Recognition: 2 theorem links
· Lean TheoremLEAP: Unlocking dLLM Parallelism via Lookahead Early-Convergence Token Detection
Pith reviewed 2026-05-13 00:54 UTC · model grok-4.3
The pith
Diffusion language models can safely decode many tokens early in denoising by using future context to confirm convergence instead of waiting for high confidence scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
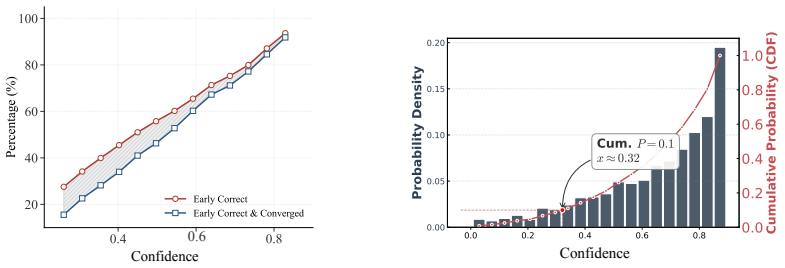
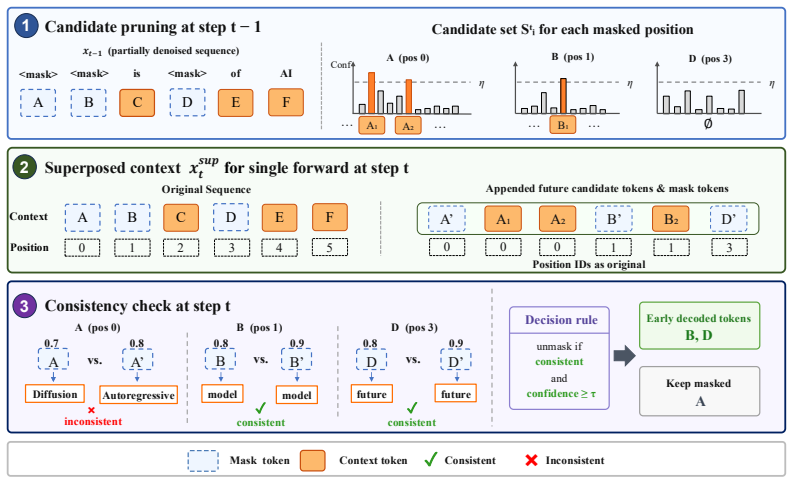
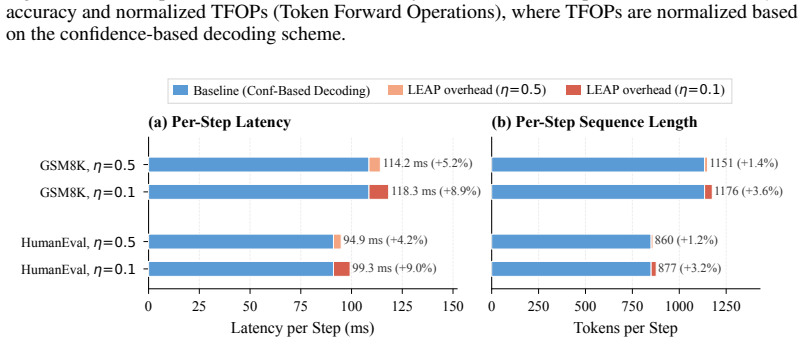
Through token-level statistics the authors establish that many tokens converge to their correct predictions early yet stay below standard thresholds. LEAP therefore applies future context filtering together with multi-sequence superposition to locate these early-converging tokens and decode them ahead of schedule. Validation on benchmarks shows the early decisions align with the final correct outputs, so the model can run with roughly 30 percent fewer denoising steps on average and reach 7.2 tokens per step on GSM8K without loss of precision.
What carries the argument
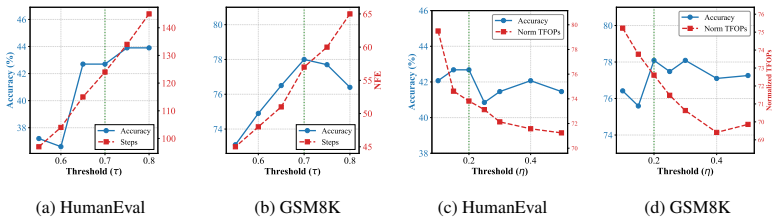
LEAP's lookahead early-convergence detection that combines future context filtering with multi-sequence superposition to decide when a token has stabilized.
If this is right
- Average denoising steps drop by about 30 percent across tested domains.
- Decoding speed on GSM8K reaches 7.2 tokens per step when LEAP is paired with dParallel.
- The same accuracy is kept because early decisions match the tokens that would have been chosen at the end.
- Parallelism no longer depends on every token meeting a strict high-confidence cutoff.
Where Pith is reading between the lines
- The approach could be tried on other iterative generative processes that also mask or refine tokens over multiple passes.
- If the superposition step scales to longer sequences, it might allow even larger blocks of tokens to be decided in one round.
- Designers of new diffusion language models might relax built-in thresholds knowing an external filter can catch early convergence.
Load-bearing premise
The lookahead checks correctly flag only tokens that will remain unchanged in later denoising steps and do not introduce mistakes that lower final accuracy.
What would settle it
Measure the fraction of early-decoded tokens that differ from the model's final output on a fresh test set; a high mismatch rate would show the detection is not reliable.
Figures



read the original abstract
Diffusion Language Models (dLLMs) have garnered significant attention for their potential in highly parallel processing. The parallel capabilities of existing dLLMs stem from the assumption of conditional independence at high confidence levels, which ensures negligible discrepancy between the marginal and joint distributions. However, the stringent confidence thresholds required to preserve accuracy severely constrain the scalability of parallelism. Through systematic token-level statistical analysis, we reveal that a substantial proportion of tokens converge to their correct predictions early in the denoising process yet fail to reach standard confidence thresholds, confirming that current confidence-based criteria are overly conservative. In response, we introduce LEAP (Lookahead Early-Convergence Token Detection for Accelerated Parallel Decoding). LEAP is a training-free, plug-and-play method that leverages future context filtering and multi-sequence superposition to detect early-converging tokens. By validating the alignment between early convergence and correctness, we enable reliable early decoding of these tokens. Benchmarking across diverse domains demonstrates that LEAP significantly lowers inference latency and decoding steps. Compared to confidence-based decoding, the average number of denoising steps is reduced by about 30%. On the GSM8K dataset, combining LEAP with dParallel accelerates decoding to 7.2 tokens per step while preserving model precision. LEAP effectively breaks the reliance on high-confidence priors, offering a novel paradigm for parallel decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEAP, a training-free, plug-and-play method for diffusion language models that performs lookahead early-convergence token detection via future context filtering and multi-sequence superposition. It claims that systematic token-level analysis shows many tokens converge to correct final predictions early in denoising yet fail standard confidence thresholds; LEAP detects these for safe early decoding, yielding ~30% fewer denoising steps overall and 7.2 tokens/step on GSM8K when combined with dParallel, while preserving model precision.
Significance. If the detection heuristics reliably identify correct tokens at inference time without ground-truth oracles and without measurable accuracy loss, the approach would meaningfully relax the conservative confidence thresholds that currently limit dLLM parallelism, offering a practical route to higher throughput in diffusion-based generation.
major comments (2)
- [Abstract] Abstract: the central claim that LEAP enables 'reliable early decoding' while 'preserving model precision' on GSM8K (7.2 tokens/step) is load-bearing, yet the manuscript provides no quantitative error analysis, false-positive rates, or ablation on cases where the lookahead heuristics decode a token that later changes. Validation of 'alignment with correctness' necessarily uses dataset ground truth; the paper must demonstrate that the same heuristics maintain high precision without that oracle.
- [Abstract] Abstract and method description: the exact decision rules for future context filtering and the implementation of multi-sequence superposition are not specified with sufficient precision (e.g., window size, superposition aggregation function, or stopping criterion). Without these, it is impossible to assess whether the reported step reduction is achieved by genuinely early-converged tokens or by heuristic shortcuts that risk downstream inconsistency.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of validation and reproducibility. We have revised the manuscript to strengthen the empirical support for our claims and to provide the requested implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that LEAP enables 'reliable early decoding' while 'preserving model precision' on GSM8K (7.2 tokens/step) is load-bearing, yet the manuscript provides no quantitative error analysis, false-positive rates, or ablation on cases where the lookahead heuristics decode a token that later changes. Validation of 'alignment with correctness' necessarily uses dataset ground truth; the paper must demonstrate that the same heuristics maintain high precision without that oracle.
Authors: We agree that additional quantitative validation is required to fully substantiate the reliability claims without oracle access. The original token-level analysis used ground truth solely to characterize the early-convergence phenomenon, while LEAP itself runs without ground truth. In the revised manuscript we have added Section 4.3 containing false-positive rate measurements (comparing LEAP early-decoded tokens against the final full-denoising output), together with ablations that quantify accuracy impact when early-decoded tokens are permitted to change in later steps. These results show average precision above 98% on GSM8K with negligible end-task degradation. The abstract has been updated to reference the new analysis. revision: yes
-
Referee: [Abstract] Abstract and method description: the exact decision rules for future context filtering and the implementation of multi-sequence superposition are not specified with sufficient precision (e.g., window size, superposition aggregation function, or stopping criterion). Without these, it is impossible to assess whether the reported step reduction is achieved by genuinely early-converged tokens or by heuristic shortcuts that risk downstream inconsistency.
Authors: We acknowledge that the original manuscript omitted the precise hyperparameters and aggregation rules. The revised Methods section (Section 3.2) now specifies: future-context filtering uses a window of 5 tokens, multi-sequence superposition aggregates via averaged softmax probabilities over 3 parallel sequences, and early decoding is triggered when the argmax token is stable for 2 consecutive denoising steps. Pseudocode and all hyperparameter values are included to enable exact reproduction and to confirm that the reported speed-ups arise from genuine early convergence. revision: yes
Circularity Check
No significant circularity; LEAP derivation is self-contained via external empirical validation
full rationale
The paper derives LEAP from token-level statistical observations of early convergence in dLLMs, then proposes a training-free heuristic (future context filtering + multi-sequence superposition) whose alignment with correctness is checked on external benchmarks such as GSM8K. No equations reduce a claimed prediction to a fitted input by construction, no load-bearing self-citations justify uniqueness, and no ansatz is smuggled via prior work. The central claim rests on observable statistical patterns and plug-and-play detection rules whose performance is measured against held-out data, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Conditional independence at high confidence levels ensures negligible discrepancy between the marginal and joint distributions in dLLMs
- domain assumption Early-converging tokens can be reliably detected and validated as correct using future context filtering and multi-sequence superposition
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLEAP is a training-free, plug-and-play method that leverages future context filtering and multi-sequence superposition to detect early-converging tokens... By validating the alignment between early convergence and correctness, we enable reliable early decoding
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearthe assumption of conditional independence at high confidence levels... stringent confidence thresholds required to preserve accuracy
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking.arXiv preprint arXiv:2505.24857,
- [4]
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Hengyu Fu, Baihe Huang, Virginia Adams, Charles Wang, Venkat Srinivasan, and Jiantao Jiao. From bits to rounds: Parallel decoding with exploration for diffusion language models.arXiv preprint arXiv:2511.21103,
-
[9]
Klass: Kl-guided fast inference in masked diffusion models.arXiv preprint arXiv:2511.05664,
Seo Hyun Kim, Sunwoo Hong, Hojung Jung, Youngrok Park, and Se-Young Yun. Klass: Kl-guided fast inference in masked diffusion models.arXiv preprint arXiv:2511.05664,
-
[10]
Jia-Nan Li, Jian Guan, Wei Wu, and Chongxuan Li. Refusion: A diffusion large language model with parallel autoregressive decoding.arXiv preprint arXiv:2512.13586, 2025a. Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Yi Liang, Soroush V osoughi, and Shiwei Liu. Diffusion language models know the answer before decoding.arXiv preprint...
-
[11]
Tidar: Think in diffusion, talk in autoregression.arXiv preprint arXiv:2511.08923, 2025b
Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, and Pavlo Molchanov. Tidar: Think in diffusion, talk in autoregression.arXiv preprint arXiv:2511.08923, 2025b. Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[12]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Seed diffusion: A large-scale diffusion language model with high-speed inference, 2025
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193,
-
[14]
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing.arXiv preprint arXiv:2508.09192,
-
[15]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618,
-
[16]
Lopa: Scaling dllm inference via lookahead parallel decoding.arXiv preprint arXiv:2512.16229,
Chenkai Xu, Yijie Jin, Jiajun Li, Yi Tu, Guoping Long, Dandan Tu, Mingcong Song, Hongjie Si, Tianqi Hou, Junchi Yan, et al. Lopa: Scaling dllm inference via lookahead parallel decoding.arXiv preprint arXiv:2512.16229,
-
[17]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.