Recognition: no theorem link
TLX: Hardware-Native, Evolvable MIMW GPU Compiler for Large-scale Production Environments
Pith reviewed 2026-05-15 05:05 UTC · model grok-4.3
The pith
TLX adds MIMW extensions to Triton so programmers can directly orchestrate multi-warp GPU execution, local memory, and async operations while keeping the blocked programming model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TLX realizes MIMW as an embedded extension to Triton that expresses orchestration at warp-group granularity while preserving the productive blocked programming model. It exposes explicit interfaces for multi-warp execution, local-memory orchestration, asynchronous operations, and cluster-aware control. This design supports substantial customization with limited development effort, stays competitive with state-of-the-art implementations, and has been used in large-scale production training and inference systems.
What carries the argument
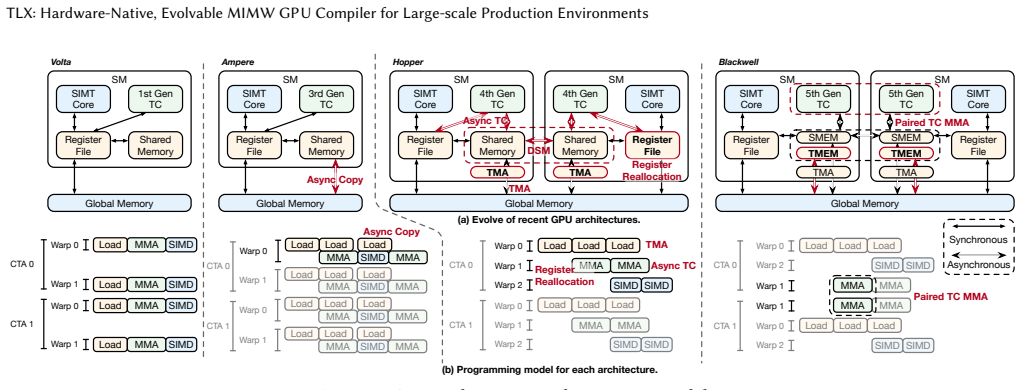
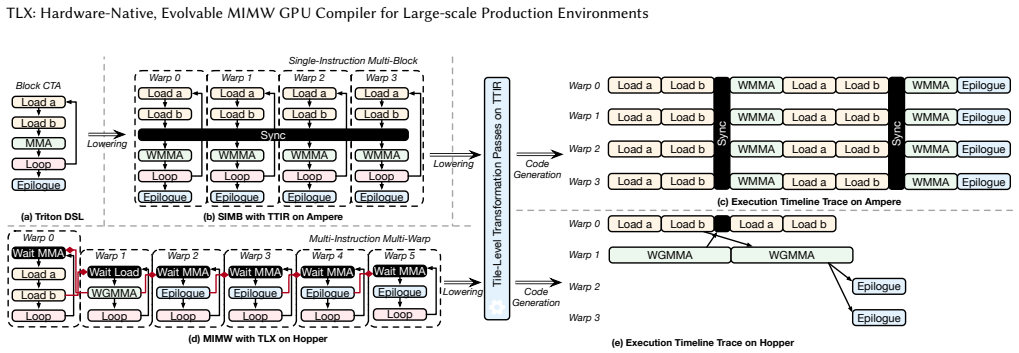
MIMW (Multi-Instruction, Multi-Warp), which expresses execution orchestration at warp-group granularity to coordinate hardware mechanisms without losing Triton's high-level blocked model.
If this is right
- Programmers can customize kernels for tensor-core and async hardware mechanisms without rewriting entire algorithms.
- Performance stays competitive with state-of-the-art hand-tuned implementations.
- Kernels written in TLX can be deployed directly into large-scale training and inference systems.
- The blocked programming model remains usable for regular computation while low-level controls are added only where needed.
Where Pith is reading between the lines
- Other high-level GPU languages could adopt similar warp-group abstractions to absorb future hardware changes without forcing programmers back to CUDA.
- Production teams might reduce the number of separate low-level code paths they maintain by routing more kernels through one evolvable compiler base.
- The open-source release lets external groups test whether the same interfaces work for new accelerator features not yet in current GPUs.
Load-bearing premise
The added explicit interfaces for multi-warp execution, local-memory orchestration, and asynchronous operations will not materially increase programmer burden or break compatibility with existing Triton code.
What would settle it
A side-by-side development-time measurement showing that equivalent performance requires substantially more code or time in TLX than in unmodified Triton or hand-written CUDA, or production logs revealing frequent compatibility breaks.
Figures










read the original abstract
Modern GPUs increasingly rely on specialized hardware units and asynchronous coordination mechanisms, so performance depends on orchestrating data movement, tensor-core computation, and synchronization rather than exposing more thread-level parallelism. This creates a programming-model tension: if too much execution structure is hidden, the compiler must catch up to new hardware mechanisms; if too much is exposed, the burden of orchestration falls back onto the programmer. We present TLX (Triton Low-level Language Extensions), built around MIMW (Multi-Instruction, Multi-Warp), which expresses orchestration at warp-group granularity while preserving Triton's productive blocked programming model for regular computation. TLX realizes this idea as an embedded extension to Triton, exposing explicit interfaces for multi-warp execution, local-memory orchestration, asynchronous operations, and cluster-aware control. Our evaluation shows that TLX supports substantial customization with limited development effort while remaining competitive with state-of-the-art implementations. TLX-authored kernels have been deployed in large-scale training and inference production systems. Our code is open sourced at https://github.com/facebookexperimental/triton.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TLX (Triton Low-level Language Extensions), an embedded extension to the Triton language built around the MIMW (Multi-Instruction, Multi-Warp) model. TLX exposes explicit interfaces for multi-warp execution, local-memory orchestration, asynchronous operations, and cluster control while aiming to preserve Triton's blocked programming model. The central claims are that TLX enables substantial hardware customization with limited programmer effort, delivers performance competitive with state-of-the-art implementations, and has been successfully deployed in large-scale production training and inference systems. The code is open-sourced.
Significance. If the performance and effort claims hold, TLX would represent a practical advance in GPU compiler design by bridging high-level productivity with hardware-native control for modern asynchronous and specialized units. The reported production deployments and open-source release provide concrete evidence of real-world applicability in large-scale environments.
major comments (2)
- [Evaluation] Evaluation section: the abstract asserts that 'evaluation shows that TLX supports substantial customization with limited development effort while remaining competitive with state-of-the-art implementations,' yet no quantitative metrics, named baselines, performance tables, or methodology details appear in the manuscript. This absence leaves the central competitiveness claim without visible supporting evidence.
- [Abstract and §1] Abstract and §1: the claim of 'substantial customization with limited development effort' is stated without any supporting data such as lines-of-code counts, developer-hours, before/after kernel sizes, or compatibility tests showing that existing Triton kernels compile and run unchanged.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support. We agree that the current manuscript under-emphasizes quantitative evidence and will revise accordingly to include detailed evaluation data, metrics, and supporting measurements while preserving the paper's core claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract asserts that 'evaluation shows that TLX supports substantial customization with limited development effort while remaining competitive with state-of-the-art implementations,' yet no quantitative metrics, named baselines, performance tables, or methodology details appear in the manuscript. This absence leaves the central competitiveness claim without visible supporting evidence.
Authors: We acknowledge this gap. The revised manuscript will add a dedicated evaluation section containing: (1) named baselines including hand-optimized CUDA kernels and prior Triton extensions, (2) performance tables with absolute and relative metrics (e.g., TFLOPS, latency, throughput) measured on production hardware, (3) explicit methodology describing measurement setup, warm-up, and statistical reporting, and (4) results demonstrating competitiveness. These additions will directly substantiate the competitiveness claim. revision: yes
-
Referee: [Abstract and §1] Abstract and §1: the claim of 'substantial customization with limited development effort' is stated without any supporting data such as lines-of-code counts, developer-hours, before/after kernel sizes, or compatibility tests showing that existing Triton kernels compile and run unchanged.
Authors: We will expand §1 and the evaluation to include quantitative effort metrics: lines-of-code counts for representative kernels written in TLX versus equivalent CUDA or low-level Triton, approximate developer-hour estimates drawn from our internal development logs, before/after kernel size comparisons, and compatibility test results confirming that unmodified Triton kernels continue to compile and execute correctly when TLX extensions are present but unused. This data will be presented in a new table and accompanying text. revision: yes
Circularity Check
No significant circularity; claims are descriptive system assertions
full rationale
The paper describes a compiler extension (TLX/MIMW) and asserts support for customization, competitiveness, and production deployment. No equations, fitted parameters, or derivation chain exist that could reduce to self-definition or self-citation. Evaluation and deployment statements are presented as empirical outcomes rather than predictions derived from the system's own inputs. No load-bearing self-citations or ansatz smuggling appear in the provided text. This is a standard non-circular systems paper whose central claims rest on implementation and usage evidence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern GPUs increasingly rely on specialized hardware units and asynchronous coordination mechanisms rather than exposing more thread-level parallelism.
invented entities (1)
-
MIMW (Multi-Instruction, Multi-Warp)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices. 2025. Introducing AMD CDNA™4 Archi- tecture.https://www.amd.com/content/dam/amd/en/documents/ instinct-tech-docs/white-papers/amd-cdna-4-architecture- whitepaper.pdf. White paper, accessed 2026-04-14
work page 2025
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normalization.arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Michael Bauer, Henry Cook, and Brucek Khailany. 2011. CudaDMA: optimizing GPU memory bandwidth via warp specialization. InPro- ceedings of 2011 International Conference for High Performance Comput- ing, Networking, Storage and Analysis(Seattle, Washington)(SC ’11). Association for Computing Machinery, New York, NY, USA, Article 12, 11 pages. doi:10.1145/2...
-
[4]
Michael Bauer, Sean Treichler, and Alex Aiken. 2014. Singe: leveraging warp specialization for high performance on GPUs. InProceedings of the 19th ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, Orlando Florida USA, 119–130. doi:10. 1145/2555243.2555258
- [5]
-
[6]
Hongzheng Chen, Bin Fan, Alexander Collins, Bastian Hagedorn, Evghenii Gaburov, Masahiro Masuda, Matthew Brookhart, Chris Sul- livan, Jason Knight, Zhiru Zhang, et al. 2026. Tawa: Automatic warp specialization for modern gpus with asynchronous references. In2026 IEEE/ACM International Symposium on Code Generation and Optimiza- tion (CGO). IEEE, 255–267
work page 2026
-
[7]
James Clift, Dmitry Doryn, Daniel Murfet, and James Wallbridge
- [8]
-
[9]
Crago, Sana Damani, Karthikeyan Sankaralingam, and Stephen W
Neal C. Crago, Sana Damani, Karthikeyan Sankaralingam, and Stephen W. Keckler. 2024. WASP: Exploiting GPU Pipeline Paral- lelism with Hardware-Accelerated Automatic Warp Specialization. In2024 IEEE International Symposium on High-Performance Com- puter Architecture (HPCA). IEEE, Edinburgh, United Kingdom, 1–16. doi:10.1109/HPCA57654.2024.00086
-
[10]
Dao-AILab. 2026. QuACK: A Quirky Assortment of CuTe Kernels. https://github.com/Dao-AILab/quack. GitHub repository, accessed 2026-04-15
work page 2026
-
[11]
Frederica Darema. 2001. The SPMD model: past, present and future. 1. doi:10.1007/3-540-45417-9_1
-
[12]
Kazushige Goto and Robert A. van de Geijn. 2008. Anatomy of High- Performance Matrix Multiplication.ACM Trans. Math. Software34, 3, Article 12 (2008). doi:10.1145/1356052.1356053
-
[13]
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sa- bet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkow- icz, and Olli Saarikivi. 2022. Breaking the computation and communica- tion abstraction barrier in distributed machine learning workloads. In Proceedings of the 27th ACM International Conference on Architectural Support for Pro...
work page 2022
-
[14]
Erik Lindholm, John Nickolls, Stuart Oberman, and John Montrym
-
[15]
NVIDIA Tesla: A Unified Graphics and Computing Architecture. IEEE Micro28, 2 (2008), 39–55. doi:10.1109/MM.2008.31
- [16]
-
[17]
NVIDIA. 2023.CUTLASS.https://github.com/NVIDIA/cutlass/tree/ v3.0.0CUDA Templates for Linear Algebra Subroutines
work page 2023
-
[18]
2020.NVIDIA A100 Tensor Core GPU Architecture
NVIDIA Corporation. 2020.NVIDIA A100 Tensor Core GPU Architecture. Technical Report. NVIDIA Corporation. https://images.nvidia.com/aem-dam/en-zz/Solutions/data- center/nvidia-ampere-architecture-whitepaper.pdfWhite pa- per on the NVIDIA Ampere GPU architecture
work page 2020
-
[19]
NVIDIA Corporation. 2024. NVIDIA Blackwell Architecture. https://www.nvidia.com/en-us/data-center/technologies/blackwell- architecture/. Official NVIDIA Blackwell architecture overview. 12 TLX: Hardware-Native, Evolvable MIMW GPU Compiler for Large-scale Production Environments
work page 2024
-
[20]
2026.CUDA C++ Programming Guide
NVIDIA Corporation. 2026.CUDA C++ Programming Guide. NVIDIA Corporation.https://docs.nvidia.com/cuda/cuda-c-programming- guide/Version 13.2
work page 2026
-
[21]
NVIDIA Corporation. 2026.CuTe DSL. NVIDIA Corpora- tion.https://docs.nvidia.com/cutlass/latest/media/docs/pythonDSL/ cute_dsl.htmlNVIDIA CUTLASS documentation for the CuTe domain- specific language
work page 2026
-
[22]
NVIDIA Developer Blog. 2022. NVIDIA Hopper Architecture In- Depth.https://developer.nvidia.com/blog/nvidia-hopper-architecture- in-depth/. Overview of the NVIDIA Hopper GPU architecture
work page 2022
-
[23]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala
-
[24]
InAdvances in Neural Information Processing Systems 32
PyTorch: An Imperative Style, High-Performance Deep Learn- ing Library. InAdvances in Neural Information Processing Systems 32. 8024–8035
-
[25]
PyTorch Contributors. 2026. PyTorch C++ API: ATen.https://docs. pytorch.org/cppdocs/. Accessed: 2026-04-14
work page 2026
- [26]
-
[27]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ra- mani, and Tri Dao. 2024. Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems37 (2024), 68658–68685
work page 2024
- [28]
- [29]
-
[30]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computa- tions. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. 10–19
work page 2019
-
[31]
Philippe Tillet, H. T. Kung, and David Cox. 2019. Triton: an interme- diate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages(Phoenix, AZ, USA) (MAPL 2019). Association for Computing Machinery, New York, NY, USA, 10–19. doi:10.1145/3315508.3329973
-
[32]
Triton Team. 2025. Gluon: A Lower-Level GPU Programming Lan- guage in Triton.https://github.com/triton-lang/triton/blob/main/ python/tutorials/gluon/01-intro.py. Official Triton Gluon tutorial
work page 2025
- [33]
-
[34]
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, Sameer Kumar, Tongfei Guo, Yuanzhong Xu, and Zongwei Zhou. 2022. Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models. In Proceedings of the 28th ACM International...
-
[35]
Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. 2026. FlashAttention-4: Algorithm and Ker- nel Pipelining Co-Design for Asymmetric Hardware Scaling.arXiv preprint arXiv:2603.05451(2026). 13 Y. Guan et al. A Evaluation Settings This section summarizes the exact workload settings used by the evaluation figures in the main t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.