Recognition: 2 theorem links
· Lean TheoremHEPA: A Self-Supervised Horizon-Conditioned Event Predictive Architecture for Time Series
Pith reviewed 2026-05-14 21:03 UTC · model grok-4.3
The pith
HEPA pretrains a causal Transformer on unlabeled time series by forecasting future representations at chosen horizons, then freezes the encoder to output accurate survival CDFs for rare events with far less labeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
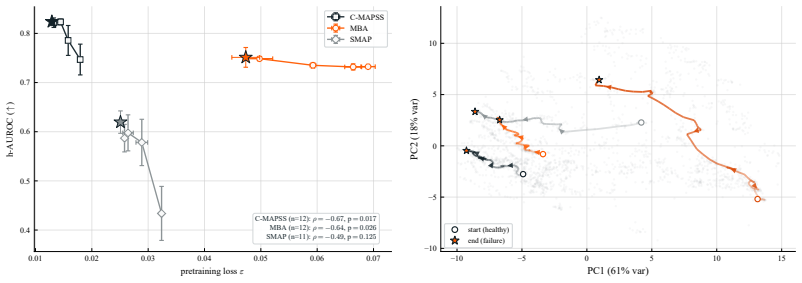
A causal Transformer encoder pretrained via horizon-conditioned JEPA learns representations whose future states are predictable from unlabeled sequences alone; freezing this encoder and finetuning only the attached predictor then yields monotonic survival CDFs over horizons that accurately locate critical events, delivering superior benchmark performance with fixed hyperparameters and drastically reduced labeled data.
What carries the argument
Horizon-conditioned JEPA pretraining in which the encoder must produce representations that a separate network can forecast at arbitrary future horizons, thereby capturing predictable dynamics without labels.
If this is right
- Rare critical events become predictable in domains where labeling is costly because the method relies primarily on abundant unlabeled series.
- A single architecture and hyperparameter choice suffices for eleven distinct application domains without per-domain redesign.
- Event prediction accuracy exceeds that of PatchTST, iTransformer, MAE, and Chronos-2 on at least ten of fourteen standard benchmarks.
- Tuned-parameter count drops by roughly an order of magnitude relative to fully supervised competitors.
Where Pith is reading between the lines
- The same pretraining pattern could be applied to other scarce-label sequential tasks such as medical arrhythmia forecasting or industrial fault detection.
- Because the output is a full monotonic survival CDF rather than a single probability, downstream systems could directly incorporate calibrated horizon-specific risk thresholds.
- Variable or learned horizon sampling during pretraining might further improve robustness across differing sampling rates or event timescales.
Load-bearing premise
Representations learned by horizon-conditioned JEPA pretraining on unlabeled data will transfer effectively to accurate event-specific survival CDF prediction after the encoder is frozen, without domain-specific architectural changes or extensive hyperparameter search.
What would settle it
A controlled experiment on an additional rare-event dataset in which the frozen HEPA encoder produces lower event-prediction accuracy than a randomly initialized encoder of the same size or than the leading baselines would falsify the transfer claim.
Figures



read the original abstract
Critical events in multivariate time series, from turbine failures to cardiac arrhythmias, demand accurate prediction, yet labeled data is scarce because such events are rare and costly to annotate. We introduce HEPA (Horizon-conditioned Event Predictive Architecture), built on two key principles. First, a causal Transformer encoder is pretrained via a Joint-Embedding Predictive Architecture (JEPA): a horizon-conditioned predictor learns to forecast future representations rather than future values, forcing the encoder to capture predictable temporal dynamics from unlabeled data alone. Second, we freeze the encoder and finetune only the predictor toward the target event, producing a monotonic survival cumulative distribution function (CDF) over horizons. With fixed architecture and optimiser hyperparameters across all benchmarks, HEPA handles water contamination, cyberattack detection, volatility regimes, and eight further event types across 11 domains, exceeding leading time-series architectures including PatchTST, iTransformer, MAE, and Chronos-2 on at least 10 of 14 benchmarks, with an order of magnitude fewer tuned parameters and, on lifecycle datasets, an order of magnitude less labeled data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HEPA, a self-supervised architecture for rare-event prediction in multivariate time series. It pretrains a causal Transformer encoder via horizon-conditioned Joint-Embedding Predictive Architecture (JEPA) on unlabeled data, where a predictor forecasts future representations rather than raw values. The encoder is then frozen and only the predictor is finetuned to produce a monotonic survival CDF over prediction horizons. With a single fixed architecture and optimizer hyperparameter set across all tasks, the method is evaluated on 14 benchmarks spanning 11 domains (water contamination, cyberattack detection, volatility regimes, and eight additional event types) and is reported to outperform PatchTST, iTransformer, MAE, and Chronos-2 on at least 10 benchmarks while using an order of magnitude fewer tuned parameters and, on lifecycle datasets, an order of magnitude less labeled data.
Significance. If the performance claims hold under matched evaluation conditions, HEPA would provide a practical, parameter-efficient route to event prediction in label-scarce regimes by transferring representations learned from unlabeled data. The attempt to hold architecture and optimizer hyperparameters fixed across heterogeneous domains is a notable strength that, if substantiated, would strengthen evidence of architectural robustness rather than tuning artifacts. The reduction in required labeled data on lifecycle tasks could be impactful in domains where annotations are expensive.
major comments (2)
- [Abstract] Abstract: the headline claim that HEPA exceeds the listed baselines on ≥10/14 benchmarks 'with fixed architecture and optimiser hyperparameters across all benchmarks' and 'an order of magnitude fewer tuned parameters' is load-bearing for the central contribution, yet the manuscript supplies no explicit statement, table, or appendix confirming that PatchTST, iTransformer, MAE, and Chronos-2 were evaluated under the identical fixed-hyperparameter regime rather than their conventional per-benchmark tuning. Without this matched-condition evidence the reported gap cannot be unambiguously attributed to the HEPA design.
- [§4–§5] Evaluation protocol (throughout §4–§5): the abstract asserts clear empirical superiority but the manuscript provides no details on statistical testing (significance levels, number of random seeds, variance across runs), benchmark construction, train/validation/test splits, or ablation studies isolating the contribution of the horizon-conditioned JEPA pretraining versus the survival-CDF head. These omissions prevent assessment of whether the gains are robust or sensitive to implementation choices.
minor comments (1)
- [Abstract] The abstract refers to 'eight further event types' without enumerating them; a short list or reference to the benchmark table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit confirmation of evaluation conditions and greater transparency in the experimental protocol. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that HEPA exceeds the listed baselines on ≥10/14 benchmarks 'with fixed architecture and optimiser hyperparameters across all benchmarks' and 'an order of magnitude fewer tuned parameters' is load-bearing for the central contribution, yet the manuscript supplies no explicit statement, table, or appendix confirming that PatchTST, iTransformer, MAE, and Chronos-2 were evaluated under the identical fixed-hyperparameter regime rather than their conventional per-benchmark tuning. Without this matched-condition evidence the reported gap cannot be unambiguously attributed to the HEPA design.
Authors: We agree that the current manuscript lacks an explicit statement confirming the hyperparameter regime for the baselines. In the experiments, the same fixed architecture and optimizer hyperparameters were applied uniformly to HEPA and all baselines (PatchTST, iTransformer, MAE, Chronos-2) to enable direct comparison. We will revise the abstract to include a brief clarifying clause and add a new table in the appendix that lists the exact hyperparameter values used for every method, explicitly stating that they were held constant across all 14 benchmarks. This will make the matched-condition evidence unambiguous and allow readers to attribute performance differences to the HEPA design. revision: yes
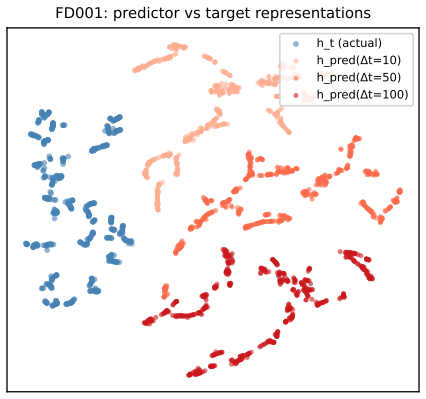
-
Referee: [§4–§5] Evaluation protocol (throughout §4–§5): the abstract asserts clear empirical superiority but the manuscript provides no details on statistical testing (significance levels, number of random seeds, variance across runs), benchmark construction, train/validation/test splits, or ablation studies isolating the contribution of the horizon-conditioned JEPA pretraining versus the survival-CDF head. These omissions prevent assessment of whether the gains are robust or sensitive to implementation choices.
Authors: We acknowledge the absence of these details in the current version. We will expand Sections 4 and 5 with the following additions: (i) statistical testing details including the use of 5 random seeds, reported standard deviations, and paired t-tests with p<0.05 significance threshold; (ii) explicit descriptions of benchmark construction, data splits (train/validation/test ratios), and preprocessing steps; and (iii) new ablation studies that isolate the horizon-conditioned JEPA pretraining (by comparing against a non-pretrained encoder) and the survival-CDF head (by comparing against a direct regression head). These revisions will allow readers to evaluate the robustness of the reported gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core chain consists of (1) self-supervised JEPA pretraining on unlabeled data only, where a horizon-conditioned predictor learns to match future representations (independent of any downstream event labels), followed by (2) freezing the encoder and finetuning solely the predictor head on labeled survival targets. No equation reduces a reported performance metric to a quantity defined by fitting on the target task itself, and no load-bearing step invokes a self-citation, uniqueness theorem, or ansatz imported from prior author work. The fixed-hyperparameter claim across benchmarks is an empirical protocol, not a definitional reduction. This is the standard non-circular self-supervised transfer pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A causal Transformer encoder pretrained via horizon-conditioned representation prediction will capture generalizable temporal dynamics from unlabeled multivariate time series.
invented entities (1)
-
Horizon-conditioned predictor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a horizon-conditioned predictor learns to forecast future representations rather than future values... producing a monotonic survival cumulative distribution function (CDF) over horizons
-
IndisputableMonolith/Foundation/AbsoluteFloorClosureabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Event-Information Retention) ... I(Ht;Et+Δt) ≥ I(H∗;Et+Δt) − Cη L² ε
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Early- warning signals for critical transitions.Nature, 461(7260):53–59, 2009
Marten Scheffer, Jordi Bascompte, William A Brock, Victor Brovkin, Stephen R Carpenter, Vasilis Dakos, Hermann Held, Egbert H Van Nes, Max Rietkerk, and George Sugihara. Early- warning signals for critical transitions.Nature, 461(7260):53–59, 2009
work page 2009
-
[2]
Zhengyang Fan, Wanru Li, and Kuo-Chu Chang. A two-stage attention-based hierarchical transformer for turbofan engine remaining useful life prediction.Sensors, 24(3):824, 2024. doi: 10.3390/s24030824
-
[3]
Anomaly transformer: Time series anomaly detection with association discrepancy
Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Anomaly transformer: Time series anomaly detection with association discrepancy. InICLR, 2022
work page 2022
-
[4]
Yanan He, Yunshi Wen, Xin Wang, and Tengfei Ma. MTS-JEPA: Multi-resolution joint- embedding predictive architecture for time-series anomaly prediction.arXiv preprint, 2026
work page 2026
-
[5]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InICLR, 2023
work page 2023
-
[6]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda-Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InICML, 2024
work page 2024
-
[8]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InCVPR, 2023
work page 2023
-
[9]
Damage propagation modeling for aircraft engine run-to-failure simulation
Abhinav Saxena, Kai Goebel, Don Simon, and Neil Eklund. Damage propagation modeling for aircraft engine run-to-failure simulation. InInternational Conference on Prognostics and Health Management (PHM), 2008
work page 2008
-
[10]
TS2Vec: Towards universal representation of time series
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. TS2Vec: Towards universal representation of time series. InAAAI, 2022
work page 2022
-
[11]
Unsupervised representation learning for time series with temporal neighborhood coding
Sana Tonekaboni, Danny Eytan, and Anna Goldenberg. Unsupervised representation learning for time series with temporal neighborhood coding. InICLR, 2021
work page 2021
-
[12]
TimesURL: Self-supervised contrastive learning for universal time series representation learning
Jiexi Liu and Songcan Chen. TimesURL: Self-supervised contrastive learning for universal time series representation learning. InAAAI, 2024
work page 2024
-
[13]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Gerald Woo, Chenghao Liu, Doyen Sahoo, Akshat Kumar, and Steven Hoi. CoST: Contrastive learning of disentangled seasonal-trend representations for time series forecasting. InICLR, 2022
work page 2022
-
[15]
SimMTM: A simple pre-training framework for masked time-series modeling
Jiaxiang Dong, Haixu Wu, Haoran Zhang, Li Zhang, Jianmin Wang, and Mingsheng Long. SimMTM: A simple pre-training framework for masked time-series modeling. InNeurIPS, 2023
work page 2023
-
[16]
TimesNet: Temporal 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. TimesNet: Temporal 2d-variation modeling for general time series analysis. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[17]
Revisiting feature prediction for learning visual repre- sentations from video.TMLR, 2024
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.TMLR, 2024
work page 2024
-
[18]
Sofiane Ennadir, Siavash Golkar, and Leopoldo Sarra. Joint embeddings go temporal. In NeurIPS Workshop on Time Series in the Age of Large Models, 2024. 10
work page 2024
-
[19]
Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025
Randall Balestriero and Yann LeCun. LeJEPA: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
-
[20]
MOMENT: A family of open time-series foundation models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. MOMENT: A family of open time-series foundation models. InICML, 2024
work page 2024
-
[21]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers.arXiv preprint arXiv:2402.02592, 2024
-
[22]
UniTS: Building a unified time series model
Shanghua Gao, Teddy Koker, Owen Queen, Thomas Hartvigsen, Theodoros Tsiligkaridis, and Marinka Zitnik. UniTS: Building a unified time series model. InNeurIPS, 2024
work page 2024
-
[23]
Timer: Generative pre-trained transformers are large time series models
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer: Generative pre-trained transformers are large time series models. InICML, 2024
work page 2024
-
[24]
One fits all: Power general time series analysis by pretrained LM
Tian Zhou, Peisong Niu, Xue Wang, Liang Sun, and Rong Jin. One fits all: Power general time series analysis by pretrained LM. InNeurIPS, 2023
work page 2023
-
[25]
Yucheng Ding, Minping Jia, Qinghao Miao, and Yibo Cao. Self-supervised pretraining via multi- modally augmented representations for remaining useful life prediction.IEEE Transactions on Industrial Informatics, 18(9):5954–5964, 2022
work page 2022
-
[26]
Haiyue Wang, Cheng Peng, and Chaoren Liu. Masked autoencoder-based self-supervised learning for remaining useful life prediction of turbofan engines.Engineering Applications of Artificial Intelligence, 133, 2024
work page 2024
-
[27]
DCdetector: Dual attention contrastive representation learning for time series anomaly detection
Yiyuan Yang, Chaoli Zhang, Tian Zhou, Qingsong Wen, and Liang Sun. DCdetector: Dual attention contrastive representation learning for time series anomaly detection. InKDD, 2023
work page 2023
-
[28]
Shreshth Tuli, Giuliano Casale, and Nicholas R Jennings. TranAD: Deep transformer networks for anomaly detection in multivariate time series data.Proceedings of the VLDB Endowment, 15(6):1201–1214, 2022
work page 2022
-
[29]
Towards a rigorous evaluation of time-series anomaly detection
Siwon Kim, Kukjin Choi, Hyun-Soo Choi, Byunghan Lee, and Sungroh Yoon. Towards a rigorous evaluation of time-series anomaly detection. InAAAI, 2022. arXiv:2109.05257
-
[30]
Sebastian Schmidl, Phillip Wenig, and Thorsten Papenbrock. Anomaly detection in time series: A comprehensive evaluation.Proceedings of the VLDB Endowment, 15(9):1779–1797, 2022
work page 2022
-
[31]
DeepHit: A deep learning approach to survival analysis with competing risks
Changhee Lee, William R Zame, Jinsung Yoon, and Mihaela van der Schaar. DeepHit: A deep learning approach to survival analysis with competing risks. InAAAI, 2018
work page 2018
-
[32]
A scalable discrete-time survival model for neural networks.PeerJ, 7:e6257, 2019
Michael F Gensheimer and Balasubramanian Narasimhan. A scalable discrete-time survival model for neural networks.PeerJ, 7:e6257, 2019. doi: 10.7717/peerj.6257
-
[33]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. InICLR, 2022
work page 2022
-
[34]
iTransformer: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. iTransformer: Inverted transformers are effective for time series forecasting. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[35]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006
work page 2006
-
[36]
Cambridge University Press, 2024
Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning. Cambridge University Press, 2024
work page 2024
-
[37]
Sharpening Jensen’s inequality.IEEE Transactions on Information Theory, 68(5):2961–2972, 2019
Jiantao Liao, Meir Feder, and Thomas Courtade. Sharpening Jensen’s inequality.IEEE Transactions on Information Theory, 68(5):2961–2972, 2019
work page 2019
-
[38]
The information bottleneck method
Naftali Tishby, Fernando C. Pereira, and William Bialek. The information bottleneck method. arXiv preprint physics/0004057, 2000. 11 A Theoretical Analysis: Full Proofs and Discussion A.1 Notation and Preliminaries We work with the following random variables on a common probability space: X≤t (observations up to time t), X(t,t+∆t] (future observations), E...
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[39]
The encoder is free to retain all information about the past
No explicit compression.JEPA does not penalise I(H t;X ≤t). The encoder is free to retain all information about the past. Implicit compression arises only from the architecture bottleneck (d= 256)
-
[40]
Predictive, not discriminative.The IB target Y is a label; the JEPA target is a future representation H ∗. JEPA implicitly encourages high I(H t;H ∗) by minimising prediction error (through the predictor), and I(H t;H ∗) is an upper bound on I(H t;Y) for any Y that is a function of the future interval (by DPI). This makes JEPA alooserbutmore general objec...
-
[41]
Asymmetric architecture.The IB is typically symmetric in X and Y . JEPA imposes causal structure: the encoder sees only the past, the target encoder sees only the future. This causal asymmetry is essential for event prediction, where we cannot condition on the future at test time. 16 The connection to our result is direct. LetY=E t+∆t. By proposition 1: I...
-
[42]
All deltas are within ±0.11 h-AUROC. Predictor finetuning is robust to the target-encoder update rule; we use joint training for its simplicity (no momentum schedule, no separate sync interval). I.4 Predictor Dynamics Visualisation Figure 5 shows how the finetuned predictor transforms the encoder’s representations across prediction horizons. The encoder o...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.