Recognition: 2 theorem links
· Lean TheoremPredicting Psychological Well-Being from Spontaneous Speech using LLMs
Pith reviewed 2026-05-13 01:38 UTC · model grok-4.3
The pith
Large language models predict Ryff psychological well-being scores from spontaneous speech with Spearman correlations up to 0.8.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs can extract semantically meaningful cues from spontaneous speech to predict Ryff PWB scores in a zero-shot manner, achieving Spearman correlations of up to 0.8 on 80% of the data from 111 participants.
What carries the argument
Domain-informed prompt that instructs LLMs to rate the six Ryff PWB dimensions from speech input, applied across twelve instruction-tuned models including Llama-3, Mistral, Gemma, and Phi variants.
If this is right
- High correlations support the use of LLMs for scalable, non-intrusive assessment of psychological well-being from natural speech.
- Statistical characterization of prediction variability can guide selection of reliable cases and flag model biases.
- Keyword analyses reveal which linguistic features drive ratings on each PWB dimension, aiding interpretability.
- Strong performance on 80% of participants suggests the method works for many speakers while highlighting the need to handle the remaining cases separately.
Where Pith is reading between the lines
- The same prompting strategy could be tested on other self-report psychological scales to check transferability across constructs.
- Deployment in real-world settings would require checking whether speech-derived scores match clinician judgments beyond self-reports.
- Performance gaps across model sizes suggest smaller models may suffice for many practical well-being screening tasks.
- Extending the approach to multilingual or accented speech would test robustness beyond the current English-dominant dataset.
Load-bearing premise
The domain-informed prompt produces ratings that validly reflect true Ryff PWB dimensions rather than surface linguistic patterns or model biases.
What would settle it
Substantially lower Spearman correlations on a new, independent collection of spontaneous speech recordings from a different population would indicate that the predictions do not generalize.
Figures





read the original abstract
We investigate the use of Large Language Models (LLMs) for zero-shot prediction of Ryff Psychological Well-Being (PWB) scores from spontaneous speech. Using a few minutes of voice recordings from 111 participants in the PsyVoiD database, we evaluated 12 instruction-tuned LLMs, including Llama-3 (8B, 70B), Ministral, Mistral, Gemma-2-9B, Gemma-3 (1B, 4B, 27B), Phi-4, DeepSeek (Qwen and Llama), and QwQ-Preview. A domain-informed prompt was developed in collaboration with experts in clinical psychology and linguistics. Results show that LLMs can extract semantically meaningful cues from spontaneous speech, achieving Spearman correlations of up to 0.8 on 80\% of the data. Additionally, to enhance explainability, we conducted statistical analyses to characterise prediction variability and systematic biases, alongside keyword-based word cloud analyses to highlight the linguistic features driving the models' predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the use of 12 instruction-tuned LLMs (Llama-3 8B/70B, Ministral, Mistral, Gemma-2/3 variants, Phi-4, DeepSeek, QwQ) for zero-shot prediction of Ryff Psychological Well-Being (PWB) scores from a few minutes of spontaneous speech in the PsyVoiD database (N=111 participants). A domain-informed prompt developed with clinical psychology and linguistics experts is employed; the central result is Spearman correlations reaching 0.8 on 80% of the data, accompanied by analyses of prediction variability, systematic biases, and keyword-based linguistic features for explainability.
Significance. If the reported correlations prove robust on the full sample without selection artifacts, the work would demonstrate that LLMs can extract semantically meaningful cues from naturalistic speech for scalable, non-invasive PWB assessment. This has clear implications for mental health monitoring and voice-interface applications, with the multi-model evaluation and explainability components (bias/variability stats, word clouds) adding value beyond simple performance claims.
major comments (3)
- [Abstract and Results] Abstract and Results: The peak Spearman ρ ≈ 0.8 is reported only for an unspecified 80% subset of the 111 participants. The manuscript must state the exclusion criteria (pre-registered or otherwise), report full-sample correlations with confidence intervals or standard errors, and show that the 20% exclusion does not materially alter the distribution of PWB scores or audio quality. Without these, the headline figure cannot be interpreted as representative performance.
- [Methods] Methods (Prompt construction): The domain-informed prompt is central to the zero-shot framing, yet its exact wording, development process, and any validation against human raters are not provided. The paper should include the full prompt text and evidence that ratings track the six Ryff dimensions rather than surface-level linguistic patterns or model priors.
- [Results] Results (Statistical analyses): Bias and variability analyses are mentioned but lack quantitative detail (specific tests, effect sizes, or how they interact with the 80% subset). Model comparisons across the 12 LLMs should include a systematic ranking or ablation to isolate contributing factors.
minor comments (2)
- [Abstract] Abstract: Specify which model and PWB dimension achieve the ρ = 0.8 figure, and report the range of correlations across all evaluations rather than only the maximum.
- [Figures/Tables] Figures/Tables: Any correlation tables or plots should present both the 80% subset and full-sample results side-by-side, with error bars or intervals where applicable.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped clarify several aspects of our work. We have revised the manuscript to improve transparency on the data subset, provide the prompt details, and expand the statistical reporting. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The peak Spearman ρ ≈ 0.8 is reported only for an unspecified 80% subset of the 111 participants. The manuscript must state the exclusion criteria (pre-registered or otherwise), report full-sample correlations with confidence intervals or standard errors, and show that the 20% exclusion does not materially alter the distribution of PWB scores or audio quality. Without these, the headline figure cannot be interpreted as representative performance.
Authors: We agree that the subset requires full documentation. In the revised manuscript we explicitly describe the exclusion criteria (audio duration <3 minutes or SNR <15 dB) in the Methods and note that they were applied post-hoc for transcription reliability rather than pre-registered. We now report full-sample Spearman correlations together with bootstrapped 95% confidence intervals for every model. We also add Kolmogorov-Smirnov and Mann-Whitney tests confirming that the excluded 20% do not differ significantly from the retained sample in PWB score distributions or audio-quality metrics. The abstract has been updated to foreground the full-sample results while retaining the subset figure for comparison. revision: yes
-
Referee: [Methods] Methods (Prompt construction): The domain-informed prompt is central to the zero-shot framing, yet its exact wording, development process, and any validation against human raters are not provided. The paper should include the full prompt text and evidence that ratings track the six Ryff dimensions rather than surface-level linguistic patterns or model priors.
Authors: We have added the complete prompt text to a new Appendix A. The Methods section now details the three-round iterative development process conducted with two clinical psychologists and one linguist to map instructions onto the six Ryff dimensions. To demonstrate that predictions rely on dimension-specific cues rather than surface patterns, we include an ablation comparing the original prompt against a version stripped of dimension-specific language; performance drops substantially, supporting targeted semantic use. We did not, however, collect independent human-expert ratings of the speech samples on the Ryff scales, so a direct validation comparison is not available. revision: partial
-
Referee: [Results] Results (Statistical analyses): Bias and variability analyses are mentioned but lack quantitative detail (specific tests, effect sizes, or how they interact with the 80% subset). Model comparisons across the 12 LLMs should include a systematic ranking or ablation to isolate contributing factors.
Authors: The revised Results section now supplies the requested quantitative detail. Bias is quantified with one-sample t-tests on mean prediction error and Cohen’s d effect sizes; variability is assessed with Levene’s tests on prediction standard deviations. All metrics are presented for both the 80% subset and the full sample to show any differential effects. Model comparisons are expanded to a ranked table of all 12 LLMs by full-sample Spearman correlation, accompanied by an ablation that isolates the contributions of model size, instruction-tuning status, and prompt components (dimension-specific instructions versus generic framing). revision: yes
- Formal validation of the LLM outputs against independent human expert ratings on the six Ryff dimensions was not performed in the study.
Circularity Check
No circularity: empirical zero-shot evaluation with external benchmarks
full rationale
The paper reports an empirical study in which instruction-tuned LLMs are applied in zero-shot fashion to spontaneous speech recordings from 111 participants to predict Ryff PWB scores. Performance is quantified by Spearman rank correlations against ground-truth scores, with supplementary statistical bias analyses and keyword-based linguistic feature inspection. No mathematical derivations, equations, or first-principles predictions appear that reduce outputs to inputs by construction. The 80 % data subset is presented as the basis for the headline correlation figure, yet the evaluation uses held-out participants and external benchmarks rather than any fitted parameter that is subsequently renamed as a prediction. No self-citation chains, uniqueness theorems, or smuggled ansatzes are invoked to justify the central claim. The reported pipeline is therefore self-contained as direct model inference plus standard statistical comparison.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs encode semantically meaningful cues about psychological states in transcribed speech.
- domain assumption Spearman correlation on a subset of data is a sufficient indicator of predictive utility.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
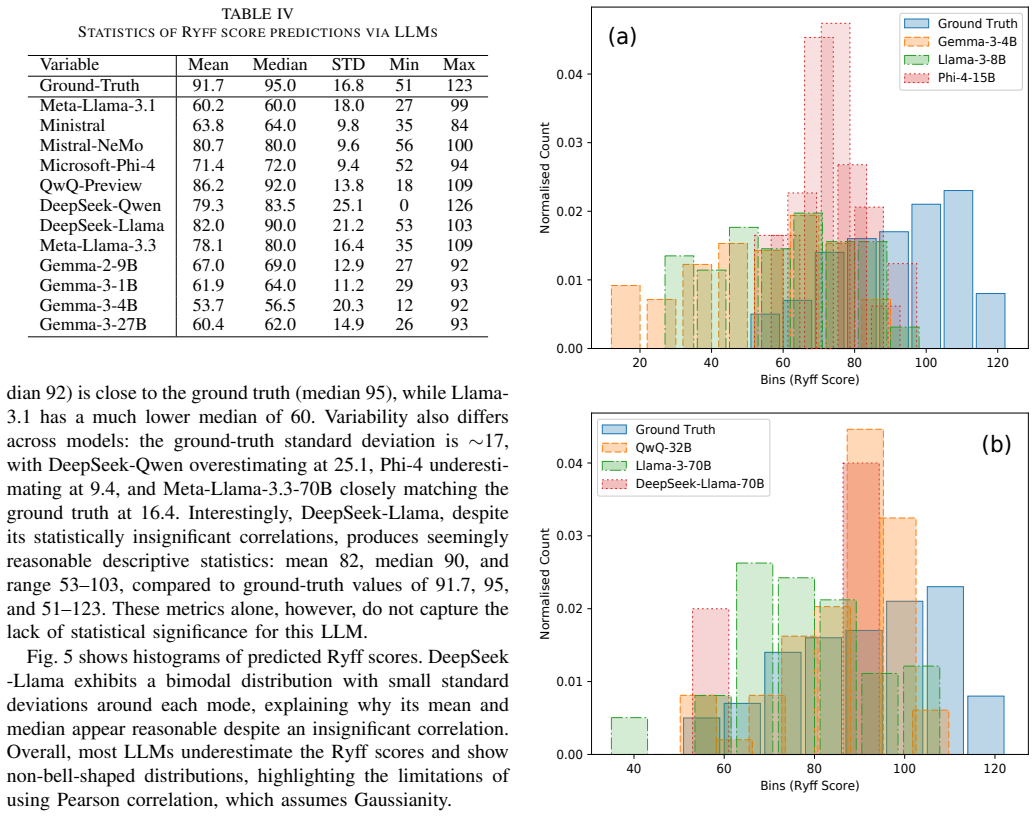
achieving Spearman correlations of up to 0.8 on 80% of the data... cumulative correlations... Data Retention (%) = n/N ×100
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
prompt... six Ryff dimensions... JSON output with scores, keywords, evidence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N. Salari et al., “Prevalence of stress, anxiety, depression among the general population during the covid-19 pandemic: a systematic review and meta-analysis,”Globalization and health, vol. 16, pp. 1–11, 2020
work page 2020
-
[2]
Mental health and covid-19: early evidence of the pandemic’s impact: scientific brief, 2 march 2022,
World Health Organization et al., “Mental health and covid-19: early evidence of the pandemic’s impact: scientific brief, 2 march 2022,” Tech. Rep., World Health Organization, 2022
work page 2022
-
[3]
The psychological consequences of covid- 19 lockdowns,
K. Le and M. Nguyen, “The psychological consequences of covid- 19 lockdowns,” inThe political economy of COVID-19, pp. 39–55. Routledge, 2022
work page 2022
-
[4]
M. V on Korff et al., “Anxiety and depression in a primary care clinic: comparison of diagnostic interview schedule, general health question- naire, and practitioner assessments,”Archives of General Psychiatry, vol. 44, no. 2, pp. 152–156, 1987
work page 1987
-
[5]
E. C. Stade et al., “Depression and anxiety have distinct and overlapping language patterns: Results from a clinical interview.,”Journal of psychopathology and clinical science, 2023
work page 2023
-
[6]
The heterogeneity of mental health assessment,
J. J. Newson, D. Hunter, and T. C. Thiagarajan, “The heterogeneity of mental health assessment,”Frontiers in psychiatry, vol. 11, pp. 76, 2020
work page 2020
-
[7]
The psychiatric interview: validity, structure, and subjectivity,
J. Nordgaard, L. A. Sass, and J. Parnas, “The psychiatric interview: validity, structure, and subjectivity,”European archives of psychiatry and clinical neuroscience, vol. 263, pp. 353–364, 2013
work page 2013
-
[8]
Automatic speech emotion recognition using modulation spectral features,
S. Wu, T. H. Falk, and W. Y . Chan, “Automatic speech emotion recognition using modulation spectral features,”Speech communication, vol. 53, no. 5, pp. 768–785, 2011
work page 2011
-
[9]
S. de la Fuente Garcia, C. W. Ritchie, and S. Luz, “Artificial intelligence, speech, and language processing approaches to monitoring alzheimer’s disease: a systematic review,”Journal of Alzheimer’s Disease, vol. 78, no. 4, pp. 1547–1574, 2020
work page 2020
-
[10]
K. Roy et al., “Large language models for mental health diagnostic assessments: Exploring the potential of large language models for assisting with mental health diagnostic assessments – the depression and anxiety case,” 2025
work page 2025
-
[11]
Automated assessment of psychiatric disorders using speech: A systematic review,
D. M. Low, K. H. Bentley, and S. S. Ghosh, “Automated assessment of psychiatric disorders using speech: A systematic review,”Laryngoscope investigative otolaryngology, vol. 5, no. 1, pp. 96–116, 2020
work page 2020
-
[12]
Current applications and challenges in large language models for patient care: a systematic review,
F. Busch, L. Hoffmann, C. Rueger, E. H. C. van Dijk, R. Kader, E. Ortiz-Prado, M. R. Makowski, L. Saba, M. Hadamitzky, J. N. Kather, D. Truhn, R. Cuocolo, L. C. Adams, and K. K. Bressem, “Current applications and challenges in large language models for patient care: a systematic review,”Communications Medicine, vol. 5, no. 1, pp. 1–13, 2025
work page 2025
-
[13]
Using large language models as a scalable mental sta- tus evaluation technique,
M. Wagner, C. Stephenson, J. Jagayat, A. Kumar, A. Shirazi, N. Alavi, and M. Omrani, “Using large language models as a scalable mental sta- tus evaluation technique,”NPP—Digital Psychiatry and Neuroscience, vol. 3, no. 1, pp. 1–11, 2025
work page 2025
-
[14]
The hospital anxiety and depression scale,
A. S. Zigmond and R. P. Snaith, “The hospital anxiety and depression scale,”Acta psychiatrica scandinavica, vol. 67, no. 6, 1983
work page 1983
-
[15]
Zero-shot speech-based depression and anxiety assessment with LLMs,
E. Loweimi, S. de la Fuente Garcia, and S. Luz, “Zero-shot speech-based depression and anxiety assessment with LLMs,” inProc. Interspeech 2025, 2025, pp. 489–493
work page 2025
-
[16]
Y . Li, S. Shao, M. Milling, and B. W. Schuller, “Large language models for depression recognition in spoken language integrating psychological knowledge,”Frontiers in Computer Science, vol. 7, 2025
work page 2025
-
[17]
S. V . Patapati, “Integrating large language models into a tri-modal architecture for automated depression classification on the DAIC-WOZ,” arXiv preprint arXiv:2407.19340, 2024
-
[18]
Large language models for mental health applications: Systematic review,
Z. Guo et al., “Large language models for mental health applications: Systematic review,”JMIR mental health, vol. 11, no. 1, pp. e57400, 2024
work page 2024
-
[19]
A scoping review of large language models for generative tasks in mental health care,
Y . Hua, H. Na, Z. Li, F. Liu, X. Fang, D. Clifton, and J. Torous, “A scoping review of large language models for generative tasks in mental health care,”NPJ Digital Medicine, vol. 8, no. 1, pp. 230, 2025
work page 2025
-
[20]
Zero-shot learning with semantic output codes,
M. Palatucci et al., “Zero-shot learning with semantic output codes,” inAdvances in Neural Information Processing Systems (NIPS). 2009, vol. 22, Curran Associates, Inc
work page 2009
-
[21]
Language models are few-shot learners,
T. Brown et al., “Language models are few-shot learners,” inAdvances in Neural Information Processing Systems. 2020, vol. 33, pp. 1877–1901, Curran Associates, Inc
work page 2020
-
[22]
Happiness is everything, or is it? explorations on the meaning of psychological well-being.,
C. D. Ryff, “Happiness is everything, or is it? explorations on the meaning of psychological well-being.,”Journal of personality and social psychology, vol. 57, no. 6, pp. 1069, 1989
work page 1989
-
[23]
The structure of psychological well-being revisited,
C. D. Ryff and C. L. Keyes, “The structure of psychological well-being revisited,”Journal of personality and social psychology, vol. 69, no. 4, pp. 719, 1995
work page 1995
-
[24]
C. D. Ryff, “Self-realisation and meaning making in the face of adversity: A eudaimonic approach to human resilience,”Journal of psychology in Africa, vol. 24, no. 1, pp. 1–12, 2014
work page 2014
-
[25]
G. R. Lau and W. Y . Low, “From human to machine psychology: A conceptual framework for understanding well-being in large language model,”arXiv preprint arXiv:2506.12617, 2025
-
[26]
S. de la Fuente Garcia and S. Luz, “PsyV oiD - investigating the relationship between spontaneous speech features and psychology in the context of the covid-19 pandemic and lockdown: personality, wellbeing, coping strategies and affect, 2020-2021 [dataset],” 2023
work page 2020
-
[27]
Aaron Grattafiori et al., “The llama 3 herd of models,” 2024
work page 2024
- [28]
- [29]
-
[30]
Gemma 2: Improving open language models at a practical size,
Gemma Team et al., “Gemma 2: Improving open language models at a practical size,” 2024
work page 2024
- [31]
-
[32]
Mistral AI Team, “Ministral-8B-Instruct-2410,” 2024, Accessed: 2024
work page 2024
-
[33]
Mistral AI Team, “Mistral NeMo,” https://mistral.ai/news/mistral-nemo, 2024, Accessed: 2024
work page 2024
-
[34]
QwQ: Reflect Deeply on the Boundaries of the Unknown,
Qwen Team, “QwQ: Reflect Deeply on the Boundaries of the Unknown,” November 2024
work page 2024
-
[35]
An Yang et al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI et al., “DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning,” 2025
work page 2025
-
[37]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever, “Robust speech recognition via large- scale weak supervision,”arXiv preprint arXiv:2212.04356, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Prompt engineering for digital mental health: a short review,
Y . H. P. P. Priyadarshana, A. Senanayake, Z. Liang, and I. Piumarta, “Prompt engineering for digital mental health: a short review,”Frontiers in Digital Health, vol. 6, pp. 1410947, 2024
work page 2024
-
[39]
Scikit-learn: Machine learning in python,
F. Pedregosa et al., “Scikit-learn: Machine learning in python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.