Recognition: 2 theorem links
· Lean TheoremTrajPrism: A Multi-Task Benchmark for Language-Grounded Urban Trajectory Understanding
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
TrajPrism benchmark shows geometry-only models leave large gaps on language-trajectory tasks that language-aware models can close.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TrajPrism unifies instruction-conditioned trajectory generation, language-driven semantic trajectory retrieval, and trajectory captioning on 300K real trajectories from Porto, San Francisco, and Beijing. Language annotations are produced under a four-dimensional travel-intent taxonomy and judge-filtered to yield 2.1M task instances. The models TrajAnchor, TrajFuse, and TrajRap instantiate the tasks and show that geometry-only trajectory baselines leave a large gap on the protocol, especially where language forms part of the input-output interface.
What carries the argument
The four-dimensional travel-intent taxonomy used to generate and filter language annotations that link travel intents, constraints, and preferences to observed trajectories, together with the unified evaluation protocol that jointly scores trajectory fidelity, retrieval quality, and language groundedness.
If this is right
- Instruction-based generation of urban routes requires joint language and geometry modeling to match real traveler behavior.
- Semantic retrieval of trajectories from natural-language queries outperforms spatial-only matching on the benchmark.
- Accurate trajectory captioning depends on grounding descriptions in both path shape and semantic intent rather than geometry alone.
- The annotation pipeline and code can be reused on new cities that supply compatible trajectory data and map resources.
- Models must be evaluated on all three tasks together to measure true language-trajectory alignment.
Where Pith is reading between the lines
- Hybrid language-geometry architectures may become standard for any AI system that plans or explains movement in cities.
- The benchmark could support training of multimodal models that accept spoken or written mobility requests and output verifiable routes.
- Extending the taxonomy or adding cities would test whether the observed language advantage generalizes beyond the current three locations.
- If the gap persists across larger models, it suggests fundamental limits to purely geometric representations of human travel.
Load-bearing premise
The judge-filtered language annotations generated under the four-dimensional travel-intent taxonomy accurately and consistently capture the travel intents, constraints, and preferences present in the underlying real-world trajectories.
What would settle it
Re-annotating a held-out sample of trajectories with the same taxonomy and measuring inter-annotator agreement or correlation with independent human descriptions of the same trips; low agreement or weak correlation would show the annotations do not reliably represent the underlying intents.
Figures















read the original abstract
Urban mobility is naturally expressed both as trajectories in space and as natural-language descriptions of travel intent, constraints, and preferences. However, prior work rarely evaluates these two modalities together on the same real-world trajectories: trajectory modeling often stays geometry-centric, while language-centric mobility benchmarks frequently target route planning and tool use rather than fine-grained, verifiable alignment between text and the underlying route. We introduce TrajPrism, a multi-task benchmark for language-trajectory alignment that unifies (i) instruction-conditioned trajectory generation, (ii) language-driven semantic trajectory retrieval, and (iii) trajectory captioning, together with an evaluation protocol that measures trajectory fidelity, retrieval quality, and language groundedness. We construct TrajPrism by pairing real urban trajectories with judge-filtered language annotations generated under a four-dimensional travel-intent taxonomy. The benchmark contains 300K selected trajectories across Porto, San Francisco, and Beijing, yielding 2.1M task instances from three instruction variants, three retrieval queries, and one caption per trajectory. We further develop proof-of-concept models for each task: TrajAnchor for instruction-conditioned trajectory generation, TrajFuse for semantic trajectory retrieval, and TrajRap for trajectory captioning. These models instantiate the proposed tasks and show that geometry-only trajectory baselines leave a large gap on our protocol, especially where language is part of the input-output interface. We release TrajPrism with code and a reproducible annotation pipeline that is designed to be portable across cities, given compatible trajectory inputs and map resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrajPrism, a multi-task benchmark for language-grounded urban trajectory understanding. It constructs 300K real trajectories from Porto, San Francisco, and Beijing paired with judge-filtered language annotations under a four-dimensional travel-intent taxonomy, producing 2.1M task instances across instruction-conditioned trajectory generation, language-driven semantic retrieval, and trajectory captioning. Proof-of-concept models (TrajAnchor, TrajFuse, TrajRap) are developed and used to show that geometry-only trajectory baselines leave a large performance gap on the proposed protocol, especially on tasks involving language in the input-output interface. The benchmark, code, and reproducible annotation pipeline are released.
Significance. If the judge-filtered annotations prove faithful to the underlying real-world trajectories, TrajPrism would offer a useful standardized resource for evaluating multimodal alignment in urban mobility, bridging geometry-centric trajectory modeling with language-based intent understanding. The multi-city scale, multi-task design, and emphasis on releasing a portable pipeline are strengths that could facilitate follow-on work.
major comments (2)
- [Benchmark Construction / Annotation Pipeline] The manuscript provides no quantitative validation of the judge-filtered annotations (e.g., inter-judge agreement rates, error rates on a re-annotated sample, or systematic mismatch analysis against the 300K trajectories). This is load-bearing for the central claim that geometry-only baselines leave a large gap, because noisy or inconsistent annotations under the four-dimensional taxonomy could artifactually inflate language-aware model performance while making geometry-only baselines appear deficient by construction.
- [Proof-of-Concept Models and Experiments] The description of the POC models and evaluation protocol supplies no concrete quantitative metrics, baseline implementation details, or error analysis supporting the claimed performance gap. Without these, it is not possible to assess the magnitude, statistical significance, or robustness of the reported differences between geometry-only and language-grounded approaches.
minor comments (1)
- [Introduction] The abstract and introduction could more explicitly define the four-dimensional travel-intent taxonomy (e.g., list the dimensions and their values) to improve readability for readers unfamiliar with the annotation scheme.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of benchmark validation and experimental transparency. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Benchmark Construction / Annotation Pipeline] The manuscript provides no quantitative validation of the judge-filtered annotations (e.g., inter-judge agreement rates, error rates on a re-annotated sample, or systematic mismatch analysis against the 300K trajectories). This is load-bearing for the central claim that geometry-only baselines leave a large gap, because noisy or inconsistent annotations under the four-dimensional taxonomy could artifactually inflate language-aware model performance while making geometry-only baselines appear deficient by construction.
Authors: We agree that the absence of quantitative annotation validation is a substantive gap in the current manuscript. The description of the judge-filtered process and four-dimensional taxonomy is provided, but no inter-judge agreement statistics, re-annotation error rates, or mismatch analysis appear in the text. In the revised version we will add a new subsection under Benchmark Construction that reports these metrics on a sampled subset of trajectories (e.g., Cohen’s kappa or raw agreement percentages across judges, error rates from independent re-annotation, and a breakdown of any systematic mismatches with the underlying GPS data). These statistics will be computed from the existing annotation logs and pipeline we release, directly supporting the reliability of the 2.1M task instances. revision: yes
-
Referee: [Proof-of-Concept Models and Experiments] The description of the POC models and evaluation protocol supplies no concrete quantitative metrics, baseline implementation details, or error analysis supporting the claimed performance gap. Without these, it is not possible to assess the magnitude, statistical significance, or robustness of the reported differences between geometry-only and language-grounded approaches.
Authors: We acknowledge that the experimental reporting in the manuscript is insufficiently detailed for independent assessment of the performance gaps. While the abstract and main text state that geometry-only baselines leave a large gap, the full quantitative tables, exact baseline implementations (architectures, hyperparameters, training details), statistical significance tests, and error analysis are not presented at the required level of concreteness. In the revision we will expand the Experiments section with complete per-task metric tables (including means, variances, and significance where appropriate), precise descriptions of all baselines and POC models (TrajAnchor, TrajFuse, TrajRap), and a dedicated error analysis subsection that examines representative failure cases for both geometry-only and language-grounded models. This will allow readers to evaluate the magnitude and robustness of the reported differences. revision: yes
Circularity Check
No circularity: benchmark built from external trajectories and annotations; claims rest on empirical protocol
full rationale
The paper constructs TrajPrism by pairing 300K real trajectories from Porto, San Francisco, and Beijing with judge-filtered language annotations under a four-dimensional taxonomy, yielding 2.1M task instances. It defines three tasks (instruction-conditioned generation, semantic retrieval, captioning) and instantiates them with proof-of-concept models (TrajAnchor, TrajFuse, TrajRap). The central claim—that geometry-only baselines leave a large gap—is an empirical comparison on the proposed protocol measuring fidelity, retrieval quality, and language groundedness. No equations, fitted parameters, or derivations are present that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The chain is self-contained against external real-world data and the newly defined evaluation protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four-dimensional travel-intent taxonomy adequately captures relevant aspects of urban travel for the purpose of creating language annotations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct TrajPrism by pairing real urban trajectories with judge-filtered language annotations generated under a four-dimensional travel-intent taxonomy... three tasks: instruction-conditioned trajectory generation, language-driven semantic trajectory retrieval, and trajectory captioning
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TrajAnchor... retrieval + constraint extraction + chain Dijkstra... TrajFuse fuses geometric and semantic representations... TrajRap retrieval-augmented captioning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
S. Banerjee and A. Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005
work page 2005
- [3]
- [4]
-
[5]
L. Chen, M. T. Özsu, and V . Oria. Robust and fast similarity search for moving object trajectories. InProceedings of the 2005 ACM SIGMOD international conference on Management of data, pages 491–502, 2005
work page 2005
-
[6]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
L. Gong, Y . Lin, X. Zhang, Y . Lu, X. Han, Y . Liu, S. Guo, Y . Lin, and H. Wan. Mobility-llm: Learning visiting intentions and travel preference from human mobility data with large language models.Advances in Neural Information Processing Systems, 37:36185–36217, 2024
work page 2024
- [8]
-
[9]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[10]
E. Keogh and C. A. Ratanamahatana. Exact indexing of dynamic time warping.Knowledge and information systems, 7(3):358–386, 2005
work page 2005
- [11]
-
[12]
L. Li, H. Xue, Y . Song, and F. Salim. T-jepa: A joint-embedding predictive architecture for trajectory similarity computation. InProceedings of the 32nd ACM international conference on advances in geographic information systems, pages 569–572, 2024
work page 2024
-
[13]
X. Li, K. Zhao, G. Cong, C. S. Jensen, and W. Wei. Deep representation learning for trajectory similarity computation. In2018 IEEE 34th international conference on data engineering (ICDE), pages 617–628. IEEE, 2018
work page 2018
-
[14]
Z. Li, L. Xia, J. Tang, Y . Xu, L. Shi, L. Xia, D. Yin, and C. Huang. Urbangpt: Spatio-temporal large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 5351–5362, 2024
work page 2024
-
[15]
C.-Y . Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
work page 2004
-
[16]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 11
work page 2014
-
[17]
Y . Lin, Z. Zhou, Y . Liu, H. Lv, H. Wen, T. Li, Y . Li, C. S. Jensen, S. Guo, Y . Lin, et al. Unite: A survey and unified pipeline for pre-training spatiotemporal trajectory embeddings.IEEE Transactions on Knowledge and Data Engineering, 37(3):1475–1494, 2024
work page 2024
-
[18]
Z. Ma, Z. Tu, X. Chen, Y . Zhang, D. Xia, G. Zhou, Y . Chen, Y . Zheng, and J. Gong. More than routing: Joint gps and route modeling for refine trajectory representation learning. In Proceedings of the ACM Web Conference 2024, pages 3064–3075, 2024
work page 2024
-
[19]
Z. Nussbaum, J. X. Morris, B. Duderstadt, and A. Mulyar. Nomic embed: Training a repro- ducible long context text embedder.arXiv preprint arXiv:2402.01613, 2024
-
[20]
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InProceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015
work page 2015
-
[21]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
- [22]
-
[23]
J. Wang, R. Jiang, C. Yang, Z. Wu, M. Onizuka, R. Shibasaki, N. Koshizuka, and C. Xiao. Large language models as urban residents: An llm agent framework for personal mobility generation. Advances in Neural Information Processing Systems, 37:124547–124574, 2024
work page 2024
- [24]
- [25]
- [26]
-
[27]
D. Xie, F. Li, and J. M. Phillips. Distributed trajectory similarity search.Proceedings of the VLDB Endowment, 10(11):1478–1489, 2017
work page 2017
- [28]
-
[29]
X. Yang, H. Ge, J. Wang, Z. Fan, R. Jiang, R. Shibasaki, and N. Koshizuka. Causalmob: Causal human mobility prediction with llms-derived human intentions toward public events. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 1773–1784, 2025
work page 2025
-
[30]
D. Yao, G. Cong, C. Zhang, and J. Bi. Computing trajectory similarity in linear time: A generic seed-guided neural metric learning approach. In2019 IEEE 35th international conference on data engineering (ICDE), pages 1358–1369. IEEE, 2019
work page 2019
-
[31]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[32]
E. Zhao, P. Awasthi, Z. Chen, S. Gollapudi, and D. Delling. Semantic routing via autoregressive modeling.Advances in Neural Information Processing Systems, 37:10060–10087, 2024
work page 2024
-
[33]
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
- [34]
- [35]
- [36]
-
[37]
Y . Zhu, J. J. Yu, X. Zhao, X. Zhou, L. Han, X. Wei, and Y . Liang. Unitraj: Learning a universal trajectory foundation model from billion-scale worldwide traces.arXiv preprint arXiv:2411.03859, 2024. 13 A Appendix A.1 Evaluation Metrics We provide formal definitions of all evaluation metrics used in TrajPrism. A.1.1 Task 1: Navigation Instruction Followi...
-
[38]
Destination 1.1 Exact Anchor Specific physical destination (POI or road name) 1.2 Fuzzy Semantic Conceptual destination (e.g. “a quiet green area”)
-
[39]
Waypoint 2.1 Strict Sequential Must pass through specific named road segments 2.2 Flexible / Feature Stop described by semantic features only 2.3 Pass-through Zone Cross an area type without stopping
-
[40]
Route Pref. 3.1 Semantic Constraints Affinity or avoidance (e.g. parks, industrial zones) 3.2 Topological / Direct. Fluency, permeability, or directional preference 3.3 Orthogonal Comp. Semantic vs. topology (e.g. “through chaos but main road”)
-
[41]
drive to the station, stop for fuel on the way, and avoid the highway
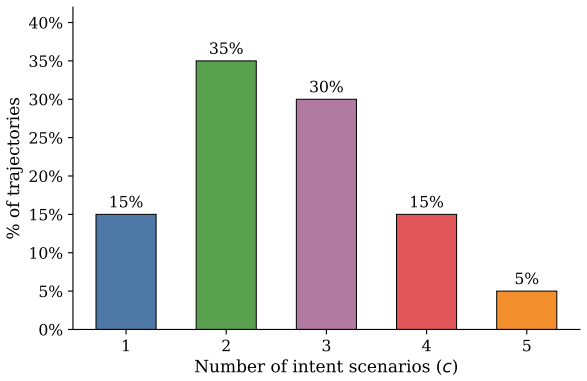
Temporal/Pace 4.1 Time-of-Day Route choice driven by time or day of week 4.2 Pace / Duration Urgency, leisure, or deadline-driven constraints the remaining scenarios from Dimensions 2–4, producing realistic multi-constraint requests such as “drive to the station, stop for fuel on the way, and avoid the highway”. Figure 12 shows the resulting distribution ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.