Recognition: no theorem link
Information and Contract Design for Repeated Interactions between Agents with Misaligned Incentives
Pith reviewed 2026-05-13 00:46 UTC · model grok-4.3
The pith
A Sender with private information learns an optimal communication strategy that a Receiver follows in repeated interactions, and uses linear contracts to extract surplus despite misaligned incentives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Sender learns an optimal communication strategy that the Receiver reliably acts on, and this strategy is highly sensitive to the degree of conflict in the agents' rewards and the amount of environmental information the Receiver can already observe. Linear contracts enable the Sender to improve its rewards by pricing the information, but this results in the Sender extracting much of the Receiver's surplus.
What carries the argument
The linear contract mechanism for pricing information exchanged in repeated interactions between agents with misaligned incentives.
If this is right
- The Sender's learned communication strategy varies with the level of reward conflict between the two agents.
- The strategy also changes based on the amount of prior environmental information available to the Receiver.
- Linear contracts allow the Sender to improve its own performance by charging for information.
- This improvement for the Sender comes with reduced fairness as it captures much of the Receiver's surplus.
Where Pith is reading between the lines
- This setup implies that in applications like autonomous agents in markets, information asymmetry could lead to one party dominating through learned contracts.
- Fairness concerns might require external mechanisms to balance surplus extraction in multi-agent learning systems.
- Extending to cases where both agents learn simultaneously could reveal different dynamics in strategy formation.
Load-bearing premise
That the Sender can reliably learn an optimal communication strategy and that linear contracts can be formed and used to price information effectively in repeated interactions.
What would settle it
An experiment where the Receiver does not reliably follow the Sender's communication strategy even after many interactions, or where introducing linear contracts fails to increase the Sender's rewards while decreasing the Receiver's.
Figures




read the original abstract
We study the consequences of information asymmetries and misaligned incentives in settings with multiple independent agents. We model an interaction between a Sender, who holds vital private information but cannot act, and a Receiver, who must make decisions but is dependent on the Sender's information. We find that the Sender learns an optimal communication strategy that the Receiver reliably acts on. Importantly, this strategy is highly sensitive to the degree of conflict in the agents' rewards and the amount of environmental information the Receiver can already observe. We introduce a mechanism allowing the agents to form linear contracts, where a price is established for the information. We demonstrate that the Sender learns to use these payment structures to improve its rewards, though this comes at a cost of "fairness" between agents as the Sender is able to extract much of the Receiver's surplus. This raises questions about fairness, contract design, and learning in the context of multi-agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models repeated interactions between a Sender with private environmental information and a Receiver who must choose actions, under misaligned reward functions. Using reinforcement learning, the Sender learns a communication policy that the Receiver conditions on; this policy is shown to be sensitive to the degree of reward conflict and the Receiver's direct observability of the environment. The authors introduce linear contracts that price signals, allowing the Sender to extract surplus from the Receiver and improve its own payoff, at the expense of fairness between the agents.
Significance. If the simulation results hold, the work contributes to multi-agent systems research on information design and contract mechanisms under asymmetry. Credit is given for the explicit repeated-game formulation, action spaces, reward functions, and RL training loop defined in Sections 3 and 4, together with the reported sensitivity to conflict degree and surplus-extraction outcomes. These elements provide a concrete empirical basis for discussing fairness costs in learned contracts.
minor comments (3)
- [§3.3] §3.3: The linear contract is introduced as a payment for signals, but the exact functional form (e.g., whether the price is per-signal or per-period) is stated only in prose; an equation would remove ambiguity for readers implementing the mechanism.
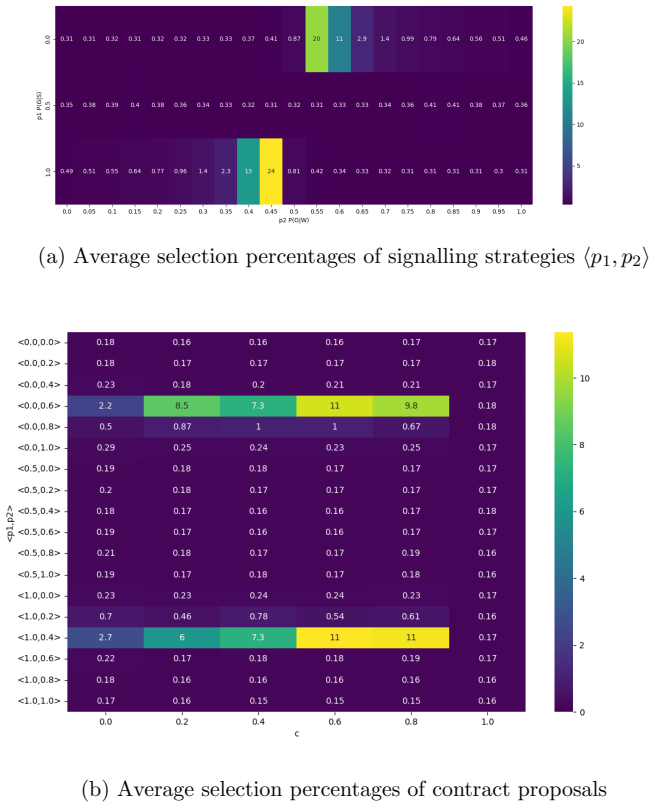
- [§4.2] §4.2, results on fairness: The claim that the Sender extracts 'much of the Receiver's surplus' is supported by the plots, yet the precise fairness metric (e.g., reward ratio, utility difference, or Gini coefficient) is not defined in the text or caption; this affects interpretability of the cost.
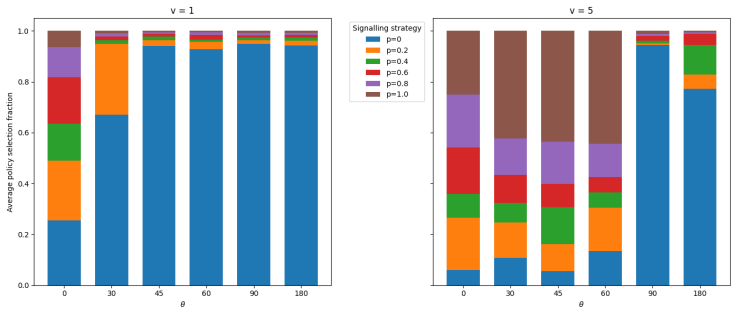
- [Figure 3] Figure 3: The sensitivity plots to conflict degree and Receiver information would benefit from error bars or shaded regions indicating variability across random seeds, as is standard for RL experiments.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation of minor revision. We appreciate the recognition of the explicit repeated-game formulation, action spaces, reward functions, RL training loop, and sensitivity analyses as providing a concrete empirical basis for discussing fairness in multi-agent contract design.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper explicitly defines the repeated game, information structure, linear contract mechanism, and RL training loop for the Sender's policy in Sections 3 and 4, including environment, action spaces, and reward functions. The reported sensitivity of the learned communication strategy to conflict degree and Receiver information, along with surplus extraction, follows directly from these definitions and simulation outputs without reducing to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. No step equates a claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- degree of conflict in agents' rewards
- amount of environmental information the Receiver can observe
axioms (2)
- domain assumption Agents learn optimal communication and contract strategies through repeated interactions.
- ad hoc to paper Linear contracts can be formed to establish a price for information.
invented entities (1)
-
Linear contract mechanism for information pricing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D. Bergemann, A. Bonatti, and A. Smolin. The design and price of information.American Economic Review, 108(1):1–48, 2018
work page 2018
-
[2]
G. Carroll. Robustness and linear contracts.American Economic Re- view, 105(2):536–563, 2015
work page 2015
-
[3]
P. J. Christoffersen, A. A. Haupt, and D. Hadfield-Menell. Get it in writing: Formal contracts mitigate social dilemmas in multi-agent rl. InProceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’23, page 448–456, Richland, SC, 2023. International Foundation for Autonomous Agents and Multi- agent Systems
work page 2023
-
[4]
F. L. Da Silva and A. H. R. Costa. A survey on transfer learn- ing for multiagent reinforcement learning systems.J. Artif. Int. Res., 64(1):645–703, Jan. 2019
work page 2019
-
[5]
F. L. da Silva, R. Glatt, and A. H. R. Costa. Simultaneously learning and advising in multiagent reinforcement learning. InProceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’17, page 1100–1108, Richland, SC, 2017. International Foundation for Autonomous Agents and Multiagent Systems
work page 2017
-
[6]
P. Duetting, M. Feldman, and I. Talgam-Cohen. Algorithmic contract theory: A survey, 2024
work page 2024
-
[7]
P. Duetting, T. Roughgarden, and I. Talgam-Cohen. Simple versus op- timal contracts. InProceedings of the 2019 ACM Conference on Eco- nomics and Computation, EC ’19, page 369–387, New York, NY, USA,
work page 2019
-
[8]
Association for Computing Machinery
-
[9]
S. Dughmi. Algorithmic information structure design: a survey.SIGe- com Exch., 15(2):2–24, Feb. 2017
work page 2017
-
[10]
J. Gan, R. Majumdar, G. Radanovic, and A. Singla. Bayesian persuasion in sequential decision-making.Proceedings of the AAAI Conference on Artificial Intelligence, 36(5):5025–5033, Jun. 2022. 20
work page 2022
-
[11]
A. Garivier and E. Moulines. On upper-confidence bound policies for switching bandit problems. In J. Kivinen, C. Szepesv´ ari, E. Ukkonen, and T. Zeugmann, editors,Algorithmic Learning Theory, pages 174–188, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg
work page 2011
- [12]
-
[13]
E. Kamenica and M. Gentzkow. Bayesian persuasion.American Eco- nomic Review, 101(6):2590–2615, October 2011
work page 2011
-
[14]
Y. Lin, W. Li, H. Zha, and B. Wang. Information design in multi- agent reinforcement learning. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc
work page 2023
-
[15]
Z. Liu, D. J. Zhang, and F. Zhang. Information sharing on retail plat- forms.Manufacturing & Service Operations Management, 23(3):606– 619, 2021
work page 2021
-
[16]
Salani´ e.The Economics of Contracts: A Primer
B. Salani´ e.The Economics of Contracts: A Primer. MIT Press, Cam- bridge, MA, 2nd edition, 2005
work page 2005
-
[17]
S. G. Subramanian, M. E. Taylor, K. Larson, and M. Crowley. Multi- agent advisor q-learning.Journal of Artificial Intelligence Research, 74:1–74, 2022
work page 2022
-
[18]
J. Wu, Z. Zhang, Z. Feng, Z. Wang, Z. Yang, M. I. Jordan, and H. Xu. Sequential information design: Markov persuasion process and its effi- cient reinforcement learning. InProceedings of the 23rd ACM Conference on Economics and Computation, EC ’22, page 471–472, New York, NY, USA, 2022. Association for Computing Machinery
work page 2022
-
[19]
J. Zhang and B. R. Nault. Upstream information sharing in platform- based e-commerce with retail plan adjustment.Decision Support Sys- tems, 177:114099, 2024
work page 2024
-
[20]
C. Zhu, M. Dastani, and S. Wang. A survey of multi-agent deep rein- forcement learning with communication.Autonomous Agents and Multi- Agent Systems, 38(4), 2024. 21 Appendix A Modeling Choices We study settings where there are two different agents, aSender (S)and a Receiver (R), interacting in some environment. There are some key asym- metries in the pro...
work page 2024
-
[21]
S can decide whether or not to share this information with R
The Sender (S) has an informational advantage over the Receiver (R) in that it can observe more of the environment. S can decide whether or not to share this information with R
-
[22]
The Sender (S) must rely on the actions of the Receiver
The Receiver (R) has agency, in that it can act in the environment. The Sender (S) must rely on the actions of the Receiver
-
[23]
Both R and S obtain rewards from the environment. However, the rewards may be different and may not be fully aligned. A single interaction of this kind has been studied extensively as Bayesian persuasion [12, 11]. We study the repeated interaction setting of the same problem with the possibility of payments (through contracts), but retain two key componen...
-
[24]
It learns to do this using MAB where each arm corresponds to a specific discretized contract
At the start of an episode, Sender proposes a contract⟨p, c⟩. It learns to do this using MAB where each arm corresponds to a specific discretized contract
-
[25]
Receiver accepts or rejects it. This is learned through contextual ban- dits where the context is the contract, and the two arms correspond to accept and reject
-
[26]
At any timestep within the episode, Receiver makes local observation. 23 Sender sends action advisea ′, which is drawn from Receiver-optimal policyπ ′ R with probabilityp, and fromπ ′ S with probability 1−p
-
[27]
Receiver uses its local observation, action advisea ′, and the contract state to choose its action (using standard RL algorithms), which changes the environment
-
[28]
Additionally, a fractioncof the Receiver’s reward is transferred to the Sender
Both Sender and Receiver get environment rewards due to the Re- ceiver’s action. Additionally, a fractioncof the Receiver’s reward is transferred to the Sender
-
[29]
At the end of an episode, both Sender and Receiver use their episodic rewards to update the arm values for contract proposal and contract acceptance, respectively. B Optimal Contracts Analysis We denote the episodic return of an agent following policyπasJ(π), given by: J(π) =E τ∼π "T−1X t=0 γtrt+1 # , In particular, we are interested in the utilities (ave...
-
[30]
We get a similar result through our theoretical analysis in Section 2.2.1
If the professor uses the optimal signalling policy above, i.e., recommend a weak student with one half probability, then the professor increases their expected utility to 2 3. We get a similar result through our theoretical analysis in Section 2.2.1. The Receiver-optimal policyπ ′ R is to hire when student is of typeSand to not hire otherwise. The Sender...
-
[31]
are: VRR = 1 3 , VSR = 1 3 , VSS = 1, VRS =− 1 3 ,andU 0 R = 0 To get the optimal commitment probability,p ∗, plugging these values into (4), we get:p ∗ = 1
-
[32]
When the student is of typeS, the optimal policiesπ ′ S andπ ′ R coincide, both recommending to hire
We note that this compact optimal solution is equivalent to the optimal signalling policy⟨1,0.5⟩derived above. When the student is of typeS, the optimal policiesπ ′ S andπ ′ R coincide, both recommending to hire. Hence, althoughp ∗ represents an equal-probability mixture overπ ′ S andπ ′ R, the resulting recommendation is the same, i.e., P r(R|S) = 1. In ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.