Recognition: no theorem link
ECHO: Continuous Hierarchical Memory for Vision-Language-Action Models
Pith reviewed 2026-05-13 07:08 UTC · model grok-4.3
The pith
ECHO maps VLA hidden states into a continuous hierarchical space with a hyperbolic autoencoder to organize experiences into a retrievable semantic memory tree.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ECHO maps VLA hidden states into a continuous hierarchical space via a hyperbolic autoencoder. Entailment constraints organize the resulting vectors into a semantic memory tree that supports efficient top-down retrieval. A background consolidation mechanism refines the tree over time by geometric interpolation and structural splitting, enabling virtual memory synthesis. Added to the π0 foundation model, this produces a 12.8 percent absolute increase in execution success rate on LIBERO-Long tasks together with stronger compositional generalization on cross-suite unseen long-horizon problems.
What carries the argument
The hyperbolic autoencoder with entailment constraints that embeds VLA states into continuous hierarchical space and constructs an organizable semantic memory tree for retrieval and refinement.
If this is right
- Enables efficient top-down retrieval from the semantic memory tree during action generation.
- Supports continuous refinement and virtual synthesis of experiences through geometric operations.
- Delivers improved compositional generalization on long-horizon tasks not seen during training.
- Provides a structural prior for manipulation categories that flat memory lacks.
Where Pith is reading between the lines
- Hyperbolic geometry may prove broadly useful for representing nested task hierarchies in sequential decision systems.
- The consolidation mechanism could reduce the need for ever-larger discrete memory buffers as task horizons grow.
- The same continuous-space organization might transfer to other embodied domains that require long-term experience reuse.
Load-bearing premise
The hyperbolic autoencoder with entailment constraints will reliably embed VLA states into a useful hierarchy that supports retrieval without introducing distortions or overfitting to the training distribution.
What would settle it
Replace the hyperbolic autoencoder and entailment constraints with a standard Euclidean autoencoder of similar capacity, retrain the full system on the same data, and check whether the 12.8 percent success-rate gain on LIBERO-Long disappears.
Figures



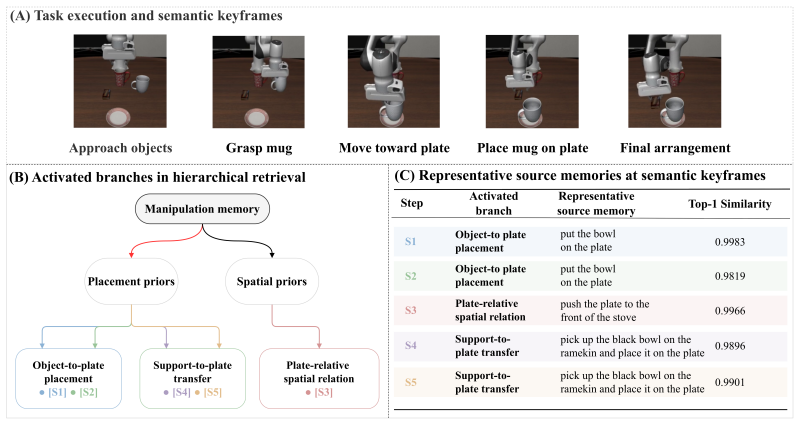
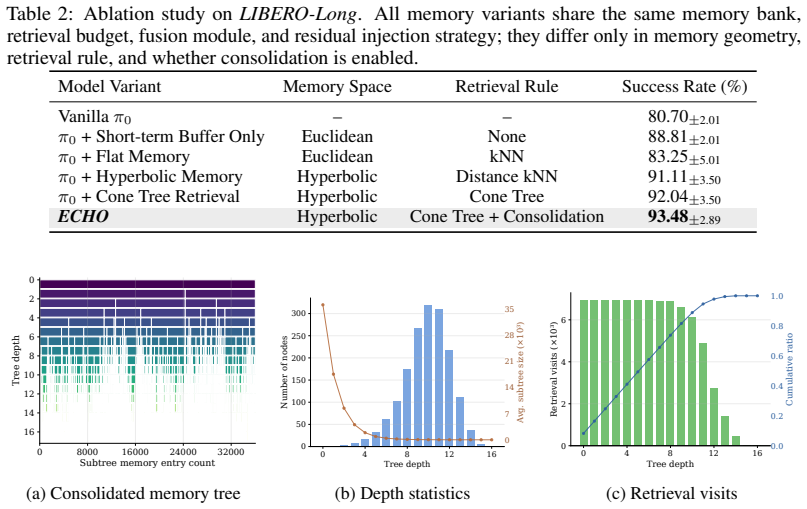



read the original abstract
Memory capacity is a critical factor determining the performance of Vision-Language-Action (VLA) models in long-horizon manipulation tasks. Existing memory-augmented architectures primarily rely on linear or flat storage, lacking structural priors for manipulation categories and hierarchical organization. This deficiency hinders efficient experience retrieval and limits generalization to unseen long-horizon task compositions. Inspired by the hierarchical organization of human experience, we propose ECHO (Experience Consolidation and Hierarchical Organization), a novel memory framework operating within a Continuous Hierarchical Space. By employing a hyperbolic autoencoder, ECHO maps VLA hidden states into this space. Leveraging hyperbolic metrics and entailment constraint mechanisms, experience vectors are organized into a semantic memory tree that supports efficient top-down retrieval. In parallel, a background consolidation mechanism continuously refines the memory tree through geometric interpolation and structural splitting, supporting virtual memory synthesis in the continuous space. We integrate ECHO into the $\pi_0$ foundation model. Evaluations on LIBERO and preliminary real-world experiments demonstrate the effectiveness of our approach, notably achieving a 12.8% absolute improvement in execution success rate over the $\pi_0$ baseline on LIBERO-Long, while improving compositional generalization on cross-suite unseen long-horizon tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ECHO, a memory framework for Vision-Language-Action (VLA) models that maps hidden states into a continuous hierarchical space using a hyperbolic autoencoder. It organizes experience vectors into a semantic memory tree via hyperbolic metrics and entailment constraints, supports top-down retrieval, and performs background consolidation through geometric interpolation and structural splitting. Integrated into the π0 foundation model, the work claims a 12.8% absolute improvement in execution success rate over the π0 baseline on LIBERO-Long tasks, along with improved compositional generalization on cross-suite unseen long-horizon tasks.
Significance. If the reported gains are shown to arise specifically from the hierarchical geometry rather than added capacity or regularization, the approach could provide a useful structural prior for efficient retrieval and virtual memory synthesis in long-horizon manipulation, addressing a recognized limitation of flat memory in current VLA architectures.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The central claim of a 12.8% absolute success-rate gain on LIBERO-Long and improved cross-suite generalization is presented without ablations, error bars, or controls that isolate the contribution of the hyperbolic tree versus other factors such as increased model capacity or the entailment loss; this leaves open whether the improvement is load-bearing on the claimed continuous hierarchical space.
- [§3.2] §3.2 (Hyperbolic Autoencoder): The assumption that the Poincaré-ball metric plus entailment constraints will produce artifact-free embeddings aligned with manipulation semantics is not verified; no quantitative checks (e.g., hierarchy preservation metrics, embedding collapse analysis, or retrieval precision on held-out states) are reported to confirm that the geometry supports the claimed top-down retrieval and interpolation without introducing spurious states.
- [§3.3] §3.3 (Background Consolidation): The mechanism of continuous refinement via interpolation and splitting is described at a high level, but the manuscript supplies no analysis of how these operations affect policy execution stability or whether they risk degrading performance on the original training distribution.
minor comments (2)
- [§3] Notation for the entailment constraint and the Poincaré-ball radius is introduced without an explicit equation reference in the methods section, making it difficult to reproduce the exact loss formulation.
- [§4] The preliminary real-world experiments are mentioned only briefly; adding quantitative metrics and task descriptions would strengthen the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We provide point-by-point responses below and outline revisions to address the concerns regarding empirical validation of the hierarchical memory contributions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central claim of a 12.8% absolute success-rate gain on LIBERO-Long and improved cross-suite generalization is presented without ablations, error bars, or controls that isolate the contribution of the hyperbolic tree versus other factors such as increased model capacity or the entailment loss; this leaves open whether the improvement is load-bearing on the claimed continuous hierarchical space.
Authors: We agree that the current manuscript reports the performance gains without explicit ablations isolating the hyperbolic tree from capacity or regularization effects. In the revised version we will add: (1) a Euclidean-space control with matched capacity, (2) an ablation removing the entailment loss, and (3) error bars from multiple random seeds. These experiments will demonstrate that the reported 12.8% gain is attributable to the continuous hierarchical geometry. revision: yes
-
Referee: [§3.2] §3.2 (Hyperbolic Autoencoder): The assumption that the Poincaré-ball metric plus entailment constraints will produce artifact-free embeddings aligned with manipulation semantics is not verified; no quantitative checks (e.g., hierarchy preservation metrics, embedding collapse analysis, or retrieval precision on held-out states) are reported to confirm that the geometry supports the claimed top-down retrieval and interpolation without introducing spurious states.
Authors: We acknowledge the absence of quantitative embedding validation. The revision will include hierarchy-preservation metrics (entailment satisfaction rate across the tree), embedding-collapse diagnostics (variance and norm statistics in the Poincaré ball), and retrieval precision/recall on held-out manipulation states. These checks will confirm that the geometry supports artifact-free top-down retrieval and interpolation. revision: yes
-
Referee: [§3.3] §3.3 (Background Consolidation): The mechanism of continuous refinement via interpolation and splitting is described at a high level, but the manuscript supplies no analysis of how these operations affect policy execution stability or whether they risk degrading performance on the original training distribution.
Authors: The referee correctly identifies the missing stability analysis. We will add experiments in the revision that measure policy success rates on the original training tasks before and after multiple consolidation rounds, together with execution-stability metrics. These results will show that geometric interpolation and structural splitting do not degrade performance on the seen distribution. revision: yes
Circularity Check
No circularity detected; ECHO is presented as an additive architectural module with empirical validation
full rationale
The paper introduces ECHO as a new memory framework that maps VLA hidden states via a hyperbolic autoencoder into a continuous hierarchical space, with organization via entailment constraints and background consolidation. No equations, derivations, or self-referential definitions appear that reduce the reported 12.8% success-rate gain or generalization improvements to fitted parameters defined by the same data or to self-citations whose load-bearing content is unverified. The framework is explicitly described as integrated into the existing π0 model, and performance claims rest on evaluations on LIBERO and real-world experiments rather than any closed mathematical chain. This is the standard case of an additive proposal whose central claims remain externally falsifiable through the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hyperbolic space with entailment constraints organizes VLA hidden states into a useful semantic hierarchy
invented entities (1)
-
Continuous Hierarchical Space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision- language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
-
[5]
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596, 2026
-
[6]
Runhao Li, Wenkai Guo, Zhenyu Wu, Changyuan Wang, Haoyuan Deng, Zhenyu Weng, Yap- Peng Tan, and Ziwei Wang. Map-vla: Memory-augmented prompting for vision-language-action model in robotic manipulation.arXiv preprint arXiv:2511.09516, 2025
-
[7]
Dejavu: Towards Experience Feedback Learning for Embodied Intelligence
Shaokai Wu, Yanbiao Ji, Qiuchang Li, Zhiyi Zhang, Qichen He, Wenyuan Xie, Guodong Zhang, Bayram Bayramli, Yue Ding, and Hongtao Lu. Dejavu: Towards experience feedback learning for embodied intelligence.arXiv preprint arXiv:2510.10181, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Goal2Skill: Long-Horizon Manipulation with Adaptive Planning and Reflection
Zhen Liu, Xinyu Ning, Zhe Hu, Xinxin Xie, Weize Li, Zhipeng Tang, Chongyu Wang, Zejun Yang, Hanlin Wang, Yitong Liu, et al. Goal2skill: Long-horizon manipulation with adaptive planning and reflection.arXiv preprint arXiv:2604.13942, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dongmei Jiang, and Liqiang Nie. Optimus-1: Hybrid multimodal memory empowered agents excel in long-horizon tasks.Advances in neural information processing systems, 37:49881–49913, 2024
work page 2024
-
[10]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision- language-action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Liangxuan Guo, Haoyang Chen, Yang Chen, Yanchao Bi, and Shan Yu. A neural network for modeling human concept formation, understanding and communication.Nature Computational Science, pages 1–15, 2026
work page 2026
-
[12]
Jiaxuan Chen, Yu Qi, Yueming Wang, and Gang Pan. Human-like cognitive generalization for large models via brain-in-the-loop supervision.arXiv preprint arXiv:2505.09085, 2025
-
[13]
Dharshan Kumaran, Demis Hassabis, and James L McClelland. What learning systems do intelligent agents need? complementary learning systems theory updated.Trends in cognitive sciences, 20(7):512–534, 2016. 10
work page 2016
-
[14]
James L McClelland, Bruce L McNaughton, and Randall C O’Reilly. Why there are comple- mentary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.Psychological review, 102(3):419, 1995
work page 1995
-
[15]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[17]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[21]
Retrieval-augmented embodied agents
Yichen Zhu, Zhicai Ou, Xiaofeng Mou, and Jian Tang. Retrieval-augmented embodied agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17985–17995, 2024
work page 2024
-
[22]
Quanting Xie, So Yeon Min, Pengliang Ji, Yue Yang, Tianyi Zhang, Kedi Xu, Aarav Bajaj, Rus- lan Salakhutdinov, Matthew Johnson-Roberson, and Yonatan Bisk. Embodied-rag: General non- parametric embodied memory for retrieval and generation.arXiv preprint arXiv:2409.18313, 2024
-
[23]
Statler: State-maintaining language models for embodied reasoning
Takuma Yoneda, Jiading Fang, Peng Li, Huanyu Zhang, Tianchong Jiang, Shengjie Lin, Ben Picker, David Yunis, Hongyuan Mei, and Matthew R Walter. Statler: State-maintaining language models for embodied reasoning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 15083–15091. IEEE, 2024
work page 2024
-
[24]
N., Hutchins, D., and Szegedy, C
Yuhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing trans- formers.arXiv preprint arXiv:2203.08913, 2022
-
[25]
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
work page 1999
-
[26]
Accelerating reinforcement learning with learned skill priors
Karl Pertsch, Youngwoon Lee, and Joseph Lim. Accelerating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR, 2021
work page 2021
-
[27]
Representation tradeoffs for hyperbolic embeddings
Frederic Sala, Chris De Sa, Albert Gu, and Christopher Ré. Representation tradeoffs for hyperbolic embeddings. InInternational conference on machine learning, pages 4460–4469. PMLR, 2018
work page 2018
-
[28]
Wordnet: a lexical database for english.Communications of the ACM, 38(11): 39–41, 1995
George A Miller. Wordnet: a lexical database for english.Communications of the ACM, 38(11): 39–41, 1995
work page 1995
-
[29]
Maximillian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical represen- tations.Advances in neural information processing systems, 30, 2017. 11
work page 2017
-
[30]
Ines Chami, Zhitao Ying, Christopher Ré, and Jure Leskovec. Hyperbolic graph convolutional neural networks.Advances in neural information processing systems, 32, 2019
work page 2019
-
[31]
Hyperbolic graph attention network.IEEE Transactions on Big Data, 8(6):1690–1701, 2021
Yiding Zhang, Xiao Wang, Chuan Shi, Xunqiang Jiang, and Yanfang Ye. Hyperbolic graph attention network.IEEE Transactions on Big Data, 8(6):1690–1701, 2021
work page 2021
-
[32]
Emile Mathieu, Charline Le Lan, Chris J Maddison, Ryota Tomioka, and Yee Whye Teh. Continuous hierarchical representations with poincaré variational auto-encoders.Advances in neural information processing systems, 32, 2019
work page 2019
-
[33]
R., Falorsi, L., De Cao, N., Kipf, T., and Tomczak, J
Tim R Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M Tomczak. Hyper- spherical variational auto-encoders.arXiv preprint arXiv:1804.00891, 2018
-
[34]
Hyperbolic entailment cones for learning hierarchical embeddings
Octavian Ganea, Gary Bécigneul, and Thomas Hofmann. Hyperbolic entailment cones for learning hierarchical embeddings. InInternational conference on machine learning, pages 1646–1655. PMLR, 2018
work page 2018
-
[35]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[36]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language- action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 12 A Core Network Architecture and Hyperparameters A.1 Hyperbolic Autoencoder Architecture The Hyperbolic A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.