Recognition: no theorem link
Algorithmic Advantage on a Gate-Based Photonic Quantum Neural Network
Pith reviewed 2026-05-12 04:25 UTC · model grok-4.3
The pith
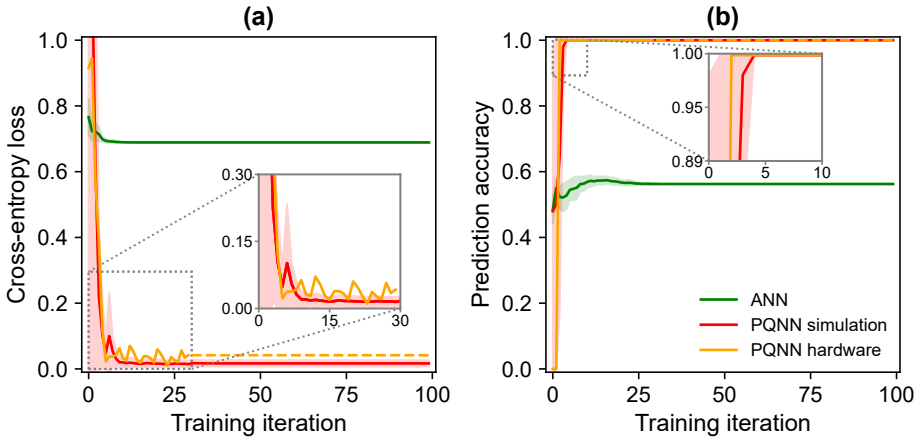
A photonic quantum neural network with only two trainable parameters solves classification tasks that classical networks with at least four times as many parameters cannot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
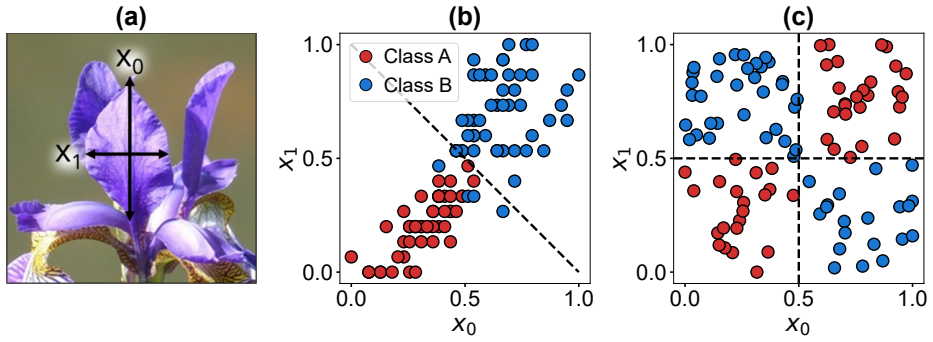
A gate-based variational quantum classifier realized with single photons and probabilistic gates exhibits superior converged cross-entropy loss and prediction accuracy relative to classical ANNs of equivalent trainable-parameter count. On a nonlinear task the two-parameter photonic QNN reaches loss 0.04 and 100 percent accuracy while the matched ANN saturates at random-guessing performance; circuits with higher effective dimension achieve up to 100 percent accuracy when deployed on photonic hardware, establishing proof of algorithmic advantage for gate-based photonic QNNs.
What carries the argument
Effective dimension, the capacity measure derived from a proven generalization-error bound that quantifies the expressive power of the variational quantum circuit relative to classical networks of equal parameter count.
If this is right
- Photonic QNNs trained with gradient-free optimization converge to lower loss than matched classical networks even under realistic noise including photon loss and phase-shifter errors.
- Deployment on a six-qubit photonic processor yields classification accuracies up to 100 percent in both online and offline learning settings.
- The performance edge holds across both photonic and superconducting QNN realizations when compared to parameter-matched ANNs.
- Minimal circuits with high effective dimension successfully handle tasks that require classical networks with at least quadruple the parameters.
Where Pith is reading between the lines
- If the parameter efficiency generalizes, quantum neural networks could enable accurate machine learning models on devices with severely limited classical compute or memory.
- Applying the same effective-dimension comparison to multi-class or regression problems would clarify whether the observed advantage extends beyond binary classification.
- Combining hardware experiments with effective-dimension calculations offers a concrete protocol for selecting quantum circuit architectures before large-scale deployment.
- The tolerance to sampling errors and photonic noise suggests these models may remain trainable even as circuit depth increases on near-term processors.
Load-bearing premise
The effective dimension computed from the circuit accurately predicts generalization performance and the classical ANN baselines are optimized and parameterized in a directly comparable way.
What would settle it
Training a classical ANN with four or fewer parameters on the XOR task using the same gradient-free optimizer and observing that it reaches comparable loss and accuracy to the two-parameter photonic QNN would falsify the claimed advantage.
Figures




read the original abstract
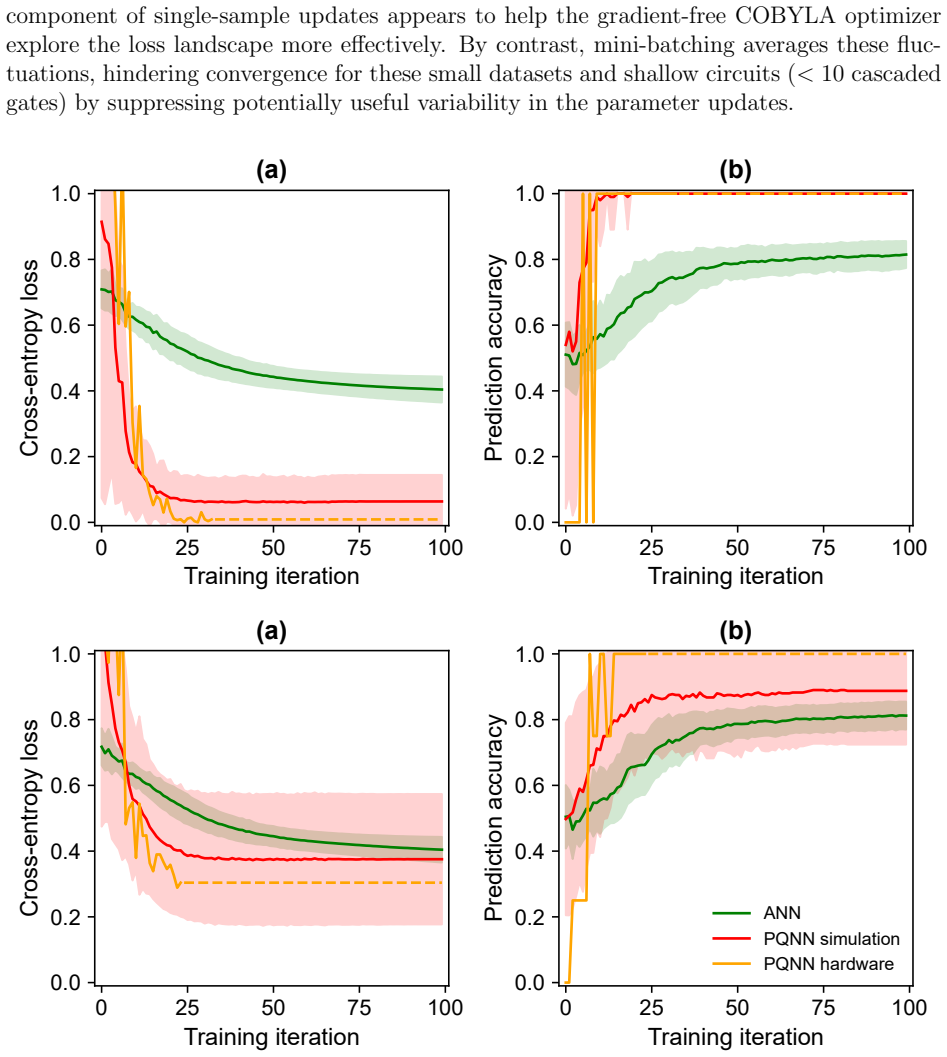
We report on a gate-based variational quantum classifier implemented with single photons and probabilistic gates, to emulate the standard quantum circuit model framework. We evaluate the expressive power of two deployable quantum neural networks (QNNs) by computing their effective dimension, a capacity measure grounded in a proven generalization-error bound, and compare them with classical artificial neural networks (ANNs) of equivalent trainable-parameter count. Supervised binary classification tasks are used to benchmark performance across photonic and superconducting QNNs, both of which exhibit superior converged (lower) cross-entropy loss and (higher) prediction accuracy relative to matched-parameter ANNs. For a nonlinearly separable task, our photonic QNN with a single pair of trainable parameters successfully converged (loss 0.04 and accuracy 100%), whereas the equivalent ANN failed to learn the decision boundary, saturating at random-guessing performance. We simulate photonic quantum circuits, training them on the XOR problem and a two-class Iris subset using gradient-free optimization, and assess their robustness to sampling errors under realistic noise processes including photon loss and phase-shifter imperfections. Circuits with comparatively high effective dimension were deployed remotely on a six-qubit photonic quantum processor, achieving classification accuracies of up to 100% in both online and offline learning settings. Notably, even the simplest QNN deployed, with just two trainable parameters, successfully solved tasks that classically require ANNs with at least quadruple the number of parameters, suggesting an emergent algorithmic advantage. Overall, these results demonstrate a clear proof-of-principle that gate-based QNNs can be realized and trained effectively on current photonic hardware, providing proof of algorithmic advantage on a gate-based photonic QNN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a gate-based variational quantum classifier realized with single photons and probabilistic gates to emulate the quantum circuit model. It computes the effective dimension of two QNN architectures as a capacity measure grounded in a generalization-error bound, benchmarks them on supervised binary classification tasks (XOR and a two-class Iris subset) against classical ANNs of matched trainable-parameter count, and reports superior converged loss and accuracy for the QNNs. A 2-parameter photonic QNN is shown to reach loss 0.04 and 100% accuracy on nonlinear tasks where the matched ANN saturates at random-guessing performance; circuits are simulated under photon loss and phase noise, then deployed on a six-qubit photonic processor in both online and offline settings.
Significance. If the classical baselines are shown to be fairly parameterized and optimized, the work would supply concrete evidence of an emergent algorithmic advantage for small photonic QNNs on current hardware, together with a practical demonstration of remote deployment and noise robustness. The use of effective dimension tied to an external generalization bound is a methodological strength that could be adopted more widely.
major comments (3)
- [Results (performance comparisons)] Results section (performance comparisons): the claim that the 2-parameter QNN succeeds where an 'equivalent' ANN fails is load-bearing for the algorithmic-advantage conclusion, yet the manuscript supplies no description of the ANN architecture (number of layers, neurons per layer, activation functions, inclusion of biases) or training protocol (optimizer, learning-rate schedule, initialization). Without these details it is impossible to confirm that the parameter count is matched on an apples-to-apples basis or that the classical model was not disadvantaged by an inappropriate choice of model class or optimizer.
- [Abstract and Results] Abstract and Results: reported convergence to loss 0.04 and 100% accuracy for the 2-parameter QNN is presented without error bars, number of independent runs, or full optimization hyperparameters (e.g., number of function evaluations for the gradient-free optimizer, convergence tolerance). This omission prevents assessment of statistical reliability and reproducibility of the headline performance gap.
- [Methods (effective-dimension calculation)] Methods (effective-dimension calculation): while the metric is stated to rest on a proven generalization bound, the manuscript does not show the explicit formula or numerical procedure used to obtain the effective dimension from the photonic circuit parameters, nor does it verify that the bound remains valid under the probabilistic-gate and photon-loss model employed.
minor comments (2)
- [Figures and Results] Figure captions and text should explicitly state the number of shots or samples used for each accuracy and loss value to allow direct comparison with the noise-robustness analysis.
- [Notation] Notation for the trainable parameters (phase shifts) should be introduced once in the Methods and used consistently; currently the abstract and main text alternate between 'pair of trainable parameters' and 'two trainable parameters' without a defining equation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments identify important omissions that we will address to strengthen the clarity and reproducibility of the results. We respond point by point below.
read point-by-point responses
-
Referee: [Results (performance comparisons)] Results section (performance comparisons): the claim that the 2-parameter QNN succeeds where an 'equivalent' ANN fails is load-bearing for the algorithmic-advantage conclusion, yet the manuscript supplies no description of the ANN architecture (number of layers, neurons per layer, activation functions, inclusion of biases) or training protocol (optimizer, learning-rate schedule, initialization). Without these details it is impossible to confirm that the parameter count is matched on an apples-to-apples basis or that the classical model was not disadvantaged by an inappropriate choice of model class or optimizer.
Authors: We agree that the manuscript lacks sufficient detail on the classical baselines. In the revised manuscript we will expand the Methods section with a complete specification of the ANN architecture (number of layers, neurons per layer, activation functions, and bias terms) together with the full training protocol (optimizer, learning-rate schedule, and initialization). These additions will allow direct verification that the trainable-parameter counts are matched and that the classical models were trained under standard, fair conditions, thereby supporting the reported performance gap. revision: yes
-
Referee: [Abstract and Results] Abstract and Results: reported convergence to loss 0.04 and 100% accuracy for the 2-parameter QNN is presented without error bars, number of independent runs, or full optimization hyperparameters (e.g., number of function evaluations for the gradient-free optimizer, convergence tolerance). This omission prevents assessment of statistical reliability and reproducibility of the headline performance gap.
Authors: We acknowledge the need for statistical context. The revised manuscript will report error bars (standard deviation across independent runs), the number of independent optimization runs, and the complete set of optimization hyperparameters, including the number of function evaluations and convergence tolerance for the gradient-free optimizer. These additions will enable readers to evaluate the reliability and reproducibility of the observed performance difference. revision: yes
-
Referee: [Methods (effective-dimension calculation)] Methods (effective-dimension calculation): while the metric is stated to rest on a proven generalization bound, the manuscript does not show the explicit formula or numerical procedure used to obtain the effective dimension from the photonic circuit parameters, nor does it verify that the bound remains valid under the probabilistic-gate and photon-loss model employed.
Authors: We will include the explicit formula for the effective dimension and a step-by-step description of the numerical procedure applied to the circuit parameters. Regarding validity under probabilistic gates and photon loss, we will add a clarifying paragraph noting that the bound applies to the effective parameterized model and that noise is accounted for separately in the simulations; we will also provide a brief robustness check confirming that the capacity ordering remains consistent under the modeled noise. revision: yes
Circularity Check
No load-bearing circularity; effective dimension grounded externally and advantage shown via independent empirical comparisons
full rationale
The paper's central claims rest on computing effective dimension as a capacity measure from a proven external generalization-error bound, followed by direct supervised training and performance benchmarking of the photonic QNN against classical ANNs with matched trainable-parameter counts. The reported success of the 2-parameter QNN on XOR and Iris tasks (where the matched ANN saturates at random guessing) is an observed empirical outcome rather than a quantity derived by construction from fitted inputs or self-citations. No derivation step equates a prediction to its own training data or renames an ansatz via internal citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abiodun, O. I.et al.Comprehensive Review of Artificial Neural Network Applica- tions to Pattern Recognition.IEEE Access7, 158820–158846 (2019). URLhttps: //ieeexplore.ieee.org/abstract/document/8859190
-
[2]
M.et al.Deep learning applications and challenges in big data analytics
Najafabadi, M. M.et al.Deep learning applications and challenges in big data analytics. Journal of Big Data2, 1 (2015). URLhttps://doi.org/10.1186/s40537-014-0007-7. 12
-
[3]
M.et al.Identification of short-range ordering motifs in semiconductors.Science389, 1342–1346 (2025)
Huang, H.-Y.et al.Quantum advantage in learning from experiments.Science376, 1182–1186 (2022). URLhttps://www.science.org/doi/full/10.1126/science. abn7293
-
[4]
Liu, Y., Arunachalam, S. & Temme, K. A rigorous and robust quantum speed-up in supervised machine learning.Nature Physics17, 1013–1017 (2021). URLhttps: //www.nature.com/articles/s41567-021-01287-z
work page 2021
-
[5]
Mosca, M. & Piani, M. Quantum Threat Timeline Re- port 2024 (2024). URLhttps://globalriskinstitute. org/publication/2024-quantum-threat-timeline-report/. Https://globalriskinstitute.org/publication/2024-quantum-threat-timeline-report/
work page 2024
-
[6]
Nature Photonics18, 603–609 (2024)
Maring, N.et al.A versatile single-photon-based quantum computing platform. Nature Photonics18, 603–609 (2024). URLhttps://www.nature.com/articles/ s41566-024-01403-4
work page 2024
-
[7]
URLhttps://www.nature.com/articles/s43588-021-00084-1
Abbas, A.et al.The power of quantum neural networks.Nature Computational Science 1, 403–409 (2021). URLhttps://www.nature.com/articles/s43588-021-00084-1
work page 2021
- [8]
-
[9]
URLhttp://jmlr.org/papers/v12/ pedregosa11a.html
Pedregosa, F.et al.Scikit-learn: Machine Learning in Python.Journal of Ma- chine Learning Research12, 2825–2830 (2011). URLhttp://jmlr.org/papers/v12/ pedregosa11a.html
work page 2011
-
[10]
Knill, E., Laflamme, R. & Milburn, G. J. A scheme for efficient quantum computa- tion with linear optics.Nature409, 46–52 (2001). URLhttps://www.nature.com/ articles/35051009
-
[11]
Schuld, M., Bocharov, A., Svore, K. M. & Wiebe, N. Circuit-centric quantum classifiers. Physical Review A101, 032308 (2020). URLhttps://link.aps.org/doi/10.1103/ PhysRevA.101.032308
work page 2020
-
[12]
Nature Communications5, 4213 (2014)
Peruzzo, A.et al.A variational eigenvalue solver on a photonic quantum processor. Nature Communications5, 4213 (2014). URLhttps://www.nature.com/articles/ ncomms5213
work page 2014
-
[13]
Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization (2017). URL http://arxiv.org/abs/1412.6980. ArXiv:1412.6980 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Powell, M. J. D. A Direct Search Optimization Method That Models the Objective and Constraint Functions by Linear Interpolation. In Gomez, S. & Hennart, J.-P. (eds.) Advances in Optimization and Numerical Analysis, 51–67 (Springer Netherlands, Dor- drecht, 1994). URLhttps://doi.org/10.1007/978-94-015-8330-5_4. 13
-
[15]
Pellow-Jarman, A., Sinayskiy, I., Pillay, A. & Petruccione, F. A comparison of vari- ous classical optimizers for a variational quantum linear solver.Quantum Information Processing20, 202 (2021). URLhttps://doi.org/10.1007/s11128-021-03140-x
-
[16]
Krzywinski, M. & Altman, N. Error bars.Nature Methods10, 921–922 (2013). URL https://www.nature.com/articles/nmeth.2659
work page 2013
-
[17]
Masters, D. & Luschi, C. Revisiting Small Batch Training for Deep Neural Networks (2018). URLhttps://arxiv.org/abs/1804.07612v1
-
[18]
Liu, C.-Y., Yang, C.-H. H., Goan, H.-S. & Hsieh, M.-H. A Quantum Circuit-Based Compression Perspective for Parameter-Efficient Learning (2025). URLhttp://arxiv. org/abs/2410.09846. ArXiv:2410.09846 [quant-ph]
-
[19]
Amer, H., Piliouras, E., Barnes, E. & Economou, S. E. Implementing and benchmark- ing dynamically corrected gates on superconducting devices using space curve quantum control (2025). URLhttps://arxiv.org/abs/2504.09767v1
-
[20]
Quandela to launch Belenos, the world’s most powerful photonic quantum computer (2025)
Quandela. Quandela to launch Belenos, the world’s most powerful photonic quantum computer (2025). URLhttps://www.quandela.com/newsroom-posts/ belenos-the-worlds-most-powerful-photonic-quantum-computer-launched-by-quandela/
work page 2025
-
[21]
Raussendorf, R., Browne, D. E. & Briegel, H. J. Measurement-based quantum com- putation on cluster states.Physical Review A68, 022312 (2003). URLhttps: //link.aps.org/doi/10.1103/PhysRevA.68.022312
-
[22]
URLhttps://www.nature.com/articles/s41467-023-36493-1
Bartolucci, S.et al.Fusion-based quantum computation.Nature Communications14, 912 (2023). URLhttps://www.nature.com/articles/s41467-023-36493-1. 14
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.