Recognition: no theorem link
Context-Aware Spear Phishing: Generative AI-Enabled Attacks Against Individuals via Public Social Media Data
Pith reviewed 2026-05-13 01:44 UTC · model grok-4.3
The pith
Generative AI can turn small amounts of public social media data into highly personalized spear-phishing emails that outperform real-world examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
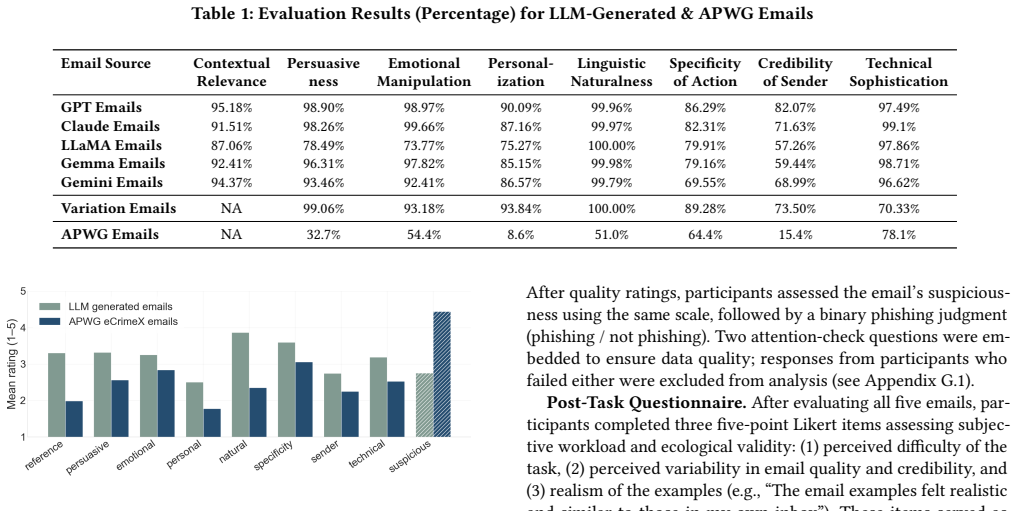
Using public social media data, generative AI models can extract interests, contextual cues, and communication styles to generate context-aware spear-phishing emails across seven strategies including baiting, scareware, honey trap, tailgating, impersonation, quid pro quo, and personalized emotional exploitation. Large-scale evaluations of thousands of emails show superior personalization, contextual grounding, and persuasive leverage compared to real-world phishing messages from sources like APWG eCrimeX. A complementary user study confirms that these LLM-generated attacks consistently outperform the real emails across eight dimensions while eliciting lower suspicion among recipients.
What carries the argument
A modular framework that combines multimodal signal extraction from social media, communication-style profiling, and attack-type instantiation across seven specific strategies.
If this is right
- These attacks can be scaled with minimal attacker effort using only public data.
- The generated messages can bypass generic content-moderation safeguards in current systems.
- Existing proactive prompt-level defenses and system-instruction chain-of-thought moderation fail to block contextualized and adaptive attacks.
- Policy-augmented safeguard models show limitations when facing these personalized prompts.
- Platform-level safeguards must explicitly address contextualized abuse at scale.
Where Pith is reading between the lines
- Platforms may need to add detection for AI-driven reconstruction of user profiles from public posts.
- Similar data-to-attack pipelines could apply to other forms of targeted social engineering.
- Defenders could explore reciprocal techniques that profile potential attackers based on their own public signals.
Load-bearing premise
A small amount of public social media activity per target is enough for generative AI to extract accurate interests, contextual cues, and communication style that produce persuasive messages under real-world conditions.
What would settle it
A controlled study that sends both the generated emails and APWG eCrimeX samples to the same recipients and measures actual click rates plus reported suspicion levels would directly test whether the performance advantage holds.
Figures













read the original abstract
We demonstrate how publicly available social-media data and generative AI (GenAI) can be misused to automate and scale highly personalized, context-aware spear-phishing campaigns. With minimal attacker effort, a small amount of public activity per target is sufficient for GenAI models to extract interests and contextual cues, producing persuasive messages that mirror a target's style while bypassing generic content-moderation safeguards. We introduce a modular framework that combines multimodal signal extraction, communication-style profiling, and attack-type instantiation across seven strategies (baiting, scareware, honey trap, tailgating, impersonation, quid pro quo, and personalized emotional exploitation). We conduct a large-scale, multi-model evaluation covering thousands of generated emails and eight security-relevant criteria, benchmarking against a corpus of real-world phishing messages. The GenAI-produced emails exhibit markedly higher personalization, contextual grounding, and persuasive leverage. Importantly, a complementary user study corroborates these results, revealing that LLM-generated attacks consistently outperform APWG eCrimeX emails across eight dimensions while eliciting lower suspicion among human recipients. Finally, we measure and analyze the behavior of existing proactive, prompt-level defense mechanisms, which incorporate adaptive mechanisms, as well as two complementary defense approaches-policy-augmented SOTA safeguard models and system-instruction chain-of-thought moderation. We document how these defenses respond to contextualized and adaptive attack prompts, underscoring the need for platform-level safeguards that explicitly account for contextualized abuse at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a modular framework combining multimodal signal extraction, communication-style profiling, and seven attack strategies (baiting, scareware, honey trap, tailgating, impersonation, quid pro quo, and personalized emotional exploitation) to generate context-aware spear-phishing emails from small amounts of public social media data per target. It reports a large-scale multi-model evaluation of thousands of generated emails against a corpus of real-world APWG eCrimeX messages on eight security-relevant criteria, a complementary user study showing superior performance and lower suspicion for the GenAI emails, and an analysis of existing proactive defenses including adaptive prompt-level mechanisms, policy-augmented safeguard models, and system-instruction chain-of-thought moderation.
Significance. If the central empirical claims hold after addressing verification gaps, the work provides concrete evidence of GenAI's potential to automate scalable, personalized attacks that bypass generic moderation, offering benchmarks that could directly inform platform-level safeguards and AI safety research in the security community.
major comments (2)
- Abstract and evaluation description: the central claim that LLM-generated attacks 'consistently outperform APWG eCrimeX emails across eight dimensions while eliciting lower suspicion' rests on a user study whose details (sample sizes, statistical tests, exclusion criteria, and bias controls) are not reported, leaving the effectiveness and suspicion results only partially verifiable as noted in the soundness assessment.
- Framework pipeline (multimodal signal extraction section): the premise that 'a small amount of public activity per target is sufficient for GenAI models to extract interests and contextual cues' is untested; no fidelity metric (human or automated comparison of generated profiles/claims against source posts) or stratification by data volume is provided, which is load-bearing for all downstream claims of superior personalization, contextual grounding, and defense bypass.
minor comments (2)
- The abstract lists seven attack strategies but does not clarify how many were instantiated in the large-scale evaluation or user study, which would aid reproducibility.
- Notation for the eight evaluation criteria is introduced without an explicit table or definition list, reducing clarity for readers comparing against APWG benchmarks.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the opportunity to clarify and strengthen the manuscript. Below we address each major comment.
read point-by-point responses
-
Referee: Abstract and evaluation description: the central claim that LLM-generated attacks 'consistently outperform APWG eCrimeX emails across eight dimensions while eliciting lower suspicion' rests on a user study whose details (sample sizes, statistical tests, exclusion criteria, and bias controls) are not reported, leaving the effectiveness and suspicion results only partially verifiable as noted in the soundness assessment.
Authors: We agree that the user study details require more explicit reporting to ensure verifiability. In the revised manuscript, we will add a dedicated subsection in the evaluation describing the participant recruitment (sample size), the statistical analyses conducted (including tests and significance levels), exclusion criteria applied, and bias mitigation strategies such as randomized presentation and attention checks. This will allow readers to fully assess the robustness of the findings on effectiveness and suspicion levels. revision: yes
-
Referee: Framework pipeline (multimodal signal extraction section): the premise that 'a small amount of public activity per target is sufficient for GenAI models to extract interests and contextual cues' is untested; no fidelity metric (human or automated comparison of generated profiles/claims against source posts) or stratification by data volume is provided, which is load-bearing for all downstream claims of superior personalization, contextual grounding, and defense bypass.
Authors: We acknowledge that a direct fidelity evaluation of the extracted profiles against the source social media posts was not included in the original submission. While the large-scale evaluation of the generated emails on personalization and contextual grounding provides supporting evidence for the sufficiency of small data amounts, we agree that an explicit metric would strengthen the claims. In the revision, we will incorporate an automated fidelity metric (e.g., semantic similarity scores between generated profiles and source data) and, where feasible, a stratification analysis by data volume to demonstrate the robustness of the extraction step. revision: yes
Circularity Check
No circularity; purely empirical demonstration with external benchmarks.
full rationale
The paper describes a modular framework for generating context-aware phishing emails from public social media data using LLMs, followed by large-scale evaluation against eight criteria, benchmarking to APWG eCrimeX corpus, a user study measuring suspicion, and analysis of defense mechanisms. No equations, derivations, fitted parameters, predictions, or uniqueness theorems appear. Results rest on direct comparisons to external real-world data and human judgments rather than any self-referential reduction. The central premise (extraction from limited public data) is an unverified assumption but does not create circularity by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public social media posts contain sufficient multimodal signals to extract accurate target interests, context, and communication style
Reference graph
Works this paper leans on
-
[1]
Using GPT-4 for content moderation
2023. Using GPT-4 for content moderation. https://openai .com/index/using-gpt- 4-for-content-moderation/?utm_source=chatgpt.com
work page 2023
-
[2]
BARR’s Analysis of the 2024 Verizon Data Breach Investigations Re- port
2024. BARR’s Analysis of the 2024 Verizon Data Breach Investigations Re- port. https://www .barradvisory.com/resource/barrs-analysis-of-the-2024- verizon-data-breach-investigations-report/
work page 2024
-
[3]
2024. CrowdTangle. https://transparency .meta.com/researchtools/other- datasets/crowdtangle
work page 2024
-
[4]
Upgrading the Moderation API with our new multimodal moderation model
2024. Upgrading the Moderation API with our new multimodal moderation model. https://openai .com/index/upgrading-the-moderation-api-with-our- new-multimodal-moderation-model/?utm_source=chatgpt.com
work page 2024
-
[5]
Ruwa F Abu Hweidi and Derar Eleyan. 2023. Social engineering attack concepts, frameworks, and awareness: A systematic literature review.International Journal of Computing and Digital Systems13, 1 (2023), 691–700
work page 2023
- [6]
-
[7]
Rana Alabdan. 2020. Phishing attacks survey: Types, vectors, and technical approaches.Future internet12, 10 (2020), 168
work page 2020
-
[8]
Hussain Aldawood and Geoffrey Skinner. 2020. An advanced taxonomy for social engineering attacks.International Journal of Computer Applications177, 30 (2020), 1–11
work page 2020
-
[9]
Ahmed Aleroud and Lina Zhou. 2017. Phishing environments, techniques, and countermeasures: A survey.Computers & Security68 (2017), 160–196
work page 2017
-
[10]
Shaukat Ali, Naveed Islam, Azhar Rauf, Ikram Ud Din, Mohsen Guizani, and Joel JPC Rodrigues. 2018. Privacy and security issues in online social networks. Future Internet10, 12 (2018), 114
work page 2018
-
[11]
Zainab Alkhalil, Chaminda Hewage, Liqaa Nawaf, and Imtiaz Khan. 2021. Phish- ing attacks: A recent comprehensive study and a new anatomy.Frontiers in Computer Science3 (2021), 563060
work page 2021
-
[12]
Luca Allodi, Tzouliano Chotza, Ekaterina Panina, and Nicola Zannone. 2019. The need for new antiphishing measures against spear-phishing attacks.IEEE Security & Privacy18, 2 (2019), 23–34
work page 2019
-
[13]
Anthropic. 2024. Claude Haiku. https://www.anthropic.com
work page 2024
-
[14]
Anti-Phishing Working Group. 2025. APWG eCrime Exchange (eCX). (2025). https://apwg.org/ecx Accessed: 2025-08-26
work page 2025
- [15]
-
[16]
Michael Bailey, David Dittrich, Erin Kenneally, and Doug Maughan. 2012. The menlo report.IEEE Security & Privacy10, 2 (2012), 71–75
work page 2012
-
[17]
Marco Balduzzi, Christian Platzer, Thorsten Holz, Engin Kirda, Davide Balzarotti, and Christopher Kruegel. 2010. Abusing social networks for automated user profiling. InInternational Workshop on Recent Advances in Intrusion Detection. Springer, 422–441
work page 2010
- [18]
-
[19]
Akashdeep Bhardwaj, Varun Sapra, Aman Kumar, Naman Kumar, and S Arthi
-
[20]
Why is phishing still successful?Computer Fraud & Security2020, 9 (2020), 15–19
work page 2020
-
[21]
Elie Bursztein, Borbala Benko, Daniel Margolis, Tadek Pietraszek, Andy Archer, Allan Aquino, Andreas Pitsillidis, and Stefan Savage. 2014. Handcrafted fraud and extortion: Manual account hijacking in the wild. InProceedings of the 2014 conference on internet measurement conference. 347–358
work page 2014
-
[22]
Marcus Butavicius, Ronnie Taib, and Simon J Han. 2022. Why people keep falling for phishing scams: The effects of time pressure and deception cues on the detection of phishing emails.Computers & Security123 (2022), 102937
work page 2022
-
[23]
Jinyu Cai, Jialong Li, Mingyue Zhang, Munan Li, Chen-Shu Wang, and Kenji Tei
- [24]
-
[25]
Zhipeng Cai, Zaobo He, Xin Guan, and Yingshu Li. 2016. Collective data- sanitization for preventing sensitive information inference attacks in social networks.IEEE Transactions on Dependable and Secure Computing15, 4 (2016), 577–590
work page 2016
-
[26]
Yanfei Cao, Naijie Gu, Xinyue Shen, Daiyuan Yang, and Xingmin Zhang. 2024. Defending Large Language Models Against Jailbreak Attacks Through Chain of Thought Prompting. In2024 International Conference on Networking and Network Applications (NaNA). IEEE, 125–130
work page 2024
-
[27]
Deanna D Caputo, Shari Lawrence Pfleeger, Jesse D Freeman, and M Eric Johnson
-
[28]
Going spear phishing: Exploring embedded training and awareness.IEEE security & privacy12, 1 (2013), 28–38
work page 2013
-
[29]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Xi Chen, Indranil Bose, Alvin Chung Man Leung, and Chenhui Guo. 2011. As- sessing the severity of phishing attacks: A hybrid data mining approach.Decision Support Systems50, 4 (2011), 662–672
work page 2011
- [31]
-
[32]
Kang Leng Chiew, Kelvin Sheng Chek Yong, and Choon Lin Tan. 2018. A survey of phishing attacks: Their types, vectors and technical approaches.Expert Systems with Applications106 (2018), 1–20
work page 2018
-
[33]
Viraj Desai and R Kavitha. 2024. Unveiling the depths of phishing: Understanding tactics impacts and countermeasures.International Journal of Innovative Research in Science, Engineering and Technology(2024)
work page 2024
-
[34]
Benjamin Edwards, Steven Hofmeyr, and Stephanie Forrest. 2016. Hype and heavy tails: A closer look at data breaches.Journal of Cybersecurity2, 1 (2016), 3–14
work page 2016
-
[35]
J Erkkila. 2011. Why we fall for phishing. InProceedings of the SIGCHI conference on Human Factors in Computing Systems CHI 2011. ACM, 7–12
work page 2011
-
[36]
Neil Zhenqiang Gong and Bin Liu. 2016. You are who you know and how you behave: Attribute inference attacks via users’ social friends and behaviors. In 25th USENIX Security Symposium (USENIX Security 16). 979–995
work page 2016
-
[37]
Neil Zhenqiang Gong and Bin Liu. 2018. Attribute inference attacks in online social networks.ACM Transactions on Privacy and Security (TOPS)21, 1 (2018), 1–30
work page 2018
-
[38]
Robin Gonzalez and Michael E Locasto. 2015. An interdiscplinary study of phishing and spear-phishing attacks.URL http://cups. cs. cmu. edu/soups/2015/papers/eduGonzales. pdf(2015)
work page 2015
-
[39]
2024.Social Engineering in Cybersecurity: Threats and Defenses
HL Gururaj, V Janhavi, and V Ambika. 2024.Social Engineering in Cybersecurity: Threats and Defenses. CRC Press
work page 2024
-
[40]
Chang-Dae Ham, Joonghwa Lee, Jameson L Hayes, and Young Han Bae. 2019. Exploring sharing behaviors across social media platforms.International Journal of Market Research61, 2 (2019), 157–177
work page 2019
- [41]
-
[42]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. De- berta: Decoding-enhanced bert with disentangled attention.arXiv preprint arXiv:2006.03654(2020)
work page internal anchor Pith review arXiv 2020
- [43]
-
[44]
Ryan Heartfield and George Loukas. 2015. A taxonomy of attacks and a survey of defence mechanisms for semantic social engineering attacks.ACM Computing Surveys (CSUR)48, 3 (2015), 1–39
work page 2015
-
[45]
Grant Ho, Asaf Cidon, Lior Gavish, Marco Schweighauser, Vern Paxson, Stefan Savage, Geoffrey M Voelker, and David Wagner. 2019. Detecting and characteriz- ing lateral phishing at scale. In28th USENIX security symposium (USENIX security 19). 1273–1290
work page 2019
-
[46]
Jason Hong. 2012. The state of phishing attacks.Commun. ACM55, 1 (2012), 74–81
work page 2012
-
[47]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
work page 2025
-
[48]
Álvaro Huertas-García, Alejandro Martín, Javier Huertas-Tato, and David Cama- cho. 2023. Countering malicious content moderation evasion in online social networks: Simulation and detection of word camouflage.Applied Soft Computing 145 (2023), 110552
work page 2023
-
[49]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Danesh Irani, Steve Webb, Kang Li, and Calton Pu. 2011. Modeling unintended personal-information leakage from multiple online social networks.IEEE Internet Computing15, 3 (2011), 13–19
work page 2011
-
[51]
David Jaeger, Chris Pelchen, Hendrik Graupner, Feng Cheng, and Christoph Meinel. 2016. Analysis of publicly leaked credentials and the long story of password (re-) use. InProc. Int. Conf. Passwords
work page 2016
-
[52]
Markus Jakobsson and Steven Myers. 2006.Phishing and countermeasures: un- derstanding the increasing problem of electronic identity theft. John Wiley & Sons
work page 2006
-
[53]
Markus Jakobsson and Steven Myers. 2007.Phishing and countermeasures: un- derstanding the increasing problem of electronic identity theft. John Wiley & Sons
work page 2007
-
[54]
S. Kamalesh. 2024. From Offer to Breach: The Empirical Study on Quid Pro Quo Cyber Attack.International Journal of Scientific Research in Engineering and Management (IJSREM)8, 6 (June 2024). doi:10.55041/IJSREM35481
-
[55]
Abu Kamruzzaman, Kutub Thakur, Sadia Ismat, Md Liakat Ali, Kevin Huang, and Hasnain Nizam Thakur. 2023. Social engineering incidents and preventions. In 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, 0494–0498
work page 2023
- [56]
-
[57]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
work page 2022
-
[58]
Deepak Kumar, Yousef Anees AbuHashem, and Zakir Durumeric. 2024. Watch Your Language: Investigating Content Moderation with Large Language Models. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 18. 865–878
work page 2024
-
[59]
Stefan Kutschera. 2023. Incidental data: observation of privacy compromising data on social media platforms.International Cybersecurity Law Review4, 1 (2023), 91–114
work page 2023
-
[60]
Tyson Langford and Bryson Payne. 2023. Phishing faster: Implementing chatgpt into phishing campaigns. InProceedings of the Future Technologies Conference. Springer, 174–187
work page 2023
-
[61]
Patrick A Lawson, Aaron D Crowson, and Christopher B Mayhorn. 2019. Bait- ing the hook: Exploring the interaction of personality and persuasion tactics in email phishing attacks. InProceedings of the 20th Congress of the International Ergonomics Association (IEA 2018) Volume V: Human Simulation and Virtual Envi- ronments, Work With Computing Systems (WWCS...
work page 2019
-
[62]
Stevens Le Blond, Adina Uritesc, Cédric Gilbert, Zheng Leong Chua, Prateek Saxena, and Engin Kirda. 2014. A look at targeted attacks through the lense of an {NGO}. In23rd USENIX Security Symposium (USENIX Security 14). 543–558
work page 2014
-
[63]
Jaeil Lee, Yongjoon Lee, Donghwan Lee, Hyukjin Kwon, and Dongkyoo Shin
-
[64]
Classification of attack types and analysis of attack methods for profiling phishing mail attack groups.IEEE Access9 (2021), 80866–80872
work page 2021
- [65]
- [66]
-
[67]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24). 1831–1847
work page 2024
-
[68]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. 2025. DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2190–2208
work page 2025
-
[69]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[70]
Francois Mouton, Louise Leenen, and Hein S Venter. 2016. Social engineering attack examples, templates and scenarios.Computers & Security59 (2016), 186– 209
work page 2016
-
[71]
OpenAI. 2022. ChatGPT. https://chat.openai.com
work page 2022
-
[72]
Luca Pajola, Eugenio Caripoti, Stefan Banzer, Simeone Pizzi, Mauro Conti, and Giovanni Apruzzese. 2025. E-PhishGen: Unlocking Novel Research in Phishing Email Detection. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security. 64–76
work page 2025
-
[73]
Stefan Palan and Christian Schitter. 2018. Prolific. ac—A subject pool for online experiments.Journal of behavioral and experimental finance17 (2018), 22–27
work page 2018
-
[74]
Ruotian Peng, Haiying He, Yake Wei, Yandong Wen, and Di Hu. 2025. Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Per- ception. InProceedings of the Computer Vision and Pattern Recognition Conference. 3963–3973
work page 2025
-
[75]
Latika Pinjarkar, Pawan Rajendra Hete, Mahantesh Mattada, Santosh Nejakar, Poorva Agrawal, and Gagandeep Kaur. 2024. An Examination of Prevalent Online Scams: Phishing Attacks, Banking Frauds, and E-Commerce Deceptions. In2024 Second International Conference on Advances in Information Technology (ICAIT), Vol. 1. IEEE, 1–6
work page 2024
-
[76]
Qinglin Qi, Yun Luo, Yijia Xu, Wenbo Guo, and Yong Fang. 2025. SpearBot: Leveraging large language models in a generative-critique framework for spear- phishing email generation.Information Fusion122 (2025), 103176
work page 2025
-
[77]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
work page 2020
-
[78]
Sayak Saha Roy, Poojitha Thota, Krishna Vamsi Naragam, and Shirin Nilizadeh
-
[79]
In2024 IEEE Symposium on Security and Privacy (SP)
From Chatbots to Phishbots?: Phishing Scam Generation in Commercial Large Language Models. In2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 221–221
-
[80]
Fatima Salahdine and Naima Kaabouch. 2019. Social engineering attacks: A survey.Future internet11, 4 (2019), 89
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.