Recognition: no theorem link
Spurious Correlation Learning in Preference Optimization: Mechanisms, Consequences, and Mitigation via Tie Training
Pith reviewed 2026-05-13 06:26 UTC · model grok-4.3
The pith
Preference optimization induces spurious feature reliance through mean bias and correlation leakage, creating a vulnerability to distribution shift that more training data cannot fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In log-linear policies, standard preference-learning objectives induce reliance on spurious features through mean spurious bias and causal-spurious correlation leakage. This reliance produces an irreducible vulnerability to distribution shift because more data drawn from the identical training distribution fails to reduce dependence on the spurious features. Tie training, which augments the dataset with ties (equal-utility preference pairs), supplies data-driven regularization that reduces spurious learning without degrading causal learning.
What carries the argument
Tie training, a data augmentation method that inserts equal-utility preference pairs to create data-driven regularization against spurious correlations.
Load-bearing premise
The mechanisms and mitigation identified for log-linear policies extend to neural networks and large language models without significant degradation of causal learning.
What would settle it
An experiment that adds increasing volumes of in-distribution preference data and measures a corresponding drop in the model's reliance on known spurious features would falsify the claim of irreducible vulnerability.
Figures
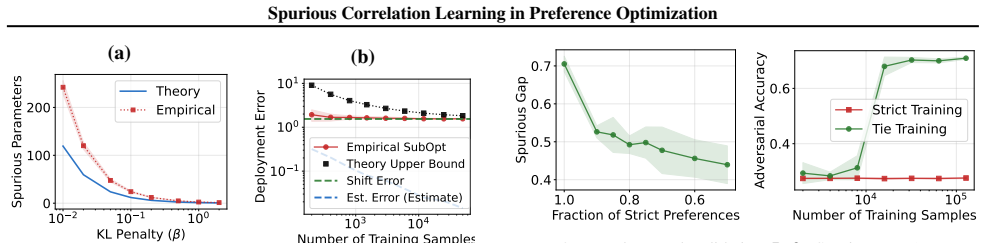

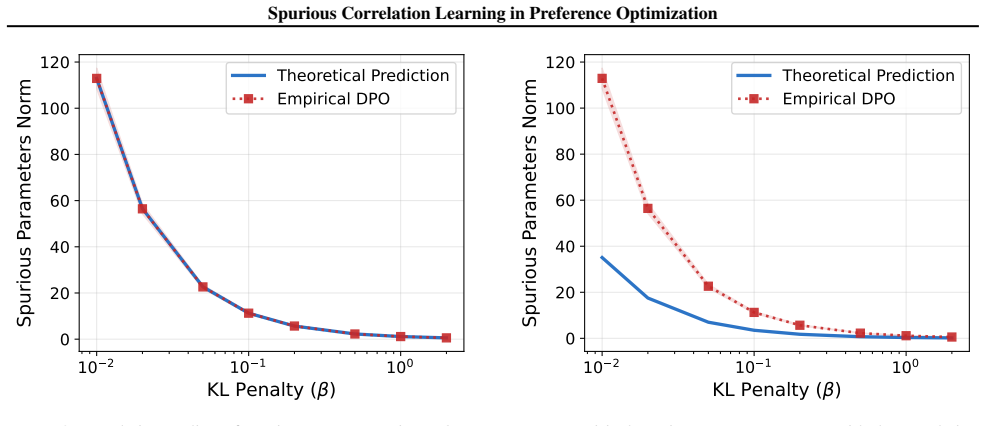
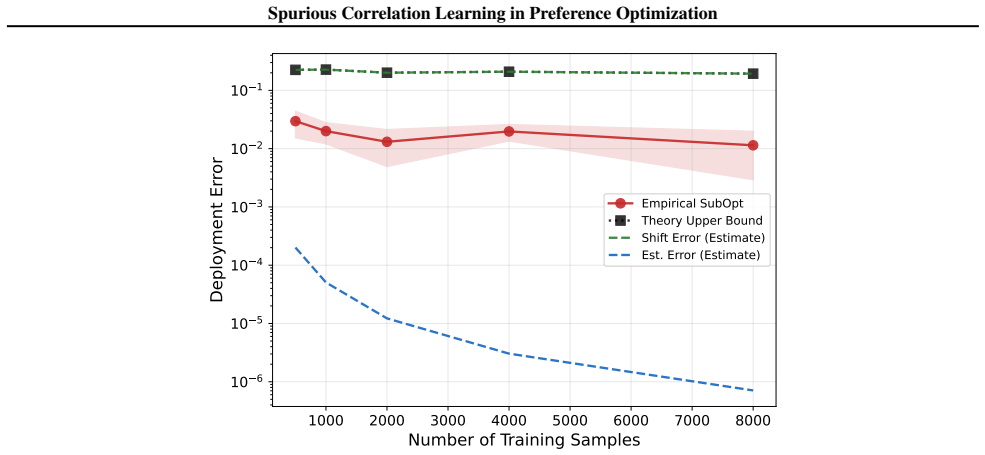
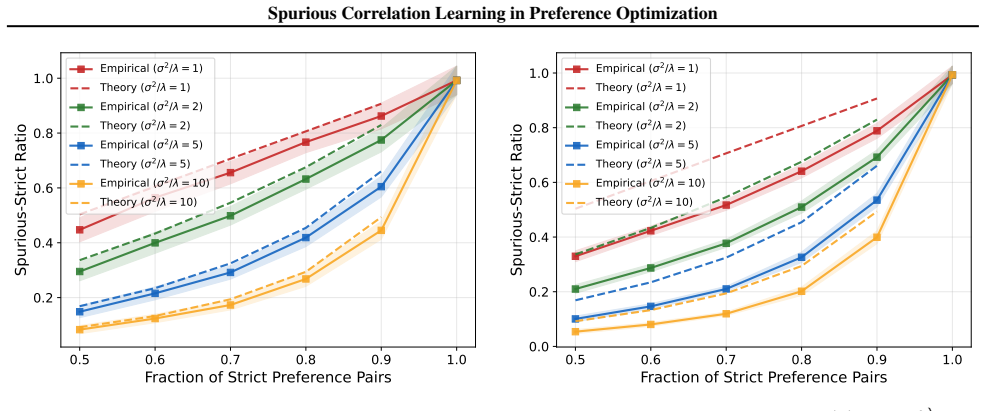





read the original abstract
Preference learning methods such as Direct Preference Optimization (DPO) are known to induce reliance on spurious correlations, leading to sycophancy and length bias in today's language models and potentially severe goal misgeneralization in future systems. In this work, we provide a unified theoretical analysis of this phenomenon, characterizing the mechanisms of spurious learning, its consequences on deployment, and a provable mitigation strategy. Focusing on log-linear policies, we show that standard preference-learning objectives induce reliance on spurious features at the population level through two channels: mean spurious bias and causal--spurious correlation leakage. We then show that this reliance creates an irreducible vulnerability to distribution shift: more data from the same training distribution fails to reduce the model's dependence on spurious features. To address this, we propose tie training, a data augmentation strategy using ties (equal-utility preference pairs) to introduce data-driven regularization. We demonstrate that this approach selectively reduces spurious learning without degrading causal learning. Finally, we validate our theory on log-linear models and provide empirical evidence that both the spurious learning mechanisms and the benefits of tie training persist for neural networks and large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard preference optimization objectives (e.g., DPO) induce spurious feature reliance in log-linear policies through two population-level mechanisms—mean spurious bias and causal-spurious correlation leakage—creating an irreducible vulnerability to distribution shift that additional in-distribution data cannot resolve. It proposes tie training (augmenting with equal-utility preference pairs) as a data-driven regularizer that selectively mitigates spurious learning without harming causal learning, validates the theory on log-linear models, and provides empirical support that the mechanisms and mitigation benefits extend to neural networks and LLMs.
Significance. If the central claims hold, the work supplies a concrete mechanistic account of why preference learning produces sycophancy and length bias, together with a simple, data-augmentation-based fix that is provably effective under log-linear assumptions. The demonstration that more training data from the same distribution cannot eliminate the spurious dependence is a useful negative result for alignment research. The empirical extension to LLMs, if reproducible, would directly inform practical mitigation strategies for current models.
major comments (3)
- [Abstract / Theoretical Analysis] Abstract and theoretical sections: the characterization of spurious learning via mean spurious bias and causal-spurious correlation leakage, as well as the proof that tie training is a selective regularizer, are derived exclusively under log-linear policy assumptions; the manuscript provides no formal argument or population-level analysis showing that the same two channels dominate in over-parameterized neural networks, where different optimization dynamics can exploit correlations.
- [Empirical Validation] Empirical validation section: the claim that 'both the spurious learning mechanisms and the benefits of tie training persist for neural networks and large language models' rests on experiments whose data exclusion rules, spurious-feature construction, and controls for causal-feature preservation are not fully specified, preventing assessment of whether the reported gains are robust or sensitive to implementation details.
- [Consequences on Deployment] Consequences section: the assertion of an 'irreducible vulnerability to distribution shift' is shown only for log-linear policies; without a corresponding analysis or counter-example for neural policies, the load-bearing claim that more data from the training distribution cannot reduce spurious dependence does not yet extend to the motivating LLM setting.
minor comments (2)
- [Tie Training Definition] Notation for tie training could be formalized with an explicit objective or augmentation rule to make the method reproducible from the text alone.
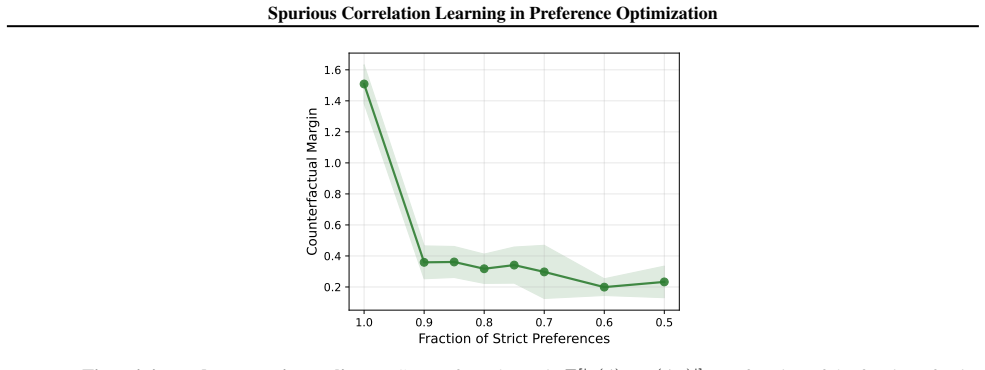
- [Figures] Several figures comparing spurious vs. causal accuracy under increasing data would benefit from error bars or multiple random seeds to support the 'irreducible' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the scope of our theoretical results and committing to improvements in the empirical details and discussion of limitations.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical sections: the characterization of spurious learning via mean spurious bias and causal-spurious correlation leakage, as well as the proof that tie training is a selective regularizer, are derived exclusively under log-linear policy assumptions; the manuscript provides no formal argument or population-level analysis showing that the same two channels dominate in over-parameterized neural networks, where different optimization dynamics can exploit correlations.
Authors: We agree that the formal proofs and population-level analysis are derived exclusively under log-linear policy assumptions, as stated throughout the manuscript. This choice enables exact characterization of the two mechanisms and the selective regularization property of tie training. For over-parameterized neural networks we provide only empirical evidence that the mechanisms and mitigation benefits persist. In revision we will expand the discussion section to explicitly note the absence of a formal extension and to articulate why the population-level mechanisms are expected to remain relevant despite differing optimization dynamics. revision: partial
-
Referee: [Empirical Validation] Empirical validation section: the claim that 'both the spurious learning mechanisms and the benefits of tie training persist for neural networks and large language models' rests on experiments whose data exclusion rules, spurious-feature construction, and controls for causal-feature preservation are not fully specified, preventing assessment of whether the reported gains are robust or sensitive to implementation details.
Authors: We acknowledge that the current manuscript does not provide sufficient implementation detail for full reproducibility. In the revised version we will add an expanded experimental appendix that fully specifies the data exclusion rules, the precise construction of spurious features, the controls used to preserve causal features, and all hyper-parameter choices. These additions will allow readers to assess robustness directly. revision: yes
-
Referee: [Consequences on Deployment] Consequences section: the assertion of an 'irreducible vulnerability to distribution shift' is shown only for log-linear policies; without a corresponding analysis or counter-example for neural policies, the load-bearing claim that more data from the training distribution cannot reduce spurious dependence does not yet extend to the motivating LLM setting.
Authors: The formal proof of irreducible vulnerability is indeed limited to log-linear policies. For neural networks and LLMs we report only empirical observations that additional in-distribution data fails to eliminate spurious dependence. In revision we will revise the consequences section to clearly separate the proven log-linear result from the supporting empirical findings and to state that a formal extension to neural policies remains an open question. revision: partial
- A formal population-level analysis demonstrating that the two identified channels dominate in over-parameterized neural networks
Circularity Check
No significant circularity; derivation is self-contained for log-linear case with empirical extension
full rationale
The paper's central derivation characterizes spurious learning mechanisms (mean spurious bias and causal-spurious correlation leakage) explicitly under log-linear policy assumptions via population-level analysis of preference objectives, without reducing to fitted parameters or self-definitions. Tie training is introduced as a new data-augmentation strategy and analyzed for its selective regularization effect. Extension to neural networks and LLMs is framed as empirical validation rather than a theoretical claim, with no load-bearing self-citations, ansatz smuggling, or renaming of known results. The derivation chain remains independent of its inputs and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Analysis restricted to log-linear policies
invented entities (1)
-
Tie training
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[5]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[6]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
work page 2020
-
[7]
arXiv preprint arXiv:2502.00657 , year=
Llm safety alignment is divergence estimation in disguise , author=. arXiv preprint arXiv:2502.00657 , year=
-
[8]
A long way to go: Investigat- ing length correlations in RLHF.arXiv preprint arXiv:2310.03716,
A long way to go: Investigating length correlations in rlhf , author=. arXiv preprint arXiv:2310.03716 , year=
-
[9]
Towards Understanding Sycophancy in Language Models
Towards understanding sycophancy in language models , author=. arXiv preprint arXiv:2310.13548 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
From lists to emojis: How format bias affects model alignment , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
arXiv preprint arXiv:2006.09994 , year=
Noise or signal: The role of image backgrounds in object recognition , author=. arXiv preprint arXiv:2006.09994 , year=
-
[12]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[13]
International Conference on Machine Learning , pages=
Just train twice: Improving group robustness without training group information , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[14]
International conference on machine learning , pages=
On the spectral bias of neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[15]
Advances in neural information processing systems , volume=
Sgd on neural networks learns functions of increasing complexity , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2403.03375 , year=
Complexity matters: Dynamics of feature learning in the presence of spurious correlations , author=. arXiv preprint arXiv:2403.03375 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Simplicity bias in 1-hidden layer neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in Neural Information Processing Systems , volume=
The pitfalls of simplicity bias in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Gradient starvation: A learning proclivity in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
On feature learning in the presence of spurious correlations , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Last layer re-training is sufficient for robustness to spurious correlations
Last layer re-training is sufficient for robustness to spurious correlations , author=. arXiv preprint arXiv:2204.02937 , year=
-
[22]
arXiv preprint arXiv:2310.16228 , year=
On the foundations of shortcut learning , author=. arXiv preprint arXiv:2310.16228 , year=
-
[23]
arXiv preprint arXiv:2502.01347 , year=
Spurious Correlations in High Dimensional Regression: The Roles of Regularization, Simplicity Bias and Over-Parameterization , author=. arXiv preprint arXiv:2502.01347 , year=
-
[24]
A unified theoretical analysis of private and robust offline alignment: from rlhf to dpo , author=. arXiv preprint arXiv:2505.15694 , year=
-
[25]
International Conference on Machine Learning , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[26]
International Conference on Artificial Intelligence and Statistics , pages=
Differentially private reward estimation with preference feedback , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[27]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
work page 1952
-
[28]
Gibbs sampling from human feedback: A provable kl-constrained framework for rlhf
Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint , author=. arXiv preprint arXiv:2312.11456 , year=
-
[29]
International Conference on Machine Learning , pages=
An investigation of why overparameterization exacerbates spurious correlations , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[30]
arXiv preprint arXiv:2110.04301 , year=
Salient imagenet: How to discover spurious features in deep learning? , author=. arXiv preprint arXiv:2110.04301 , year=
-
[31]
International Conference on Machine Learning , pages=
Examining and combating spurious features under distribution shift , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[32]
arXiv preprint arXiv:2310.10076 , year=
Verbosity bias in preference labeling by large language models , author=. arXiv preprint arXiv:2310.10076 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Defining and characterizing reward gaming , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Open problems and fundamental limitations of reinforcement learning from human feedback , author=. arXiv preprint arXiv:2307.15217 , year=
work page internal anchor Pith review arXiv
-
[35]
Invariant risk minimization , author=. arXiv preprint arXiv:1907.02893 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[36]
arXiv preprint arXiv:2502.15657 , year=
Superintelligent agents pose catastrophic risks: Can scientist ai offer a safer path? , author=. arXiv preprint arXiv:2502.15657 , year=
-
[37]
The alignment problem from a deep learning perspective
The alignment problem from a deep learning perspective , author=. arXiv preprint arXiv:2209.00626 , year=
-
[38]
arXiv preprint arXiv:1906.01820 , year =
Risks from learned optimization in advanced machine learning systems , author=. arXiv preprint arXiv:1906.01820 , year=
-
[39]
Goal misgeneralization: Why correct specifications aren’t enough for correct goals, 2022
Goal misgeneralization: Why correct specifications aren't enough for correct goals , author=. arXiv preprint arXiv:2210.01790 , year=
-
[40]
International Conference on Machine Learning , pages=
Goal misgeneralization in deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[41]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards robust classification model by counterfactual and invariant data generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
arXiv preprint arXiv:2106.02112 , year=
Finding and fixing spurious patterns with explanations , author=. arXiv preprint arXiv:2106.02112 , year=
-
[44]
arXiv preprint arXiv:2403.00409 , year=
Provably robust dpo: Aligning language models with noisy feedback , author=. arXiv preprint arXiv:2403.00409 , year=
-
[45]
arXiv preprint arXiv:2407.07880 , year=
Towards robust alignment of language models: Distributionally robustifying direct preference optimization , author=. arXiv preprint arXiv:2407.07880 , year=
-
[46]
arXiv preprint arXiv:2505.08849 , year=
Improved Algorithms for Differentially Private Language Model Alignment , author=. arXiv preprint arXiv:2505.08849 , year=
-
[47]
Conference on Learning Theory , pages=
Contextual dueling bandits , author=. Conference on Learning Theory , pages=. 2015 , organization=
work page 2015
-
[48]
International conference on artificial intelligence and statistics , pages=
Dueling rl: Reinforcement learning with trajectory preferences , author=. International conference on artificial intelligence and statistics , pages=. 2023 , organization=
work page 2023
-
[49]
In Findings of the Association for Computational Linguistics: ACL 2024, pages 4998–5017, 2024
Disentangling length from quality in direct preference optimization , author=. arXiv preprint arXiv:2403.19159 , year=
-
[50]
arXiv preprint arXiv:2307.08701 , year=
Alpagasus: Training a better alpaca with fewer data , author=. arXiv preprint arXiv:2307.08701 , year=
- [51]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.