Recognition: no theorem link
LoKA: Low-precision Kernel Applications for Recommendation Models At Scale
Pith reviewed 2026-05-15 04:52 UTC · model grok-4.3
The pith
LoKA framework makes FP8 practical for large recommendation models by profiling safe sites, adapting components, and dispatching kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoKA is a framework that integrates LoKA Probe, a statistically grounded online method that learns activation and weight statistics to quantify per-layer errors and mark safe versus unsafe FP8 sites, LoKA Mods, a set of reusable adaptations that improve numerical stability and execution efficiency under FP8, and LoKA Dispatch, a runtime that uses the profiling data to select the fastest compliant FP8 kernel for each operation.
What carries the argument
LoKA Probe, the statistically grounded online benchmarking method that learns activation and weight statistics under realistic distributions and quantifies per-layer errors to identify safe FP8 sites.
If this is right
- FP8 can be applied to more operations inside LRMs once safe sites are located by realistic profiling.
- Model adaptations expand the regions where low precision remains stable and efficient.
- Runtime kernel selection delivers the highest throughput while satisfying accuracy constraints.
- Overall training throughput rises while model quality stays comparable to higher-precision runs.
Where Pith is reading between the lines
- Periodic re-profiling may be needed if training data distributions drift over many epochs.
- Energy use in large-scale recommendation training could fall as FP8 replaces higher precision in more layers.
- Hardware designers might prioritize better FP8 support and mixed-precision scheduling for recommendation workloads.
- The same profiling-plus-adaptation pattern could be tested on other numerically sensitive models such as those used in ranking or retrieval tasks.
Load-bearing premise
The statistical profiling from LoKA Probe accurately identifies all safe FP8 sites without missing interactions or distribution shifts that would degrade overall model quality during full training.
What would settle it
A complete training run of a large recommendation model under LoKA's FP8 configuration that shows a measurable drop in final model quality metrics relative to the FP16 or FP32 baseline.
Figures






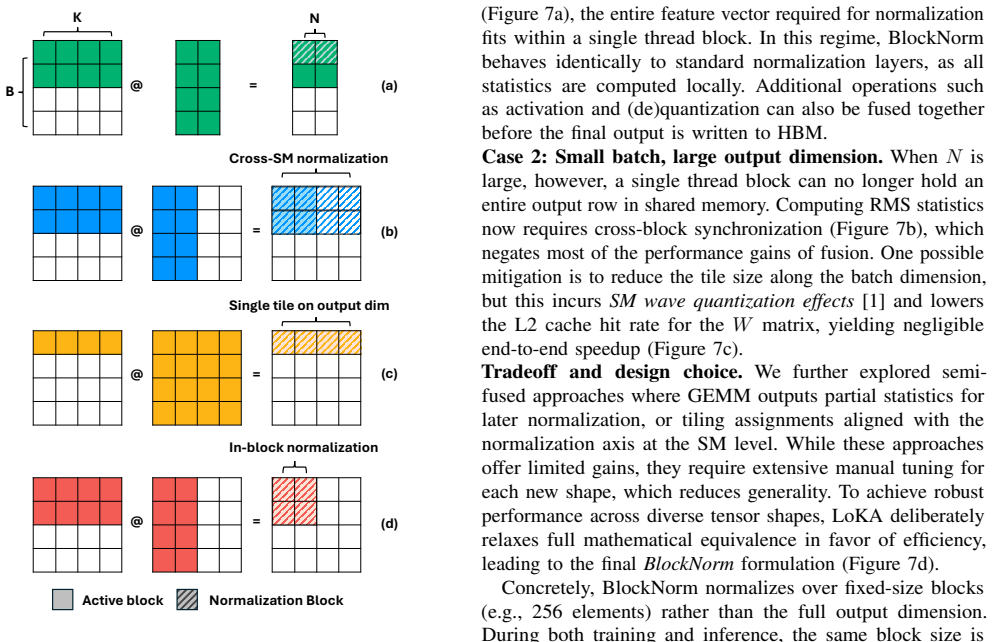






read the original abstract
Recent GPU generations deliver significantly higher FLOPs using lower-precision arithmetic, such as FP8. While successfully applied to large language models (LLMs), its adoption in large recommendation models (LRMs) has been limited. This is because LRMs are numerically sensitive, dominated by small matrix multiplications (GEMMs) followed by normalization, and trained in communication-intensive environments. Applying FP8 directly to LRMs often degrades model quality and prolongs training time. These challenges are inherent to LRM workloads and cannot be resolved merely by introducing better FP8 kernels. Instead, a system-model co-design approach is needed to successfully integrate FP8. We present LoKA (Low-precision Kernel Applications), a framework that makes FP8 practical for LRMs through three principles: profile under realistic distributions to know where low precision is safe, co-design model components with hardware to expand where it is safe, and orchestrate across kernel libraries to maximize the gains. Concretely, LoKA Probe is a statistically grounded, online benchmarking method that learns activation and weight statistics, and quantifies per-layer errors. This process pinpoints safe and unsafe, fast and slow sites for FP8 adoption. LoKA Mods is a set of reusable model adaptations that improve both numerical stability and execution efficiency with FP8. LoKA Dispatch is a runtime that leverages the statistical insights from LoKA Probe to select the fastest FP8 kernel that satisfies the accuracy requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LoKA, a framework for applying FP8 low-precision arithmetic to large recommendation models (LRMs). It relies on three principles: LoKA Probe for online statistical profiling of activations/weights to identify safe FP8 sites via per-layer error quantification, LoKA Mods for reusable model adaptations that enhance numerical stability and efficiency, and LoKA Dispatch for runtime selection of the fastest compliant FP8 kernel. The approach targets LRM-specific issues including numerical sensitivity, small GEMMs followed by normalization, and communication-heavy training environments.
Significance. If the profiling and adaptations prove robust, the work could meaningfully advance low-precision adoption in production-scale recommendation systems by delivering efficiency gains without quality degradation. The co-design emphasis on realistic distributions and hardware-aware modifications offers a structured alternative to kernel-only solutions and may generalize to other sensitive workloads.
major comments (2)
- [LoKA Probe description] The central claim that LoKA Probe correctly identifies all safe FP8 sites rests on per-layer statistical benchmarking, yet the description supplies no validation that isolated per-layer error bounds translate to stable end-to-end model quality; cumulative propagation through the embedding-to-logit path and SGD-induced distribution shifts are unaddressed.
- [LoKA Mods and LoKA Dispatch] LoKA Mods and Dispatch presuppose that profiled sites remain safe throughout full training runs, but no experiments or analysis demonstrate that the adaptations prevent quality loss under realistic LRM training dynamics (e.g., long-horizon SGD with inter-layer normalization dependencies).
minor comments (2)
- The abstract states that LoKA Probe 'quantifies per-layer errors' but does not define the error metric (e.g., relative L2, maximum absolute deviation) or the acceptance threshold used to classify sites as safe.
- Clarify how 'fast and slow sites' are distinguished during profiling and whether this classification incorporates both arithmetic throughput and communication costs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation gaps in LoKA Probe and the need for evidence under full training dynamics. We agree these points require strengthening and will revise the manuscript with additional end-to-end experiments and long-horizon analysis while preserving the core co-design contributions.
read point-by-point responses
-
Referee: [LoKA Probe description] The central claim that LoKA Probe correctly identifies all safe FP8 sites rests on per-layer statistical benchmarking, yet the description supplies no validation that isolated per-layer error bounds translate to stable end-to-end model quality; cumulative propagation through the embedding-to-logit path and SGD-induced distribution shifts are unaddressed.
Authors: We appreciate this observation. LoKA Probe employs conservative per-layer error quantification under realistic activation distributions precisely to bound potential propagation effects, and its online profiling is meant to track SGD-induced shifts. However, the manuscript does not include explicit end-to-end validation showing that per-layer decisions preserve full-model quality across the embedding-to-logit path. In revision we will add full-training experiments comparing LoKA-enabled models against FP16 baselines, with measurements of cumulative error and quality metrics at multiple training checkpoints. revision: yes
-
Referee: [LoKA Mods and LoKA Dispatch] LoKA Mods and Dispatch presuppose that profiled sites remain safe throughout full training runs, but no experiments or analysis demonstrate that the adaptations prevent quality loss under realistic LRM training dynamics (e.g., long-horizon SGD with inter-layer normalization dependencies).
Authors: This is a fair critique. While LoKA Mods are designed to improve numerical stability for normalization-heavy small GEMMs and Dispatch enforces accuracy constraints at runtime, the current text lacks dedicated long-horizon experiments. We will incorporate ablation studies and training curves over extended SGD runs that explicitly track inter-layer normalization dependencies and demonstrate that the combined adaptations maintain model quality without degradation. revision: yes
Circularity Check
No circularity: LoKA relies on empirical profiling and co-design without self-referential derivations
full rationale
The paper describes a practical systems framework consisting of LoKA Probe for statistical online benchmarking of activation/weight distributions and per-layer errors, LoKA Mods for model adaptations to improve FP8 stability, and LoKA Dispatch for runtime kernel selection. No equations, uniqueness theorems, or fitted parameters are presented that reduce the central claims to their own inputs by construction. The approach is grounded in external empirical measurements and hardware co-design rather than self-definition or self-citation chains, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption FP8 delivers significant speedups on modern GPUs for GEMM operations
- ad hoc to paper LRM numerical sensitivity can be mitigated by localized model adaptations without global quality loss
invented entities (3)
-
LoKA Probe
no independent evidence
-
LoKA Mods
no independent evidence
-
LoKA Dispatch
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Matrix multiplication background user’s guide - nvidia docs,
“Matrix multiplication background user’s guide - nvidia docs,” [Online; accessed 2025-09-11]. [Online]. Avail- able: https://docs.nvidia.com/deeplearning/performance/dl-performance- matrix-multiplication/index.html#wave-quant
work page 2025
-
[2]
The falcon series of open language models,
E. Almazrouei, H. Alobeidli, A. Alshamsi, A. Cappelli, R. Cojocaru, M. Debbah, ´Etienne Goffinet, D. Hesslow, J. Launay, Q. Malartic, D. Mazzotta, B. Noune, B. Pannier, and G. Penedo, “The falcon series of open language models,” 2023. [Online]. Available: https://arxiv.org/abs/2311.16867
-
[3]
Introduction — amd quark 0.10 documentation,
AMD, “Introduction — amd quark 0.10 documentation,” [Online; accessed 2025-10-29]. [Online]. Available: https://quark.docs.amd.com/ latest/onnx/tutorial microexponents quantization.html
work page 2025
-
[4]
R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen, E. Chu, J. H. Clark, L. E. Shafey, Y . Huang, K. Meier-Hellstern, G. Mishra, E. Moreira, M. Omernick, K. Robinson, S. Ruder, Y . Tay, K. Xiao, Y . Xu, Y . Zhang, G. H. Abrego, J. Ahn, J. Austin, P. Barham, J. Botha, J. Bradbury, S. Brahma, K. Brook...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Dot product matrix compression for machine learning,
Anonymous, “Dot product matrix compression for machine learning,” Technical Disclosure Commons, 2019
work page 2019
-
[6]
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. V oznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, G. Chauhan, A. Chourdia, W. Constable, A. Desmaison, Z. DeVito, E. Ellison, W. Feng, J. Gong, M. Gschwind, B. Hirsh, S. Huang, K. Kalambarkar, L. Kirsch, M. Lazos, M. Lezcano, Y . Liang, J. Liang, Y . Lu, C. K. Luk, B. Maher, Y . Pan, C. Puhrsch, M....
-
[7]
Un- derstanding scaling laws for recommendation models,
N. Ardalani, C.-J. Wu, Z. Chen, B. Bhushanam, and A. Aziz, “Un- derstanding scaling laws for recommendation models,”arXiv preprint arXiv:2208.08489, 2022
-
[8]
Quarot: Outlier-free 4-bit inference in rotated llms,
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, P. Cameron, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman, “Quarot: Outlier-free 4-bit inference in rotated llms,”Advances in Neural Information Processing Systems, vol. 37, pp. 100 213–100 240, 2024
work page 2024
-
[9]
Halo: Hadamard-assisted lower-precision optimization for llms,
S. Ashkboos, M. Nikdan, S. Tabesh, R. L. Castro, T. Hoefler, and D. Alistarh, “Halo: Hadamard-assisted lower-precision optimization for llms,”arXiv preprint arXiv:2501.02625, 2025
-
[10]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” 2016. [Online]. Available: https://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Post-training 4-bit quantization of convolution networks for rapid-deployment
R. Banner, Y . Nahshan, E. Hoffer, and D. Soudry, “Post-training 4-bit quantization of convolution networks for rapid-deployment,” 2019. [Online]. Available: https://arxiv.org/abs/1810.05723
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Quartet: Native fp4 training can be optimal for large language models,
R. L. Castro, A. Panferov, S. Tabesh, O. Sieberling, J. Chen, M. Nikdan, S. Ashkboos, and D. Alistarh, “Quartet: Native fp4 training can be optimal for large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2505.14669
-
[13]
Algorithms for computing the sample variance: Analysis and recommendations,
T. F. Chan, G. H. Golub, and R. J. LeVeque, “Algorithms for computing the sample variance: Analysis and recommendations,”The American Statistician, vol. 37, no. 3, pp. 242–247, 1983. 12
work page 1983
-
[14]
NetHint: White-Box networking for Multi-Tenant data centers,
J. Chen, H. Zhang, W. Zhang, L. Luo, J. Chase, I. Stoica, and D. Zhuo, “NetHint: White-Box networking for Multi-Tenant data centers,” in19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). Renton, WA: USENIX Association, Apr. 2022, pp. 1327–1343. [Online]. Available: https: //www.usenix.org/conference/nsdi22/presentation/chen-jingrong
work page 2022
-
[15]
Adaptive factorization network: Learning adaptive-order feature interactions,
W. Cheng, Y . Shen, and L. Huang, “Adaptive factorization network: Learning adaptive-order feature interactions,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 3609– 3616
work page 2020
-
[16]
arXiv preprint arXiv:2505.19115 , year=
B. Chmiel, M. Fishman, R. Banner, and D. Soudry, “Fp4 all the way: Fully quantized training of llms,” 2025. [Online]. Available: https://arxiv.org/abs/2505.19115
-
[17]
Deepgemm: clean and efficient fp8 gemm kernels with fine-grained scaling,
DeepSeek, “Deepgemm: clean and efficient fp8 gemm kernels with fine-grained scaling,” [Online; accessed 2025-08-29]. [Online]. Available: https://github.com/deepseek-ai/DeepGEMM
work page 2025
-
[18]
DeepSeek-AI, “Deepgemm numerical test,” https://github.com/deepseek- ai/DeepGEMM/blob/main/tests/test bf16.py#L38, [Accessed 17-02- 2026]
work page 2026
-
[19]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Lu, C. Zhao, C. Deng, C. Xu, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, E. Li, F. Zhou, F. Lin, F. Dai, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Li, H. Liang, H. Wei, H. Zhang, H. Luo, H. Ji, H. Ding, H. Tang, H. Cao, H. Gao, H. Qu, H. Zeng, J. Huang, J. L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
K. Deng, H. Zheng, M. Qing, K. Zhu, G. Li, Y . Xiao, L. E. Zhang, L. Guo, B. Hui, Y . Wang, G. Yuan, G. Agrawal, W. Niu, and X. Ma, “From bits to chips: An llm-based hardware-aware quantization agent for streamlined deployment of llms,” 2026. [Online]. Available: https://arxiv.org/abs/2601.03484
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Llm.int8(): 8-bit matrix multiplication for transformers at scale,” 2022. [Online]. Available: https://arxiv.org/abs/2208.07339
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Nvfp4 trains with precision of 16-bit and speed and effi- ciency of 4-bit — nvidia technical blog,
K. Devleker, “Nvfp4 trains with precision of 16-bit and speed and effi- ciency of 4-bit — nvidia technical blog,” 8 2025, [Online; accessed 2025- 08-31]. [Online]. Available: https://developer.nvidia.com/blog/nvfp4- trains-with-precision-of-16-bit-and-speed-and-efficiency-of-4-bit/
work page 2025
-
[24]
R.-G. Dumitru, V . Yadav, R. Maheshwary, P.-I. Clotan, S. T. Madhusudhan, and M. Surdeanu, “Layer-wise quantization: A pragmatic and effective method for quantizing llms beyond integer bit-levels,”
-
[25]
Available: https://arxiv.org/abs/2406.17415
[Online]. Available: https://arxiv.org/abs/2406.17415
-
[26]
Learned step size quantization,
S. K. Esser, J. L. McKinstry, D. Bablani, R. Appuswamy, and D. S. Modha, “Learned step size quantization,” 2020. [Online]. Available: https://arxiv.org/abs/1902.08153
-
[27]
Adaptive gradient quantization for data-parallel sgd,
F. Faghri, I. Tabrizian, I. Markov, D. Alistarh, D. Roy, and A. Ramezani- Kebrya, “Adaptive gradient quantization for data-parallel sgd,” 2020. [Online]. Available: https://arxiv.org/abs/2010.12460
-
[28]
FBGEMM, “Fbgemm numerical test,” https://github.com/pytorch/ FBGEMM/blob/main/fbgemm gpu/test/quantize/fused 8bit rowwise test.py#L61)rely, [Accessed 17-02-2026]
work page 2026
-
[29]
Enabling float8 all-gather in fsdp2 - distributed - pytorch developer mailing list,
W. Feng, “Enabling float8 all-gather in fsdp2 - distributed - pytorch developer mailing list,” 8 2024, [Online; accessed 2025-10-29]. [Online]. Available: https://dev-discuss.pytorch.org/t/enabling-float8-all-gather-in- fsdp2/2359
work page 2024
-
[30]
Scaling fp8 training to trillion-token llms,
M. Fishman, B. Chmiel, R. Banner, and D. Soudry, “Scaling fp8 training to trillion-token llms,”arXiv preprint arXiv:2409.12517, 2024
-
[31]
Deck: Experiences on delta checkpointing for industrial recommendation systems,
X. Gao, S. Acharya, S. Han, Y . Ren, Y . Zhao, L. Luo, C. Wang, P. Fernando, S. Mishra, S. Yanet al., “Deck: Experiences on delta checkpointing for industrial recommendation systems,”Proceedings of the VLDB Endowment, vol. 18, no. 12, pp. 4978–4990, 2025
work page 2025
-
[32]
Vip5: Towards multimodal foundation models for recommendation,
S. Geng, J. Tan, S. Liu, Z. Fu, and Y . Zhang, “Vip5: Towards multimodal foundation models for recommendation,”arXiv preprint arXiv:2305.14302, 2023
-
[33]
A survey of quantization methods for efficient neural network inference,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network inference,”
-
[34]
Available: https://arxiv.org/abs/2103.13630
[Online]. Available: https://arxiv.org/abs/2103.13630
-
[35]
On the embedding collapse when scaling up recommendation models,
X. Guo, J. Pan, X. Wang, B. Chen, J. Jiang, and M. Long, “On the embedding collapse when scaling up recommendation models,”arXiv preprint arXiv:2310.04400, 2023
-
[36]
Matrix algebra from a statistician’s perspective,
D. A. Harville, “Matrix algebra from a statistician’s perspective,” 1998
work page 1998
-
[37]
Towards fully fp8 gemm llm training at scale,
A. Hern´andez-Cano, D. Garbaya, I. Schlag, and M. Jaggi, “Towards fully fp8 gemm llm training at scale,”arXiv preprint arXiv:2505.20524, 2025
-
[38]
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y . Bengio, “Quantized neural networks: Training neural networks with low precision weights and activations,” 2016. [Online]. Available: https: //arxiv.org/abs/1609.07061
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
Torchrec: a pytorch domain library for recommendation systems,
D. Ivchenko, D. Van Der Staay, C. Taylor, X. Liu, W. Feng, R. Kindi, A. Sudarshan, and S. Sefati, “Torchrec: a pytorch domain library for recommendation systems,” inProceedings of the 16th ACM Conference on Recommender Systems, 2022, pp. 482–483
work page 2022
-
[40]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” 2017. [Online]. Available: https://arxiv.org/abs/1712.05877
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Massive values in self-attention modules are the key to contextual knowledge understanding,
M. Jin, K. Mei, W. Xu, M. Sun, R. Tang, M. Du, Z. Liu, and Y . Zhang, “Massive values in self-attention modules are the key to contextual knowledge understanding,” 2025. [Online]. Available: https://arxiv.org/abs/2502.01563
-
[42]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020. 13
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[43]
Fbgemm: Enabling high-performance low- precision deep learning inference,
D. Khudia, J. Huang, P. Basu, S. Deng, H. Liu, J. Park, and M. Smelyanskiy, “Fbgemm: Enabling high-performance low- precision deep learning inference,” 2021. [Online]. Available: https: //arxiv.org/abs/2101.05615
-
[44]
Scout before you attend: Sketch-and-walk sparse attention for efficient llm inference,
H. A. D. Le, S. Joshi, Z. Yang, Z. Xu, and A. Shrivastava, “Scout before you attend: Sketch-and-walk sparse attention for efficient llm inference,” 2026. [Online]. Available: https://arxiv.org/abs/2602.07397
-
[45]
M. Liang, X. Liu, R. Jin, B. Liu, Q. Suo, Q. Zhou, S. Zhou, L. Chen, H. Zheng, Z. Li, S. Jiang, J. Yang, X. Xia, F. Yang, Y . Badr, E. Wen, S. Xu, H. Chen, Z. Zhang, J. Nie, C. Yang, Z. Zeng, W. Zhang, X. Huang, Q. Li, S. Wang, E. Lyu, W. Lu, R. Zhang, W. Wang, J. Rudy, M. Hang, K. Wang, Y . Ma, S. Wang, S. Zeng, T. Tang, X. Wei, L. Jin, J. Zhang, M. Chen...
-
[46]
Available: https://arxiv.org/abs/2502.17494
[Online]. Available: https://arxiv.org/abs/2502.17494
-
[47]
June 7, 2025.DOI:10.48550/arXiv.2410.06511
W. Liang, T. Liu, L. Wright, W. Constable, A. Gu, C.-C. Huang, I. Zhang, W. Feng, H. Huang, J. Wang, S. Purandare, G. Nadathur, and S. Idreos, “Torchtitan: One-stop pytorch native solution for production ready llm pre-training,” 2024. [Online]. Available: https://arxiv.org/abs/2410.06511
-
[48]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “Awq: Activation-aware weight quantization for on-device llm compression and acceleration,” inProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. D. Sa, Eds., vol. 6, 2024, pp. 87–100. [Online]. Available: https://proceedings.mlsys.o...
work page 2024
-
[49]
Parameter hub: a rack-scale parameter server for distributed deep neural network training,
L. Luo, J. Nelson, L. Ceze, A. Phanishayee, and A. Krishnamurthy, “Parameter hub: a rack-scale parameter server for distributed deep neural network training,” inProceedings of the ACM Symposium on Cloud Computing, 2018, pp. 41–54
work page 2018
-
[50]
Plink: Discovering and exploiting locality for accelerated distributed training on the public cloud,
L. Luo, P. West, J. Nelson, A. Krishnamurthy, and L. Ceze, “Plink: Discovering and exploiting locality for accelerated distributed training on the public cloud,”Proceedings of Machine Learning and Systems, vol. 2, pp. 82–97, 2020
work page 2020
-
[51]
L. Luo, B. Zhang, M. Tsang, Y . Ma, C.-H. Chu, Y . Chen, S. Li, Y . Hao, Y . Zhao, G. Lakshminarayananet al., “Disaggregated multi- tower: Topology-aware modeling technique for efficient large-scale recommendation,”arXiv preprint arXiv:2403.00877, 2024
-
[52]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” 2018. [Online]. Available: https://arxiv.org/abs/1710.03740
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
High-performance, distributed training of large-scale deep learning recommendation models,
D. Mudigere, Y . Hao, J. Huang, A. Tulloch, S. Sridharan, X. Liu, M. Ozdal, J. Nie, J. Park, L. Luoet al., “High-performance, distributed training of large-scale deep learning recommendation models,”arXiv preprint arXiv:2104.05158, 2021
-
[54]
A white paper on neural network quantization,
M. Nagel, M. Fournarakis, R. A. Amjad, Y . Bondarenko, M. van Baalen, and T. Blankevoort, “A white paper on neural network quantization,”
-
[55]
Available: https://arxiv.org/abs/2106.08295
[Online]. Available: https://arxiv.org/abs/2106.08295
-
[57]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
M. Naumov, D. Mudigere, H.-J. M. Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C.-J. Wu, A. G. Azzoliniet al., “Deep learning recommendation model for personalization and recommendation systems,”arXiv preprint arXiv:1906.00091, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[58]
1. nvidia ampere gpu architecture tuning guide — ampere tuning guide 13.0 documentation,
Nvidia, “1. nvidia ampere gpu architecture tuning guide — ampere tuning guide 13.0 documentation,” [Online; accessed 2025-09-12]. [Online]. Available: https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html
work page 2025
-
[59]
NVIDIA, “Github - nvidia/transformerengine: A library for accelerating transformer models on nvidia gpus, including using 8-bit floating point (fp8) precision on hopper, ada and blackwell gpus, to provide better performance with lower memory utilization in both training and inference.” [Online; accessed 2025-10-29]. [Online]. Available: https://github.com...
work page 2025
-
[60]
arXiv preprint arXiv:2509.25149 , year=
NVIDIA, F. Abecassis, A. Agrusa, D. Ahn, J. Alben, S. Alborghetti, M. Andersch, S. Arayandi, A. Bjorlin, A. Blakeman, E. Briones, I. Buck, B. Catanzaro, J. Choi, M. Chrzanowski, E. Chung, V . Cui, S. Dai, B. D. Rouhani, C. del Mundo, D. Donia, B. Eryilmaz, H. Estela, A. Goel, O. Goncharov, Y . Guvvala, R. Hesse, R. Hewett, H. Hum, U. Kapasi, B. Khailany, ...
-
[61]
NVIDIA Corporation, “Nvidia a100 gpu datasheet,” [Online; accessed 2025-08-25]. [Online]. Available: https://www.nvidia.com/content/dam/ en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf
work page 2025
-
[62]
——, “Nvidia b200 gpu datasheet,” [Online; accessed 2025-08-25]. [Online]. Available: https://nvdam.widen.net/s/wwnsxrhm2w/blackwell- datasheet-3384703
work page 2025
-
[63]
——, “Nvidia h100 gpu datasheet,” [Online; accessed 2025-08- 25]. [Online]. Available: https://resources.nvidia.com/en-us-hopper- architecture/nvidia-tensor-core-gpu-datasheet?ncid=no-ncid
work page 2025
-
[64]
Torchao: Pytorch-native training-to-serving model optimization,
A. Or, A. Jain, D. Vega-Myhre, J. Cai, C. D. Hernandez, Z. Zheng, D. Guessous, V . Kuznetsov, C. Puhrsch, M. Saroufim, S. Rao, T. Tran, and A. Samard ˇzi´c, “Torchao: Pytorch-native training-to-serving model optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2507.16099
-
[65]
Evaluating model performance with hard-swish activation function adjustments,
S. A. Pydimarry, S. M. Khairnar, S. G. Palacios, G. Sankaranarayanan, D. Hoagland, D. Nepomnayshy, and H. P. Nguyen, “Evaluating model performance with hard-swish activation function adjustments,” 2024. [Online]. Available: https://arxiv.org/abs/2410.06879
-
[66]
Swish: a self-gated activation function,
P. Ramachandran, B. Zoph, and Q. V . Le, “Swish: a self-gated activation function,”arXiv: Neural and Evolutionary Computing, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:196158220
work page 2017
-
[67]
arXiv preprint arXiv:2310.10537 , year=
B. D. Rouhani, R. Zhao, A. More, M. Hall, A. Khodamoradi, S. Deng, D. Choudhary, M. Cornea, E. Dellinger, K. Denolf, S. Dusan, V . Elango, M. Golub, A. Heinecke, P. James-Roxby, D. Jani, G. Kolhe, M. Langhammer, A. Li, L. Melnick, M. Mesmakhosroshahi, A. Rodriguez, M. Schulte, R. Shafipour, L. Shao, M. Siu, P. Dubey, P. Micikevicius, M. Naumov, C. Verrill...
-
[68]
Improving training stability for multitask ranking models in recommender systems,
J. Tang, Y . Drori, D. Chang, M. Sathiamoorthy, J. Gilmer, L. Wei, X. Yi, L. Hong, and E. H. Chi, “Improving training stability for multitask ranking models in recommender systems,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 4882–48...
-
[69]
Triton: an intermediate language and compiler for tiled neural network computations,
P. Tillet, H. T. Kung, and D. Cox, “Triton: an intermediate language and compiler for tiled neural network computations,” inProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, ser. MAPL 2019. New York, NY , USA: Association for Computing Machinery, 2019, p. 10–19. [Online]. Available: https://doi.org/10...
-
[70]
Torchao blockwise triton test,
TorchAO, “Torchao blockwise triton test,” https://github.com/pytorch/ ao/blob/main/test/kernel/test blockwise triton.py#L55, [Accessed 17-02- 2026]
work page 2026
-
[71]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[72]
Haq: Hardware-aware automated quantization with mixed precision,
K. Wang, Z. Liu, Y . Lin, J. Lin, and S. Han, “Haq: Hardware-aware automated quantization with mixed precision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8612–8620
work page 2019
-
[73]
arXiv preprint arXiv:2501.17116 , year=
R. Wang, Y . Gong, X. Liu, G. Zhao, Z. Yang, B. Guo, Z. Zha, 14 and P. Cheng, “Optimizing large language model training using fp4 quantization,” 2025. [Online]. Available: https://arxiv.org/abs/2501.17116
-
[74]
Dcn v2: Improved deep & cross network and practical lessons for web- scale learning to rank systems,
R. Wang, R. Shivanna, D. Cheng, S. Jain, D. Lin, L. Hong, and E. Chi, “Dcn v2: Improved deep & cross network and practical lessons for web- scale learning to rank systems,” inProceedings of the web conference 2021, 2021, pp. 1785–1797
work page 2021
-
[75]
Y . Wu and K. He, “Group normalization,” 2018. [Online]. Available: https://arxiv.org/abs/1803.08494
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[76]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” 2024. [Online]. Available: https: //arxiv.org/abs/2211.10438
-
[77]
Training deep learning recommendation model with quantized collective communications,
J. A. Yang, J. Park, S. Sridharan, and P. T. P. Tang, “Training deep learning recommendation model with quantized collective communications,” in Conference on Knowledge Discovery and Data Mining (KDD), 2020, p. 95
work page 2020
-
[78]
Interformer: Towards effective heterogeneous interaction learning for click-through rate prediction,
Z. Zeng, X. Liu, M. Hang, X. Liu, Q. Zhou, C. Yang, Y . Liu, Y . Ruan, L. Chen, Y . Chen, Y . Hao, J. Xu, J. Nie, X. Liu, B. Zhang, W. Wen, S. Yuan, K. Wang, W.-Y . Chen, Y . Han, H. Li, C. Yang, B. Long, P. S. Yu, H. Tong, and J. Yang, “Interformer: Towards effective heterogeneous interaction learning for click-through rate prediction,” 2024. [Online]. A...
-
[79]
Pre-train and search: Efficient embedding table sharding with pre-trained neural cost models,
D. Zha, L. Feng, L. Luo, B. Bhushanam, Z. Liu, Y . Hu, J. Nie, Y . Huang, Y . Tian, A. Kejariwalet al., “Pre-train and search: Efficient embedding table sharding with pre-trained neural cost models,”Proceedings of Machine Learning and Systems, vol. 5, 2023
work page 2023
-
[80]
J. Zhai, L. Liao, X. Liu, Y . Wang, R. Li, X. Cao, L. Gao, Z. Gong, F. Gu, J. He, Y . Lu, and Y . Shi, “Actions speak louder than words: Trillion- parameter sequential transducers for generative recommendations,” in Proceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kol...
work page 2024
-
[81]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.