Recognition: 2 theorem links
· Lean TheoremScalable linearized gate set tomography
Pith reviewed 2026-05-13 02:35 UTC · model grok-4.3
The pith
Linearized gate set tomography scales error characterization to many-qubit systems by using sparse models and a linear approximation on shallow-circuit data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
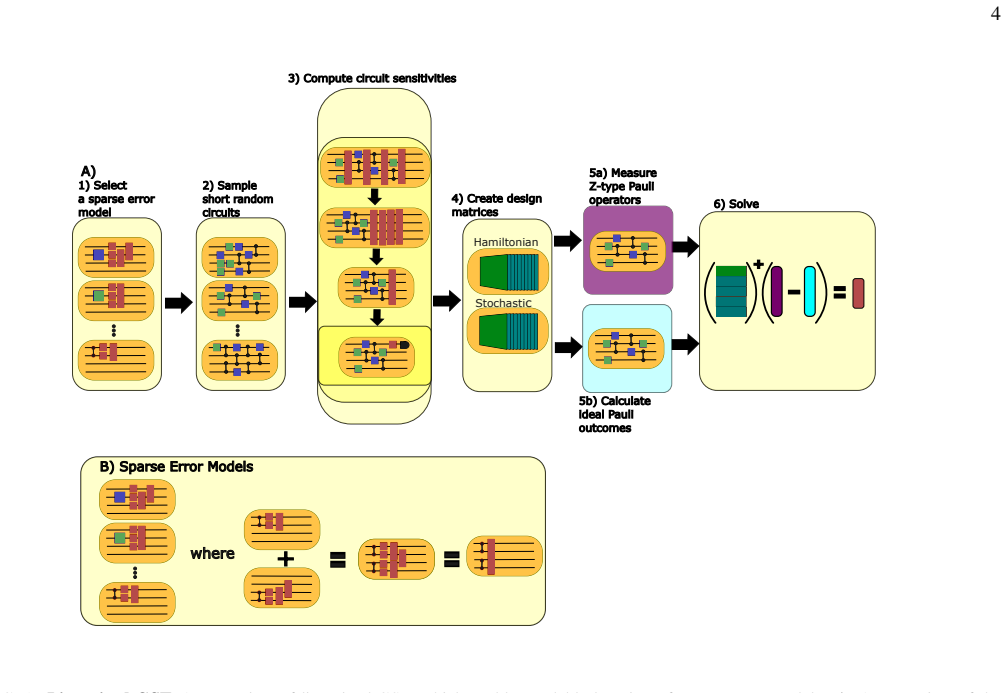
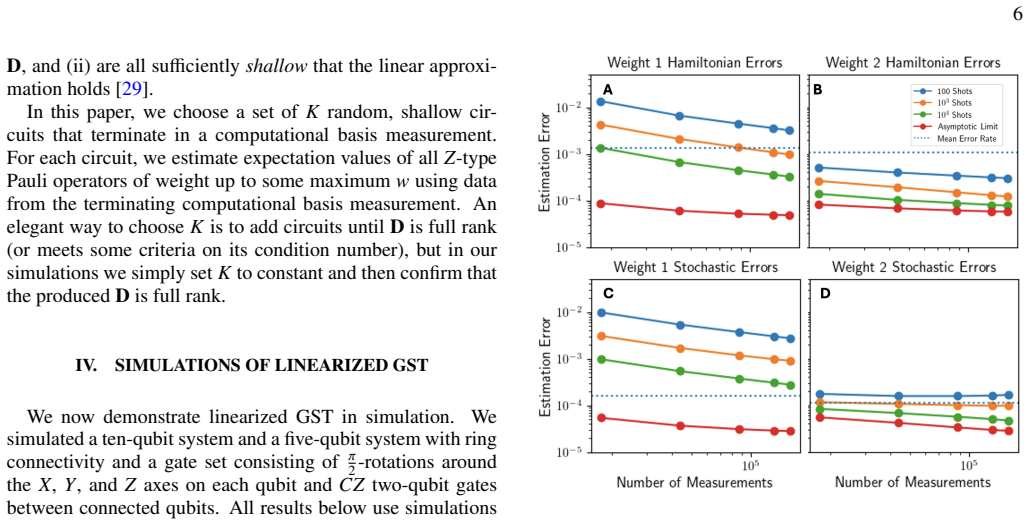
Linearized gate set tomography enables characterization of many-qubit systems. It relies on sparse error models, a linear approximation to enable efficient data fitting, and data from shallow circuits so that the systematic error in the linear approximation is small. The technique is accurate in simulations of a ten-qubit system with coherent and stochastic errors including coherent crosstalk, and it is robust in the presence of additional errors that are not included within the sparse error model ansatz.
What carries the argument
Linearized gate set tomography, which applies a linear approximation to the gate set tomography fitting problem together with a sparse ansatz for the error model to process shallow-circuit data efficiently.
If this is right
- Characterization of coherent, stochastic, and crosstalk errors becomes feasible on systems up to at least ten qubits without assuming only stochastic Pauli errors.
- The method stays accurate even when the sparse model omits some physical error sources.
- Efficient data fitting from shallow circuits reduces the resources needed compared to full nonlinear tomography.
- Physical error mechanisms in many-qubit devices can be diagnosed more directly to guide device improvements.
Where Pith is reading between the lines
- The same linear-plus-sparse strategy might be adapted to other tomography or benchmarking protocols that currently face scaling limits.
- If shallow-circuit data collection remains practical, the approach could be tested on hardware systems beyond ten qubits to check real-world scaling.
- Robustness to unmodeled errors suggests the method could serve as a diagnostic tool even when the full error physics is unknown.
Load-bearing premise
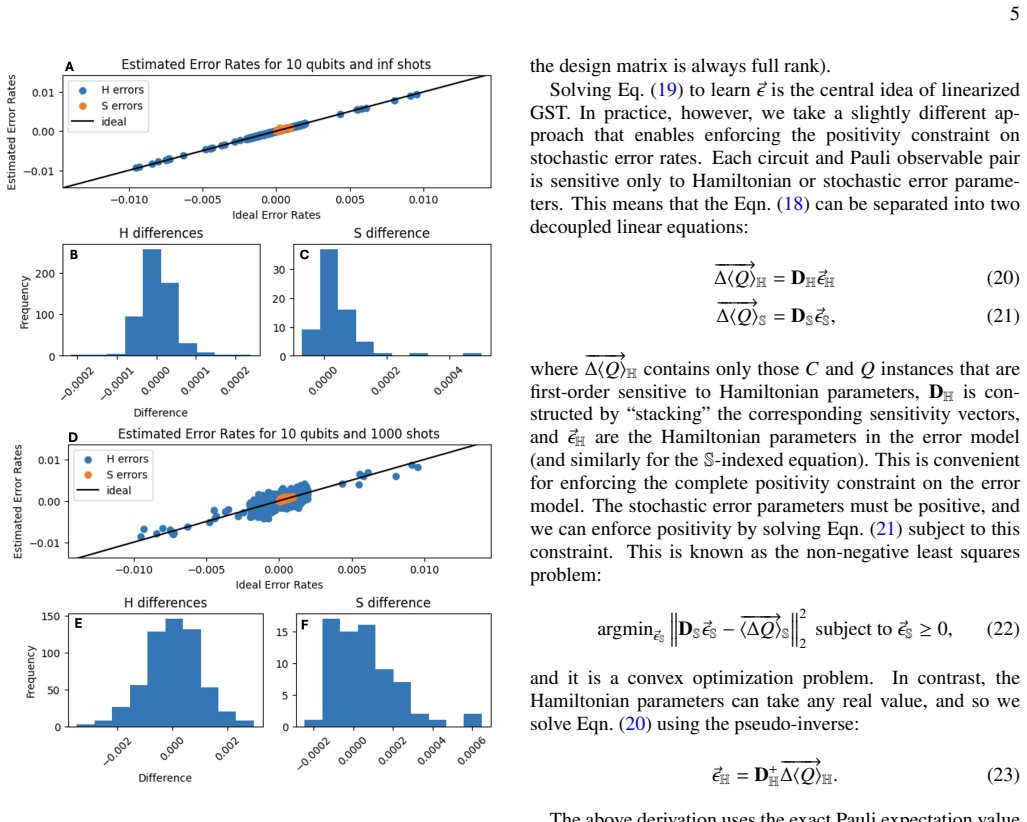
The linear approximation introduces only small systematic error when data comes from shallow circuits, and the chosen sparse error model ansatz captures the dominant physical mechanisms even when unmodeled errors are present.
What would settle it
A direct comparison on ten-qubit simulated or experimental data where the error parameters reconstructed by linearized GST deviate substantially from those obtained by a full nonlinear method or from independent fidelity benchmarks on deeper circuits.
Figures


read the original abstract
Characterizing errors on many-qubit quantum computers remains a key challenge to understanding and improving the performance of these devices. Current characterization methods either don't scale beyond a few qubits, or make simplifying assumptions (such as assuming stochastic Pauli error) that obscure the underlying physical error mechanisms. In this work, we present a scalable extension to gate set tomography-linearized gate set tomography-that enables characterization of many-qubit systems. Linearized gate set tomography relies on sparse error models, a linear approximation to enable efficient data fitting, and data from shallow circuits-so that the systematic error in the linear approximation is small. We demonstrate the accuracy of our technique using simulations of a ten-qubit system with coherent and stochastic errors, including coherent crosstalk, and we demonstrate that it is robust in presence of additional errors that are not included within the sparse error model ansatz.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces linearized gate set tomography (LGST), a scalable extension of gate set tomography for characterizing errors on many-qubit systems. It relies on sparse error models, a linear approximation to the error map for efficient fitting, and data collected from shallow circuits to ensure the approximation error remains small. The central claims are validated through numerical simulations on a 10-qubit system that include coherent and stochastic errors as well as crosstalk, with additional tests showing robustness when the sparse ansatz is incomplete.
Significance. If the linearization and sparsity assumptions hold under realistic conditions, LGST would address a key scalability barrier in quantum error characterization, enabling diagnostics on systems beyond the reach of standard GST. The simulations incorporate physically relevant error types (coherent crosstalk, mixed coherent/stochastic) and explicitly test robustness to unmodeled errors, which strengthens the practical utility of the approach for near-term hardware.
major comments (1)
- [Linear Approximation and Fitting Procedure] The linear approximation's systematic error for shallow circuits is load-bearing for the accuracy and robustness claims. The manuscript should include either an analytic bound on the neglected higher-order terms or a direct numerical comparison (e.g., LGST versus full nonlinear GST on the same 10-qubit data) to quantify the approximation error as a function of circuit depth and error strength.
minor comments (1)
- Add a brief statement of the computational scaling of the linear least-squares fit (e.g., matrix size versus qubit number) to make the scalability advantage over standard GST explicit.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and constructive comments on our manuscript introducing linearized gate set tomography. We address the major comment point by point below.
read point-by-point responses
-
Referee: The linear approximation's systematic error for shallow circuits is load-bearing for the accuracy and robustness claims. The manuscript should include either an analytic bound on the neglected higher-order terms or a direct numerical comparison (e.g., LGST versus full nonlinear GST on the same 10-qubit data) to quantify the approximation error as a function of circuit depth and error strength.
Authors: We agree that explicitly quantifying the systematic error of the linear approximation is important for supporting the accuracy and robustness claims. A direct comparison with full nonlinear GST on the 10-qubit data is not feasible, as full GST does not scale to this size due to exponential growth in parameters and computational cost—this scalability barrier is the central motivation for developing LGST. In the revised manuscript, we will add numerical comparisons between LGST and full GST on smaller systems (2–4 qubits) using the same error models, circuit depths, and error strengths to quantify the approximation error as a function of these parameters. We will also include an analytic bound on the neglected higher-order terms, derived from a perturbative expansion of the error superoperator under the assumption of small error rates consistent with the shallow-circuit regime. These additions will appear in a new subsection of the Methods and an appendix with supporting analysis and figures. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces linearized gate set tomography via sparse error models, a linear approximation to the error map, and shallow-circuit data to keep systematic error small. The central claims of accuracy and robustness are validated through forward simulations of a 10-qubit system containing coherent, stochastic, and crosstalk errors (plus unmodeled errors), rather than by fitting parameters to the same data used to define the model. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Sparse error model coefficients
axioms (2)
- domain assumption A linear approximation to the error-to-outcome map is accurate for shallow circuits
- domain assumption Sparse combinations of Pauli and coherent errors capture the main physical mechanisms
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLinearized GST relies on sparse error models, a linear approximation to enable efficient data fitting, and data from shallow circuits—so that the systematic error in the linear approximation is small.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclearWe demonstrate the accuracy of our technique using simulations of a ten-qubit system with coherent and stochastic errors, including coherent crosstalk
Reference graph
Works this paper leans on
- [1]
-
[2]
Quantum error correction below the surface code threshold, Na- ture638, 920 (2025)
work page 2025
-
[3]
Y . Kim, A. Eddins, S. Anand, K. X. Wei, E. Van Den Berg, S. Rosenblatt, H. Nayfeh, Y . Wu, M. Zaletel, K. Temme,et al., Evidence for the utility of quantum computing before fault tol- erance, Nature618, 500 (2023)
work page 2023
-
[4]
Helios: A 98-qubit trapped-ion quantum computer,
A. Ransfordet al., Helios: A 98-qubit trapped-ion quantum computer (2025), arXiv:2511.05465 [quant-ph]
-
[5]
J.-S. Chen, E. Nielsen, M. Ebert, V . Inlek, K. Wright, V . Chap- lin, A. Maksymov, E. P ´aez, A. Poudel, P. Maunz, and J. Gam- ble, Benchmarking a trapped-ion quantum computer with 30 qubits, Quantum8, 1516 (2024)
work page 2024
-
[6]
T. Proctor, K. Young, A. D. Baczewski, and R. Blume-Kohout, Benchmarking quantum computers, Nature Reviews Physics7, 105 (2025)
work page 2025
-
[7]
C. Gidney and M. Ekerå, How to factor 2048 bit rsa integers in 8 hours using 20 million noisy qubits, Quantum5, 433 (2021)
work page 2048
-
[8]
J. Lee, D. W. Berry, C. Gidney, W. J. Huggins, J. R. McClean, N. Wiebe, and R. Babbush, Even more efficient quantum com- putations of chemistry through tensor hypercontraction, PRX Quantum2, 030305 (2021)
work page 2021
-
[9]
N. C. Rubin, D. W. Berry, A. Kononov, F. D. Malone, T. Khat- tar, A. White, J. Lee, H. Neven, R. Babbush, and A. D. Baczewski, Quantum computation of stopping power for iner- tial fusion target design, Proceedings of the National Academy of Sciences121, e2317772121 (2024)
work page 2024
-
[10]
E. Magesan, J. M. Gambetta, and J. Emerson, Scalable and ro- bust randomized benchmarking of quantum processes, Phys. Rev. Lett.106, 180504 (2011)
work page 2011
-
[11]
A. Hashim, L. B. Nguyen, N. Goss, B. Marinelli, R. K. Naik, T. Chistolini, J. Hines, J. Marceaux, Y . Kim, P. Gokhale, 10 T. Tomesh, S. Chen, L. Jiang, S. Ferracin, K. Rudinger, T. Proc- tor, K. C. Young, I. Siddiqi, and R. Blume-Kohout, Practical introduction to benchmarking and characterization of quantum computers, PRX Quantum6, 030202 (2025)
work page 2025
- [12]
-
[13]
A. M. Childs, D. Maslov, Y . Nam, N. J. Ross, and Y . Su, Toward the first quantum simulation with quantum speedup, Proceed- ings of the National Academy of Sciences115, 9456 (2018), https://www.pnas.org/doi/pdf/10.1073/pnas.1801723115
-
[14]
T. J. Proctor, A. Carignan-Dugas, K. Rudinger, E. Nielsen, R. Blume-Kohout, and K. Young, Direct randomized bench- marking for multiqubit devices, Phys. Rev. Lett.123, 030503 (2019)
work page 2019
- [15]
- [16]
-
[17]
T. Proctor, S. Seritan, K. Rudinger, E. Nielsen, R. Blume- Kohout, and K. Young, Scalable randomized benchmarking of quantum computers using mirror circuits, Phys. Rev. Lett.129, 150502 (2022)
work page 2022
-
[18]
J. Hines, M. Lu, R. K. Naik, A. Hashim, J.-L. Ville, B. Mitchell, J. M. Kriekebaum, D. I. Santiago, S. Seritan, E. Nielsen, R. Blume-Kohout, K. Young, I. Siddiqi, B. Whaley, and T. Proc- tor, Demonstrating scalable randomized benchmarking of uni- versal gate sets, Phys. Rev. X13, 041030 (2023)
work page 2023
- [19]
- [20]
-
[21]
E. Magesan, J. M. Gambetta, B. R. Johnson, C. A. Ryan, J. M. Chow, S. T. Merkel, M. P. da Silva, G. A. Keefe, M. B. Roth- well, T. A. Ohki, M. B. Ketchen, and M. Steffen, Efficient measurement of quantum gate error by interleaved randomized benchmarking, Phys. Rev. Lett.109, 080505 (2012)
work page 2012
-
[22]
E. Nielsen, J. K. Gamble, K. Rudinger, T. Scholten, K. Young, and R. Blume-Kohout, Gate Set Tomography, Quantum5, 557 (2021)
work page 2021
-
[23]
Y . Gu, R. Mishra, B.-G. Englert, and H. K. Ng, Randomized linear gate-set tomography, PRX Quantum2, 030328 (2021)
work page 2021
-
[24]
R. Brieger, I. Roth, and M. Kliesch, Compressive gate set to- mography, PRX Quantum4, 010325 (2023)
work page 2023
- [25]
-
[26]
C. Ostrove, K. Rudinger, S. Seritan, K. Young, and R. Blume- Kohout, Near-minimal gate set tomography experiment de- signs, in2023 IEEE International Conference on Quantum Computing and Engineering (QCE), V ol. 01 (IEEE, 2023) pp. 1422–1432
work page 2023
- [27]
-
[28]
R. Blume-Kohout, M. P. da Silva, E. Nielsen, T. Proctor, K. Rudinger, M. Sarovar, and K. Young, A taxonomy of small markovian errors, PRX Quantum3, 020335 (2022)
work page 2022
-
[29]
The appropriate maximum depth depends on the magnitude of the errors, which is typicallya prioriknown approximately
-
[30]
Although we expect compressed sensing techniques can be used to extend toa priori-unknown sparse models
-
[31]
D. Dobrynin, L. Cardarelli, M. M ¨uller, and A. Bermudez, Compressed-sensing lindbladian quantum tomography with trapped ions, Quantum Science and Technology10, 045041 (2025)
work page 2025
-
[32]
F. J. Schreiber, J. Eisert, and J. J. Meyer, Tomography of parametrized quantum states, PRX Quantum6, 020346 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.