Recognition: unknown
ReVision: Scaling Computer-Use Agents via Temporal Visual Redundancy Reduction
Pith reviewed 2026-05-14 20:52 UTC · model grok-4.3
The pith
ReVision removes redundant visual patches from agent history screenshots to cut token usage by 46 percent while raising success rates by 3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
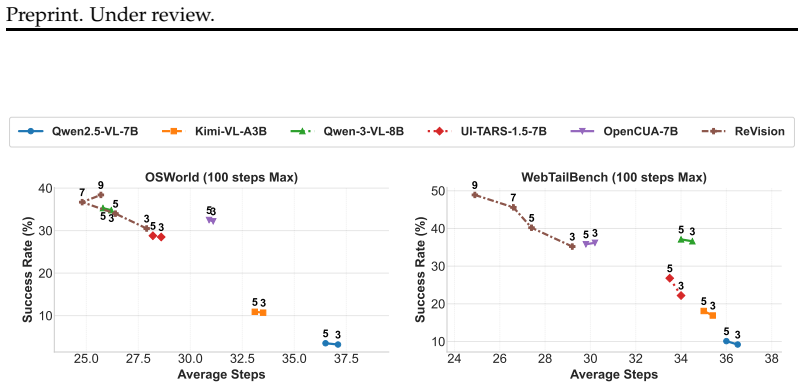
ReVision trains multimodal language models on trajectories where redundant visual patches are removed using a learned patch selector that compares patch representations across consecutive screenshots while preserving spatial structure required by the model. Across OSWorld, WebTailBench, and AgentNetBench, when processing trajectories with 5 history screenshots using Qwen2.5-VL-7B, ReVision reduces token usage by approximately 46% on average while improving success rate by 3% over the no drop baseline. This establishes a clear efficiency gain, enabling agents to process longer trajectories with fewer tokens. With this improved efficiency, performance continues to improve as more past visual-0
What carries the argument
a learned patch selector that compares patch representations across consecutive screenshots to drop redundant patches while preserving spatial structure
If this is right
- Agents can process longer trajectories without exceeding fixed token budgets.
- Performance improves steadily with added visual history once temporal redundancy is removed.
- The observed saturation with history in prior work stems from token inefficiency rather than lack of useful past information.
- The approach applies across OSWorld, WebTailBench, and AgentNetBench.
Where Pith is reading between the lines
- Similar patch-level redundancy reduction could extend to video-based agents in robotics or navigation.
- The method might combine with other compression techniques to scale context even further.
- Adaptive selection that also considers task relevance could yield larger gains than temporal comparison alone.
Load-bearing premise
The learned patch selector accurately identifies and removes only redundant patches without discarding task-critical visual information required for correct agent actions.
What would settle it
An experiment in which agents using the selected patches fail on tasks that succeed with the full set of patches, or in which adding more history after reduction produces no further performance gains.
Figures







read the original abstract
Computer-use agents (CUAs) rely on visual observations of graphical user interfaces, where each screenshot is encoded into a large number of visual tokens. As interaction trajectories grow, the token cost increases rapidly, limiting the amount of history that can be incorporated under fixed context and compute budgets. This has resulted in no or very limited improvement in the performance when using history unlike other domains. We address this inefficiency by introducing ReVision, which is used to train multimodal language models on trajectories where redundant visual patches are removed using a learned patch selector that compares patch representations across consecutive screenshots while preserving spatial structure required by the model. Across three benchmarks, OSWorld, WebTailBench, and AgentNetBench, when processing trajectories with 5 history screenshots using Qwen2.5-VL-7B, ReVision reduces token usage by approximately 46% on average while improving success rate by 3% over the no drop baseline. This establishes a clear efficiency gain, enabling agents to process longer trajectories with fewer tokens. With this improved efficiency, we revisit the role of history in CUAs and find that performance continues to improve as more past observations are incorporated when redundancy is removed. This suggests that the commonly observed saturation in visual history is not due to limited usefulness of past information, but rather a consequence of inefficient token representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReVision, a method that trains multimodal LLMs for computer-use agents by removing temporally redundant visual patches from sequences of history screenshots via a learned patch selector. The selector compares patch representations across consecutive frames while preserving spatial structure. On OSWorld, WebTailBench, and AgentNetBench, using Qwen2.5-VL-7B with 5 history screenshots, it reports ~46% average token reduction and a 3% success-rate improvement over a no-drop baseline. The work further claims that, once redundancy is removed, agent performance continues to scale with additional history observations, implying that prior saturation effects stem from token inefficiency rather than limited utility of past visual information.
Significance. If the empirical claims hold under closer scrutiny, the result directly addresses a core scaling bottleneck for visual history in computer-use agents, where token counts grow linearly with trajectory length. Demonstrating both substantial efficiency gains and a modest performance lift on three distinct benchmarks would support the broader hypothesis that history saturation is an artifact of representation rather than an inherent limit, potentially enabling longer-horizon agents within fixed context budgets.
major comments (3)
- [§4] §4 (Experiments): The headline 46% token reduction and 3% success lift are reported as aggregate figures without accompanying per-benchmark breakdowns, standard deviations across runs, or statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals). This makes it impossible to determine whether the observed lift exceeds run-to-run variance or is driven by a subset of trajectories.
- [§3.2] §3.2 (Learned Patch Selector): The training objective and loss used to optimize the patch selector are not specified. Without an explicit term that penalizes removal of low-redundancy but high-action-value patches (e.g., transient UI state changes), it remains unclear whether the selector truly preserves task-critical information or merely reduces tokens in a manner correlated with the training distribution.
- [§4.3] §4.3 (Ablation and Analysis): No oracle ablation or per-trajectory inspection is provided that forces removal of ground-truth critical patches (identified via action relevance) and measures the resulting drop in success rate. Such a control is necessary to substantiate the claim that the selector removes only redundant content rather than discarding necessary visual signals.
minor comments (3)
- [Abstract] The abstract states concrete benchmark gains but does not cite the exact prior works that observed “no or very limited improvement” when adding history; adding 1–2 references would strengthen the motivation.
- [§3] Notation for the patch selector (e.g., how spatial structure is preserved after dropping) is introduced without an accompanying equation or diagram in the main text; a small illustrative figure would improve clarity.
- [Tables] Table captions should explicitly list the number of trajectories and random seeds used for each reported metric.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major concerns below and will revise the paper to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: §4 (Experiments): The headline 46% token reduction and 3% success lift are reported as aggregate figures without accompanying per-benchmark breakdowns, standard deviations across runs, or statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals). This makes it impossible to determine whether the observed lift exceeds run-to-run variance or is driven by a subset of trajectories.
Authors: We agree that disaggregated results and statistical analysis would improve clarity. In the revised manuscript, we will add per-benchmark tables showing token reduction and success rates, include standard deviations from multiple experimental runs, and report p-values from paired t-tests or bootstrap confidence intervals to demonstrate that the improvements are statistically significant. revision: yes
-
Referee: §3.2 (Learned Patch Selector): The training objective and loss used to optimize the patch selector are not specified. Without an explicit term that penalizes removal of low-redundancy but high-action-value patches (e.g., transient UI state changes), it remains unclear whether the selector truly preserves task-critical information or merely reduces tokens in a manner correlated with the training distribution.
Authors: The patch selector is trained using a composite loss consisting of a temporal redundancy term (measuring similarity between patch embeddings across consecutive frames) and a task-specific term that encourages preservation of patches relevant to the agent's action prediction. This is achieved by backpropagating through the agent's success on the trajectories. We will explicitly detail this objective and the loss formulation in the revised §3.2. The end-to-end training with agent performance serves as the mechanism to avoid discarding high-value patches, as removing them would directly reduce success rates during training. revision: yes
-
Referee: §4.3 (Ablation and Analysis): No oracle ablation or per-trajectory inspection is provided that forces removal of ground-truth critical patches (identified via action relevance) and measures the resulting drop in success rate. Such a control is necessary to substantiate the claim that the selector removes only redundant content rather than discarding necessary visual signals.
Authors: We recognize the value of an oracle ablation study. However, constructing ground-truth critical patches would require additional human annotation or a separate model for action relevance, which was not feasible within the scope of this work. Our current evidence for preserving critical information includes the observed 3% success rate improvement over the no-drop baseline and the continued performance scaling with longer histories, which would be unlikely if essential visual signals were being removed. We will expand §4.3 with qualitative analysis of selected vs. dropped patches and discuss this limitation. revision: partial
Circularity Check
No significant circularity; empirical results on held-out benchmarks
full rationale
The paper introduces ReVision as a trained patch selector that removes redundant visual patches from screenshot trajectories while preserving spatial structure, then reports direct empirical measurements: ~46% average token reduction and +3% success rate on 5-history trajectories using Qwen2.5-VL-7B across OSWorld, WebTailBench, and AgentNetBench. These outcomes are obtained by training the selector and evaluating success rates on held-out benchmark trajectories; no equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citation chain justifies the core claim, and no ansatz or uniqueness theorem is smuggled in. The central efficiency gain is therefore a measured quantity rather than a tautological re-expression of the training objective.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal language models can learn to selectively attend to or drop visual patches based on cross-frame similarity comparisons.
invented entities (1)
-
learned patch selector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
-
[2]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 , eprint=
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction , author=. 2025 , eprint=
2025
-
[4]
2024 , url =
GPT-4o , author =. 2024 , url =
2024
-
[5]
2024 , journal=
GUICourse: From General Vision Language Models to Versatile GUI Agents , author=. 2024 , journal=
2024
-
[6]
arXiv preprint arXiv:2401.13649 , year=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. arXiv preprint arXiv:2401.13649 , year=
-
[7]
Introducing GPT-5.4 , year =
-
[8]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Kimi Team and Angang Du and Bohong Yin and Bowei Xing and Bowen Qu and Bowen Wang and Cheng Chen and Chenlin Zhang and Chenzhuang Du and Chu Wei and Congcong Wang and Dehao Zhang and Dikang Du and Dongliang Wang and Enming Yuan and Enzhe Lu and Fang Li and Flood Sung and Guangda Wei and Guokun Lai and Han Zhu and Hao Ding and Hao Hu and Hao Yang and Hao Z...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2024 , eprint=
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents , author=. 2024 , eprint=
2024
-
[11]
arXiv preprint arXiv:2511.19663 , year=
Fara-7B: An Efficient Agentic Model for Computer Use , author=. arXiv preprint arXiv:2511.19663 , year=
-
[12]
2026 , eprint=
WebSTAR: Scalable Data Synthesis for Computer Use Agents with Step-Level Filtering , author=. 2026 , eprint=
2026
-
[13]
2024 , url=
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction , author=. 2024 , url=
2024
-
[14]
2024 , eprint=
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? , author=. 2024 , eprint=
2024
-
[15]
2023 , eprint=
CogAgent: A Visual Language Model for GUI Agents , author=. 2023 , eprint=
2023
-
[16]
2025 , eprint=
SpiritSight Agent: Advanced GUI Agent with One Look , author=. 2025 , eprint=
2025
-
[17]
arXiv preprint arXiv:2401.13919 , year=
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models , author=. arXiv preprint arXiv:2401.13919 , year=
-
[18]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents , author=. arXiv preprint arXiv:2410.23218 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ScreenSpot-Pro:
Kaixin Li and Meng Ziyang and Hongzhan Lin and Ziyang Luo and Yuchen Tian and Jing Ma and Zhiyong Huang and Tat-Seng Chua , booktitle=. ScreenSpot-Pro:. 2025 , url=
2025
-
[20]
2025 , eprint=
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis , author=. 2025 , eprint=
2025
-
[21]
arXiv preprint arXiv:2401.01614 , year=
GPT-4V(ision) is a Generalist Web Agent, if Grounded , author=. arXiv preprint arXiv:2401.01614 , year=
-
[22]
arXiv preprint arXiv:2506.03143 , year=
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents , author=. arXiv preprint arXiv:2506.03143 , year=
-
[23]
2024 , eprint=
OmniParser for Pure Vision Based GUI Agent , author=. 2024 , eprint=
2024
-
[24]
2024 , eprint=
ScreenAI: A Vision-Language Model for UI and Infographics Understanding , author=. 2024 , eprint=
2024
-
[25]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V , author=. arXiv preprint arXiv:2310.11441 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2023 , eprint=
Mind2Web: Towards a Generalist Agent for the Web , author=. 2023 , eprint=
2023
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[28]
2024 , eprint=
WebLINX: Real-World Website Navigation with Multi-Turn Dialogue , author=. 2024 , eprint=
2024
-
[29]
A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions
A comprehensive survey of agents for computer use: Foundations, challenges, and future directions , author=. arXiv preprint arXiv:2501.16150 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
The Fourteenth International Conference on Learning Representations , year=
IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction , author=. The Fourteenth International Conference on Learning Representations , year=
-
[31]
2024 , eprint=
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents , author=. 2024 , eprint=
2024
-
[32]
arXiv preprint arXiv:2406.03679 , year=
On the Effects of Data Scale on Computer Control Agents , author=. arXiv preprint arXiv:2406.03679 , year=
-
[33]
2023 , eprint=
Android in the Wild: A Large-Scale Dataset for Android Device Control , author=. 2023 , eprint=
2023
-
[34]
2024 , eprint=
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents , author=. 2024 , eprint=
2024
-
[35]
2024 , eprint=
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks? , author=. 2024 , eprint=
2024
-
[36]
2024 , month =
Bonatti, Rogerio and Zhao, Dan and Bonacci, Francesco and Dupont, Dillon and Abdali, Sara and Li, Yinheng and Wagle, Justin and Koishida, Kazuhito and Bucker, Arthur and Jang, Lawrence and Hui, Zack , title =. 2024 , month =
2024
-
[37]
arXiv preprint arXiv:2510.00536 , year =
GUI-KV: Efficient GUI Agents via KV Cache with Spatio-Temporal Awareness , author =. arXiv preprint arXiv:2510.00536 , year =
-
[38]
2025 , eprint=
OpenCUA: Open Foundations for Computer-Use Agents , author=. 2025 , eprint=
2025
-
[39]
arXiv preprint arXiv:2402.18577 , year=
Motion Guided Token Compression for Efficient Masked Video Modeling , author=. arXiv preprint arXiv:2402.18577 , year=
-
[40]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
One Token per Highly Selective Frame: Towards Extreme Compression for Long Video Understanding , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[41]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
PVC: Progressive Visual Token Compression for Unified Image and Video Processing in Large Vision-Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[42]
arXiv preprint arXiv:2509.14199 , year=
Dense Video Understanding with Gated Residual Tokenization , author=. arXiv preprint arXiv:2509.14199 , year=
-
[43]
2022 , eprint=
WebGPT: Browser-assisted question-answering with human feedback , author=. 2022 , eprint=
2022
-
[44]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[45]
2021 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2021 , eprint=
2021
-
[46]
2024 , eprint=
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , author=. 2024 , eprint=
2024
-
[47]
2025 , eprint=
OSWorld-Human: Benchmarking the Efficiency of Computer-Use Agents , author=. 2025 , eprint=
2025
-
[48]
V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Russ and Fried, Daniel. V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[49]
First Workshop on Multi-Turn Interactions in Large Language Models , year=
WebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation , author=. First Workshop on Multi-Turn Interactions in Large Language Models , year=
-
[50]
arXiv preprint arXiv:2603.04949 , year=
TimeWarp: Evaluating Web Agents by Revisiting the Past , author=. arXiv preprint arXiv:2603.04949 , year=
-
[51]
AgentOccam: A Simple Yet Strong Baseline for
Ke Yang and Yao Liu and Sapana Chaudhary and Rasool Fakoor and Pratik Chaudhari and George Karypis and Huzefa Rangwala , booktitle=. AgentOccam: A Simple Yet Strong Baseline for. 2025 , url=
2025
-
[52]
arXiv preprint arXiv:2510.03204 , year=
Focusagent: Simple yet effective ways of trimming the large context of web agents , author=. arXiv preprint arXiv:2510.03204 , year=
-
[53]
W eb A gent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
Wei, Zhepei and Yao, Wenlin and Liu, Yao and Zhang, Weizhi and Lu, Qin and Qiu, Liang and Yu, Changlong and Xu, Puyang and Zhang, Chao and Yin, Bing and Yun, Hyokun and Li, Lihong. W eb A gent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 20...
-
[54]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[55]
2024 , eprint=
ShowUI: One Vision-Language-Action Model for GUI Visual Agent , author=. 2024 , eprint=
2024
-
[56]
arXiv preprint arXiv:2601.03928 , year=
FocusUI: Efficient UI Grounding via Position-Preserving Visual Token Selection , author=. arXiv preprint arXiv:2601.03928 , year=
-
[57]
arXiv preprint arXiv:2602.05809 , year=
Focus-Scan-Refine: From Human Visual Perception to Efficient Visual Token Pruning , author=. arXiv preprint arXiv:2602.05809 , year=
-
[58]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scsampler: Sampling salient clips from video for efficient action recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[59]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[60]
Conference on Computer Vision and Pattern Recognition , year=
vid-TLDR: Training Free Token merging for Light-weight Video Transformer , author=. Conference on Computer Vision and Pattern Recognition , year=
-
[61]
2025 , eprint=
TimeChat-Online: 80 author=. 2025 , eprint=
2025
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
European Conference on Computer Vision , pages=
Rotary position embedding for vision transformer , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[67]
2026 , url=
Mouxiao Huang and Borui Jiang and Dehua Zheng and Hailin Hu and Kai Han and Xinghao Chen , booktitle=. 2026 , url=
2026
-
[68]
N\"uwa: Mending the Spatial Integrity Torn by
Yihong Huang and Fei Ma and Yihua Shao and Jingcai Guo and Zitong YU and Laizhong Cui and Qi Tian , booktitle=. N\"uwa: Mending the Spatial Integrity Torn by. 2026 , url=
2026
-
[69]
CubistMerge : spatial-preserving token merging for diverse ViT backbones , url=
Gong, Wenyi , year=. CubistMerge : spatial-preserving token merging for diverse ViT backbones , url=. doi:http://dx.doi.org/10.14288/1.0450473 , school=
-
[70]
arXiv preprint arXiv:2601.22231 , year=
Geometry without Position? When Positional Embeddings Help and Hurt Spatial Reasoning , author=. arXiv preprint arXiv:2601.22231 , year=
-
[71]
Advances in Neural Information Processing Systems , volume=
Don't Look Twice: Faster Video Transformers with Run-Length Tokenization , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
arXiv preprint arXiv:2509.15221 , year =
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data , author =. arXiv preprint arXiv:2509.15221 , year =
-
[75]
2026 , eprint=
Scaling Agents for Computer Use , author=. 2026 , eprint=
2026
-
[76]
Second Conference on Language Modeling , year=
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents , author=. Second Conference on Language Modeling , year=
-
[77]
Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation , year=
Agent S: An Open Agentic Framework that Uses Computers Like a Human , author=. Towards Agentic AI for Science: Hypothesis Generation, Comprehension, Quantification, and Validation , year=
-
[78]
and Yao, Lina and McAuley, Julian
Xia, Yu and Shen, Yiran Jenny and Wu, Junda and Yu, Tong and Kim, Sungchul and Rossi, Ryan A. and Yao, Lina and McAuley, Julian. SAND : Boosting LLM Agents with Self-Taught Action Deliberation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.152
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.