Recognition: no theorem link
Compute Where it Counts: Self Optimizing Language Models
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
A small policy network learns per-token compute decisions to improve LLM quality at fixed inference budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Self-Optimizing Language Models attach a lightweight policy network to a frozen LLM. At each decoding step the policy reads the current hidden state and selects a discrete efficiency action that jointly sets token-level attention sparsity, structured activation pruning in the MLP, and activation quantization bit-width. The policy is trained with group-relative policy optimization on teacher-forced episodes by sampling multiple compute schedules for the identical token sequence and optimizing their relative likelihoods under a reward that balances language-model quality against soft budget penalties. This produces schedules that outperform both uniform allocation and strong random search on a
What carries the argument
Lightweight policy network that selects joint efficiency actions (attention sparsity, MLP pruning, quantization) from LLM hidden states at each decode step.
If this is right
- Quality at matched compute budget exceeds that of static uniform allocation across tested model sizes and regimes.
- The method traces a superior quality-efficiency Pareto frontier relative to both static schedules and random schedule search.
- MMLU accuracy rises by as much as 7.3 percent compared with uniform budget allocation at the same total cost.
- The approach supplies an orthogonal axis of inference optimization that can be combined with existing weight-compression techniques.
Where Pith is reading between the lines
- If the policy generalizes from teacher-forced training to free generation, similar lightweight controllers could adapt other per-step decisions such as expert selection in mixture-of-experts models.
- The technique implies that token difficulty distributions contain enough structure for learned policies to discover recurring patterns without explicit supervision on difficulty labels.
- Deployed systems could request different average budgets at inference time and receive automatically adjusted per-token schedules without retraining the base model.
Load-bearing premise
The policy trained only on teacher-forced episodes will choose actions that still improve quality when the model generates tokens autoregressively.
What would settle it
Measure MMLU accuracy or perplexity of the policy-controlled model against a uniform-budget baseline at identical average compute cost on a held-out test set; improvement would support the claim, no improvement or degradation would refute it.
Figures









read the original abstract
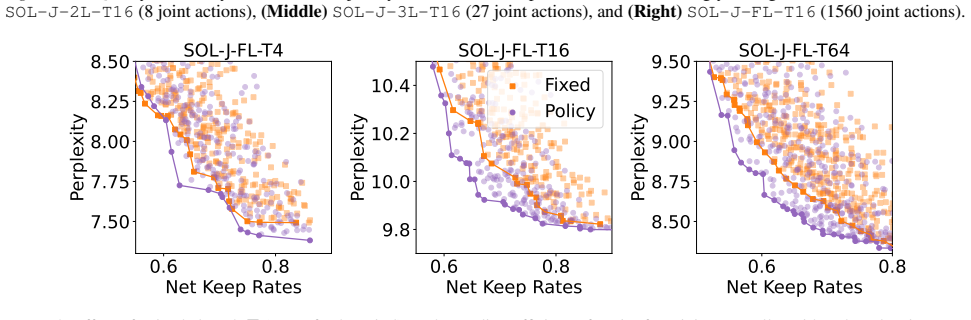
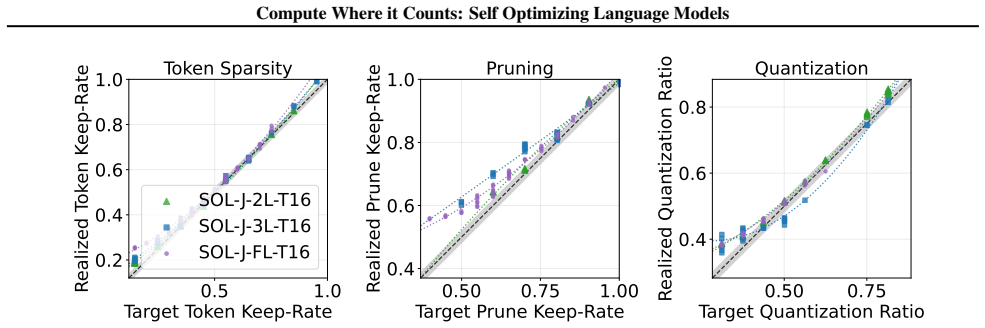
Efficient LLM inference research has largely focused on reducing the cost of each decoding step (e.g., using quantization, pruning, or sparse attention), typically applying a uniform computation budget to every generated token. In practice, token difficulty varies widely, so static compression can over-compute on easy steps and under-compute on hard ones. We study dynamic budget allocation for autoregressive decoding: learning how much computation to spend per token from within a single model. Self-Optimizing Language Models (SOL) pair a frozen LLM with a lightweight policy network that reads the LLM hidden state and selects a discrete efficiency action at each decode step. Actions can jointly control (i) token-level attention sparsity, (ii) structured activation pruning in the MLP, and (iii) activation quantization bit-width, while leaving the base model weights unchanged. We train the policy with group-relative policy optimization on teacher-forced episodes: the token sequence is fixed, while we sample multiple compute schedules (i.e., "counterfactual" schedules that vary only the efficiency actions for the same token path) and compare their likelihoods under the same supervision. Our reward trades off language-model quality against soft penalties that encourage episode-average budget usage to match a requested target. Across model variants and compute regimes, SOL improves quality at matched budget over static allocation and strong random schedule search, offering a complementary axis for inference-efficiency optimization. SOL discovers a better quality-efficiency pareto-front across all our experiments and improves MMLU accuracy by up to 7.3% over uniform budget allocation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Optimizing Language Models (SOL) that augment a frozen LLM with a lightweight policy network. At each autoregressive decoding step the policy reads the current hidden state and selects a joint efficiency action controlling attention sparsity, structured MLP pruning, and activation quantization bit-width. The policy is trained via group-relative policy optimization on teacher-forced episodes: multiple counterfactual compute schedules are sampled for the same fixed token sequence, their likelihoods under the supervised next token are compared, and a reward balances next-token quality against a soft penalty that enforces a target average budget. The authors report that SOL discovers a superior quality-efficiency Pareto front and yields up to 7.3 % MMLU accuracy improvement relative to uniform budget allocation.
Significance. If the reported gains hold under autoregressive deployment, the work supplies a new, model-internal axis for inference-time efficiency that is complementary to static quantization or pruning. The GRPO training on counterfactual schedules is a clean way to obtain relative quality signals without external reward models, and the approach leaves base-model weights untouched.
major comments (3)
- [Abstract / Training procedure] Abstract and training description: the policy is optimized exclusively on teacher-forced episodes in which the token sequence is held fixed and only efficiency actions vary. No experiment is reported that measures whether the resulting policy transfers to full autoregressive generation, where an early low-compute error corrupts subsequent hidden states and policy inputs. This transfer is load-bearing for the central claim of improved MMLU accuracy and Pareto front.
- [Abstract] Abstract: the 7.3 % MMLU improvement and “better quality-efficiency Pareto front across all experiments” are stated without any description of model sizes, evaluation datasets, exact baselines (beyond uniform and random search), number of runs, variance, or statistical tests. These omissions prevent verification that the data support the headline numbers.
- [Reward definition] Reward formulation: the quality component is defined via likelihoods of the supervised next token under the chosen efficiency actions. It is unclear how this teacher-forced likelihood reward correlates with downstream task accuracy (MMLU) once the model generates its own tokens; no ablation or correlation analysis is provided.
minor comments (2)
- [Methods] Notation for the discrete action space (sparsity level, pruning ratio, bit-width) should be introduced with an explicit table or equation early in the methods section.
- [Training algorithm] The manuscript should clarify whether the policy network parameters are updated only on the teacher-forced episodes or whether any on-policy fine-tuning occurs during autoregressive rollouts.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the presentation of our work. We address each major comment below and will revise the manuscript to incorporate additional details, experiments, and analyses where needed.
read point-by-point responses
-
Referee: [Abstract / Training procedure] Abstract and training description: the policy is optimized exclusively on teacher-forced episodes in which the token sequence is held fixed and only efficiency actions vary. No experiment is reported that measures whether the resulting policy transfers to full autoregressive generation, where an early low-compute error corrupts subsequent hidden states and policy inputs. This transfer is load-bearing for the central claim of improved MMLU accuracy and Pareto front.
Authors: We appreciate the referee highlighting this important consideration. Teacher-forced episodes are used during training to enable stable group-relative comparisons of counterfactual compute schedules on identical token sequences, yielding reliable relative quality signals without the confounding effects of error accumulation during policy optimization. The policy is explicitly conditioned on the current hidden state at each step, which is compatible with autoregressive deployment. In the revised manuscript we will add dedicated experiments evaluating the trained policy under full autoregressive generation on a subset of tasks (including MMLU), with analysis of any error propagation effects and comparison to the teacher-forced setting. This will directly address transferability. revision: yes
-
Referee: [Abstract] Abstract: the 7.3 % MMLU improvement and “better quality-efficiency Pareto front across all experiments” are stated without any description of model sizes, evaluation datasets, exact baselines (beyond uniform and random search), number of runs, variance, or statistical tests. These omissions prevent verification that the data support the headline numbers.
Authors: We agree that the abstract should supply sufficient context for the reported results. In the revision we will expand the abstract to specify the model sizes (Llama-2 7B and 13B variants), the MMLU benchmark along with other evaluation datasets, the precise baselines (uniform budget allocation and random schedule search), and indicate that results are averaged over multiple random seeds with reported variance and statistical significance where applicable. revision: yes
-
Referee: [Reward definition] Reward formulation: the quality component is defined via likelihoods of the supervised next token under the chosen efficiency actions. It is unclear how this teacher-forced likelihood reward correlates with downstream task accuracy (MMLU) once the model generates its own tokens; no ablation or correlation analysis is provided.
Authors: The next-token likelihood under supervision directly reflects the language-modeling objective that drives downstream accuracy on tasks such as MMLU. To make this connection explicit, the revised manuscript will include (i) a correlation analysis between per-episode average quality rewards and final MMLU accuracy across varied policy configurations and (ii) an ablation comparing policies trained with and without the quality reward term, demonstrating its contribution to task-level performance. revision: yes
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The paper's core method trains a policy network via group-relative policy optimization on teacher-forced episodes, sampling counterfactual efficiency schedules on fixed token paths and rewarding based on supervised likelihoods plus budget penalties. Claimed gains (MMLU accuracy up to 7.3%, superior Pareto front) are presented as empirical results from deploying the trained policy, compared against static allocation and random search baselines. No equation, definition, or self-citation reduces the reported improvements to a fit on the evaluation data itself, a renaming of known patterns, or an ansatz imported from prior author work. The separation between teacher-forced training and downstream autoregressive evaluation keeps the central claims independent of their inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- target average budget
- quality-budget reward weights
axioms (1)
- domain assumption The base LLM weights remain frozen and are not modified by the efficiency actions chosen by the policy.
invented entities (1)
-
lightweight policy network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
F., Dotzel, J., Zhang, Z., Rush, A
Akhauri, Y ., AbouElhamayed, A. F., Dotzel, J., Zhang, Z., Rush, A. M., Huda, S., and Abdelfattah, M. S. Shad- owllm: Predictor-based contextual sparsity for large lan- guage models.arXiv preprint arXiv:2406.16635,
-
[2]
F., Gao, Y ., Chang, C.-C., Jain, N., and Abdelfattah, M
Akhauri, Y ., AbouElhamayed, A. F., Gao, Y ., Chang, C.-C., Jain, N., and Abdelfattah, M. S. Tokenbutler: Token im- portance is predictable.arXiv preprint arXiv:2503.07518, 2025a. Akhauri, Y ., Fei, A., Chang, C.-C., AbouElhamayed, A. F., Li, Y ., and Abdelfattah, M. S. Splitreason: Learning to offload reasoning.arXiv preprint arXiv:2504.16379, 2025b. Bis...
-
[3]
Chang, C.-C., Lin, C.-Y ., Akhauri, Y ., Lin, W.-C., Wu, K.-C., Ceze, L., and Abdelfattah, M. S. xkv: Cross-layer svd for kv-cache compression.arXiv preprint arXiv:2503.18893, 2025a. Chang, C.-C., Lin, W.-C., Lin, C.-Y ., Chen, C.-Y ., Hu, Y .- F., Wang, P.-S., Huang, N.-C., Ceze, L., Abdelfattah, M. S., and Wu, K.-C. Palu: Kv-cache compression with low-r...
-
[4]
Generating Long Sequences with Sparse Transformers
Child, R., Gray, S., Radford, A., and Sutskever, I. Gen- erating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[5]
Rethinking Attention with Performers
Choromanski, K., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794,
work page internal anchor Pith review arXiv 2009
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
S., Zhang, Z., Cheng, L., Dixon, M
Dotzel, J., Wu, G., Li, A., Umar, M., Ni, Y ., Abdelfat- tah, M. S., Zhang, Z., Cheng, L., Dixon, M. G., Jouppi, N. P., et al. Fliqs: One-shot mixed-precision floating- point and integer quantization search.arXiv preprint arXiv:2308.03290,
-
[8]
Elbayad, M., Gu, J., Grave, E., and Auli, M. Depth-adaptive transformer.arXiv preprint arXiv:1910.10073,
-
[9]
Aly, Beidi Chen, and Carole-Jean Wu
Elhoushi, M., Shrivastava, A., Liskovich, D., Hosmer, B., Wasti, B., Lai, L., Mahmoud, A., Acun, B., Agarwal, S., Roman, A., et al. Layerskip: Enabling early exit inference and self-speculative decoding.arXiv preprint arXiv:2404.16710,
- [10]
-
[11]
Fu, T., Ge, Y ., You, Y ., Liu, E., Yuan, Z., Dai, G., Yan, S., Yang, H., and Wang, Y . R2r: Efficiently navigating divergent reasoning paths with small-large model token routing.arXiv preprint arXiv:2505.21600,
-
[12]
URL https://zenodo.org/records/12608602. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR),
-
[13]
Huang, C.-W., Chen, T.-W., and Huang, J.-D. All-you- can-fit 8-bit flexible floating-point format for accurate and memory-efficient inference of deep neural networks. arXiv preprint arXiv:2104.07329,
- [14]
-
[15]
arXiv preprint arXiv:2408.14690 , year=
Liu, J., Ponnusamy, P., Cai, T., Guo, H., Kim, Y ., and Athiwaratkun, B. Training-free activation sparsity in large language models.arXiv preprint arXiv:2408.14690, 2024a. Liu, Z., Desai, A., Liao, F., Wang, W., Xie, V ., Xu, Z., Kyril- lidis, A., and Shrivastava, A. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compre...
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
ISSN 0001-0782. doi: 10.1145/3474381. URL https: //doi.org/10.1145/3474381. Schuster, T., Fisch, A., Gupta, J., Dehghani, M., Bahri, D., Tran, V ., Tay, Y ., and Metzler, D. Confident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472, 2022a. Schuster, T., Fisch, A., Gupta, J., Dehghani, M., Bahri, D., Tran, V ., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3474381
-
[17]
Adaptive attention span in transformers
Sukhbaatar, S., Grave, E., Bojanowski, P., and Joulin, A. Adaptive attention span in transformers.arXiv preprint arXiv:1905.07799,
-
[18]
arXiv preprint arXiv:2406.10774 , year=
Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
-
[19]
Wu, W., Pan, Z., Wang, C., Chen, L., Bai, Y ., Wang, T., Fu, K., Wang, Z., and Xiong, H. Tokenselect: Efficient long- context inference and length extrapolation for llms via dynamic token-level kv cache selection.arXiv preprint arXiv:2411.02886,
-
[20]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Xiao, G., Tang, J., Zuo, J., Guo, J., Yang, S., Tang, H., Fu, Y ., and Han, S. Duoattention: Efficient long-context 10 Compute Where it Counts: Self Optimizing Language Models llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819,
-
[22]
DeeBERT: dynamic early exiting for accelerating BERT inference.arXiv preprint arXiv:2004.12993, 2020
Xin, J., Tang, R., Lee, J., Yu, Y ., and Lin, J. Deebert: Dynamic early exiting for accelerating bert inference. arXiv preprint arXiv:2004.12993,
-
[23]
arXiv preprint arXiv:2505.03469 , year=
Yu, B., Yuan, H., Li, H., Xu, X., Wei, Y ., Wang, B., Qi, W., and Chen, K. Long-short chain-of-thought mixture super- vised fine-tuning eliciting efficient reasoning in large lan- guage models.arXiv preprint arXiv:2505.03469,
-
[24]
Zhang, R., Wang, K., Liu, L., Wang, S., Cheng, H., Zhang, C., and Shen, Y . Lorc: Low-rank compression for llms kv cache with a progressive compression strategy.arXiv preprint arXiv:2410.03111,
-
[25]
We overlay the fixed baseline (constant action across decode steps) and the policy. 0.5 0.6 0.7 Net Keep Rates 0.0 0.5 1.0Normalized Perplexity SOL-J-2L-T16 0.4 0.6 Net Keep Rates Normalized Perplexity SOL-J-3L-T16 0.6 0.7 Net Keep Rates Normalized Perplexity SOL-J-FL-T16 Random Best-of-500 Random Fixed Policy Figure 9.Comparison against 500-sample random...
work page 2020
-
[26]
Budget Ranges:Token budget[0.1,1.0]; pruning budget[0.4,1.0]; quantization ratio budget[0.3125,1.0] Budget Penalty Weights:α κ = 100;α ρ = 100;α η = 200 GRPO group size / horizon:T=16decode steps/episode;K=16schedules/input; entropy coef= 0.05 Optimization:Batch size= 8; grad accumulation= 8; lr= 10 −4; max grad norm= 2.0; epochs= 1 Context Length:1024 Po...
work page 2048
-
[27]
Action Space: Keep-Rate {0.1, 0.4, 0.7, 1.0} ;Prune {s45, s50, s60, s70, s80, s90, s100} ; Quant{q5, q6, ..., q16} Budget Ranges:Token budget[0.1,1.0]; pruning budget[0.45,1.0]; quantization ratio budget[0.3125,1.0] 15 Compute Where it Counts: Self Optimizing Language Models Budget Penalty Weights:α κ = 100;α ρ = 100;α η = 200 GRPO group size / horizon (d...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.