Recognition: no theorem link
Quantum Parity Representations: Learnable Basis Discovery, Encoders, and Shadow Deployment
Pith reviewed 2026-05-13 02:23 UTC · model grok-4.3
The pith
Hybrid quantum-classical training discovers parity bases that improve accuracy by 24 to 42 percent on tasks depending on higher-order bit interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Parity features defined as signed products over chosen bits can be made useful by hybrid training that selects effective Pauli words for basis discovery or learned projections for encoding; the resulting classifiers outperform logistic regression and support-vector baselines on native-binary tasks because the selected words capture label-relevant higher-order interactions, while the final evaluation stays fully classical.
What carries the argument
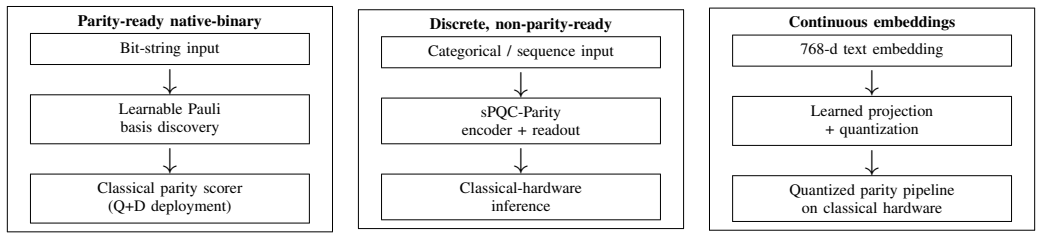
Learnable Pauli word selection within hybrid quantum-classical training, which searches the space of possible parity words to find those whose products best separate the labels.
Load-bearing premise
The hybrid training process will consistently find parity words whose higher-order products remain predictive after the input is binarized or quantized.
What would settle it
Run the same binary parity tasks with randomly chosen parity words of matching weight instead of the learned ones and check whether the accuracy advantage over logistic regression and support-vector machines disappears.
Figures

read the original abstract
We study parity features as representations that can be evaluated entirely classically once the binary or quantized input representation and parity words are fixed, particularly when labels depend on higher-order feature interactions or when discrete inference interfaces support perturbation robustness. A parity feature is a signed product over selected bits of a binary input: once the participating bits are known, evaluation requires no quantum resources. Reaching a useful parity representation requires solving two challenges. When the input is parity-ready (a meaningful binary string), the challenge is basis discovery: selecting useful parity words from a combinatorial search space. Otherwise, the challenge is encoding: constructing a binary vector on which parity computation is meaningful. We use hybrid quantum-classical training pipelines to address these: learnable Pauli word selection for basis discovery, learned projection encodings for continuous embeddings, and sPQC-Parity for discrete inputs. On three native-binary parity tasks with 5-10 qubits, the learned parity basis improves mean accuracy by 23.9% to 41.7% over logistic-regression and support-vector baselines. A model comparison shows that the improvement comes primarily from discovering the right parity basis, rather than from quantum moment computation at inference. On five continuous text benchmarks, learned projection recovers much of the loss introduced by dimensionality reduction and fixed binarization, exceeding the full continuous baseline on CR, SST-2, and SST-5. On three encoding-limited discrete datasets, when compared with PCA-bin as the baseline, sPQC-Parity reaches 94.6% improvement on mushroom, 3.0% on splice, and matches PCA-bin on promoter. We also analyze inference robustness under binary or quantized inference, where rounding gives exact invariance below half the quantization step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces quantum parity representations for tasks where labels depend on higher-order interactions, using hybrid quantum-classical training for learnable Pauli word selection (basis discovery on native-binary inputs), learned projection encodings (for continuous inputs), and sPQC-Parity encoders (for discrete inputs). It claims that on three native-binary parity tasks (5-10 qubits), the learned basis yields 23.9-41.7% mean accuracy gains over logistic regression and SVM baselines, with ablations attributing gains primarily to basis discovery rather than quantum inference; on five continuous text benchmarks it recovers losses from dimensionality reduction; and on three discrete datasets it improves over PCA-bin baselines while providing exact invariance under quantization rounding.
Significance. If the empirical claims are substantiated with full protocols, the work offers a concrete hybrid pipeline for discovering parity features that can be evaluated classically at inference, with potential robustness advantages in quantized or binary settings. The separation of basis discovery from quantum moment evaluation in the model comparison is a constructive element. However, given the small qubit counts (n≤10) and absence of classical parity-selection controls, the significance for demonstrating quantum utility in representation learning remains limited.
major comments (3)
- [Abstract / Experimental results] Abstract and experimental results section: The headline claim of 23.9-41.7% accuracy improvement on native-binary tasks is presented without any description of experimental protocols, dataset details, train/test splits, hyperparameter settings, number of runs, error bars, or statistical tests. This renders the central empirical result unverifiable and load-bearing for all downstream claims about basis discovery.
- [Model comparison / ablation] Model comparison / ablation subsection: The reported separation of contributions shows gains from parity basis discovery rather than quantum inference, but the ablation omits any classical baseline for word selection (e.g., exhaustive enumeration of the ≤1024 parity words for n≤10, beam search, or mutual-information ranking). For these system sizes such classical procedures are computationally trivial and could reproduce or exceed the reported gains, directly challenging the necessity of the hybrid quantum-classical training pipeline.
- [Methods (sPQC-Parity and projection encoders)] Methods on sPQC-Parity and learned projection: The weakest assumption—that hybrid training reliably identifies label-relevant higher-order parity words that survive binarization/quantization—is not tested against post-hoc selection effects or alternative classical feature-selection methods. Without these controls the attribution of improvements to the quantum component remains circular.
minor comments (2)
- [Abstract] The abstract introduces the term 'sPQC-Parity encoder' without a concise definition or pointer to its formal construction; this should be clarified on first use.
- [Notation / Methods] Notation for Pauli words, parity features, and the learned projection parameters is used inconsistently between the abstract and later sections; a unified table of symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify important gaps in experimental reporting and controls. We address each major comment below and will incorporate revisions to improve verifiability and strengthen the attribution of results.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results section: The headline claim of 23.9-41.7% accuracy improvement on native-binary tasks is presented without any description of experimental protocols, dataset details, train/test splits, hyperparameter settings, number of runs, error bars, or statistical tests. This renders the central empirical result unverifiable and load-bearing for all downstream claims about basis discovery.
Authors: We agree that the manuscript currently lacks sufficient detail on experimental protocols, rendering the central claims difficult to verify. In the revised manuscript we will add a dedicated Experimental Setup subsection (and expand the abstract if space permits) that specifies: full dataset descriptions and sources, train/test split ratios and randomization procedures, hyperparameter grids and selection method, number of independent runs with random seeds, error bars as standard deviations, and statistical tests (e.g., paired t-tests with p-values). These additions will make the reported 23.9–41.7 % accuracy gains fully reproducible and verifiable. revision: yes
-
Referee: [Model comparison / ablation] Model comparison / ablation subsection: The reported separation of contributions shows gains from parity basis discovery rather than quantum inference, but the ablation omits any classical baseline for word selection (e.g., exhaustive enumeration of the ≤1024 parity words for n≤10, beam search, or mutual-information ranking). For these system sizes such classical procedures are computationally trivial and could reproduce or exceed the reported gains, directly challenging the necessity of the hybrid quantum-classical training pipeline.
Authors: The referee correctly notes that classical word-selection baselines are feasible for n≤10 and should have been included. We will add these controls (exhaustive enumeration where tractable, beam search, and mutual-information ranking) to the model-comparison and ablation subsection. We will report their accuracy relative to the hybrid quantum pipeline and discuss why the quantum-hybrid optimizer remains relevant for scaling: gradient-based search over Pauli words becomes intractable for n≫10, where 2^n exceeds classical enumeration limits. The revision will therefore both satisfy the immediate request and clarify the intended regime of the method. revision: yes
-
Referee: [Methods (sPQC-Parity and projection encoders)] Methods on sPQC-Parity and learned projection: The weakest assumption—that hybrid training reliably identifies label-relevant higher-order parity words that survive binarization/quantization—is not tested against post-hoc selection effects or alternative classical feature-selection methods. Without these controls the attribution of improvements to the quantum component remains circular.
Authors: We acknowledge that the current manuscript does not sufficiently rule out post-hoc selection effects or compare against classical feature-selection pipelines. In the revision we will add explicit controls: (i) post-hoc classical selection (e.g., L1-regularized logistic regression or recursive feature elimination) applied after fixed binarization/quantization, and (ii) end-to-end classical baselines that perform feature selection without any quantum circuit. These comparisons will be reported alongside the existing ablations, allowing readers to assess whether the hybrid training pipeline yields gains beyond what classical methods achieve on the same binarized inputs. revision: yes
Circularity Check
No circularity: empirical ML study with independent ablations
full rationale
The manuscript is an empirical machine-learning paper that trains hybrid quantum-classical models to select parity words on small (5-10 qubit) native-binary tasks and reports accuracy gains versus LR/SVM baselines. It explicitly includes a model comparison that isolates the contribution of basis discovery from quantum moment evaluation at inference. No first-principles derivation, uniqueness theorem, or closed-form prediction is advanced whose result is definitionally equivalent to its own fitted inputs or to a self-citation chain. The central claims rest on experimental measurements rather than on any self-referential reduction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- Learned projection parameters
- Pauli word selection weights
axioms (2)
- domain assumption Parity features can capture labels that depend on higher-order feature interactions.
- domain assumption Hybrid quantum-classical optimization can discover useful parity bases more effectively than classical search.
invented entities (1)
-
sPQC-Parity encoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A variational eigenvalue solver on a photonic quantum processor,
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, “A variational eigenvalue solver on a photonic quantum processor,”Nature Communications, vol. 5, p. 4213, 2014
work page 2014
-
[2]
Super- vised learning with quantum-enhanced feature spaces,
V . Havl´ıˇcek, A. D. C ´orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Super- vised learning with quantum-enhanced feature spaces,” Nature, vol. 567, no. 7747, pp. 209–212, 2019
work page 2019
-
[3]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,” Nature, vol. 549, no. 7671, pp. 195–202, 2017
work page 2017
-
[4]
Shadows of quantum machine learning,
S. Jerbiet al., “Shadows of quantum machine learning,” Nature Communications, vol. 15, p. 5676, 2024
work page 2024
-
[5]
Pmlb v1.0: an open-source dataset collection for benchmarking machine learning methods,
J. D. Romano, T. T. Le, W. La Cava, J. T. Gregg, D. J. Goldberg, P. Chakraborty, B. Ray, D. S. Himmelstein, W. Fu, and J. H. Moore, “Pmlb v1.0: an open-source dataset collection for benchmarking machine learning methods,”Bioinformatics, vol. 37, no. 8, pp. 1194–1195, 2021
work page 2021
-
[6]
Efficient few-shot learn- ing without prompts,
L. Tunstall, N. Reimers, U. E. S. Jo, L. Bates, D. Korat, M. Wasserblat, and O. Pereg, “Efficient few-shot learn- ing without prompts,”arXiv preprint arXiv:2209.11055, 2022
-
[7]
Recursive deep models for semantic compositionality over a sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Man- ning, A. Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” inProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013, pp. 1631–1642
work page 2013
-
[8]
Character-level con- volutional networks for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level con- volutional networks for text classification,” inAdvances in Neural Information Processing Systems, vol. 28, 2015
work page 2015
-
[9]
CARER: Contextualized affect representations for emotion recognition,
E. Saravia, H.-C. T. Liu, Y .-H. Huang, J. Wu, and Y .- S. Chen, “CARER: Contextualized affect representations for emotion recognition,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 3687–3697
work page 2018
-
[10]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Sch ¨olkopf, and A. J. Smola, “A kernel two-sample test,”Journal of Machine Learning Research, vol. 13, pp. 723–773, 2012
work page 2012
-
[11]
Quantum large language model fine-tuning,
S. H. Kim, J. Mei, C. Girotto, M. Yamada, and M. Roet- teler, “Quantum large language model fine-tuning,”arXiv preprint arXiv:2504.08732, 2025
-
[12]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for con- ditional computation,”arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[13]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019, pp. 3982–3992
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.