset that makes this reasoning explicit and trainable. RadThinking releases VQA pairs at three difficulty tiers. Foundation VQAs are atomic perception questions. Single-step reasoning VQAs apply one clinical rule. Compositional VQAs require multi-step chain-of-thought to reach a guideline category such as LI-RADS-5. For every compositional VQA, we release the chain of foundation VQAs that solves it. The chain follows the rules of the governing clinical reporting standard. The dataset spans 20,362 CT scans from 9,131 patients across 43 cancer groups, plus 2,077 verified healthy controls with >1-year follow-up. To our knowledge, RadThinking is the first cancer-screening VQA corpus that stratifies questions by reasoning depth and grounds compositions in clinical reporting standards. The foundation tier supplies atomic perception supervision. The compositional tier supplies chain-of-thought data and verifiable rewards for reinforcement-learning recipes such as DeepSeek-R1 and OpenAI o1. RadThinking enables systematic training and evaluation of whether AI systems can reason about cancer, not merely detect it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RadThinking, a VQA dataset for longitudinal clinical reasoning in radiology cancer screening. It releases VQA pairs stratified into three tiers: foundation (atomic perception questions), single-step reasoning (applying one clinical rule), and compositional (multi-step chain-of-thought to reach guideline categories such as LI-RADS-5). For every compositional VQA, the corresponding chain of foundation VQAs is released and claimed to follow the rules of the governing clinical reporting standard. The dataset covers 20,362 CT scans from 9,131 patients across 43 cancer groups plus 2,077 verified healthy controls with >1-year follow-up. It positions itself as the first cancer-screening VQA corpus to stratify by reasoning depth and ground compositions in clinical standards, supplying atomic perception supervision and chain-of-thought data for RL-based training.
Significance. If the reasoning chains are shown to accurately reflect clinical practice, RadThinking would be a significant resource for medical AI by enabling explicit supervision of compositional and longitudinal reasoning rather than isolated detection. The tiered design supports progressive model training and provides verifiable rewards for methods such as chain-of-thought RL, while the scale and multi-cancer coverage increase its potential utility for developing systems that integrate findings across time and context.
major comments (1)
- [Abstract] Abstract: The central claim that compositional VQAs 'require multi-step chain-of-thought to reach a guideline category such as LI-RADS-5' and that 'the chain follows the rules of the governing clinical reporting standard' is unsupported by any description of the VQA generation pipeline, expert review, inter-annotator agreement, or quality-control metrics. This detail is load-bearing for the assertion that the dataset grounds compositions in clinical reporting standards and supplies faithful chain-of-thought data.
minor comments (2)
- The abstract states the dataset 'spans 20,362 CT scans' but provides no breakdown by tier, cancer group, or reasoning depth; a summary table would improve clarity on scale and balance.
- The claim of being 'the first' such corpus would be strengthened by explicit comparison to prior radiology VQA datasets in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the single major comment below and will make the requested revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that compositional VQAs 'require multi-step chain-of-thought to reach a guideline category such as LI-RADS-5' and that 'the chain follows the rules of the governing clinical reporting standard' is unsupported by any description of the VQA generation pipeline, expert review, inter-annotator agreement, or quality-control metrics. This detail is load-bearing for the assertion that the dataset grounds compositions in clinical reporting standards and supplies faithful chain-of-thought data.
Authors: We agree that the abstract currently states the claim without referencing the supporting methodology, which weakens the manuscript. In the revised version we will (1) update the abstract to briefly note that compositional chains are constructed according to explicit clinical reporting rules and (2) add a dedicated subsection in Methods that fully describes the VQA generation pipeline. This subsection will detail the rule-based chaining procedure, the role of board-certified radiologists in annotation and verification, inter-annotator agreement statistics, and the quality-control steps used to ensure the released chains remain faithful to the governing clinical standards. revision: yes
Circularity Check
Dataset release paper exhibits no circularity
full rationale
This is a dataset paper that releases VQA pairs stratified by reasoning depth and grounded in clinical standards. It contains no derivations, equations, fitted parameters, predictions, or first-principles results that could reduce to prior quantities by construction. Claims of novelty and composition are descriptive rather than deductive, with no self-citation chains or ansatzes invoked to force any outcome. The generation process is described at a high level but does not involve any circular reduction of results to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical reporting standards such as LI-RADS provide accurate and complete rules for diagnostic reasoning in cancer screening.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RadThinking releases VQA pairs at three difficulty tiers... For every compositional VQA, we release the chain of foundation VQAs that solves it. The chain follows the rules of the governing clinical reporting standard.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The three tiers form a curriculum from atomic skills to multi-step clinical reasoning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Agrawal, S. Antoniak, E. B. Hanna, B. Bout, D. Chaplot, J. Chudnovsky, D. Costa, B. De Monicault, S. Garg, T. Gervet, et al. Pixtral 12B.arXiv preprint arXiv:2410.07073, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
J. A. Ajani, T. A. D’Amico, K. Almhanna, D. J. Bentrem, J. Chao, P. Das, C. S. Denlinger, P. Fanta, F. Farjah, C. S. Fuchs, et al. Gastric cancer, version 3.2016, nccn clinical practice guidelines in oncology.Journal of the National Comprehensive Cancer Network, 14(10): 1286–1312, 2016
work page 2016
-
[3]
J. A. Ajani, T. A. D’Amico, D. J. Bentrem, J. Chao, C. Corvera, P. Das, C. S. Denlinger, P. C. Enzinger, P. Fanta, F. Farjah, et al. Esophageal and esophagogastric junction cancers, version 2.2019, nccn clinical practice guidelines in oncology.Journal of the National Comprehensive Cancer Network, 17(7):855–883, 2019
work page 2019
-
[4]
S. Al-Katib, G. Gupta, A. Brudvik, S. Ries, J. Krauss, and M. Farah. A practical guide to managing ct findings in the breast.Clinical imaging, 60(2):274–282, 2020
work page 2020
- [5]
-
[6]
J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural module networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[7]
R. F. Andreotti, D. Timmerman, L. M. Strachowski, W. Froyman, B. R. Benacerraf, G. L. Bennett, T. Bourne, D. L. Brown, B. G. Coleman, M. C. Frates, et al. O-rads us risk stratification and management system: a consensus guideline from the acr ovarian-adnexal reporting and data system committee.Radiology, 294(1):168–185, 2020
work page 2020
-
[8]
The medical segmentation decathlon.arXiv preprint arXiv:2106.05735, 2021
M. Antonelli, A. Reinke, S. Bakas, K. Farahani, B. A. Landman, G. Litjens, B. Menze, O. Ronneberger, R. M. Summers, B. van Ginneken, et al. The medical segmentation decathlon. arXiv preprint arXiv:2106.05735, 2021
-
[9]
M. Atri, A. Alabousi, C. Reinhold, E. A. Akin, C. B. Benson, P. R. Bhosale, S. K. Kang, Y . Lakhman, R. Nicola, P. V . Pandharipande, et al. Acr appropriateness criteria® clinically suspected adnexal mass, no acute symptoms.Journal of the American College of Radiology, 16(5):S77–S93, 2019
work page 2019
- [10]
-
[11]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
P. R. Bassi, W. Li, Y . Tang, F. Isensee, Z. Wang, J. Chen, Y .-C. Chou, Y . Kirchhoff, M. Rokuss, Z. Huang, J. Ye, J. He, T. Wald, C. Ulrich, M. Baumgartner, S. Roy, K. H. Maier-Hein, P. Jaeger, Y . Ye, Y . Xie, J. Zhang, Z. Chen, Y . Xia, Z. Xing, L. Zhu, Y . Sadegheih, A. Bozorgpour, P. Kumari, R. Azad, D. Merhof, P. Shi, T. Ma, Y . Du, F. Bai, T. Huan...
work page 2024
-
[13]
P. R. Bassi, W. Li, J. Chen, Z. Zhu, T. Lin, S. Decherchi, A. Cavalli, K. Wang, Y . Yang, A. L. Yuille, and Z. Zhou. Learning segmentation from radiology reports. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 305–315. Springer, 2025. URLhttps://github.com/MrGiovanni/R-Super
work page 2025
-
[14]
P. R. Bassi, Q. Wu, W. Li, S. Decherchi, A. Cavalli, A. Yuille, and Z. Zhou. Label critic: Design data before models. InIEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2025. URLhttps://github.com/PedroRASB/LabelCritic. 10
work page 2025
-
[15]
P. R. Bassi, M. C. Yavuz, I. E. Hamamci, S. Er, X. Chen, W. Li, B. Menze, S. Decherchi, A. Cavalli, K. Wang, Y . Yang, A. Yuille, and Z. Zhou. Radgpt: Constructing 3d image-text tumor datasets. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23720–23730, 2025. URLhttps://github.com/MrGiovanni/RadGPT
work page 2025
-
[16]
P. R. Bassi, X. Zhou, W. Li, S. Płotka, J. Chen, Q. Chen, Z. Zhu, J. Prz ˛ ado, I. E. Hamamci, S. Er, X. Chen, M. C. Yavuz, Y .-C. Chou, T. Lin, K. Wang, Y . Tang, J. B. Cwikla, S. Decherchi, A. Cavalli, Y . Yang, A. L. Yuille, and Z. Zhou. Scaling artificial intelligence for multi-tumor early detection with more reports, fewer masks.arXiv preprint arXiv:...
- [17]
-
[18]
A. B. Benson, A. P. Venook, M. M. Al-Hawary, M. A. Arain, Y .-J. Chen, K. K. Ciombor, S. A. Cohen, H. S. Cooper, D. A. Deming, I. Garrido-Laguna, et al. Small bowel adenocarci- noma, version 1.2020, nccn clinical practice guidelines in oncology.Journal of the National Comprehensive Cancer Network, 17(9):1109–1133, 2019
work page 2020
-
[19]
The liver tumor segmentation benchmark (lits).arXiv preprint arXiv:1901.04056, 2019
P. Bilic, P. F. Christ, E. V orontsov, G. Chlebus, H. Chen, Q. Dou, C.-W. Fu, X. Han, P.- A. Heng, J. Hesser, et al. The liver tumor segmentation benchmark (lits).arXiv preprint arXiv:1901.04056, 2019
-
[20]
L. Blankemeier, J. P. Cohen, A. Kumar, D. Van Veen, S. J. S. Gardezi, M. Paschali, Z. Chen, J.-B. Delbrouck, E. Reis, C. Truyts, et al. Merlin: A vision language foundation model for 3d computed tomography.Research Square, pages rs–3, 2024
work page 2024
- [21]
-
[22]
Q. Chen, X. Chen, H. Song, Z. Xiong, A. Yuille, C. Wei, and Z. Zhou. Towards generalizable tumor synthesis. InIEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 11147–11158, 2024. URLhttps://github.com/MrGiovanni/DiffTumor
work page 2024
-
[23]
Q. Chen, X. Zhou, C. Liu, H. Chen, W. Li, Z. Jiang, Z. Huang, Y . Zhao, D. Yu, J. He, Y . Zheng, L. Shao, A. Yuille, and Z. Zhou. Scaling tumor segmentation: Best lessons from real and syn- thetic data. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 24001–24013, 2025. URLhttps://github.com/BodyMaps/AbdomenAtlas2.0
work page 2025
-
[24]
Y . Chen, W. Xiao, P. R. Bassi, X. Zhou, S. Er, I. E. Hamamci, Z. Zhou, and A. Yuille. Are vision language models ready for clinical diagnosis? a 3d medical benchmark for tumor- centric visual question answering.arXiv preprint arXiv:2505.18915, 2025. URL https: //github.com/Schuture/DeepTumorVQA
- [25]
-
[26]
V . Chernyak, K. J. Fowler, A. Kamaya, A. Z. Kielar, K. M. Elsayes, M. R. Bashir, Y . Kono, R. K. Do, D. G. Mitchell, A. G. Singal, et al. Liver imaging reporting and data system (li-rads) version 2018: imaging of hepatocellular carcinoma in at-risk patients.Radiology, 289(3): 816–830, 2018
work page 2018
-
[27]
B. D. Cheson, R. I. Fisher, S. F. Barrington, F. Cavalli, L. H. Schwartz, E. Zucca, and T. A. Lister. Recommendations for initial evaluation, staging, and response assessment of hodgkin and non-hodgkin lymphoma: the lugano classification.Journal of clinical oncology, 32(27): 3059–3067, 2014
work page 2014
-
[28]
Y .-C. Chou, B. Li, D.-P. Fan, A. Yuille, and Z. Zhou. Acquiring weak annotations for tumor localization in temporal and volumetric data.Machine Intelligence Research, pages 1–13,
-
[29]
URLhttps://github.com/johnson111788/Drag-Drop. 11
-
[30]
Y .-C. Chou, Z. Zhou, and A. Yuille. Embracing massive medical data. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 24–35. Springer, 2024. URLhttps://github.com/MrGiovanni/OnlineLearning
work page 2024
-
[31]
J. Christensen, A. E. Prosper, C. C. Wu, J. Chung, E. Lee, B. Elicker, A. R. Hunsaker, M. Petranovic, K. L. Sandler, B. Stiles, et al. Acr lung-rads v2022: assessment categories and management recommendations.Journal of the American College of Radiology, 21(3): 473–488, 2024
work page 2024
-
[32]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
M. de Grauw, E. T. Scholten, E. J. Smit, M. J. Rutten, M. Prokop, B. van Ginneken, and A. Hering. The uls23 challenge: A baseline model and benchmark dataset for 3d universal lesion segmentation in computed tomography.Medical image analysis, 102:103525, 2025
work page 2025
- [35]
- [36]
-
[37]
A. Diaz-Pinto, S. Alle, V . Nath, Y . Tang, A. Ihsani, M. Asad, F. Pérez-García, P. Mehta, W. Li, M. Flores, et al. Monai label: A framework for ai-assisted interactive labeling of 3d medical images.Medical Image Analysis, 95:103207, 2024
work page 2024
-
[38]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [39]
-
[40]
E. A. Eisenhauer, P. Therasse, J. Bogaerts, L. H. Schwartz, D. Sargent, R. Ford, J. Dancey, S. Arbuck, S. Gwyther, M. Mooney, et al. New response evaluation criteria in solid tumours: revised recist guideline (version 1.1).European journal of cancer, 45(2):228–247, 2009
work page 2009
- [41]
- [42]
-
[43]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
T. Gupta and A. Kembhavi. Visual programming: Compositional visual reasoning without training. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[45]
I. E. Hamamci, S. Er, and B. Menze. Ct2rep: Automated radiology report generation for 3d medical imaging. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 476–486. Springer, 2024. 12
work page 2024
-
[46]
I. E. Hamamci, S. Er, C. Wang, F. Almas, A. G. Simsek, S. N. Esirgun, I. Dogan, O. F. Durugol, B. Hou, S. Shit, et al. Generalist foundation models from a multimodal dataset for 3d computed tomography.Nature Biomedical Engineering, pages 1–19, 2026
work page 2026
-
[47]
X. He, Y . Zhang, L. Mou, E. Xing, and P. Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review arXiv 2003
-
[48]
M. T. Heller, M. Harisinghani, J. D. Neitlich, P. Yeghiayan, and L. L. Berland. Managing incidental findings on abdominal and pelvic ct and mri, part 3: white paper of the acr incidental findings committee ii on splenic and nodal findings.Journal of the American College of Radiology, 10(11):833–839, 2013
work page 2013
-
[49]
N. Heller, N. Sathianathen, A. Kalapara, E. Walczak, K. Moore, H. Kaluzniak, J. Rosenberg, P. Blake, Z. Rengel, M. Oestreich, et al. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes.arXiv preprint arXiv:1904.00445, 2019
-
[50]
B. R. Herts, S. G. Silverman, N. M. Hindman, R. G. Uzzo, R. P. Hartman, G. M. Israel, D. A. Baumgarten, L. L. Berland, and P. V . Pandharipande. Management of the incidental renal mass on ct: a white paper of the acr incidental findings committee.Journal of the American College of Radiology, 15(2):264–273, 2018
work page 2018
-
[51]
J. K. Hoang, J. E. Langer, W. D. Middleton, C. C. Wu, L. W. Hammers, J. J. Cronan, F. N. Tessler, E. G. Grant, and L. L. Berland. Managing incidental thyroid nodules detected on imaging: white paper of the acr incidental thyroid findings committee.Journal of the American College of Radiology, 12(2):143–150, 2015
work page 2015
- [52]
-
[53]
Y . Hu, T. Li, Q. Lu, W. Shao, J. He, Y . Qiao, and P. Luo. OmniMedVQA: A new large- scale comprehensive evaluation benchmark for medical LVLM. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[54]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
W. Huang, B. Jia, Z. Zhai, S. Cao, Z. Ye, F. Zhao, Y . Hu, and S. Lin. Vision-R1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
D. A. Hudson and C. D. Manning. GQA: A new dataset for real-world visual reasoning and compositional question answering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
- [56]
- [57]
-
[58]
J. Johnson, B. Hariharan, L. van der Maaten, L. Fei-Fei, C. Lawrence Zitnick, and R. Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[59]
M. Kang, B. Li, Z. Zhu, Y . Lu, E. K. Fishman, A. Yuille, and Z. Zhou. Label-assemble: Leverag- ing multiple datasets with partial labels. InIEEE International Symposium on Biomedical Imag- ing, pages 1–5. IEEE, 2023. URLhttps://github.com/MrGiovanni/LabelAssemble
work page 2023
-
[60]
T. Khot, H. Trivedi, M. Finlayson, Y . Fu, K. Richardson, P. Clark, and A. Sabharwal. Decom- posed prompting: A modular approach for solving complex tasks. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
- [61]
-
[62]
J. J. Lau, S. Gayen, A. Ben Abacha, and D. Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
work page 2018
- [63]
-
[64]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, Y . Li, Z. Liu, and C. Li. LLaV A-OneVision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
C. Li, C. Wong, S. Zhang, N. Usuyama, H. Liu, J. Yang, T. Naumann, H. Poon, and J. Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Ad- vances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[66]
W. Li, C. Qu, X. Chen, P. R. Bassi, Y . Shi, Y . Lai, Q. Yu, H. Xue, Y . Chen, X. Lin, Y . Tang, Y . Cao, H. Han, Z. Zhang, J. Liu, T. Zhang, Y . Ma, J. Wang, G. Zhang, A. Yuille, and Z. Zhou. Abdomenatlas: A large-scale, detailed-annotated, & multi-center dataset for efficient transfer learning and open algorithmic benchmarking.Medical Image Analysis, pa...
work page 2024
-
[67]
W. Li, A. Yuille, and Z. Zhou. How well do supervised models transfer to 3d image segmentation? InInternational Conference on Learning Representations, 2024. URL https://github.com/MrGiovanni/SuPreM
work page 2024
-
[68]
W. Li, P. R. Bassi, T. Lin, Y .-C. Chou, X. Zhou, Y . Tang, F. Isensee, K. Wang, Q. Chen, X. Xu, J. Ye, Z. Zhu, S. Decherchi, A. Cavalli, A. L. Yuille, and Z. Zhou. Scalemai: Accelerating the development of trusted datasets and ai models.arXiv preprint arXiv:2501.03410, 2025. URL https://github.com/MrGiovanni/ScaleMAI
-
[69]
W. Li, X. Zhou, Q. Chen, T. Lin, P. R. Bassi, X. Chen, C. Ye, Z. Zhu, K. Ding, H. Li, K. Wang, Y . Yang, Y . Tang, D. Xu, A. L. Yuille, and Z. Zhou. Pants: The pancreatic tumor segmentation dataset. InConference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025. URLhttps://github.com/MrGiovanni/PanTS
work page 2025
-
[70]
W. Li, P. R. A. S. Bassi, L. Wu, X. Zhou, Y . Zhao, Q. Chen, S. Plotka, T. Lin, Z. Zhu, M. Martin, J. Caskey, S. Jiang, X. Chen, J. B. ´Cwikła, A. Sankowski, Y . Wu, S. Decherchi, A. Cavalli, C. Lall, C. Tomasetti, Y . Guo, X. Yu, Y . Cai, H. Qiao, J. Bao, C. Hu, X. Wang, A. Sitek, K. Ding, H. Li, M. Wang, D. Yu, G. Zhang, Y . Yang, K. Wang, A. L. Yuille,...
-
[71]
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han. VILA: On pre-training for visual language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
- [72]
-
[73]
J. Liu, A. Yuille, Y . Tang, and Z. Zhou. Clip-driven universal model for partially labeled organ and pan-cancer segmentation. InMICCAI 2023 FLARE Challenge, 2023. URL https: //github.com/ljwztc/CLIP-Driven-Universal-Model
work page 2023
-
[74]
J. Liu, Y . Zhang, K. Wang, M. C. Yavuz, X. Chen, Y . Yuan, H. Li, Y . Yang, A. Yuille, Y . Tang, and Z. Zhou. Universal and extensible language-vision models for organ segmentation and tumor detection from abdominal computed tomography.Medical Image Analysis, page 103226,
-
[75]
URLhttps://github.com/ljwztc/CLIP-Driven-Universal-Model
-
[76]
R. Liu, I. Q. Mohiuddin, A. J. Schoeffler, K. Renduchintala, A. Nayak, P. L. Vemu, S. C. Vedak, K. C. Black, J. L. Havlik, I. Ogunmola, S. P. Ma, R. Dhatt, and J. H. Chen. PhysicianBench: Evaluating LLM agents in real-world EHR environments.arXiv preprint arXiv:2605.02240, 2026. 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Z. Liu, Z. Sun, Y . Zang, X. Dong, Y . Cao, H. Duan, D. Lin, and J. Wang. Visual-RFT: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review arXiv 2025
-
[78]
H. Lu, W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, et al. DeepSeek-VL: Towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
A. Lubonja, P. R. Bassi, W. Li, H. Qiao, R. Burns, A. L. Yuille, and Z. Zhou. Auditing significance, metric choice, and demographic fairness in medical ai challenges.arXiv preprint arXiv:2512.19091, 2025. URLhttps://github.com/ariellubonja/RankInsight
-
[80]
W. W. Mayo-Smith, J. H. Song, G. L. Boland, I. R. Francis, G. M. Israel, P. J. Mazzaglia, L. L. Berland, and P. V . Pandharipande. Management of incidental adrenal masses: a white paper of the acr incidental findings committee.Journal of the American College of Radiology, 14(8): 1038–1044, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.