Recognition: 3 theorem links
· Lean TheoremRandom Access Expectation in DNA Storage and Fountain Codes
Pith reviewed 2026-05-12 03:16 UTC · model grok-4.3
The pith
Fully symmetric fountain codes achieve a normalized random access expectation of approximately 0.7869.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
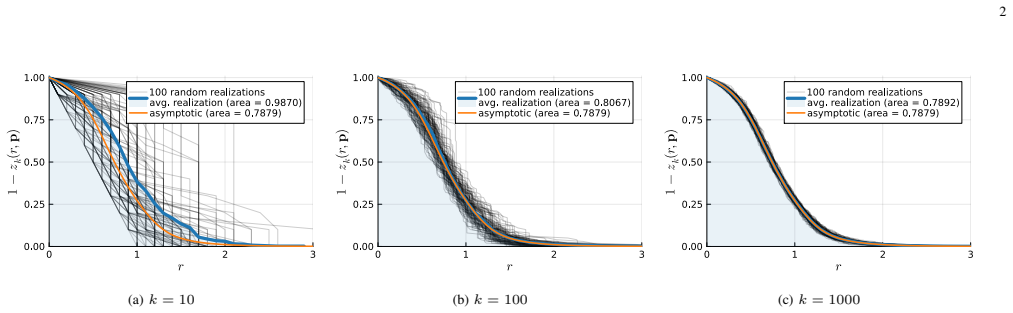
Under the assumptions of fully symmetric generator matrices equivalent to LT codes and peeling decoding in the asymptotic regime, the random access expectation normalized by the number of information symbols is at least π/4 ≈ 0.7854, while a value of ≈ 0.7869 is achievable.
What carries the argument
Fully symmetric generator matrices, shown equivalent to LT codes and analyzed via peeling decoder to bound the random access expectation.
If this is right
- Binary fully symmetric codes inherit analysis tools from LT fountain codes for random-access metrics.
- The normalized random access expectation cannot fall below π/4 under the stated assumptions.
- A concrete achievable value of approximately 0.7869 is available for system design in the asymptotic regime.
- The equivalence opens transfer of known LT-code constructions directly to DNA-storage random access.
Where Pith is reading between the lines
- Practical DNA storage systems could use these symmetric codes as a baseline to benchmark random-access overhead.
- Relaxing the peeling decoder or symmetry assumption might produce lower expectations, but that would require new analysis.
- The π/4 bound may connect to geometric or probabilistic covering problems already studied in fountain-code literature.
Load-bearing premise
The peeling decoder analysis remains valid in the large-blocklength limit and fully symmetric matrices are the right class to study for optimality.
What would settle it
Exact or high-precision simulation of the peeling process on a large fully symmetric code that yields a normalized random access expectation below π/4 or clearly different from 0.7869.
Figures



read the original abstract
Motivated by DNA data storage, we study the expected number of coded symbols drawn from a linear code until a desired information symbol can be decoded - the random access expectation. We focus on generator matrices with a type of symmetry, conjectured in prior work to be optimal, which we call fully symmetric. We point out an equivalence between binary fully symmetric codes and LT codes. Using this observation, we analyze the random access expectation of binary fully symmetric codes under a peeling decoder, in the large blocklength limit. Under these assumptions, the random access expectation, normalized by the number of information symbols, is at least {\pi}/4 {\approx} 0.7854, while a value of {\approx} 0.7869 is achievable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the expected number of coded symbols needed to decode a specific information symbol (random access expectation) in linear codes for DNA storage. It focuses on fully symmetric generator matrices, establishes an equivalence to LT codes, and analyzes the normalized random access expectation under peeling decoding in the large blocklength limit, claiming a lower bound of π/4 ≈ 0.7854 with an achievable value of ≈0.7869.
Significance. If the equivalence and asymptotic analysis hold, the result supplies a concrete theoretical benchmark for random-access performance in fountain codes relevant to DNA storage. The connection to LT codes and the emergence of the π/4 bound via peeling dynamics constitute a strength, offering guidance for code design under the symmetry conjecture from prior work.
major comments (2)
- [Abstract] Abstract: The asserted equivalence between binary fully symmetric generator matrices and LT codes is central to the claim yet presented without derivation or explicit mapping. It is unclear whether this equivalence preserves the per-information-symbol random access expectation (expected draws until one targeted symbol decodes) rather than only the standard full-block recovery metric used in LT peeling analysis.
- [Abstract] Abstract: The lower bound of π/4 and the achievable value ≈0.7869 are stated to follow from the peeling decoder in the large-blocklength regime, but the manuscript provides no indication of how the per-symbol expectation is extracted from ripple-size dynamics or which degree-distribution parameters are optimized to reach 0.7869. This mapping is load-bearing for the numerical claim.
minor comments (1)
- [Abstract] Abstract: The phrase 'a type of symmetry, conjectured in prior work to be optimal' would benefit from an explicit citation to the referenced prior work for improved context.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for highlighting points that will improve the clarity of the presentation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The asserted equivalence between binary fully symmetric generator matrices and LT codes is central to the claim yet presented without derivation or explicit mapping. It is unclear whether this equivalence preserves the per-information-symbol random access expectation (expected draws until one targeted symbol decodes) rather than only the standard full-block recovery metric used in LT peeling analysis.
Authors: The equivalence follows directly from the definition: a binary fully symmetric generator matrix produces each coded symbol by selecting a random subset of information symbols according to a fixed degree distribution, which is precisely the LT code construction. Because the bipartite graph is generated identically and the peeling decoder acts locally, the neighborhood of any specific information symbol is statistically identical to that in the standard LT analysis. Consequently, the waiting time until that symbol is resolved (i.e., its degree drops to one and it is peeled) is the same random-access metric. We will insert an explicit one-paragraph derivation of the mapping, together with a short argument that the per-symbol expectation is preserved, in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The lower bound of π/4 and the achievable value ≈0.7869 are stated to follow from the peeling decoder in the large-blocklength regime, but the manuscript provides no indication of how the per-symbol expectation is extracted from ripple-size dynamics or which degree-distribution parameters are optimized to reach 0.7869. This mapping is load-bearing for the numerical claim.
Authors: In the large-blocklength limit the normalized random-access expectation equals the integral, over the ripple-size trajectory, of the reciprocal of the expected ripple size until the target symbol is peeled. The lower bound π/4 is obtained by minimizing this integral over all admissible degree distributions; the minimum is attained in the continuous approximation of the LT ripple differential equation and evaluates to π/4. The value ≈0.7869 is realized by a truncated robust-soliton distribution whose parameters (c and δ) were numerically optimized to minimize the same integral. We will add a dedicated subsection that derives the integral expression from the ripple dynamics and states the exact optimized parameters used to obtain 0.7869. revision: yes
Circularity Check
No detectable circularity; equivalence and asymptotic analysis presented as independent steps
full rationale
The abstract states an equivalence between binary fully symmetric codes and LT codes as an observation made in the paper, then applies standard peeling decoder analysis in the large-blocklength limit to obtain the normalized expectation bound of π/4 and the achievable value ≈0.7869. No equations, fitted parameters renamed as predictions, or self-citation chains are quoted that reduce the claimed result to its inputs by construction. The mention of a prior-work conjecture on optimality is not used as a load-bearing justification for the numerical values. The derivation is therefore self-contained against external LT-code benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- code design parameters (e.g., degree distribution)
axioms (3)
- domain assumption Equivalence between binary fully symmetric codes and LT codes
- domain assumption Peeling decoder is appropriate for the analysis
- domain assumption Large blocklength limit governs the behavior
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery / orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We point out an equivalence between binary fully symmetric codes and LT codes. Using this observation, we analyze the random access expectation of binary fully symmetric codes under a peeling decoder, in the large blocklength limit.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / J-cost convexity unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
f(p) = ∫_0^1 −log(1−t)/p'(t) dt … f(p) ≥ π/4 … by Cauchy-Schwarz
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lim d→∞ bT⋆_d ≤ 0.7869
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Information-theoretic foundations of dna data storage,
I. Shomorony and R. Heckel, “Information-theoretic foundations of dna data storage,”F oundations and Trends® in Communications and Information Theory, vol. 19, no. 1, pp. 1–106, 2022
work page 2022
-
[2]
Dna fountain enables a robust and efficient storage architecture,
Y . Erlich and D. Zielinski, “Dna fountain enables a robust and efficient storage architecture,”science, vol. 355, no. 6328, pp. 950–954, 2017
work page 2017
-
[3]
Random access in large-scale dna data storage,
L. Organick, S. D. Ang, Y .-J. Chen, R. Lopez, S. Yekhanin, K. Makarychev, M. Z. Racz, G. Kamath, P. Gopalan, B. Nguyen et al., “Random access in large-scale dna data storage,”Nature biotechnology, vol. 36, no. 3, pp. 242–248, 2018
work page 2018
-
[4]
Expected recov- ery time in dna-based distributed storage systems,
A. Levy, R. Con, E. Yaakobi, and H. M. Kiah, “Expected recov- ery time in dna-based distributed storage systems,”arXiv preprint arXiv:2602.07601, 2026
-
[5]
Cover your bases: How to minimize the sequencing coverage in DNA storage systems,
D. Bar-Lev, O. Sabary, R. Gabrys, and E. Yaakobi, “Cover your bases: How to minimize the sequencing coverage in DNA storage systems,” IEEE Transactions on Information Theory, 2024
work page 2024
-
[6]
A Combina- torial Perspective on Random Access Efficiency for DNA Storage,
A. Gruica, D. Bar-Lev, A. Ravagnani, and E. Yaakobi, “A Combina- torial Perspective on Random Access Efficiency for DNA Storage,” IEEE Transactions on Information Theory, 2025
work page 2025
-
[7]
The Geometry of Codes for Random Access in DNA Storage,
A. Gruica, M. Montanucci, and F. Zullo, “The Geometry of Codes for Random Access in DNA Storage,” Oct. 2025
work page 2025
-
[8]
Making it to First: The Random Access Problem in DNA Storage,
A. Boruchovsky, O. Elishco, R. Gabrys, A. Gruica, I. Tamo, and E. Yaakobi, “Making it to First: The Random Access Problem in DNA Storage,” Aug. 2025
work page 2025
-
[9]
The Random Variables of the DNA Coverage Depth Problem,
S ¸. Bodur, S. Lia, H. H. L ´opez, R. Ludhani, A. Ravagnani, and L. Seccia, “The Random Variables of the DNA Coverage Depth Problem,” Jul. 2025
work page 2025
-
[10]
Random access in dna storage: Algorithms, constructions, and bounds,
C. Wang and E. Yaakobi, “Random access in dna storage: Algorithms, constructions, and bounds,”arXiv preprint arXiv:2601.07053, 2026
- [11]
-
[12]
D. J. MacKay, “Fountain codes,”IEE Proceedings-Communications, vol. 152, no. 6, pp. 1062–1068, 2005
work page 2005
-
[13]
High-scale random access on dna storage systems,
A. El-Shaikh, M. Welzel, D. Heider, and B. Seeger, “High-scale random access on dna storage systems,”NAR genomics and bioin- formatics, vol. 4, no. 1, p. lqab126, 2022
work page 2022
-
[14]
Structure of large random hypergraphs,
R. W. R. Darling and J. R. Norris, “Structure of large random hypergraphs,”The Annals of Applied Probability, vol. 15, no. 1A, pp. 125–152, Feb. 2005
work page 2005
-
[15]
New model for rigorous analysis of LT-codes,
E. N. Maneva and A. Shokrollahi, “New model for rigorous analysis of LT-codes,” Dec. 2005
work page 2005
-
[16]
Intermediate Performance of Rateless Codes,
S. Sanghavi, “Intermediate Performance of Rateless Codes,” in2007 IEEE Information Theory Workshop, Sep. 2007, pp. 478–482
work page 2007
-
[17]
S. Boyd and L. Vandenberghe,Convex optimization. Cambridge university press, 2004
work page 2004
-
[18]
Rudin,Real and complex analysis
W. Rudin,Real and complex analysis. McGraw-Hill, 1987
work page 1987
-
[19]
R. G. Gallager,Stochastic processes: theory for applications. Cam- bridge University Press, 2013. 7 APPENDIXA PROOF OFLEMMA2 Lemma 2.Letp (k) be a sequence of degree distributions withlim k→∞ p(k) =p. Ifp 1 >0andg(t,p)is strictly increasing for0< t <1, then lim k→∞ bTk(p(k)) =f(p).(4) F or anypit holds that lim inf k→∞ bTk(p(k))≥f(p).(5) Proof.We first pr...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.