Recognition: no theorem link
Large Spectrum Models (LSMs): Decoder-Only Transformer-Powered Spectrum Activity Forecasting via Tokenized RF Data
Pith reviewed 2026-05-12 04:01 UTC · model grok-4.3
The pith
Decoder-only transformers forecast spectrum activity across 33 bands with RMSE of 3.25 dB after tokenizing raw RF measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Foundational large spectrum models (LSMs) are created by applying a custom RF tokenizer to raw spectrum measurements and then training decoder-only transformers on the resulting sequences; across 33 bands the strongest model reaches 3.25 dB RMSE with 97 percent of predictions under 5 dB mean absolute error, and fine-tuning on data from different locations keeps RMSE below 3.7 dB.
What carries the argument
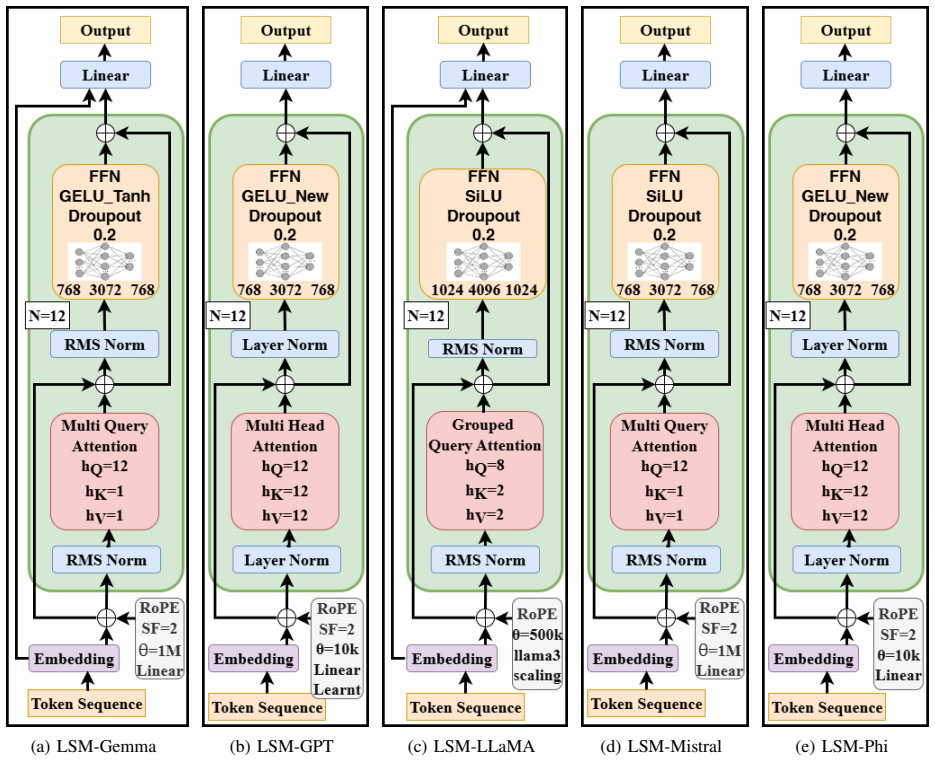
The RF tokenizer that converts each power-spectral-density value into a vocabulary token while attaching embeddings for gain, frequency, FFT bin index, and timestamp.
If this is right
- Accurate short-term forecasts become available for dynamic spectrum access decisions without hand-crafted features.
- Fine-tuning on modest new-location data suffices to maintain performance below 3.7 dB RMSE.
- Decoder-only architectures scale to spectrum forecasting once data volume reaches billions of tokens.
- A single trained model can cover dozens of bands simultaneously.
- The same pipeline can ingest additional bands or longer traces to enlarge the training corpus.
Where Pith is reading between the lines
- The same tokenization step could be reused for related RF tasks such as interference classification or modulation identification.
- Real-time deployment would require streaming tokenization and low-latency inference to support live channel allocation.
- Extending the vocabulary or embedding scheme might allow joint modeling of multiple radio parameters beyond power alone.
Load-bearing premise
The tokenizer must preserve the temporal and frequency structure of the original RF signals so that transformer attention can learn useful forecasting patterns.
What would settle it
Record fresh spectrum traces at a new outdoor site, fine-tune one of the published LSM checkpoints on a small subset, and check whether the resulting RMSE on the remaining traces exceeds 4 dB.
Figures






read the original abstract
Dynamic spectrum access (DSA) has become a key pillar of next-generation wireless systems to address the spectrum scarcity due to the rapid growth of connected devices. Accurate short-term spectrum forecasting is critical for DSA, where data-driven approaches have proven most effective. Recent advances in and widespread adoption of large language model (LLM) architectures present new opportunities for spectrum prediction. In this paper, foundational large spectrum models (LSMs) are presented. A novel RF tokenizer is introduced to convert raw IQ measurements into token sequences by mapping each power-spectral density value to a fixed vocabulary along with embedding gain, frequency, FFT bin, and timestamp information. Five established open-source LLM architectures (Gemma-2B, GPT-2, LLaMA-7B, Mistral-7B, and Phi-1) are trained on this tokenized spectrum data for the task of spectrum forecasting, yielding LSMs. To leverage the scaling gains of LSMs, a fully automated outdoor wireless testbed is employed to collect over 22 TB of raw spectrum data across 33 sub-GHz frequency bands, yielding 8.4B tokens in total. Across all 33 bands, the best model (LSM-Mistral) achieves a root-mean-square error of 3.25 dB and 97% of predictions have a mean absolute error below 5 dB. Generalization of LSMs is illustrated by fine-tuning the models on data collected in different locations, where RMSE is maintained below 3.7 dB. These results demonstrate that widespread decoder-only transformer architectures can serve as effective predictive models for large-scale RF spectrum forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Large Spectrum Models (LSMs) by adapting decoder-only transformer architectures (Gemma-2B, GPT-2, LLaMA-7B, Mistral-7B, Phi-1) to short-term RF spectrum forecasting. A novel RF tokenizer converts raw IQ-derived power spectral density (PSD) values into discrete token sequences augmented with embeddings for gain, frequency, FFT bin index, and timestamp. Models are trained on a 22 TB dataset spanning 33 sub-GHz bands (8.4 B tokens) collected via an automated outdoor testbed. The best model (LSM-Mistral) reports 3.25 dB RMSE across all bands with 97 % of predictions having MAE below 5 dB; fine-tuning on data from new locations maintains RMSE below 3.7 dB, demonstrating generalization for dynamic spectrum access applications.
Significance. If the empirical results hold after proper validation, the work shows that scaling decoder-only transformers to tokenized RF data can yield practically useful forecasting accuracy on a large, real-world spectrum corpus. The scale of data collection (22 TB, 33 bands) and the direct reuse of open-source LLM backbones are concrete strengths that could accelerate data-driven DSA techniques, provided the tokenizer and training pipeline are shown to be robust.
major comments (2)
- [Abstract] Abstract: The headline metrics (3.25 dB RMSE for LSM-Mistral, 97 % of predictions with MAE < 5 dB) are presented without any baseline comparisons (e.g., LSTM, GRU, or ARIMA on raw or tokenized PSD), training hyperparameters, validation-split details, or statistical significance tests. This omission is load-bearing for the central claim that decoder-only transformers are effective predictive models, because it leaves open whether the reported error stems from the LSM architecture, the tokenizer, or simply the statistics of the collected testbed data.
- [Abstract] RF tokenizer description (implied in Abstract and methods): The tokenizer maps continuous PSD bins to a fixed vocabulary and augments them with discrete embeddings for frequency, timestamp, gain, and FFT index. No ablation is reported that isolates the contribution of these embeddings or compares the tokenized discrete model against a continuous-valued forecaster (e.g., LSTM directly on PSD values). Without such controls, it remains unclear whether the discretization step preserves the local spectral continuity and short-term temporal correlations required for reliable forecasting, which is the weakest link in the generalization argument.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline metrics (3.25 dB RMSE for LSM-Mistral, 97 % of predictions with MAE < 5 dB) are presented without any baseline comparisons (e.g., LSTM, GRU, or ARIMA on raw or tokenized PSD), training hyperparameters, validation-split details, or statistical significance tests. This omission is load-bearing for the central claim that decoder-only transformers are effective predictive models, because it leaves open whether the reported error stems from the LSM architecture, the tokenizer, or simply the statistics of the collected testbed data.
Authors: We agree that the abstract's brevity leaves the headline metrics without immediate context from baselines or other details. The full manuscript describes the experimental setup, including model hyperparameters and data splits, in Sections 3 and 4, and reports comparisons against LSTM/GRU/ARIMA baselines in the results. To strengthen the abstract and better support the central claim, we will revise it to include a concise reference to baseline performance (e.g., 'outperforming conventional time-series models') while directing readers to the detailed comparisons and statistical tests in the body of the paper. revision: partial
-
Referee: [Abstract] RF tokenizer description (implied in Abstract and methods): The tokenizer maps continuous PSD bins to a fixed vocabulary and augments them with discrete embeddings for frequency, timestamp, gain, and FFT index. No ablation is reported that isolates the contribution of these embeddings or compares the tokenized discrete model against a continuous-valued forecaster (e.g., LSTM directly on PSD values). Without such controls, it remains unclear whether the discretization step preserves the local spectral continuity and short-term temporal correlations required for reliable forecasting, which is the weakest link in the generalization argument.
Authors: We concur that dedicated ablations on the tokenizer components would clarify its role and address potential concerns about information loss from discretization. In the revised manuscript we will add an ablation study that systematically removes individual embeddings (frequency, timestamp, gain, FFT index) and directly compares the tokenized discrete model against a continuous-valued LSTM baseline operating on raw PSD values. These new results will be placed in the experiments section to demonstrate that the tokenizer preserves the necessary spectral and temporal structure. revision: yes
Circularity Check
No circularity: empirical performance metrics on held-out tokenized spectrum data
full rationale
The paper presents an RF tokenizer that discretizes PSD values and augments them with embeddings, then trains decoder-only transformers on the resulting token sequences collected from a large outdoor testbed. Reported results (RMSE 3.25 dB, 97% MAE < 5 dB, generalization after fine-tuning) are standard supervised learning evaluation metrics computed on held-out portions of the 8.4B-token dataset. No equations, uniqueness theorems, or self-citations are invoked that would reduce these metrics to quantities defined by the model's own fitted parameters or prior outputs. The derivation chain consists of data collection, tokenization, model training, and empirical testing, all of which remain independent of the final performance numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer decoder architectures can capture sequential dependencies in tokenized RF power spectral density data
invented entities (2)
-
RF tokenizer
no independent evidence
-
Large Spectrum Model (LSM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
State of IoT 2024: Num. of connected IoT devices growing 13% to 18.8B globally,
S. Sinha, “State of IoT 2024: Num. of connected IoT devices growing 13% to 18.8B globally,” https://bit.ly/4l36mLs, 2024, accessed: 2025- 06-21
work page 2024
-
[2]
On the road to 6G: Visions, requirements, key tech- nologies, and testbeds,
C.-X. Wang et al., “On the road to 6G: Visions, requirements, key tech- nologies, and testbeds,” IEEE Communications Surveys and Tutorials , vol. 25, no. 2, pp. 905–974, 2023
work page 2023
-
[3]
NeXt generation/dynamic spectrum access/cognitive radio wireless networks: A survey,
I. F. Akyildiz, W.- Y . Lee, M. C. Vuran, and S. Mohanty, “NeXt generation/dynamic spectrum access/cognitive radio wireless networks: A survey,” Computer Networks, vol. 50, no. 13, pp. 2127–2159, 2006
work page 2006
-
[4]
Spectrum Sensing Using Software Defined Radio for Cognitive Radio Networks: A Survey,
J. Manco, I. Dayoub, A. Nafkha et al. , “Spectrum Sensing Using Software Defined Radio for Cognitive Radio Networks: A Survey,” IEEE Access, 2022
work page 2022
-
[5]
A Novel Software Defined Radio for Practical, Mobile Crowdsourced Spectrum Sensing,
P . Smith, A. Luong, S. Sarkar et al. , “A Novel Software Defined Radio for Practical, Mobile Crowdsourced Spectrum Sensing,” IEEE Trans. on Mob. Comp. , 2023
work page 2023
-
[6]
X. Cao, B. Y ang, and K. o. Wangand, “AI-Empowered Multiple Access for 6G: A Survey of Spectrum Sensing, Protocol Designs, and Opti- mizations,” Proc. of the IEEE , 2024
work page 2024
-
[7]
A New Spectrum Prediction Method for UA V Communications,
Y . Zhao, S. Luo, Z. Yuan, and R. Lin, “A New Spectrum Prediction Method for UA V Communications,” in 2019 IEEE ICCC , 2019
work page 2019
-
[8]
Predicting dynamic spectrum allocation: a review covering simulation, modelling, and prediction,
A. C. Cullen, B. I. P . Rubinstein, S. Kandeepan, B. Flower, and P . H. W. Leong, “Predicting dynamic spectrum allocation: a review covering simulation, modelling, and prediction,” Artif. Intell. Rev., vol. 56, no. 10, pp. 10 921–10 959, Oct. 2023
work page 2023
-
[9]
A city-wide experimental testbed for the next generation wireless networks,
Z. Zhao, M. C. Vuran, B. Zhou, M. M. Lunar, Z. Aref, D. P . Y oung, W. Humphrey, S. Goddard, G. Attebury, and B. France, “A city-wide experimental testbed for the next generation wireless networks,” Ad Hoc Networks, vol. 111, p. 102305, Feb. 2021
work page 2021
-
[10]
M. M. R. Lunar, J. Sun, J. Wensowitch, M. Fay, H. B. Tulay, V . S. S. L. Karanam, B. Qiu, D. Nadig, G. Attebury, H. Yu, J. Camp, C. E. Koksal, D. Pompili, B. Ramamurthy, M. Hashemi, E. Ekici, and M. C. Vuran, “Onelnk: One link to rule them all: Web-based wireless experimentation for multi-vendor remotely accessible indoor/outdoor testbeds,” in Proceedings...
-
[11]
Gemma: Open Models Based on Gemini Research and Technology
G. Team, T. Mesnard, C. Hardin et al. , “Gemma: Open models based on gemini research and technology,” arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Language Models are Unsupervised Multitask Learners,
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” 2019. [Online]. Available: https://cdn.openai.com/better-language-models/ language_models_are_unsupervised_multitask_learners.pdf
work page 2019
-
[13]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard et al. , “LLaMA: Open and Efficient Foundation Language Models,” 2023. [Online]. Available: https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
A. Q. Jiang, A. Sablayrolles, A. Mensch et al. , “Mistral 7B,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
S. Gunasekar, Y . Zhang, J. Aneja et al. , “Textbooks Are All Y ou Need,” 2023. [Online]. Available: https://arxiv.org/abs/2306.11644
work page internal anchor Pith review arXiv 2023
-
[16]
M. Abd Elaziz, M. A. Al-qaness, and A. o. Dahou, “Evolution toward intelligent communications: Impact of deep learning applications on the future of 6G technology,” Wiley Interdisciplinary Reviews , 2024
work page 2024
-
[17]
Recent Advances in Deep Learning for Channel Coding: A Survey,
T. Matsumine and H. Ochiai, “Recent Advances in Deep Learning for Channel Coding: A Survey,” IEEE Open Journal of the Comm. Society , 2024
work page 2024
-
[18]
Deep learning for joint channel estimation and feedback in massive mimo systems,
J. Guo, T. Chen, S. Jin et al., “Deep learning for joint channel estimation and feedback in massive mimo systems,” Digital Communications and Networks, vol. 10, no. 1, pp. 83–93, 2024
work page 2024
-
[19]
Lightweight deep learning based channel estimation for extremely large-scale massive MIMO systems,
S. Gao, P . Dong, Z. Pan, and X. Y ou, “Lightweight deep learning based channel estimation for extremely large-scale massive MIMO systems,” IEEE Transactions on Vehicular Technology , vol. 73, no. 7, 2024
work page 2024
-
[20]
D. Wang, Z. Wang, H. Zhao et al. , “Secure Energy Efficiency for ARIS Networks With Deep Learning: Active Beamforming and Position Optimization,” IEEE Trans. on Wireless Comm. , 2025
work page 2025
-
[21]
Deep Learning Enabled Multicast Beamforming With Movable Antenna Array,
J.-M. Kang, “Deep Learning Enabled Multicast Beamforming With Movable Antenna Array,” IEEE Wireless Comm. Letters , 2024
work page 2024
-
[22]
I Can’t Believe It’s Not Real: CV-MuSeNet: Complex-Valued Multi-Signal Segmentation,
S. Shin and M. C. Vuran, “I Can’t Believe It’s Not Real: CV-MuSeNet: Complex-Valued Multi-Signal Segmentation,” in IEEE DySPAN, 2025
work page 2025
-
[23]
Analysis of spectrum sensing using deep learning algorithms: CNNs and RNNs,
A. Kumar, N. Gaur, S. Chakravarty et al. , “Analysis of spectrum sensing using deep learning algorithms: CNNs and RNNs,” Ain Shams Engineering Journal , 2024
work page 2024
-
[24]
N. El-haryqy, Z. Madini, and Y . Zouine, “A review of deep learning techniques for enhancing spectrum sensing and prediction in cognitive radio systems: approaches, datasets, and challenges,” International Jour- nal of Computers and Applications , vol. 46, no. 12, 2024
work page 2024
-
[25]
P . Subedi, S. Shin, and M. C. Vuran, “Seek and Classify: End-to- end Joint Spectrum Segmentation and Classification for Multi-signal Wideband Spectrum Sensing,” in IEEE LCN’24 , 2024
work page 2024
-
[26]
VIA: Establishing the link between spectrum sensor capabilities and data analytics performance,
K. Doke, B. Okoro, A. Zare, and M. Zheleva, “VIA: Establishing the link between spectrum sensor capabilities and data analytics performance,” in IEEE INFOCOM 2024
work page 2024
-
[27]
DeepSense: Fast Wideband Spectrum Sensing Through Real-Time In-the-Loop Deep Learning,
D. Uvaydov, S. D’Oro, F. Restuccia et al. , “DeepSense: Fast Wideband Spectrum Sensing Through Real-Time In-the-Loop Deep Learning,” in IEEE INFOCOM 2021
work page 2021
-
[28]
Spectrum sensing in cognitive radio: A deep learning based model,
H. Xing et al. , “Spectrum sensing in cognitive radio: A deep learning based model,” Transactions on Emerging Telecommunications Technolo- gies, vol. 33, no. 1, p. e4388, 2022
work page 2022
-
[29]
Deep Learning Classification of 3.5-GHz Band Spec- trograms With Applications to Spectrum Sensing,
W. M. Lees et al., “Deep Learning Classification of 3.5-GHz Band Spec- trograms With Applications to Spectrum Sensing,” IEEE Transactions on Cognitive Communications and Networking , 2019
work page 2019
-
[30]
Signal Detection and Classification in Shared Spec- trum: A Deep Learning Approach,
W. Zhang et al. , “Signal Detection and Classification in Shared Spec- trum: A Deep Learning Approach,” in IEEE INFOCOM 2021
work page 2021
-
[31]
Learning the unknown: Improving modulation clas- sification perf. in unseen scenarios,
E. Perenda et al. , “Learning the unknown: Improving modulation clas- sification perf. in unseen scenarios,” in IEEE INFOCOM 2021
work page 2021
-
[32]
X. Li, G. Chen, Y . Xu et al. , “Recovering Missing Values From Cor- rupted Historical Observations: Approaching the Limit of Predictability in Spectrum Prediction Tasks,” IEEE Access , 2020
work page 2020
-
[33]
Spectrum Transformer: An Attention-Based Wideband Spectrum Detector,
W. Zhang, Y . Wang, X. Chen et al. , “Spectrum Transformer: An Attention-Based Wideband Spectrum Detector,” IEEE Trans. on Wire- less Comm. , 2024
work page 2024
-
[34]
Multi-channel multi-step spec- trum prediction using transformer and stacked Bi-LSTM,
P . Guangliang, L. Jie, and L. Minglei, “Multi-channel multi-step spec- trum prediction using transformer and stacked Bi-LSTM,” China Com- munications, 2025
work page 2025
-
[35]
USRP N310: Networked soft- ware‑defined radio,
Ettus Research (National Instruments), “USRP N310: Networked soft- ware‑defined radio,” Product page, Ettus Research, Jun. 2025, available at https://tinyurl.com/usrpn310 (Accessed: 2025-06-11)
work page 2025
-
[36]
TensorFlow: Large-scale machine learning on heterogeneous systems,
M. Abadi, A. Agarwal, P . Barham et al. , “ TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015, software available from tensorflow.org. [Online]. Available: https://www.tensorflow.org/
work page 2015
-
[37]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa et al. , “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[38]
Trimmed sample means for robust uniform mean estimation and regression,
R. I. Oliveira and L. Resende, “Trimmed sample means for robust uniform mean estimation and regression,” arXiv:2302.06710, 2023
-
[39]
C. Kocak, E. Bas, and E. Egrioglu, “Trimmed Mean Dendritic Neuron Model Artificial Neural Network for Time Series Forecasting in Case of Outliers,” Available at SSRN 4937461 , 2024
work page 2024
-
[40]
Llama model configuration — transform- ers main branch,
Hugging Face & EleutherAI, “Llama model configuration — transform- ers main branch,” GitHub Repository, 2025, accessed: 2025-06-14
work page 2025
-
[41]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
T. Wolf, L. Debut, V . Sanh et al. , “Huggingface’s transformers: State- of-the-art natural language processing,” arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[42]
TimeGPT-1: Foundation Model for Time Series Forecasting,
A. Garza and M. Mergenthaler-Canseco, “TimeGPT-1: Foundation Model for Time Series Forecasting,” arXiv, 2023
work page 2023
-
[43]
A coefficient of agreement for nominal scale,
J. Kohen, “A coefficient of agreement for nominal scale,” Educ Psychol Meas, vol. 20, pp. 37–46, 1960
work page 1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.