Recognition: 3 theorem links
· Lean TheoremInterpretable EEG Microstate Discovery via Variational Deep Embedding: A Systematic Architecture Search with Multi-Quadrant Evaluation
Pith reviewed 2026-05-15 07:10 UTC · model grok-4.3
The pith
A convolutional variational deep embedding model discovers stable EEG microstates through systematic architecture search rather than increased model scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
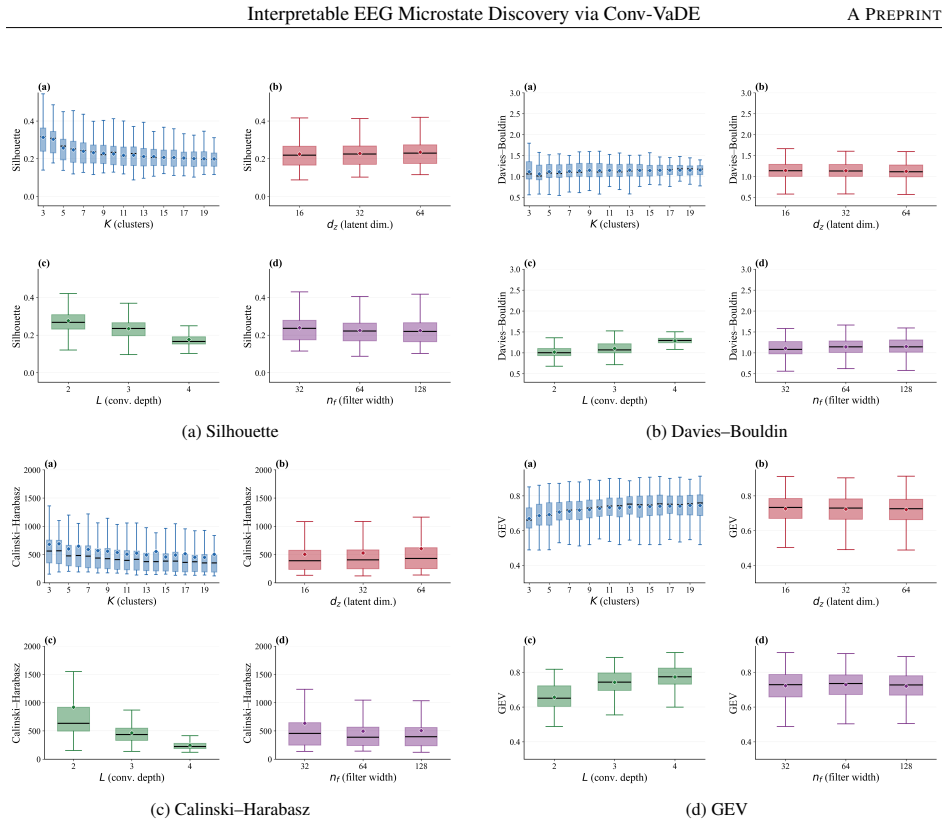
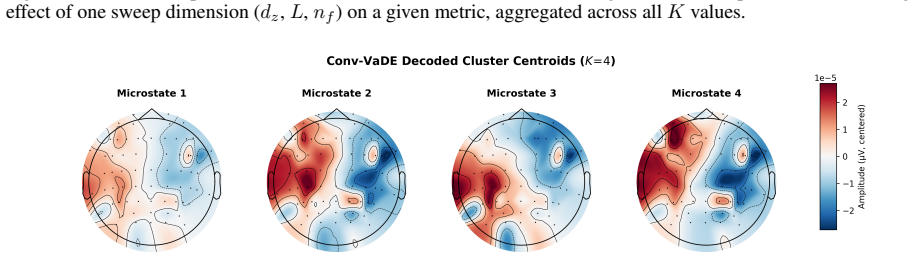
Conv-VaDE jointly learns topographic reconstruction and probabilistic soft clustering in a shared latent space, replacing opaque hard partitioning with generative decoding of cluster prototypes into verifiable scalp topographies. A systematic four-dimensional grid search over K from 3 to 20, latent dimensionality, network depth, and channel width on the LEMON dataset shows that depth L equals 4 appears in every top-performing configuration, yielding a best-case GEV of 0.730 and silhouette of 0.229 at K equals 4, where moderately deep networks with compact channel widths and small latent dimensionality dominate across the full range of K.
What carries the argument
The Conv-VaDE model, which performs joint convolutional variational reconstruction and deep embedding to enable probabilistic soft assignment together with generative decoding of latent cluster prototypes into scalp topographies.
If this is right
- Network depth of four layers consistently ranks among the best configurations across all tested cluster counts.
- Compact channel widths and small latent dimensionality outperform wider or deeper alternatives for stability and explained variance.
- The polarity-invariance scheme and soft probabilistic assignment improve topographic template formation over hard clustering.
- Principled search over architectural choices, rather than simple scaling of model capacity, determines the quality of learned microstate representations.
- The resulting models produce generative reconstructions that can be inspected as scalp topographies for each discovered cluster.
Where Pith is reading between the lines
- The same search procedure could be applied to task-based or clinical EEG recordings to test whether the identified depth and latent-size preferences hold outside resting-state data.
- Because the model produces explicit generative decodings, it may support downstream neurophysiological validation by comparing decoded prototypes against known functional networks from fMRI or source localization.
- Smaller, high-performing configurations found by the search could be deployed in low-power wearable EEG devices for real-time microstate monitoring.
- The emphasis on architecture search suggests that similar systematic sweeps over depth and width may improve variational embedding models for other time-series clustering tasks such as sleep staging or seizure detection.
Load-bearing premise
That the generative decoding of latent cluster prototypes produces verifiable scalp topographies that meaningfully reflect discrete functional brain states and that GEV and silhouette scores adequately measure interpretability without direct comparison to conventional methods.
What would settle it
A side-by-side run on the same LEMON dataset in which modified k-means achieves higher global explained variance or better clustering stability than the best Conv-VaDE configuration would falsify the claim that architecture search is the decisive factor.
Figures



read the original abstract
EEG microstate analysis segments continuous brain electrical activity into brief, quasi-stable topographic configurations that reflect discrete functional brain states. Conventional approaches such as Modified K-Means operate directly in electrode space with hard assignment, offering no learned latent representation, no generative decoder, and no mechanism to decode latent configurations into verifiable scalp topographies, limiting both model transparency and interpretability. To address this, we present a Convolutional Variational Deep Embedding (Conv-VaDE) model that jointly learns topographic reconstruction and probabilistic soft clustering in a shared latent space. Conv-VaDE enables generative decoding of cluster prototypes into verifiable scalp topographies, replacing opaque hard partitioning with probabilistic soft assignment. A polarity invariance scheme and a four-dimensional grid search over cluster count (K from 3 to 20), latent dimensionality, network depth, and channel width are conducted to systematically reveal how each architectural design choice shapes the quality, stability, and interpretability of learned EEG microstate representations. The model is evaluated on the LEMON resting-state eyes-closed EEG dataset with ten participants using topographic template formation, clustering stability, and global explained variance (GEV). The architecture search reveals that depth L = 4 appears consistently across all 18 best-performing configurations, yielding a best-case GEV of 0.730 and a silhouette of 0.229 at K = 4 across the model sweeps, where moderately deep networks with compact channel widths and small latent dimensionality dominate across the full K range. These results establish that principled architecture search, rather than model scale, is the key to interpretable and stable EEG microstate discovery via variational deep embedding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Convolutional Variational Deep Embedding (Conv-VaDE) model for EEG microstate discovery that learns a latent representation for probabilistic soft clustering and generative decoding of topographic prototypes. Through a four-dimensional grid search over K (3-20), latent dim, depth L, and channel width on the LEMON eyes-closed EEG data from 10 participants, it identifies L=4 as dominant across best configurations, achieving peak GEV=0.730 and silhouette=0.229 at K=4, and concludes that principled architecture search, not model scale, drives interpretable and stable microstate representations.
Significance. If validated with baselines, the approach could advance EEG microstate analysis by providing generative, interpretable alternatives to hard clustering methods like Modified K-Means. The emphasis on systematic search over hyperparameters is a strength, but without direct comparisons or physiological validation, the significance remains potential rather than demonstrated.
major comments (3)
- [Abstract] Abstract: The central claim that 'principled architecture search, rather than model scale, is the key to interpretable and stable EEG microstate discovery' is unsupported because the manuscript supplies no quantitative GEV, silhouette, or stability results for Modified K-Means (or any conventional baseline) on the identical 10-participant LEMON eyes-closed segments.
- [Abstract] Abstract: The reported best-case metrics (GEV 0.730, silhouette 0.229 at K=4) are presented without error bars, statistical significance tests, or any external verification that the generative-decoded prototypes match established neurophysiological microstate topographies (e.g., standard classes A–D).
- [Evaluation] Evaluation (architecture search results): The statement that depth L=4 'appears consistently across all 18 best-performing configurations' is load-bearing for the architecture-search conclusion, yet no ablation isolating the contribution of depth versus latent dimensionality or channel width is provided, leaving open whether the dominance is an artifact of the chosen grid.
minor comments (2)
- [Abstract] Abstract: Define the polarity invariance scheme explicitly and state how it is enforced during training and prototype decoding.
- [Methods] Methods: Report the number of random seeds or restarts used for the grid search and stability metrics to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to strengthen the claims with additional baselines, statistical reporting, and ablations where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'principled architecture search, rather than model scale, is the key to interpretable and stable EEG microstate discovery' is unsupported because the manuscript supplies no quantitative GEV, silhouette, or stability results for Modified K-Means (or any conventional baseline) on the identical 10-participant LEMON eyes-closed segments.
Authors: We agree that direct quantitative comparisons would strengthen the central claim. While the manuscript emphasizes the generative and soft-clustering advantages of Conv-VaDE, we will add results for Modified K-Means (and potentially other baselines) on the exact same 10-participant LEMON eyes-closed segments, reporting GEV, silhouette, and stability metrics for side-by-side evaluation in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The reported best-case metrics (GEV 0.730, silhouette 0.229 at K=4) are presented without error bars, statistical significance tests, or any external verification that the generative-decoded prototypes match established neurophysiological microstate topographies (e.g., standard classes A–D).
Authors: We will add error bars by recomputing metrics across multiple random seeds and data splits, reporting means and standard deviations with appropriate statistical tests for any comparisons. For physiological validation, the generative decoder enables direct topographic inspection, but we did not perform quantitative correlation or matching against standard A–D classes; we will include visual prototype comparisons in the revision and explicitly note the absence of formal neurophysiological matching as a limitation. revision: partial
-
Referee: [Evaluation] Evaluation (architecture search results): The statement that depth L=4 'appears consistently across all 18 best-performing configurations' is load-bearing for the architecture-search conclusion, yet no ablation isolating the contribution of depth versus latent dimensionality or channel width is provided, leaving open whether the dominance is an artifact of the chosen grid.
Authors: The four-dimensional grid search covered a broad range of hyperparameter combinations, with L=4 emerging in all top configurations. To isolate depth's specific contribution and rule out grid artifacts, we will add a targeted ablation study in the revision that fixes K, latent dimension, and channel width while systematically varying depth, reporting the resulting GEV and silhouette trends. revision: yes
Circularity Check
No significant circularity; derivation relies on standard external metrics
full rationale
The paper conducts an explicit grid search over architectural choices (K, latent dimensionality, depth L, channel width) and reports performance via GEV and silhouette score. These metrics are computed from the input EEG data and the resulting cluster assignments or reconstructions, independent of any internal model parameters or fitted hyperparameters. No step in the abstract or described method reduces a claimed prediction to a quantity defined solely by the search itself, nor does any load-bearing premise rest on a self-citation chain or an ansatz smuggled from prior author work. The central assertion that architecture search outperforms scale is an empirical observation across the sweep rather than a definitional equivalence. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (4)
- cluster count K =
4
- latent dimensionality
- network depth L =
4
- channel width
axioms (2)
- standard math Variational inference with ELBO provides a tractable training objective for the generative clustering model
- domain assumption EEG topographic maps can be clustered into discrete microstates that represent functional brain states
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Polarity invariance ... Lrecon = min(MSE(ˆx,x),MSE( ˆx,−x)) ... total loss L=Lrecon +βLKL + ...
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
four-dimensional grid search over cluster count (K from 3 to 20), latent dimensionality, network depth, and channel width
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
best-case GEV of 0.730 and a silhouette of 0.229 at K=4
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lehmann, D. and Pascual-Marqui, R. D. and Michel, C. , title =. 2009 , journal =
work page 2009
-
[2]
Michel and Thomas Koenig , title =
Christoph M. Michel and Thomas Koenig , title =. NeuroImage , volume =
-
[3]
Frontiers in Computational Neuroscience , year =
von Wegner, Frederic and Knaut, Paul and Laufs, Helmut , title =. Frontiers in Computational Neuroscience , year =
-
[4]
Poulsen, Andreas Trier and Pedroni, Andreas and Langer, Nicolas and Hansen, Lars Kai , title =. 2018 , journal =
work page 2018
-
[5]
Pycrostates: a Python library to study EEG microstates , journal =
F. Pycrostates: a Python library to study EEG microstates , journal =
-
[6]
and Kochi, Kieko and Hell, Daniel and Koukkou, Martha , title =
Koenig, Thomas and Lehmann, Dietrich and Merlo, Marco C. and Kochi, Kieko and Hell, Daniel and Koukkou, Martha , title =. European Archives of Psychiatry and Clinical Neuroscience , year =
-
[7]
Thomas Koenig and Leslie Prichep and Dietrich Lehmann and Pedro Valdes Sosa and Elisabeth Braeker and Horst Kleinlogel and Robert Isenhart and E.Roy John , title =. NeuroImage , volume =
- [8]
-
[9]
and Deccy, Stephanie and Ironside, Maria L
Murphy, Michael and Whitton, Alexis E. and Deccy, Stephanie and Ironside, Maria L. and Rutherford, Aava and Beltzer, Miranda and Sacchet, Matthew and Pizzagalli, Diego A. , title =. Neuropsychopharmacology , year =
-
[10]
Journal of Neural Engineering , year =
Duc, Nguyen Thanh and Lee, Boreom , title =. Journal of Neural Engineering , year =
-
[11]
Sikka, Ashish and Jamalabadi, Hamidreza and Krylova, Marina and Alizadeh, Sarah and van der Meer, Johan N. and Danyeli, Lena and Deliano, Matthias and Vicheva, Petya and Hahn, Tim and Koenig, Thomas and Bathula, Deepti R. and Walter, Martin , title =. Human Brain Mapping , year =
-
[12]
Journal of Neural Engineering , year =
Zhao, Qinglin and Cui, Kunbo and Zhang, Lixin and Wu, Zhongqing and Jiang, Hua and Zhao, Mingqi and Hu, Bin , title =. Journal of Neural Engineering , year =
-
[13]
Convolutional Autoencoder-Based Dimensionality Reduction for EEG Microstate Analysis , booktitle =
Thukral, Sanat and Raufi, Bujar and Bo. Convolutional Autoencoder-Based Dimensionality Reduction for EEG Microstate Analysis , booktitle =. 2025 , organization =
work page 2025
- [14]
-
[15]
Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI) , pages =
Jiang, Zhuxi and Zheng, Yin and Tan, Huachun and Tang, Bangsheng and Zhou, Hanning , title =. Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI) , pages =
-
[16]
Fu, Hao and Li, Chunyuan and Liu, Xiaodong and Gao, Jianfeng and Celikyilmaz, Asli and Carin, Lawrence , title =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics , pages =
work page 2019
-
[17]
Simple, Scalable, and Stable Variational Deep Clustering , booktitle =
Cao, Lele and Asadi, Sahar and Zhu, Wenfei and Schmidli, Christian and Sj. Simple, Scalable, and Stable Variational Deep Clustering , booktitle =. 2020 , organization =
work page 2020
-
[18]
Cristovao, Paulino and Nakada, Hidemoto and Tanimura, Yusuke and Asoh, Hideki , title =. IEEE Access , year =
-
[19]
Available at SSRN 5427958 , year =
Scrivano, Arimondo , title =. Available at SSRN 5427958 , year =
-
[20]
Babayan, Anahit and Erbey, Miray and Kumral, Deniz and Reinelt, Janis D and Reiter, Andrea MF and R. A mind-brain-body dataset of MRI, EEG, cognition, emotion, and peripheral physiology in young and old adults , journal =
-
[21]
Nature Machine Intelligence , volume =
Rudin, Cynthia , title =. Nature Machine Intelligence , volume =
-
[22]
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos , title =. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =
-
[23]
Advances in Neural Information Processing Systems , volume =
Lundberg, Scott M and Lee, Su-In , title =. Advances in Neural Information Processing Systems , volume =
- [24]
-
[25]
International Conference on Machine Learning , pages =
Xie, Junyuan and Girshick, Ross and Farhadi, Ali , title =. International Conference on Machine Learning , pages =
-
[26]
International Joint Conference on Artificial Intelligence , pages =
Guo, Xifeng and Gao, Long and Liu, Xinwang and Yin, Jianping , title =. International Joint Conference on Artificial Intelligence , pages =
-
[27]
Examining the size of the latent space of convolutional variational autoencoders trained with spectral topographic maps of EEG frequency bands , author=. IEEE Access , volume=. 2022 , publisher=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.