Recognition: no theorem link
PathISE: Learning Informative Path Supervision for Knowledge Graph Question Answering
Pith reviewed 2026-05-12 04:33 UTC · model grok-4.3
The pith
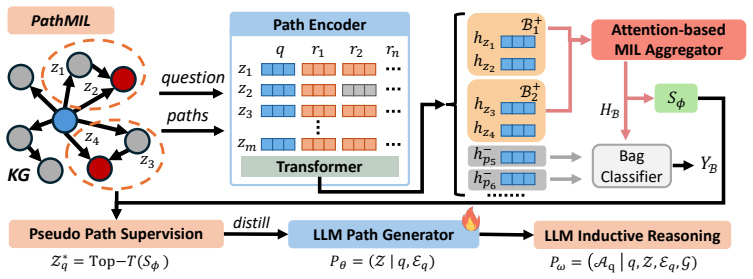
PathISE derives high-quality path supervision for KGQA directly from answer labels by estimating relation-path informativeness with a lightweight transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PathISE introduces a lightweight transformer-based estimator that evaluates the informativeness of relation paths to create pseudo path-level supervision from answer-level labels alone; this supervision is distilled into an LLM path generator whose outputs are grounded in the knowledge graph to support inductive answer reasoning.
What carries the argument
The lightweight transformer-based estimator that scores relation-path informativeness to build pseudo path-level supervision for distillation into an LLM path generator.
If this is right
- KGQA training no longer requires costly manual or LLM-refined path annotations.
- The generated pseudo paths can be reused to improve other existing KGQA models.
- LLM reasoning is grounded in compact, question-relevant graph evidence rather than raw retrieval.
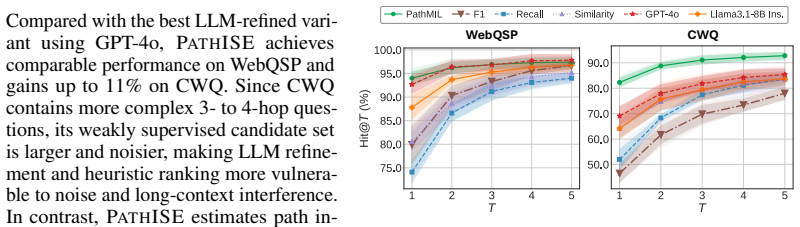
- Performance remains competitive or state-of-the-art across three standard benchmarks.
Where Pith is reading between the lines
- The same estimator could be applied to other structured-reasoning tasks that currently lack intermediate labels.
- Scaling the estimator to larger transformers might further tighten the quality gap to human-annotated paths.
- The reusable supervision signals open the possibility of iterative self-improvement loops in KGQA pipelines.
Load-bearing premise
The lightweight transformer can accurately judge which relation paths are informative enough to produce useful pseudo supervision when only final-answer correctness is known.
What would settle it
A direct comparison on a held-out KGQA benchmark showing whether the distilled LLM path generator produces paths that measurably raise answer accuracy relative to an identical LLM given the same questions but no path supervision.
Figures





read the original abstract
Knowledge Graph Question Answering (KGQA) aims to answer user questions by reasoning over Knowledge Graphs (KGs). Recent KGQA methods mainly follow the retrieval-augmented generation paradigm to ground Large Language Models~(LLMs) with structured knowledge from KGs. However, training effective models to retrieve question-relevant evidence from KGs typically requires high-quality intermediate supervision signals, such as question-relevant paths or subgraphs, which are time- and resource-intensive to obtain. We propose PathISE, a novel framework for learning high-quality intermediate supervision from answer-level labels. PathISE introduces a lightweight transformer-based estimator that estimates the informativeness of relation paths to construct pseudo path-level supervision. This supervision is then distilled into an LLM path generator, whose generated paths are grounded in the KG to provide compact evidence for inductive answer reasoning. ExtensiveISE experiments on three KGQA benchmarks show that PathISE achieves competitive or state-of-the-art KGQA performance, and provides reusable supervision signals that can enhance existing KGQA models, without relying on costly LLM-refined supervision signals. Our source code is available at https://anonymous.4open.science/r/PathISE-2F87.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PathISE, a framework for Knowledge Graph Question Answering (KGQA) that learns high-quality intermediate supervision from answer-level labels. It introduces a lightweight transformer-based estimator to score the informativeness of relation paths and construct pseudo path-level supervision, which is then distilled into an LLM path generator. The generated paths are grounded in the KG to provide compact evidence for inductive answer reasoning. Experiments on three KGQA benchmarks are reported to achieve competitive or state-of-the-art performance, with the learned supervision signals shown to be reusable for enhancing existing KGQA models without relying on costly LLM-refined supervision. Source code is provided.
Significance. If the central claims hold, this work addresses a key bottleneck in retrieval-augmented KGQA by deriving reusable path-level supervision from inexpensive answer labels via a lightweight estimator and distillation. This could improve scalability of KGQA systems and provide a general template for obtaining intermediate signals in structured reasoning tasks. The open-source code is a clear strength for reproducibility.
major comments (1)
- [§4 (Experiments)] §4 (Experiments): The abstract claims competitive or SOTA results on three benchmarks, but the manuscript provides insufficient detail on baselines, ablation studies (e.g., isolating the estimator's contribution), statistical significance tests, and full hyperparameter settings. This weakens verification of the central performance claim and the assertion that the estimator produces high-quality pseudo-supervision.
minor comments (2)
- [Abstract] Abstract: 'ExtensiveISE experiments' is a typographical error and should read 'Extensive experiments'.
- [Abstract] Abstract: The statement that supervision signals 'can enhance existing KGQA models' should reference specific quantitative results or tables from the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental section. We address the major comment below and will incorporate the suggested enhancements in the revised manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): The abstract claims competitive or SOTA results on three benchmarks, but the manuscript provides insufficient detail on baselines, ablation studies (e.g., isolating the estimator's contribution), statistical significance tests, and full hyperparameter settings. This weakens verification of the central performance claim and the assertion that the estimator produces high-quality pseudo-supervision.
Authors: We agree that §4 would benefit from greater detail to support verification. In the revision we will: (1) expand the baselines table to list all compared methods with citations, brief descriptions, and implementation notes; (2) add ablation experiments that isolate the transformer estimator (e.g., PathISE without the estimator vs. full model, and variants using random or heuristic paths); (3) report statistical significance via paired t-tests or bootstrap confidence intervals over multiple random seeds; and (4) move all hyperparameter values, training schedules, and model dimensions to a new appendix subsection. These additions will directly substantiate both the performance claims and the quality of the learned pseudo-supervision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a standard semi-supervised pipeline in which answer-level labels are used to train a lightweight transformer estimator that produces pseudo path-level supervision signals; these signals are then distilled into an LLM path generator. No equation or step reduces a claimed prediction to a fitted quantity by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled in. The central claim (competitive KGQA performance via reusable pseudo-supervision) remains independent of the inputs and does not collapse into a renaming or self-definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- informativeness scoring threshold
axioms (1)
- domain assumption Relation paths can be scored for informativeness to the answer using only final answer supervision
Reference graph
Works this paper leans on
-
[1]
K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor. Freebase: A collaboratively created graph database for structuring human knowledge. InSIGMOD, pages 1247–1250, 2008
work page 2008
-
[2]
L. Chen, P. Tong, Z. Jin, Y . Sun, J. Ye, and H. Xiong. Plan-on-graph: Self-correcting adaptive planning of large language model on knowledge graphs.NeurIPS, pages 37665–37691, 2024
work page 2024
-
[3]
H. K. Choi, S. Lee, J. Chu, and H. J. Kim. NuTrea: Neural tree search for context-guided multi-hop KGQA. InNeurIPS, pages 35954–35965, 2023
work page 2023
-
[4]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
S. Fang, K. Ma, T. Zheng, X. Du, N. Lu, G. Zhang, and Q. Tang. KARPA: A training-free method of adapting knowledge graph as references for large language model’s reasoning path aggregation. InACL, page 24724–24746, 2024
work page 2024
- [7]
-
[8]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Y . Gu, S. Kase, M. Vanni, B. Sadler, P. Liang, X. Yan, and Y . Su. Beyond I.I.D.: Three levels of generalization for question answering on knowledge bases. InWWW, pages 3477–3488, 2021
work page 2021
- [10]
-
[11]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
work page 2022
-
[12]
M. Ilse, J. Tomczak, and M. Welling. Attention-based deep multiple instance learning. InICML, pages 2127–2136, 2018
work page 2018
-
[13]
J. Jang and H.-Y . Kwon. Are multiple instance learning algorithms learnable for instances? InNeurIPS, pages 10575–10612, 2024
work page 2024
- [14]
- [15]
-
[16]
Y . Lan, G. He, J. Jiang, J. Jiang, W. X. Zhao, and J.-R. Wen. Complex knowledge base question answering: A survey.IEEE Transactions on Knowledge and Data Engineering, 35(11):11196–11215, 2023
work page 2023
-
[17]
C. Lei, Y . Chang, N. Lipovetzky, and K. A. Ehinger. Planning-driven programming: A large language model programming workflow. InACL, pages 12647–12684, 2025
work page 2025
- [18]
-
[19]
M. Li, S. Miao, and P. Li. Simple is effective: The roles of graphs and large language models in knowledge-graph- based retrieval-augmented generation. InICLR, 2025
work page 2025
-
[20]
T. Li, X. Ma, A. Zhuang, Y . Gu, Y . Su, and W. Chen. Few-shot in-context learning for knowledge base question answering. InACL, pages 6966–6980, 2023
work page 2023
-
[21]
Z. Li, X. Zhang, Y . Zhang, D. Long, P. Xie, and M. Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Z. Li, S. Fan, Y . Gu, X. Li, Z. Duan, B. Dong, N. Liu, and J. Wang. FlexKBQA: A flexible LLM-powered framework for few-shot knowledge base question answering. InAAAI, pages 18608–18616, 2024
work page 2024
-
[23]
H. Luo, H. E, Y . Guo, Q. Lin, X. Wu, X. Mu, W. Liu, M. Song, Y . Zhu, and L. A. Tuan. KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search. InICML, 2025
work page 2025
-
[24]
L. Luo, Y .-F. Li, G. Haffari, and S. Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning. InICLR, 2024
work page 2024
-
[25]
L. Luo, Z. Zhao, C. Gong, G. Haffari, and S. Pan. Graph-constrained reasoning: Faithful reasoning on knowledge graphs with large language models. InICML, 2025
work page 2025
-
[26]
J. Ma, Z. Gao, Q. Chai, W. Sun, P. Wang, H. Pei, J. Tao, L. Song, J. Liu, C. Zhang, et al. Debate on graph: A flexible and reliable reasoning framework for large language models. InAAAI, pages 24768–24776, 2025
work page 2025
-
[27]
J. Ma, N. Qu, Z. Gao, R. Xing, J. Liu, H. Pei, J. Xie, L. Song, P. Wang, J. Tao, and Z. Su. Deliberation on priors: Trustworthy reasoning of large language models on knowledge graphs. InNeurIPS, 2025
work page 2025
-
[28]
C. Mavromatis and G. Karypis. ReaRev: Adaptive reasoning for question answering over knowledge graphs. InFindings of EMNLP, pages 2447–2458, 2022
work page 2022
-
[29]
C. Mavromatis and G. Karypis. GNN-RAG: Graph neural retrieval for efficient large language model reasoning on knowledge graphs. InACL, pages 16682–16699, 2025
work page 2025
-
[30]
Gemini: A Family of Highly Capable Multimodal Models
OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V . Balcom, P. Baltescu, H. Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bogdonoff, O. Boiko, M. Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M. Brunda...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
S. Pan, L. Luo, Y . Wang, C. Chen, J. Wang, and X. Wu. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36(7):3580–3599, 2024
work page 2024
- [32]
-
[33]
Y . Sui, Y . He, N. Liu, X. He, K. Wang, and B. Hooi. FiDeLiS: Faithful reasoning in large language model for knowledge graph question answering. InACL, 2025
work page 2025
-
[34]
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y . Gong, L. M. Ni, H.-Y . Shum, and J. Guo. Think-on-Graph: Deep and responsible reasoning of large language model on knowledge graph. InICLR, 2024
work page 2024
-
[35]
A. Talmor and J. Berant. The web as a knowledge-base for answering complex questions. InNAACL, pages 641–651, 2018
work page 2018
-
[36]
D. Vrandeˇci´c and M. Krötzsch. Wikidata: A free collaborative knowledgebase.Communications of the ACM, 57:78–85, 2014
work page 2014
-
[37]
KG-Hopper: Empowering Compact Open LLMs with Knowledge Graph Reasoning via Reinforcement Learning
S. Wang and Y . Yu. KG-Hopper: Empowering compact open LLMs with knowledge graph reasoning via reinforcement learning.arXiv preprint arXiv:2603.21440, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
S. Wang, W. Fan, Y . Feng, L. Shanru, X. Ma, S. Wang, and D. Yin. Knowledge graph retrieval-augmented generation for LLM-based recommendation. InACL, pages 27152–27168, 2025
work page 2025
-
[39]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InICLR, 2023
work page 2023
-
[40]
Y . Wang, S. Fan, M. Wang, S. Gao, C. Wang, and N. Yin. Damr: Efficient and adaptive context-aware knowledge graph question answering with llm-guided mcts. InICLR, 2025
work page 2025
-
[41]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain- of-Thought prompting elicits reasoning in large language models. InNeurIPS, pages 24824–24837, 2023
work page 2023
-
[42]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InEMNLP, pages 2369–2380, 2018. 11
work page 2018
- [44]
-
[45]
W.-t. Yih, M. Richardson, C. Meek, M.-W. Chang, and J. Suh. The value of semantic parse labeling for knowledge base question answering. InACL, pages 201–206, 2016
work page 2016
-
[46]
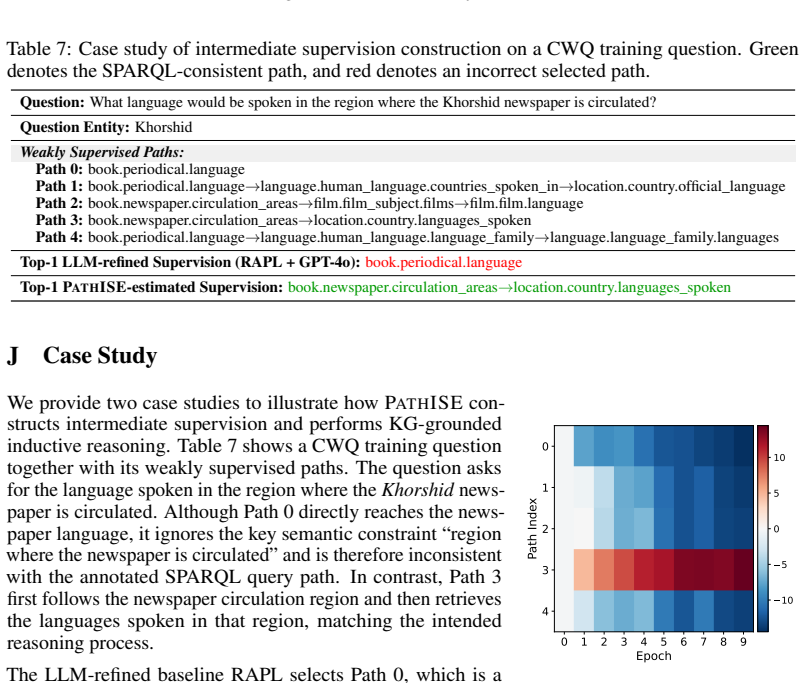
region where the newspaper is circulated
D. Zou, Y . Chen, M. Li, S. Miao, C. Liu, B. Han, J. Cheng, and P. Li. Weak-to-strong GraphRAG: Aligning weak retrievers with large language models for graph-based retrieval augmented generation.arXiv preprint arXiv:2506.22518, 2025. A Relation Path Example We provide an illustrative example on how a relation path is grounded over a KG. Consider a relatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.