Recognition: no theorem link
Adaptive Policy Learning Under Unknown Network Interference
Pith reviewed 2026-05-13 02:00 UTC · model grok-4.3
The pith
Thompson sampling jointly learns unknown interference networks and optimizes individual treatment allocations to achieve sublinear regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central contribution is a Thompson sampling algorithm that jointly samples the posterior over interference networks and treatment policies using a Gibbs sampler. Under additive spillover models the total reward reduces to a linear function of the treatment vector whose coefficients are an n-dimensional latent score, which yields a Bayesian regret bound of order sqrt(nT · B log(en/B)). For general neighborhood interference the authors analyze an explore-then-commit variant whose graph-discovery cost is O(n² log T), complemented by an information-theoretic lower bound of Omega(n log T).
What carries the argument
The Gibbs-sampler-based Thompson sampling procedure that jointly infers the interference graph and adaptively allocates treatments at the individual level.
If this is right
- The algorithm returns both an optimized treatment policy and a network estimate that supports downstream estimation of direct, indirect, and total effects.
- Empirical regret remains sublinear even when the additive-spillover assumption is violated.
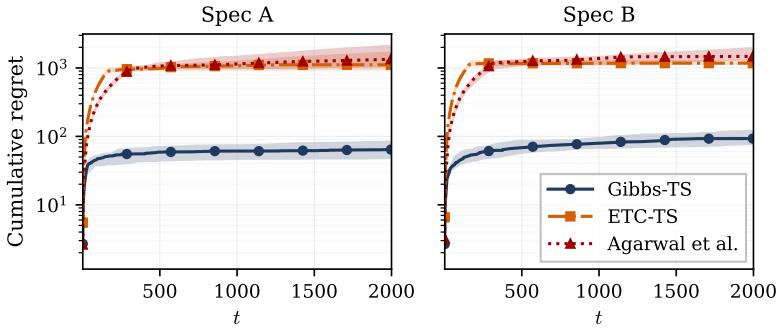
- Head-to-head comparisons show more than an order-of-magnitude regret reduction relative to baselines that either assume the network is known or operate on clusters.
- On two real-world networks the method attains sublinear regret while producing effect estimates with small RMSE.
Where Pith is reading between the lines
- The latent-score representation may generalize to other interference models that admit low-dimensional sufficient statistics.
- The same joint-learning idea could be applied to time-varying or directed networks without changing the core sampling structure.
- In applied settings the returned network estimate could be used to design follow-up experiments that target high-influence nodes.
- Scaling the Gibbs sampler to very large n will likely require further approximation techniques not analyzed here.
Load-bearing premise
That the interference structure permits an additive spillover representation in which total reward is exactly linear in the treatment vector.
What would settle it
Running the algorithm on simulated data generated from a known additive spillover model and observing cumulative regret that grows faster than order sqrt(nT · B log(en/B)) would falsify the claimed bound.
Figures

read the original abstract
Adaptive experimentation under unknown network interference requires solving two coupled problems: (i) learning the underlying dynamics of interference among units and (ii) using these dynamics to inform treatment allocation in order to maximize a cumulative outcome of interest (e.g. revenue). Existing adaptive experimentation methods either assume the interference network is fully known or bypass the network by operating on coarse cluster-level randomizations. We develop a Thompson sampling algorithm that jointly learns the interference network and adaptively optimizes individual-level treatment allocations via a Gibbs sampler. The algorithm returns both an optimized treatment policy and an estimate of the interference network; the latter supports downstream causal analyses such as estimation of direct, indirect, and total treatment effects. For additive spillover models, we show that total reward is linear in the treatment vector with coefficients given by an $n$-dimensional latent score. We prove a Bayesian regret bound of order $\sqrt{nT \cdot B \log(en/B)}$ for exact posterior sampling; empirically, our Gibbs-based approximate sampler achieves regret consistent with this rate and remains sublinear when the additive spillovers assumption is violated. For general Neighborhood Interference, where this reduction is unavailable, we analyze an explore-then-commit variant with $O(n^2 \log T)$ graph-discovery cost. An information-theoretic $\Omega(n \log T)$ lower bound complements both results. Empirically, our method achieves more than an order-of-magnitude reduction in regret in head-to-head comparisons. On two real-world networks, the algorithm achieves sublinear regret and yields downstream effect estimates with small RMSE relative to the truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Thompson sampling algorithm using a Gibbs sampler to jointly learn an unknown interference network and optimize individual-level treatment allocations under network interference. For additive spillover models, total reward is shown to be linear in the treatment vector with coefficients from an n-dimensional latent score; a Bayesian regret bound of order √(nT · B log(en/B)) is proven for exact posterior sampling. For general neighborhood interference, an explore-then-commit variant is analyzed with O(n² log T) graph-discovery cost. An information-theoretic Ω(n log T) lower bound is provided, and empirical results show sublinear regret, consistency with the theoretical rate under the Gibbs approximation, robustness to mild additive assumption violations, and over an order-of-magnitude regret reduction versus baselines on synthetic and two real-world networks, plus downstream effect estimates with small RMSE.
Significance. If the central claims hold, this advances adaptive experimentation and causal inference under interference by enabling joint network learning and individual treatment optimization, rather than assuming known networks or using coarse cluster randomizations. The combination of a non-trivial regret upper bound, matching lower bound, and empirical validation of sublinear regret is a strength; the algorithm's output of both policy and network estimate for downstream analyses (direct/indirect/total effects) adds practical value. The order-of-magnitude empirical improvement and real-network results suggest impact beyond theory.
major comments (2)
- [Theorem on Bayesian regret for exact posterior sampling (additive spillover case)] The Bayesian regret bound of order √(nT · B log(en/B)) (abstract and main theorem on exact posterior sampling) is derived under exact Thompson sampling for the additive spillover model. The deployed algorithm replaces this with a Gibbs sampler, but no bound is given on the approximation error (e.g., total-variation distance to the true posterior or its effect on the information ratio or posterior concentration used in the analysis). This gap means the proven √T scaling does not necessarily transfer to the implemented method.
- [Analysis of explore-then-commit variant for neighborhood interference] For the general neighborhood interference model, the explore-then-commit analysis incurs O(n² log T) cost for graph discovery. The paper should clarify whether this cost is necessary or if the main Thompson sampling approach could be extended with weaker assumptions while retaining sublinear regret.
minor comments (2)
- [Abstract and empirical evaluation section] The abstract states that the Gibbs sampler 'achieves regret consistent with this rate' empirically, but the main text should include more detail on the number of replications, network sizes, and how consistency with √(nT B log(en/B)) was assessed (e.g., via log-log plots or regression).
- [Model and additive spillover reduction] Notation for the latent score, spillover parameters, and B (budget or sparsity parameter) should be defined at first use and used consistently; some equations in the additive model reduction could benefit from an explicit statement of the linearity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the paper's contributions to adaptive experimentation under unknown network interference. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Theorem on Bayesian regret for exact posterior sampling (additive spillover case)] The Bayesian regret bound of order √(nT · B log(en/B)) (abstract and main theorem on exact posterior sampling) is derived under exact Thompson sampling for the additive spillover model. The deployed algorithm replaces this with a Gibbs sampler, but no bound is given on the approximation error (e.g., total-variation distance to the true posterior or its effect on the information ratio or posterior concentration used in the analysis). This gap means the proven √T scaling does not necessarily transfer to the implemented method.
Authors: We agree that the Bayesian regret bound is established only for exact posterior sampling, while the algorithm deploys a Gibbs sampler approximation. In the revision we will explicitly qualify the theorem and abstract to state that the √(nT · B log(en/B)) guarantee applies to exact Thompson sampling. We will add a dedicated paragraph discussing the Gibbs approximation, citing standard convergence results for Gibbs samplers on this class of models and noting that our experiments exhibit regret scaling consistent with the theoretical rate. Deriving a rigorous non-asymptotic bound on the approximation error's effect on regret remains technically open. revision: partial
-
Referee: [Analysis of explore-then-commit variant for neighborhood interference] For the general neighborhood interference model, the explore-then-commit analysis incurs O(n² log T) cost for graph discovery. The paper should clarify whether this cost is necessary or if the main Thompson sampling approach could be extended with weaker assumptions while retaining sublinear regret.
Authors: The O(n² log T) cost is required in the worst case because the general neighborhood interference model allows arbitrary interference patterns, necessitating exploration of all potential edges to recover the structure. This necessity is consistent with the information-theoretic Ω(n log T) lower bound already provided. Extending the main Thompson sampling procedure to the general model while preserving sublinear regret without an explicit exploration phase would require additional structural assumptions or substantially more efficient posterior sampling; we view this as an interesting open direction. In the revision we will insert a clarifying paragraph explaining why the explore-then-commit strategy is used for the general case and why the current Thompson sampling analysis is restricted to additive spillovers. revision: yes
- A rigorous non-asymptotic bound quantifying the effect of the Gibbs sampler approximation error on Bayesian regret
Circularity Check
No circularity; regret bound stated for exact posterior sampling under explicit model assumptions
full rationale
The paper states a Bayesian regret bound of order √(nT · B log(en/B)) explicitly for exact posterior sampling under the additive spillover model, where total reward is shown to be linear in the treatment vector with an n-dimensional latent score. This is presented as a theoretical result. The practical algorithm employs a Gibbs sampler, but the bound is not claimed to hold for the approximation; only empirical regret consistency is reported. The general-case analysis uses an explore-then-commit variant with O(n² log T) cost and an information-theoretic lower bound. No quoted derivation reduces the bound or prediction to a fitted quantity defined by the same data, nor relies on self-citation chains or ansatzes smuggled via prior work by the authors. The central claims remain independent of the inputs they analyze.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Additive spillover model in which total reward is linear in the treatment vector with coefficients given by an n-dimensional latent score
- domain assumption Neighborhood Interference model for the general case
Reference graph
Works this paper leans on
-
[1]
Agarwal, A., Agarwal, A., Masoero, L., and Whitehouse, J. (2024). Mutli-armed bandits with network interference. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Aronow, P. M. and Samii, C. (2017). Estimating average causal effects under general interference, with application to a social network experiment.The Annals of Appl...
-
[2]
10 Phan, M., Abbasi Yadkori, Y ., and Domke, J. (2019). Thompson sampling and approximate inference. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information Processing Systems, volume
work page 2019
-
[3]
Curran Associates, Inc. Rubin, D. B. (1978). Bayesian inference for causal effects: The role of randomization.The Annals of Statistics, 6(1):34–58. Russo, D. and Van Roy, B. (2014). Learning to optimize via posterior sampling.Mathematics of Operations Research, 39(4):1221–1243. Su, L., Lu, W., and Song, R. (2019). Modelling and estimation for optimal trea...
-
[4]
Wager, S. and Xu, K. (2021). Experimenting in equilibrium.Management Science, 67(11):6694–6715. 11 A Proof of Theorem 1 We begin with a Lemma: Lemma 1(Linear posterior-sampling information ratio).Consider posterior sampling for a linear objective fs(z) =z ⊤s,s∈R n,z∈ Z B. If one-step regret is bounded by R, then the conditional information ratio with scal...
work page 2021
-
[5]
Then Assumption 2 holds with cA,θ = nX i=1 αi, s j =τ j + nX i=1 ηij. Therefore the regret bound of Theorem 1 applies to ideal posterior sampling over the unknown graph and reward parameters. Proof.Summing the node-level rewards gives nX i=1 ri(z;A,θ) = nX i=1 αi + nX i=1 τizi + nX i=1 nX j=1 ηijzj =c A,θ + nX j=1 zj τj + nX i=1 ηij ! . This is exactly th...
work page 2020
-
[6]
IfA ij = 0, then¯rij has mean0and the error probability is P(¯rij > δ γ/2)≤exp − mδ2 γ 8σ2 ! . IfA ij = 1, then¯rij has meanγ 1 ≥δ γ and the error probability is P(¯rij ≤δ γ/2) =P(¯rij −γ 1 ≤δ γ/2−γ 1)≤exp − m(γ1 −δ γ/2)2 2σ2 ≤exp − mδ2 γ 8σ2 ! , where the last inequality uses γ1 ≥δ γ, which implies γ1 −δ γ/2≥δ γ/2. By our choice of m, we haveP( ˆAij ̸=A ...
work page 2025
-
[7]
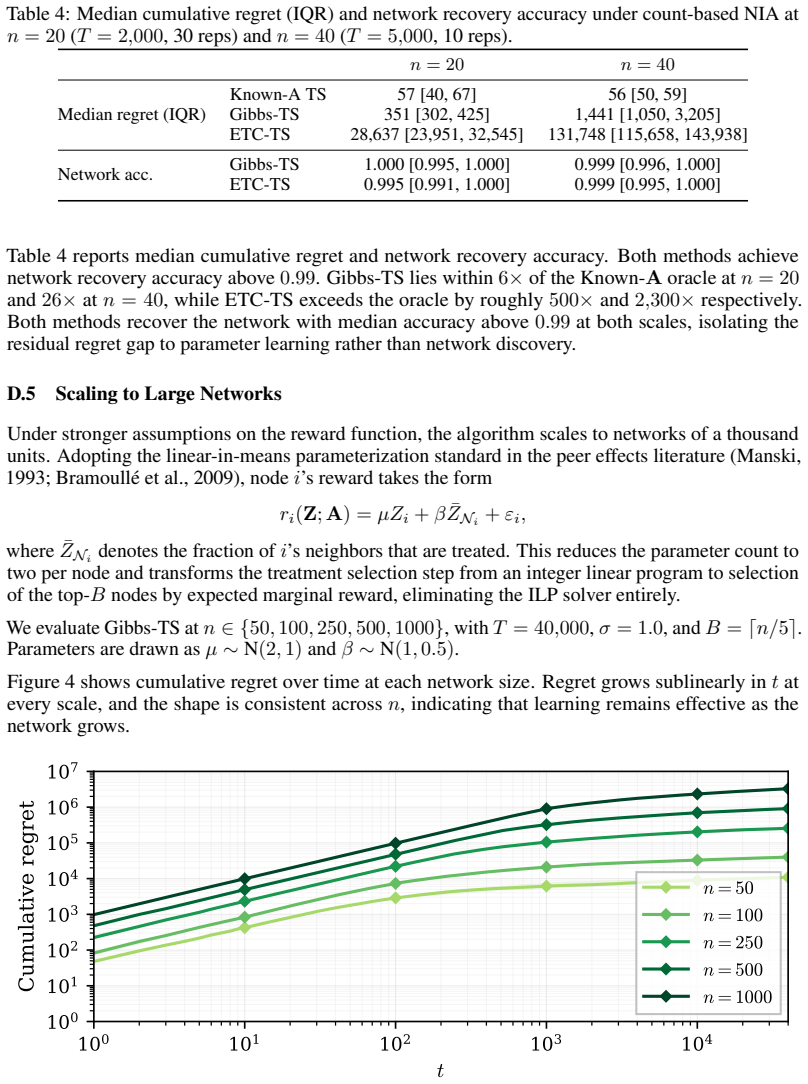
16 Table 4: Median cumulative regret (IQR) and network recovery accuracy under count-based NIA at n= 20(T= 2,000, 30 reps) andn= 40(T= 5,000, 10 reps). n= 20n= 40 Median regret (IQR) Known-A TS 57 [40, 67] 56 [50, 59] Gibbs-TS 351 [302, 425] 1,441 [1,050, 3,205] ETC-TS 28,637 [23,951, 32,545] 131,748 [115,658, 143,938] Network acc. Gibbs-TS 1.000 [0.995, ...
work page 1993
-
[8]
Algorithms Gibbs-TS (well-spec.), Gibbs-TS (additive misspec., dropsξ), ETC-TS (well-spec.), Agarwal et al. (2024) Gibbs sweepsK10 Edge priorρ0.3(=p edge) Prior meanµ 0 0 Prior covarianceΣ 0 10·I Phase-2 ridge for ETC (1/λ)λ= 0.1, equivalent toΣ 0 = 10·I ETC isolation budgetm20rounds per node ETC edge thresholdδ γ/2withδ γ = 0.3 Agarwal et al. regularizat...
work page 2024
-
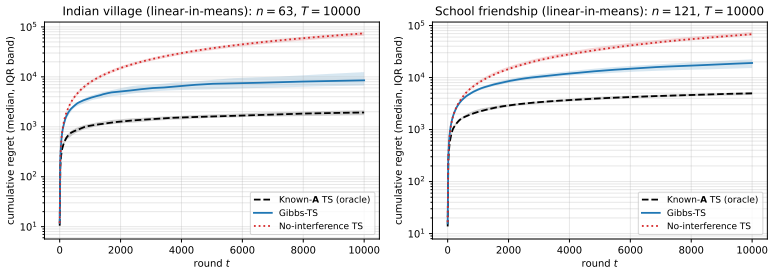
[9]
(2013) borrowing-money household n= 63,|E|= 114, density0.058, isolates dropped Network 2 (SCHID
Banerjee et al. (2013) borrowing-money household n= 63,|E|= 114, density0.058, isolates dropped Network 2 (SCHID
work page 2013
-
[10]
Paluck et al. (2016) friendship roster, symmetrized n= 121,|E|= 251, density0.035, isolates dropped Reward function Per-node linear-in-means:r i =µ iZi +β i ¯ZNi +ε i µi, βi distributionUniform[0,1]iid per node, fresh per rep HorizonT10,000 BudgetB⌈n/5⌉:13(village),25(SCHID
work page 2016
-
[11]
Prior meanµ 0 0(per-node(µ i, βi)) Prior covarianceΣ 0 10·I(per-node2×2block) Posterior decomposition Per-node2×2block-diagonalθ-sampler Treatment selection Top-Bby expected marginal reward (no ILP solver) Graph-accuracy snapshots Every 100 rounds Per-rep checkpointing SLURM array tasks (one rep per task) E.3 Downstream Causal Estimation:n= 20SBM, count-b...
work page 2013
-
[12]
Algorithms Gibbs-TS, ETC-TS, Agarwal et al. (2024) Gibbs sweepsK= 10 Edge priorρ0.3 Prior meanµ 0 0 Prior covarianceΣ 0 10·I Phase-2 ridge for ETC (1/λ)λ= 0.1, equivalent toΣ 0 = 10·I ETC isolation budgetm20rounds per node ETC edge thresholdδ γ/2withδ γ = 0.3 Agarwal et al. regularization Default Lasso, CV-selected Treatment-selection optimizer Gurobi ILP...
work page 2024
-
[13]
Top-Bby expected marginal reward E.11 Sweep-Count Ablation Table 18: Protocol for the Appendix D.7 sweep-count ablation on regret. (The within-round mixing diagnostic in Table 6 runs Kdiag = 200 Gibbs sweeps from the warm-start state at four snapshot rounds with75seeds; otherwise the problem instance matches the line below.) Setting Value Network family E...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.