Recognition: 1 theorem link
· Lean TheoremCan Graphs Help Vision SSMs See Better?
Pith reviewed 2026-05-13 06:08 UTC · model grok-4.3
The pith
GraphScan adds local graph message passing to boost vision state space models on classification and segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
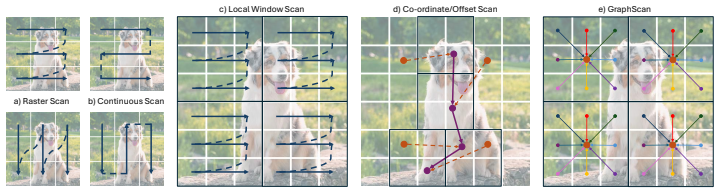
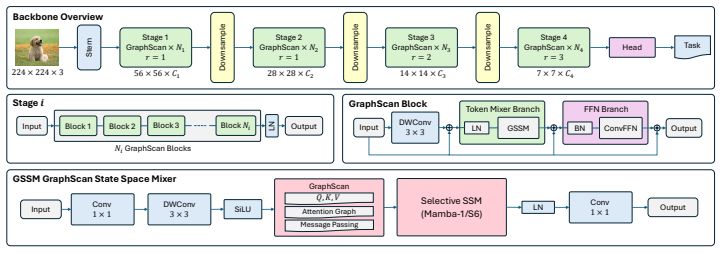
We introduce GraphScan, a graph-induced dynamic scanning operator for Vision SSMs. For each token, GraphScan constructs a spatially bounded local graph, learns feature-conditioned affinities with relative positional bias, and produces the output token by one-step message passing over its semantic neighborhood. The resulting tokens are locally grounded before being processed by the selective SSM for global aggregation. Integrated into a hierarchical backbone, GraphScan-Mamba achieves state-of-the-art performance among Vision SSMs across image classification, object detection, instance segmentation, and semantic segmentation, with modest computational overhead. The operator also induces analyz
What carries the argument
GraphScan: a graph-induced dynamic scanning operator that builds spatially bounded local graphs, learns feature-conditioned affinities with positional bias, and performs one-step message passing to ground tokens semantically before selective SSM processing.
If this is right
- GraphScan-Mamba sets new accuracy records among vision SSMs on image classification, object detection, instance segmentation, and semantic segmentation.
- Token count and linear complexity in image size remain unchanged.
- Coordinate-based interpolation is replaced by feature-driven semantic routing.
- The method produces interpretable displacement fields over the token lattice that reveal semantic and spatial structure.
- Future vision SSM designs should combine learned local semantic routing with global state-space mixing.
Where Pith is reading between the lines
- The same local-graph routing idea could be tested inside transformer blocks or other sequence models for vision.
- The induced displacement fields might serve as a diagnostic tool for understanding how models group visual content.
- Extending the bounded graphs to temporal neighborhoods could improve video processing without quadratic cost.
- Combining GraphScan with existing dynamic sampling methods might compound gains while keeping overhead low.
Load-bearing premise
The learned feature affinities within each local spatial graph will reliably form semantic neighborhoods that improve the downstream selective SSM without needing task-specific retuning.
What would settle it
If replacing GraphScan with a standard geometric scan in the same backbone yields equal or higher accuracy on the same detection and segmentation benchmarks, the benefit of the graph operator would be refuted.
Figures



read the original abstract
Vision state space models inherit the efficiency and long-range modeling ability of Mamba-style selective scans. However, their performance depends critically on the representation of two-dimensional visual features as one-dimensional token sequences. Existing scan operators range from predefined geometric traversals to dynamic coordinate-based samplers that reroute tokens through predicted offsets and interpolation. While effective, these mechanisms primarily adapt paths or sampling locations, rather than explicitly modeling which local patches should exchange information before global state-space mixing. This motivates a simple question: \emph{can graphs help vision state space models see better?} We introduce \textbf{GraphScan}, a graph-induced dynamic scanning operator for Vision SSMs. For each token, GraphScan constructs a spatially bounded local graph, learns feature-conditioned affinities with relative positional bias, and produces the output token by one-step message passing over its semantic neighborhood. The resulting tokens are locally grounded before being processed by the selective SSM for global aggregation. GraphScan preserves token count and linear scaling in image size, while replacing coordinate-conditioned interpolation with feature-conditioned semantic routing. Integrated into a hierarchical backbone, \textbf{GraphScan-Mamba} achieves state-of-the-art performance among Vision SSMs across image classification, object detection, instance segmentation, and semantic segmentation, with modest computational overhead. Our analysis further shows that GraphScan induces interpretable displacement fields over the token lattice, providing a semantic and spatially grounded view of dynamic scanning. These results suggest that future Vision SSMs should treat scanning not merely as geometric serialization, but as learned local semantic routing before global state-space modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GraphScan, a graph-induced dynamic scanning operator for Vision SSMs. For each token, it builds a spatially bounded local graph, computes feature-conditioned affinities augmented by relative positional bias, and applies one-step message passing over the resulting semantic neighborhood to produce locally grounded tokens. These tokens are then fed into a standard selective SSM for global aggregation. The resulting GraphScan-Mamba hierarchical backbone is reported to achieve state-of-the-art results among Vision SSMs on image classification, object detection, instance segmentation, and semantic segmentation while incurring only modest computational overhead; the method is also claimed to produce interpretable displacement fields over the token lattice.
Significance. If the empirical claims are substantiated, the work provides a concrete demonstration that explicit local graph-based semantic routing can improve the local grounding of tokens before global state-space mixing in Vision SSMs. This reframes scanning as learned neighborhood construction rather than purely geometric serialization or coordinate-based resampling, which could influence the design of future efficient vision backbones that combine graph and SSM primitives. The preservation of linear complexity and token count is a practical strength.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The central SOTA claim among Vision SSMs is asserted without any quantitative tables, ablation studies, error bars, or detailed baseline comparisons in the provided manuscript. This absence makes it impossible to assess the magnitude of improvement, statistical significance, or whether the gains are attributable to GraphScan rather than other implementation details.
- [§3.2] §3.2 (Graph Construction and Message Passing): The paper does not supply a quantitative validation (e.g., edge-class agreement with semantic labels or comparison against low-level edge detectors) that the learned feature-conditioned affinities with relative positional bias produce semantic neighborhoods rather than low-level feature correlations. Without such a check, the one-step message passing could reduce to learned local averaging whose benefit might be replicated by a small convolution at lower cost, undermining the semantic-routing interpretation.
- [§3.3] §3.3 (Integration with Selective SSM): No equations or ablation are provided showing how the output of the graph message-passing step is exactly injected into the SSM recurrence (e.g., whether it replaces the input projection, augments the state, or is simply concatenated). This leaves open whether the reported gains require the full GraphScan machinery or could be obtained by a simpler local operator.
minor comments (2)
- [§3.1] Notation for the affinity function and relative positional bias is introduced without an explicit equation number or pseudocode listing, making the precise computation of edge weights difficult to reproduce from the text alone.
- [§3] The manuscript would benefit from a small diagram or pseudocode block illustrating the full forward pass of one GraphScan layer, including the transition from graph output to SSM input.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We will revise the manuscript to address the concerns raised regarding the presentation of empirical results and technical details of the method.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central SOTA claim among Vision SSMs is asserted without any quantitative tables, ablation studies, error bars, or detailed baseline comparisons in the provided manuscript. This absence makes it impossible to assess the magnitude of improvement, statistical significance, or whether the gains are attributable to GraphScan rather than other implementation details.
Authors: We agree that the empirical claims require stronger substantiation through quantitative results. In the revised manuscript, we will expand the abstract to reference key performance metrics and include detailed tables in §4 with comparisons to existing Vision SSMs such as VMamba and others on ImageNet classification, COCO object detection, and segmentation tasks. We will also add ablation studies, report results with error bars from multiple runs, and provide more granular baseline comparisons to demonstrate that the improvements stem from the GraphScan operator. revision: yes
-
Referee: [§3.2] §3.2 (Graph Construction and Message Passing): The paper does not supply a quantitative validation (e.g., edge-class agreement with semantic labels or comparison against low-level edge detectors) that the learned feature-conditioned affinities with relative positional bias produce semantic neighborhoods rather than low-level feature correlations. Without such a check, the one-step message passing could reduce to learned local averaging whose benefit might be replicated by a small convolution at lower cost, undermining the semantic-routing interpretation.
Authors: We acknowledge the value of quantitative validation for the semantic interpretation. We will add a new analysis in the revised §3.2, including metrics such as the agreement rate between the learned graph edges and semantic class boundaries derived from ground-truth labels on a held-out set. Additionally, we will compare the learned affinities against those produced by standard low-level edge detectors like Canny or Sobel to highlight the semantic conditioning. This will help distinguish the approach from simple local averaging and support the semantic-routing claim. revision: yes
-
Referee: [§3.3] §3.3 (Integration with Selective SSM): No equations or ablation are provided showing how the output of the graph message-passing step is exactly injected into the SSM recurrence (e.g., whether it replaces the input projection, augments the state, or is simply concatenated). This leaves open whether the reported gains require the full GraphScan machinery or could be obtained by a simpler local operator.
Authors: We appreciate this observation on the need for precise technical specification. In the revised §3.3, we will include explicit mathematical formulations showing that the message-passing output directly substitutes for the input features in the selective SSM's input projection. Furthermore, we will incorporate an ablation experiment replacing the graph-based message passing with a standard local convolution to quantify the additional benefit of the semantic graph routing. This will clarify the necessity of the full GraphScan design for achieving the reported performance gains. revision: yes
Circularity Check
No circularity: GraphScan is an independent architectural addition whose performance claims rest on empirical benchmarks rather than self-referential definitions or fitted inputs.
full rationale
The paper presents GraphScan as a new module that builds spatially bounded local graphs, computes feature-conditioned affinities with positional bias, and applies one-step message passing before feeding tokens into the selective SSM. No equations or derivations reduce the claimed semantic routing benefit to a fitted parameter renamed as a prediction, nor does any load-bearing step rely on a self-citation chain or uniqueness theorem imported from the authors' prior work. The SOTA results are reported as experimental outcomes on standard vision tasks; the method does not derive its improvements by construction from its own inputs. This is the common case of a self-contained architectural proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Relational inductive biases, deep learning, and graph networks
Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks.arXiv preprint arXiv:1806.01261, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Vision transformer adapter for dense predictions
Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[3]
Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Twins: Revisiting the design of spatial attention in vision transformers.Advances in neural information processing systems, 34:9355–9366, 2021
work page 2021
-
[4]
Conditional positional encodings for vision transformers
Xiangxiang Chu, Zhi Tian, Bo Zhang, Xinlong Wang, and Chunhua Shen. Conditional positional encodings for vision transformers. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[5]
Zihang Dai, Hanxiao Liu, Quoc V Le, and Mingxing Tan. Coatnet: Marrying convolution and attention for all data sizes.Advances in neural information processing systems, 34:3965–3977, 2021
work page 2021
-
[6]
Tri Dao and Albert Gu. Transformers are ssms: generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024
work page 2024
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[8]
Xiaohan Ding, Yiyuan Zhang, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, and Ying Shan. Unireplknet: A universal perception large-kernel convnet for audio video point cloud time-series and image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5513–5524, 2024
work page 2024
-
[9]
Cswin transformer: A general vision transformer backbone with cross-shaped windows
Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, and Baining Guo. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12124–12134, 2022
work page 2022
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
Hungry hungry hippos: Towards language modeling with state space models
Daniel Y Fu, Tri Dao, Khaled Kamal Saab, Armin W Thomas, Atri Rudra, and Christopher Re. Hungry hungry hippos: Towards language modeling with state space models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[12]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. Pmlr, 2017
work page 2017
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
work page 2024
-
[14]
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. On the parameterization and initialization of diagonal state space models.Advances in neural information processing systems, 35:35971–35983, 2022
work page 2022
-
[15]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2022
work page 2022
-
[16]
Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, and Enhua Wu. Vision gnn: An image is worth graph of nodes.Advances in neural information processing systems, 35:8291–8303, 2022
work page 2022
-
[17]
Neighborhood attention transformer
Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi. Neighborhood attention transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6185–6194, 2023
work page 2023
-
[18]
Mambavision: A hybrid mamba-transformer vision backbone
Ali Hatamizadeh and Jan Kautz. Mambavision: A hybrid mamba-transformer vision backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25261–25270, 2025
work page 2025
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[20]
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In2017 IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017
work page 2017
-
[21]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017
work page 2017
-
[22]
Localmamba: Visual state space model with windowed selective scan
Tao Huang, Xiaohuan Pei, Shan You, Fei Wang, Chen Qian, and Chang Xu. Localmamba: Visual state space model with windowed selective scan. InEuropean conference on computer vision, pages 12–22. Springer, 2024. 10
work page 2024
-
[23]
R. E. Kalman. A new approach to linear filtering and prediction problems.Journal of Basic Engineering, 82(1):35–45, 1960
work page 1960
-
[24]
Similarity-aware selective state-space modeling for semantic correspon- dence
Seungwook Kim and Minsu Cho. Similarity-aware selective state-space modeling for semantic correspon- dence. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 6147–6157, 2025
work page 2025
-
[25]
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017
work page 2017
-
[26]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[27]
Mamba-3: Improved sequence modeling using state space principles
Aakash Lahoti, Kevin Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
- [28]
-
[29]
Mamba-nd: Selective state space modeling for multi- dimensional data
Shufan Li, Harkanwar Singh, and Aditya Grover. Mamba-nd: Selective state space modeling for multi- dimensional data. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024
work page 2024
-
[30]
DAMamba: Vision state space model with dynamic adaptive scan
Tanzhe Li, Caoshuo Li, Jiayi Lyu, Hongjuan Pei, Baochang Zhang, Taisong Jin, and Rongrong Ji. DAMamba: Vision state space model with dynamic adaptive scan. InThe Thirty-ninth Annual Con- ference on Neural Information Processing Systems, 2025
work page 2025
-
[31]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision – ECCV 2014, pages 740–755, Cham, 2014. Springer International Publishing
work page 2014
-
[32]
Pay attention to mlps.Advances in neural information processing systems, 34:9204–9215, 2021
Hanxiao Liu, Zihang Dai, David So, and Quoc V Le. Pay attention to mlps.Advances in neural information processing systems, 34:9204–9215, 2021
work page 2021
-
[33]
Defmamba: Deformable visual state space model
Leiye Liu, Miao Zhang, Jihao Yin, Tingwei Liu, Wei Ji, Yongri Piao, and Huchuan Lu. Defmamba: Deformable visual state space model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8838–8847, 2025
work page 2025
-
[34]
More convnets in the 2020s: Scaling up kernels beyond 51x51 using sparsity
Shiwei Liu, Tianlong Chen, Xiaohan Chen, Xuxi Chen, Qiao Xiao, Boqian Wu, Tommi Kärkkäinen, Mykola Pechenizkiy, Decebal Constantin Mocanu, and Zhangyang Wang. More convnets in the 2020s: Scaling up kernels beyond 51x51 using sparsity. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[35]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024
work page 2024
-
[36]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[37]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022
work page 2022
-
[38]
MMDetection.https://github.com/open-mmlab/mmdetection
MMDetection Contributors. MMDetection.https://github.com/open-mmlab/mmdetection
-
[39]
MMSegmentation Contributors. MMSegmentation. https://github.com/open-mmlab/ mmsegmentation
-
[40]
Vcmamba: Bridging convolutions with multi- directional mamba for efficient visual representation
Mustafa Munir, Alex Zhang, and Radu Marculescu. Vcmamba: Bridging convolutions with multi- directional mamba for efficient visual representation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 3037–3046, 2025
work page 2025
-
[41]
Efficientvmamba: Atrous selective scan for light weight visual mamba
Xiaohuan Pei, Tao Huang, and Chang Xu. Efficientvmamba: Atrous selective scan for light weight visual mamba. InProceedings of the AAAI conference on artificial intelligence, pages 6443–6451, 2025
work page 2025
-
[42]
Hyena hierarchy: Towards larger convolutional language models
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning, pages 28043–28078. PMLR, 2023
work page 2023
-
[43]
Designing network design spaces
Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. Designing network design spaces. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10428–10436, 2020
work page 2020
-
[44]
Group- mamba: Efficient group-based visual state space model
Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, and Fahad Shahbaz Khan. Group- mamba: Efficient group-based visual state space model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14912–14922, 2025
work page 2025
-
[45]
Yuheng Shi, Minjing Dong, and Chang Xu. Multi-scale vmamba: Hierarchy in hierarchy visual state space model.Advances in Neural Information Processing Systems, 37:25687–25708, 2024
work page 2024
-
[46]
Vssd: Vision mamba with non-causal state space duality
Yuheng Shi, Mingjia Li, Minjing Dong, and Chang Xu. Vssd: Vision mamba with non-causal state space duality. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10819–10829, 2025. 11
work page 2025
-
[47]
Very deep convolutional networks for large-scale image recogni- tion
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. Association for Computing Machinery, 2015
work page 2015
-
[48]
Smith, Andrew Warrington, and Scott Linderman
Jimmy T.H. Smith, Andrew Warrington, and Scott Linderman. Simplified state space layers for sequence modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[49]
Springer Science & Business Media, 2013
Eduardo D Sontag.Mathematical control theory: deterministic finite dimensional systems. Springer Science & Business Media, 2013
work page 2013
-
[50]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015
work page 2015
-
[51]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019
work page 2019
-
[52]
Scalable visual state space model with fractal scanning.arXiv preprint arXiv:2405.14480, 2024
Lv Tang, HaoKe Xiao, Peng-Tao Jiang, Hao Zhang, Jinwei Chen, and Bo Li. Scalable visual state space model with fractal scanning.arXiv preprint arXiv:2405.14480, 2024
-
[53]
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
work page 2021
-
[54]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021
work page 2021
-
[55]
Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. Resmlp: Feedforward networks for image classification with data-efficient training.IEEE transactions on pattern analysis and machine intelligence, 45(4):5314–5321, 2022
work page 2022
-
[56]
Maxvit: Multi-axis vision transformer
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxvit: Multi-axis vision transformer. InEuropean conference on computer vision, pages 459–479. Springer, 2022
work page 2022
-
[57]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[58]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[59]
Repvit: Revisiting mobile cnn from vit perspective
Ao Wang, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Repvit: Revisiting mobile cnn from vit perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15909–15920, 2024
work page 2024
-
[60]
Bo Wang, Mengyuan Xu, Yue Yan, Yuqun Yang, Kechen Shu, Wei Ping, Xu Tang, Wei Jiang, and Zheng You. Asm-unet: Adaptive scan mamba integrating group commonalities and individual variations for fine-grained segmentation, 2025
work page 2025
-
[61]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF international conference on computer vision, pages 568–578, 2021
work page 2021
-
[62]
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pvt v2: Improved baselines with pyramid vision transformer.Computational visual media, 8 (3):415–424, 2022
work page 2022
-
[63]
Internimage: Exploring large-scale vision foundation models with deformable convolutions
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14408–14419, 2023
work page 2023
-
[64]
Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018
work page 2018
-
[65]
Convnext v2: Co-designing and scaling convnets with masked autoencoders
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Convnext v2: Co-designing and scaling convnets with masked autoencoders. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16133–16142, 2023
work page 2023
-
[66]
Pvg: Progressive vision graph for vision recognition
JiaFu Wu, Jian Li, Jiangning Zhang, Boshen Zhang, Mingmin Chi, Yabiao Wang, and Chengjie Wang. Pvg: Progressive vision graph for vision recognition. InProceedings of the 31st ACM international conference on multimedia, pages 2477–2486, 2023
work page 2023
-
[67]
Vision transformer with deformable attention
Zhuofan Xia, Xuran Pan, Shiji Song, Li Erran Li, and Gao Huang. Vision transformer with deformable attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4794–4803, 2022
work page 2022
-
[68]
Spatial-mamba: Effective visual state space models via structure-aware state fusion
Chaodong Xiao, Minghan Li, Zhengqiang ZHANG, Deyu Meng, and Lei Zhang. Spatial-mamba: Effective visual state space models via structure-aware state fusion. InThe Thirteenth International Conference on Learning Representations, 2025. 12
work page 2025
-
[69]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InProceedings of the European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[70]
Quadmamba: Learning quadtree-based selective scan for visual state space model
Fei Xie, Weijia Zhang, Zhongdao Wang, and Chao Ma. Quadmamba: Learning quadtree-based selective scan for visual state space model. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[71]
Pvmamba: Parallelizing vision mamba via dynamic state aggregation
Fei Xie, Zhongdao Wang, Weijia Zhang, and Chao Ma. Pvmamba: Parallelizing vision mamba via dynamic state aggregation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10218–10228, 2025
work page 2025
-
[72]
Chenhongyi Yang, Zehui Chen, Miguel Espinosa, Linus Ericsson, Zhenyu Wang, Jiaming Liu, and Elliot J. Crowley. Plainmamba: Improving non-hierarchical mamba in visual recognition. In35th British Machine Vision Conference 2024, BMVC 2024, Glasgow, UK, November 25-28, 2024. BMV A, 2024
work page 2024
-
[73]
Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Xiyang Dai, Bin Xiao, Lu Yuan, and Jianfeng Gao. Focal self-attention for local-global interactions in vision transformers.arXiv preprint arXiv:2107.00641, 2021
-
[74]
Inceptionnext: When inception meets convnext
Weihao Yu, Pan Zhou, Shuicheng Yan, and Xinchao Wang. Inceptionnext: When inception meets convnext. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 5672–5683, 2024
work page 2024
-
[75]
Objectness scan for efficient vision mamba.Knowledge-Based Systems, 330:114573, 2025
Kai Zhang, Xia Yuan, and Chunxia Zhao. Objectness scan for efficient vision mamba.Knowledge-Based Systems, 330:114573, 2025
work page 2025
-
[76]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5122–5130, 2017
work page 2017
-
[77]
Biformer: Vision transformer with bi-level routing attention
Lei Zhu, Xinjiang Wang, Zhanghan Ke, Wayne Zhang, and Rynson WH Lau. Biformer: Vision transformer with bi-level routing attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10323–10333, 2023
work page 2023
-
[78]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InForty-first International Conference on Machine Learning, 2024. 13 A Analysis of GraphScan-Induced Selective Scan This appendix provides a more detailed analysis of how GraphSca...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.