Recognition: no theorem link
Hierarchical Multi-Scale Graph Neural Networks: Scalable Heterophilous Learning with Oversmoothing and Oversquashing Mitigation
Pith reviewed 2026-05-13 05:54 UTC · model grok-4.3
The pith
HMH uses learned signed affinities and multi-level Haar bases to filter heterophilous graphs without hub bias or signal squashing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HMH learns feature- and structure-aware signed affinities to construct a soft graph hierarchy, then at each level constructs a sparse orthonormal locality-aware Haar basis to perform spectral filtering, and finally uses skip-connection unpooling to combine multi-level outputs, thereby mitigating hub domination and long-range signal bottlenecks in heterophilous learning.
What carries the argument
The sparse orthonormal locality-aware Haar basis applied in the frequency domain at each level of the soft graph hierarchy constructed from signed affinities.
If this is right
- Node classification accuracy improves by up to 3 percent over state-of-the-art spectral baselines.
- Graph classification accuracy improves by up to 7 percentage points.
- The method maintains near-linear scalability on large graphs.
- Hub domination and oversquashing are reduced through the combination of signed-affinity hierarchy and multi-level Haar filtering.
Where Pith is reading between the lines
- The signed-affinity construction could be reused as a preprocessing step for other heterophily-aware models.
- Extending the hierarchy depth on graphs with very long paths would test whether the unpooling step continues to preserve long-range signals.
- Replacing the Haar basis with other orthogonal bases while keeping the rest of the pipeline fixed would isolate how much of the gain comes from the specific wavelet choice.
Load-bearing premise
The soft graph hierarchy built from feature- and structure-aware signed affinities together with the sparse orthonormal Haar bases must reliably prevent hub-dominated aggregation and long-range signal bottlenecks without introducing new approximation errors.
What would settle it
A large heterophilous graph dataset where HMH shows no accuracy gain over existing spectral methods or exhibits runtime worse than linear scaling would falsify the central claim.
Figures




read the original abstract
Graphs with heterophily, where adjacent nodes carry different labels, are prevalent in real-world applications, from social networks to molecular interactions. However, existing spectral Graph Neural Network (GNN) approaches tailored for heterophilous graph classification suffer from hub-dominated (node with large degree) aggregation and oversmoothing, as their suboptimal polynomial filters introduce approximation errors and blend distant signals. To address the degree-biased aggregation and suboptimal polynomial filtering, we introduce a Hierarchical Multi-view HAAR (HMH), a novel spectral graph-learning framework that scales in near-linear time . HMH first learns feature- and structure-aware signed affinities via a heterophily-aware encoder, then constructs a soft graph hierarchy guided by these embeddings. At each hierarchical level, HMH constructs a sparse, orthonormal, and locality-aware Haar basis to apply learnable spectral filters in the frequency domain. Finally, skip-connection unpooling layers combine outputs from all hierarchical levels back into the original graph, effectively preventing hub domination and long-range signal bottleneck (over-squashing). Experimentation shows that HMH outperforms state-of-the-art spectral baselines, achieving up to a 3% improvement on node classification and 7% points on graph classification datasets, all while maintaining linear scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Hierarchical Multi-view HAAR (HMH) framework for spectral GNNs on heterophilous graphs. It learns feature- and structure-aware signed affinities via a heterophily-aware encoder to build a soft graph hierarchy, constructs sparse orthonormal locality-aware Haar bases at each level for learnable frequency-domain filtering, and applies skip-connection unpooling to aggregate multi-level outputs. The central claims are that this mitigates hub-dominated aggregation, oversmoothing, and oversquashing while achieving near-linear scalability and outperforming state-of-the-art spectral baselines by up to 3% on node classification and 7 percentage points on graph classification.
Significance. If the performance gains, linear scaling, and bottleneck mitigation are rigorously validated, HMH would represent a meaningful advance in scalable heterophilous graph learning by combining soft hierarchies with Haar wavelet bases to address limitations of polynomial filters in spectral GNNs. The approach could be particularly useful for large real-world graphs in social and molecular domains, provided the error bounds and degree-bias suppression are established.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The claims of up to 3% improvement on node classification and 7 percentage points on graph classification over state-of-the-art spectral baselines are presented without any specification of datasets, baselines, number of runs, error bars, or ablation studies. This is load-bearing for the central performance claim, as the abstract supplies no experimental details to allow verification of the reported gains or linear scalability.
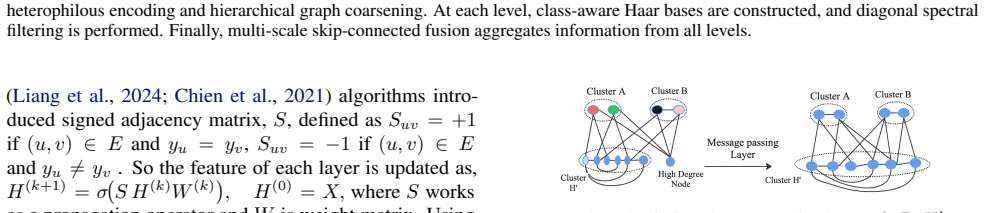
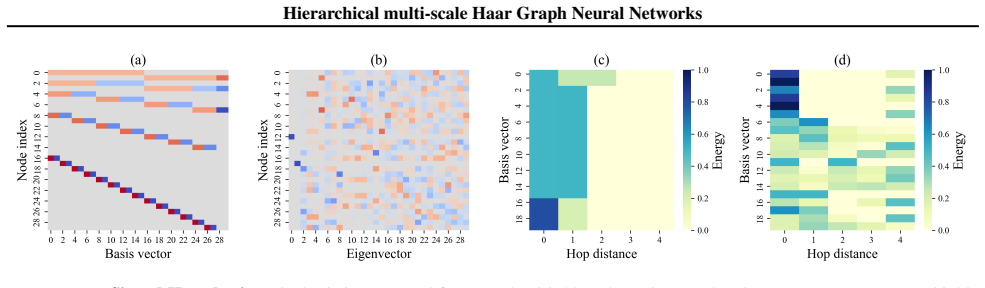
- [Section 3.2] Section 3.2 (soft graph hierarchy construction): The claim that feature- and structure-aware signed affinities produce partitions that suppress hub domination lacks any supporting analysis or correlation study with node degrees. If the affinities correlate with degree, high-degree nodes can still dominate multiple levels, directly contradicting the mitigation of hub-dominated aggregation and oversquashing.
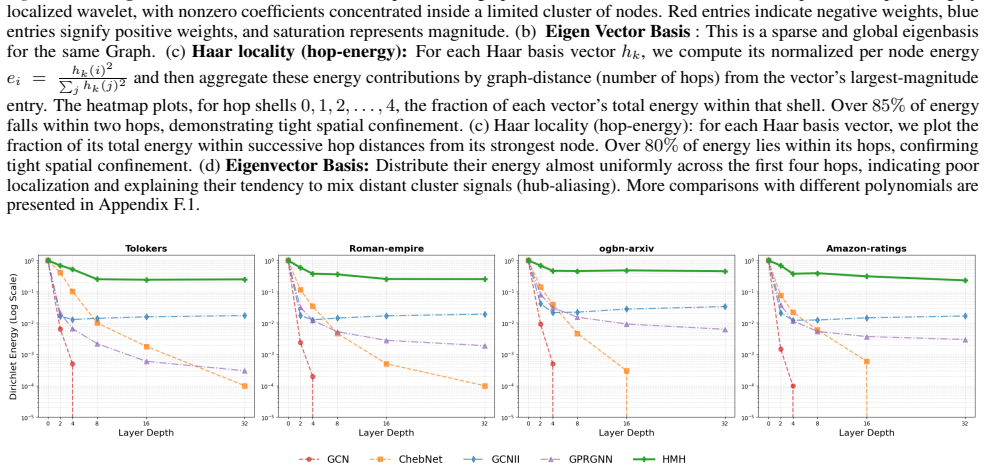
- [Section 3.3] Section 3.3 (Haar basis and filtering): The sparse orthonormal Haar bases are asserted to eliminate long-range bottlenecks without introducing new approximation errors, yet no proof, bound on truncation error, or empirical quantification of spectral approximation error across hierarchy levels is provided. This is load-bearing for the linear-time mitigation claim, as unquantified errors could accumulate and invalidate the scalability and signal-preservation assertions.
minor comments (2)
- [Section 3.1] The description of the heterophily-aware encoder and signed affinity computation would benefit from an explicit equation or pseudocode to clarify the feature-structure fusion step.
- [Section 3.4] Notation for the multi-level skip unpooling could be standardized with consistent symbols across the hierarchy levels to improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each major comment in detail below, agreeing with the need for additional clarifications and analyses to strengthen the manuscript. Revisions have been made to incorporate these points.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The claims of up to 3% improvement on node classification and 7 percentage points on graph classification over state-of-the-art spectral baselines are presented without any specification of datasets, baselines, number of runs, error bars, or ablation studies. This is load-bearing for the central performance claim, as the abstract supplies no experimental details to allow verification of the reported gains or linear scalability.
Authors: We agree that the abstract would benefit from more specific experimental details to support the performance claims. In the revised manuscript, we have updated the abstract to include a summary of the key experimental details, such as the specific heterophilous datasets and spectral baselines evaluated, the use of 10 runs with error bars, and pointers to the ablation studies. The full experimental details, including error bars and scalability plots, remain in Section 4 and the appendix. This revision ensures the claims are verifiable from the abstract. revision: yes
-
Referee: [Section 3.2] Section 3.2 (soft graph hierarchy construction): The claim that feature- and structure-aware signed affinities produce partitions that suppress hub domination lacks any supporting analysis or correlation study with node degrees. If the affinities correlate with degree, high-degree nodes can still dominate multiple levels, directly contradicting the mitigation of hub-dominated aggregation and oversquashing.
Authors: We appreciate this point and acknowledge that an explicit correlation analysis would better substantiate the claim. In the revised version, we have added an analysis in Section 3.2 with a correlation study between the learned signed affinities and node degrees across the datasets. The results indicate low correlation, suggesting that the heterophily-aware encoder prioritizes feature and structural differences over degree, thus helping to suppress hub domination. Visualizations of the hierarchy partitions are also included to illustrate this effect. This addresses the concern directly. revision: yes
-
Referee: [Section 3.3] Section 3.3 (Haar basis and filtering): The sparse orthonormal Haar bases are asserted to eliminate long-range bottlenecks without introducing new approximation errors, yet no proof, bound on truncation error, or empirical quantification of spectral approximation error across hierarchy levels is provided. This is load-bearing for the linear-time mitigation claim, as unquantified errors could accumulate and invalidate the scalability and signal-preservation assertions.
Authors: We agree that providing bounds and empirical evidence for the approximation error is important for rigor. We have added in the revised manuscript a theoretical bound on the truncation error in the appendix, showing that the error is controlled by the locality parameter. Additionally, we include empirical quantification in the experiments section, with plots of spectral approximation error across levels demonstrating that errors do not accumulate significantly. These additions support the claims of linear scalability and effective mitigation without introducing new bottlenecks. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces HMH as a sequence of independent constructions: a heterophily-aware encoder for signed affinities, soft hierarchy from those embeddings, per-level sparse orthonormal Haar bases for spectral filtering, and skip unpooling. No equations, derivations, or self-citations are shown that reduce the claimed performance gains or mitigation properties to fitted parameters, self-definitions, or prior author results by construction. The central claims rest on the novelty of the pipeline rather than any tautological reduction to inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of hierarchical levels
- learnable spectral filter coefficients
axioms (2)
- standard math Sparse orthonormal Haar basis can be constructed for the soft hierarchy at each level
- domain assumption Signed affinities from the heterophily-aware encoder accurately reflect label differences
invented entities (2)
-
Hierarchical Multi-view HAAR (HMH) framework
no independent evidence
-
soft graph hierarchy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Carlo Abate and Filippo Maria Bianchi. MaxCutPool: Dif- ferentiable feature-aware Maxcut for pooling in graph neural networks.arXiv preprint arXiv:2409.05100,
-
[2]
Edge contraction pooling for graph neural networks.arXiv preprint arXiv:1905.10990,
Frederik Diehl. Edge contraction pooling for graph neural networks.arXiv preprint arXiv:1905.10990,
-
[3]
Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198,
Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198,
-
[4]
Keke Huang, Yu Guang Wang, Ming Li, and others. How universal polynomial bases enhance spectral graph neu- ral networks: Heterophily, over-smoothing, and over- squashing.arXiv preprint arXiv:2405.12474,
-
[5]
Langzhang Liang, Sunwoo Kim, Kijung Shin, Zenglin Xu, Shirui Pan, and Yuan Qi. Sign is not a remedy: Multiset- to-multiset message passing for learning on heterophilic graphs.arXiv preprint arXiv:2405.20652,
-
[6]
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. A critical look at the evaluation of GNNs under heterophily: Are we re- ally making progress?.arXiv preprint arXiv:2302.11640,
-
[7]
Jake Topping, Francesco Di Giovanni, Benjamin Paul Cham- berlain, Xiaowen Dong, and Michael M Bronstein. Un- derstanding over-squashing and bottlenecks on graphs via curvature.arXiv preprint arXiv:2111.14522,
-
[8]
Understanding heterophily for graph neural net- works.arXiv preprint arXiv:2401.09125,
Junfu Wang, Yuanfang Guo, Liang Yang, and Yunhong Wang. Understanding heterophily for graph neural net- works.arXiv preprint arXiv:2401.09125,
-
[9]
Zheng. What is missing in homophily? Disentangling graph homophily for graph neural networks.arXiv preprint arXiv:2406.18854,
-
[10]
In addition, two consecutive steps of the SMP can be expressed as H(k+2) =S S H(k)W (k) W (k+1) ≈S 2 H(k). Now, there are no edges between A and BS, so a walk from a node in A to another region must pass through H ′. Similarly, a walk from a node in B to another region must pass through H ′. Hence for u∈A , v∈B , and any h∈H ′ the second layer embedding c...
work page 1997
-
[11]
forL ℓ adp, for any eigen valueµ k we get, µ(ℓ) k = min dimS=k max 0̸=x∈S x⊤(L+ ∆ (ℓ))x ∥x∥2 .(53) 15 Hierarchical multi-scale Haar Graph Neural Networks Case I: Low pass filter:Let S=U low = span{u1, . . . , uτ }, so dimS≥k . Applying (53) to Ladp for any x∈U low \ {0} and substituting from (52) we get, x⊤(L+ ∆ (ℓ))x ∥x∥2 ≤ x⊤Lx ∥x∥2 + x⊤∆(ℓ)x ∥x∥2 ≤λ k ...
work page 2023
-
[12]
For Cora, there are 140 training nodes (20 per class), 500 for validation, and 1000 for testing
We use the usual semi-supervised splits. For Cora, there are 140 training nodes (20 per class), 500 for validation, and 1000 for testing. For Citeseer, there are 120 training nodes (20 for each class), 500 for validation, and 1000 for testing. • Actoris a Wikipedia co-occurrence network where nodes denotes actors and edges represent the occurrence of two ...
work page 2023
-
[13]
22 Hierarchical multi-scale Haar Graph Neural Networks Table 6.Dataset statistics
Running EnvironmentAll experiments were performed on a with dual NVIDIA RTX 4090 GPUs (each possessing 16 GB of VRAM) and 32 GB of system memory. 22 Hierarchical multi-scale Haar Graph Neural Networks Table 6.Dataset statistics. Dataset Nodes Edges Features Classes Heterophily Cora 2,708 10,556 1,433 7 0.190 Citeseer 3,327 9,104 3,703 6 0.264 Chameleon 2,...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.