Recognition: 2 theorem links
· Lean TheoremAcceleration of horizontal numerical advection for atmospheric modeling through surrogate modeling with temporal coarse-graining
Pith reviewed 2026-05-13 05:59 UTC · model grok-4.3
The pith
A convolutional neural network learns to compute mass fluxes for advection using time steps larger than the CFL limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors built a solver framework whose central component is a convolutional neural network that receives concentration fields and CFL numbers and returns mass fluxes. When trained to advance the solution in temporally coarsened steps, the network reproduces baseline ten-day ground-level advection with r-squared values from 0.60 to 0.98. Speed gains scale with coarsening factor while accuracy declines linearly, and the same networks generalize across seventy-two vertical levels and most seasons after training exclusively on January surface winds, except for instabilities that appear in June and October.
What carries the argument
Convolutional neural network that maps concentration fields plus CFL numbers to mass flux, trained on temporally coarsened integration steps to bypass the standard CFL time-step restriction.
If this is right
- The learned solvers become practical for screening tools that accept moderate accuracy loss in exchange for higher throughput.
- Ensemble simulations gain an order-of-magnitude increase in the number of members that can be completed in fixed wall-clock time.
- After modest fine-tuning the same networks can support operational workflows such as data assimilation where speed is critical.
- Because spatial resolution is unchanged, the surrogate can be swapped into existing model grids without re-tuning other physical schemes.
Where Pith is reading between the lines
- Extending the surrogate to three-dimensional advection would require training data that spans vertical velocities and multiple heights simultaneously.
- The same temporal-coarse-graining strategy could be tested on other expensive operators such as diffusion or chemical kinetics inside the same atmospheric model.
- Collecting wind data from all twelve months during the initial training phase would likely reduce the seasonal instabilities observed in June and October.
Load-bearing premise
A model trained only on January ground-level wind data will continue to produce stable, accurate results when applied to other seasons and to all seventy-two vertical levels.
What would settle it
Apply the eight-times or sixteen-times coarsened network to June or October wind fields and observe either visible concentration instabilities or an r-squared value well below 0.60 against the baseline integrator.
Figures






read the original abstract
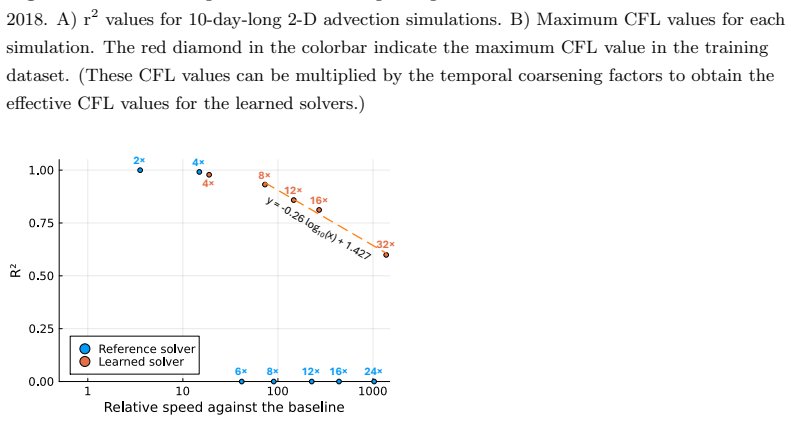
Machine-learned surrogate modeling of advection may accelerate geoscientific models, but existing approaches have either achieved limited speedup or have sacrificed spatial resolution compared to the model they are trained to emulate. We developed a machine-learned solver that speeds up advection simulations without sacrificing spatial resolution through the use of temporal coarse-graining, where the model is trained to take larger integration steps than dictated by the Courant-Friedrich-Lewy (CFL) condition. Our solver framework includes a convolutional neural network that takes concentrations and CFL numbers as inputs and outputs mass flux. Our solvers emulate 10-day ground-level horizontal advection simulations with r$^2$ values against the baseline ranging from 0.60--0.98 with temporal coarsening factors of 4 to 32 times the baseline integration time step. Speed increases and accuracy decreases with increased coarsening, with $r^2 = 0.24$ in accuracy lost for every factor of 10 gained in speed, reaching a maximum 92$\times$ speedup while maintaining $r^2 = 0.60$. We deliberately trained our solvers only on January ground-level wind data to examine their ability to generalize across seasons and vertical heights. The 4$\times$-coarsened learned solver successfully reproduces simulations over 72 vertical levels. The 8$\times$--16$\times$ solvers (but not 32$\times$) emulate most vertical levels. The learned solvers also generalize well across seasons, except for instabilities in June and October. With additional fine-tuning, these learned solvers could be appropriate for operational use where trading accuracy for speed could be advantageous, such as in screening tools, in ensemble simulations, or with data assimilation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a CNN-based surrogate solver for horizontal advection that uses temporal coarse-graining to take integration steps larger than the CFL limit. The network takes concentrations and CFL numbers as inputs and outputs mass flux; it is trained exclusively on January ground-level wind data from a baseline simulation. The surrogates reproduce 10-day ground-level simulations with r² values of 0.60–0.98 for coarsening factors of 4×–32×, yielding speedups up to 92× at r² = 0.60, with a reported linear trade-off of 0.24 r² loss per 10× speedup. Generalization is tested across seasons and all 72 vertical levels, with success claimed at 4× across levels, partial success at 8×–16×, and instabilities noted in June and October.
Significance. If the accuracy–speed trade-off and generalization results hold under more complete testing, the approach would provide a concrete method for accelerating advection without loss of spatial resolution, which is a common bottleneck in atmospheric models. The use of independent baseline output for both training and evaluation avoids circularity, and the mass-flux formulation preserves a physically meaningful output. The quantitative speedup–accuracy relation supplies a useful benchmark for future surrogate work in geoscientific modeling.
major comments (1)
- [Abstract] Abstract and generalization evaluation: the central claim that the learned solvers are suitable for operational use after fine-tuning rests on reliable generalization beyond the narrow January ground-level training distribution. The reported instabilities in June and October, together with outright failure at 32× coarsening for many levels, indicate that this generalization is only partial. A quantitative breakdown of error distributions, identification of conditions that trigger instabilities, and performance metrics across all seasons and the full vertical column is required to substantiate the practical scope of the 92× speedup at r² = 0.60.
minor comments (2)
- [Abstract] The abstract reports an r² range of 0.60–0.98 but does not map specific values to individual coarsening factors; this mapping should be stated explicitly.
- [Methods] Details on training/validation splits, loss function, hyperparameter selection, and full error distributions are missing; these should be supplied to allow assessment of the robustness of the reported r² values and the claimed linear trade-off.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment highlights the need for stronger evidence on generalization to support claims about operational suitability after fine-tuning. We address this below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and generalization evaluation: the central claim that the learned solvers are suitable for operational use after fine-tuning rests on reliable generalization beyond the narrow January ground-level training distribution. The reported instabilities in June and October, together with outright failure at 32× coarsening for many levels, indicate that this generalization is only partial. A quantitative breakdown of error distributions, identification of conditions that trigger instabilities, and performance metrics across all seasons and the full vertical column is required to substantiate the practical scope of the 92× speedup at r² = 0.60.
Authors: We agree that the current presentation of generalization results is insufficient to fully substantiate the operational scope of the 92× speedup. The manuscript already reports that the 4× solver succeeds across all 72 levels, the 8×–16× solvers succeed on most levels, and instabilities occur specifically in June and October, but we did not provide per-season histograms, RMSE distributions, or explicit identification of triggering conditions (e.g., wind-speed thresholds or vertical shear). In the revised manuscript we will add: (1) supplementary figures showing r² and RMSE distributions across all four seasons and all vertical levels, (2) a table of failure rates per coarsening factor and season, and (3) a short discussion identifying high-wind events in June/October as the primary instability trigger. These additions will make the partial nature of generalization explicit while preserving the claim that lower-coarsening solvers remain viable for screening or ensemble applications after modest fine-tuning. We therefore revise the abstract and results sections to reflect this more nuanced scope. revision: yes
Circularity Check
No circularity: performance metrics are measured outcomes of independent ML training and evaluation
full rationale
The paper trains a CNN surrogate on baseline advection simulation outputs (January ground-level data) and reports r² and speedup metrics by direct comparison to held-out baseline runs across seasons and vertical levels. No equations, parameters, or self-citations reduce the reported accuracy-speed trade-off to a fitted constant or self-referential definition; the central results are empirical measurements against an external simulator. Generalization limitations are noted but do not create circularity in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN weights and biases
axioms (1)
- domain assumption The advection operator can be approximated by a convolutional network trained on coarse time steps
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our solver framework includes a convolutional neural network that takes concentrations and CFL numbers as inputs and outputs mass flux.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
temporal coarsening factors of 4 to 32 times the baseline integration time step
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of Advances in Modeling Earth Systems , volume=
Evaluating the impact of chemical complexity and horizontal resolution on tropospheric ozone over the conterminous US with a global variable resolution chemistry model , author=. Journal of Advances in Modeling Earth Systems , volume=. 2022 , publisher=
work page 2022
-
[2]
Impact of numerical choices on water conservation in the
Zhang, Kai and Rasch, Philip J and Taylor, Mark A and Wan, Hui and Leung, Ruby and Ma, Po-Lun and Golaz, Jean-Christophe and Wolfe, Jon and Lin, Wuyin and Singh, Balwinder and others , journal=. Impact of numerical choices on water conservation in the. 2018 , publisher=
work page 2018
-
[3]
Courant, Richard and Friedrichs, Kurt and Lewy, Hans , journal=. 1928 , publisher=
work page 1928
-
[4]
Proceedings of the National Academy of Sciences , volume=
Machine learning--accelerated computational fluid dynamics , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , publisher=
work page 2021
-
[5]
Proceedings of the National Academy of Sciences , volume=
Learning data-driven discretizations for partial differential equations , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
work page 2019
-
[6]
arXiv preprint arXiv:2112.15275 , year=
Learned coarse models for efficient turbulence simulation , author=. arXiv preprint arXiv:2112.15275 , year=
-
[7]
Atmospheric transport modeling of
Benson, Vitus and Bastos, Ana and Reimers, Christian and Winkler, Alexander J and Yang, Fanny and Reichstein, Markus , journal=. Atmospheric transport modeling of. 2025 , publisher=
work page 2025
-
[8]
arXiv preprint arXiv:2405.06590 , year=
Decomposing weather forecasting into advection and convection with neural networks , author=. arXiv preprint arXiv:2405.06590 , year=
-
[9]
The piecewise parabolic method (
Colella, Phillip and Woodward, Paul R , journal=. The piecewise parabolic method (. 1984 , publisher=
work page 1984
-
[10]
Multidimensional flux-form semi-
Lin, Shian-Jiann and Rood, Richard B , journal=. Multidimensional flux-form semi-
-
[11]
Global modeling of tropospheric chemistry with assimilated meteorology:
Bey, Isabelle and Jacob, Daniel J and Yantosca, Robert M and Logan, Jennifer A and Field, Brendan D and Fiore, Arlene M and Li, Qinbin and Liu, Honguy Y and Mickley, Loretta J and Schultz, Martin G , journal=. Global modeling of tropospheric chemistry with assimilated meteorology:. 2001 , publisher=
work page 2001
-
[12]
Bezanson, Jeff and Karpinski, Stefan and Shah, Viral B and Edelman, Alan , journal=. Julia:
-
[13]
Nature Machine Intelligence , pages=
Weak baselines and reporting biases lead to overoptimism in machine learning for fluid-related partial differential equations , author=. Nature Machine Intelligence , pages=. 2024 , publisher=
work page 2024
- [14]
-
[15]
Methods in Computational Physics/Academic Press , year=
Computational design of the basic dynamical processes of the UCLA general circulation model , author=. Methods in Computational Physics/Academic Press , year=
- [16]
-
[17]
Park, Manho and Zheng, Zhonghua and Riemer, Nicole and Tessum, Christopher W , journal=. Learned 1-. 2024 , publisher=
work page 2024
-
[18]
Learned discretizations for passive scalar advection in a two-dimensional turbulent flow , author=. Phys. Rev. Fluids , volume=. 2021 , publisher=
work page 2021
-
[19]
P umas AI / S imple C hains.jl
PumasAI. P umas AI / S imple C hains.jl. 2022 , note =
work page 2022
-
[20]
Doing small network scientific machine learning in J ulia 5x faster than P y T orch
Elrod, Chris and Korsbo, Niklas and Rackauckas, Chris. Doing small network scientific machine learning in J ulia 5x faster than P y T orch. 2022 , note =
work page 2022
-
[21]
Mike Innes , title =. J. Open Source Softw. , year =
-
[22]
Gaussian Error Linear Units (GELUs)
Gaussian error linear units (gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Numerical methods for fluid dynamics: With applications to geophysics , author=. 2010 , publisher=
work page 2010
-
[24]
Donahue, Aaron Sheffield and Caldwell, Peter Martin and Bertagna, Luca and Beydoun, Hassan and Bogenschutz, Peter A and Bradley, AM and Clevenger, Thomas C and Foucar, J and Golaz, C and Guba, Oksana and others , journal=. To exascale and beyond—. 2024 , publisher=
work page 2024
- [25]
-
[26]
EarthSciML Authors. E nvironmental T ransport.jl. 2025 , note =
work page 2025
-
[27]
Enabling high-performance cloud computing for the
Efstathiou, Christos I and Adams, Elizabeth and Coats, Carlie J and Zelt, Robert and Reed, Mark and McGee, John and Foley, Kristen M and Sidi, Fahim I and Wong, David C and Fine, Steven and others , journal=. Enabling high-performance cloud computing for the. 2024 , publisher=
work page 2024
-
[28]
Cao, Kai and Wu, Qizhong and Wang, Lingling and Wang, Nan and Cheng, Huaqiong and Tang, Xiao and Li, Dongqing and Wang, Lanning , journal=. 2023 , publisher=
work page 2023
-
[29]
Eastham, Sebastian D and Long, Michael S and Keller, Christoph A and Lundgren, Elizabeth and Yantosca, Robert M and Zhuang, Jiawei and Li, Chi and Lee, Colin J and Yannetti, Matthew and Auer, Benjamin M and others , journal=. 2018 , publisher=
work page 2018
- [30]
-
[31]
Manheim, David and Garrabrant, Scott , journal=. Categorizing variants of
-
[32]
Problems of monetary management: the
Goodhart, Charles AE , booktitle=. Problems of monetary management: the. 1984 , publisher=
work page 1984
-
[33]
Earth system predictability research and development: proceedings of a workshop--in brief , author=
-
[34]
ML -advection-without-spatial-coarse-graining
Park, Manho. ML -advection-without-spatial-coarse-graining. 2026 , note =
work page 2026
-
[35]
arXiv preprint arXiv:2312.00907 , year=
Extreme event prediction with multi-agent reinforcement learning-based parametrization of atmospheric and oceanic turbulence , author=. arXiv preprint arXiv:2312.00907 , year=
-
[36]
Journal of Advances in Modeling Earth Systems , volume=
Deep learning for subgrid-scale turbulence modeling in large-eddy simulations of the convective atmospheric boundary layer , author=. Journal of Advances in Modeling Earth Systems , volume=. 2022 , publisher=
work page 2022
-
[37]
Nature Computational Science , volume=
Enhancing computational fluid dynamics with machine learning , author=. Nature Computational Science , volume=. 2022 , publisher=
work page 2022
-
[38]
Machine learning in fluid dynamics:
Taira, Kunihiko and Rigas, Georgios and Fukami, Kai , journal=. Machine learning in fluid dynamics:. 2025 , publisher=
work page 2025
-
[39]
Air Quality, Atmosphere & Health , volume=
The influence of air quality model resolution on health impact assessment for fine particulate matter and its components , author=. Air Quality, Atmosphere & Health , volume=. 2016 , publisher=
work page 2016
-
[40]
Environmental Science & Technology Letters , volume=
Effect of model spatial resolution on estimates of fine particulate matter exposure and exposure disparities in the United States , author=. Environmental Science & Technology Letters , volume=. 2018 , publisher=
work page 2018
-
[41]
Stiff neural ordinary differential equations , author=. Chaos , volume=. 2021 , publisher=
work page 2021
-
[42]
Geoscientific Model Development , volume=
Sensitivity of chemistry-transport model simulations to the duration of chemical and transport operators: a case study with GEOS-Chem v10-01 , author=. Geoscientific Model Development , volume=. 2016 , publisher=
work page 2016
- [43]
- [44]
-
[45]
Journal of Computational Physics , volume=
Finite-volume transport on various cubed-sphere grids , author=. Journal of Computational Physics , volume=. 2007 , publisher=
work page 2007
-
[46]
The GEOS-5 Data Assimilation System-Documentation of Versions 5.0. 1, 5.1. 0, and 5.2. 0 , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.