Recognition: no theorem link
Constraint-Data-Value-Maximization: Utilizing Data Attribution for Effective Data Pruning in Low-Data Environments
Pith reviewed 2026-05-13 01:35 UTC · model grok-4.3
The pith
Constraint-Data-Value-Maximization selects a small training subset by maximizing total influence while capping any single point's contribution to individual test examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing data value estimates are not optimally suited for pruning low-value data when only a limited amount remains. By casting pruning as a constrained optimization that maximizes total influence and penalizes excessive per-test contributions, the CDVM approach selects subsets that preserve downstream model utility even at very low retention rates.
What carries the argument
Constraint-Data-Value-Maximization (CDVM), the formulation that turns data pruning into a constrained optimization maximizing aggregate attribution scores while bounding per-test-point influence contributions.
If this is right
- Models retain higher test accuracy when trained on the CDVM-chosen subset rather than a top-k attribution subset at the same small retention rate.
- The procedure works with any underlying data attribution method without altering how the scores themselves are obtained.
- Runtime stays competitive with standard attribution-based pruning on existing evaluation suites.
- The performance benefit holds across varying model types and datasets in the reported experiments.
Where Pith is reading between the lines
- The same constrained selection logic could be adapted to decide which historical examples to retain in continual learning settings.
- Tuning the per-test contribution penalty might expose how much redundancy is present in common training collections.
- One could check whether CDVM subsets also improve model robustness under distribution shift compared with standard pruning.
Load-bearing premise
Attribution scores computed on the full dataset remain reliable guides to each example's value once most other examples have been removed.
What would settle it
If models trained on CDVM-selected subsets show no consistent accuracy advantage over models trained on subsets chosen by ranking attribution scores, when both are tested at the same low retention fractions on repeated benchmark runs, the central advantage claim would be falsified.
Figures






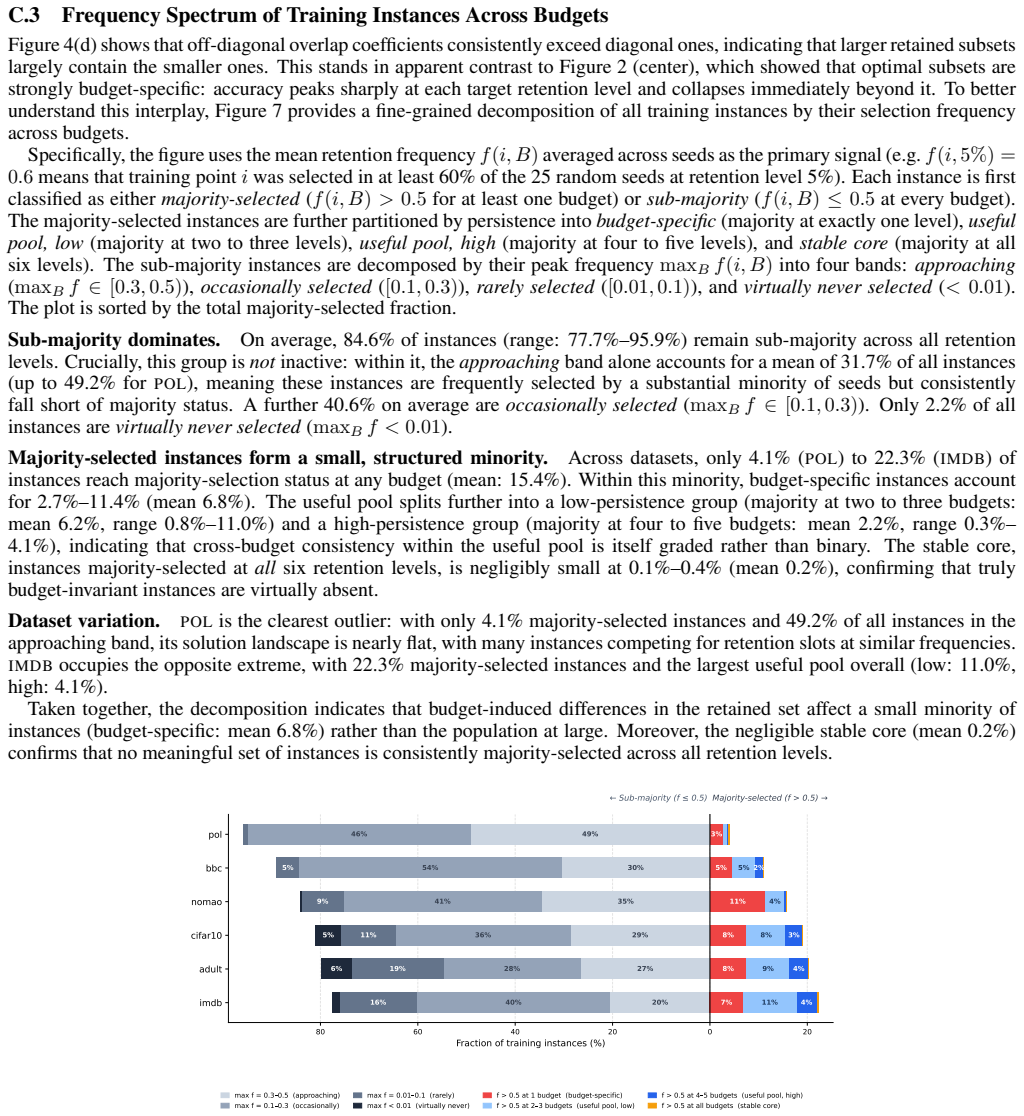



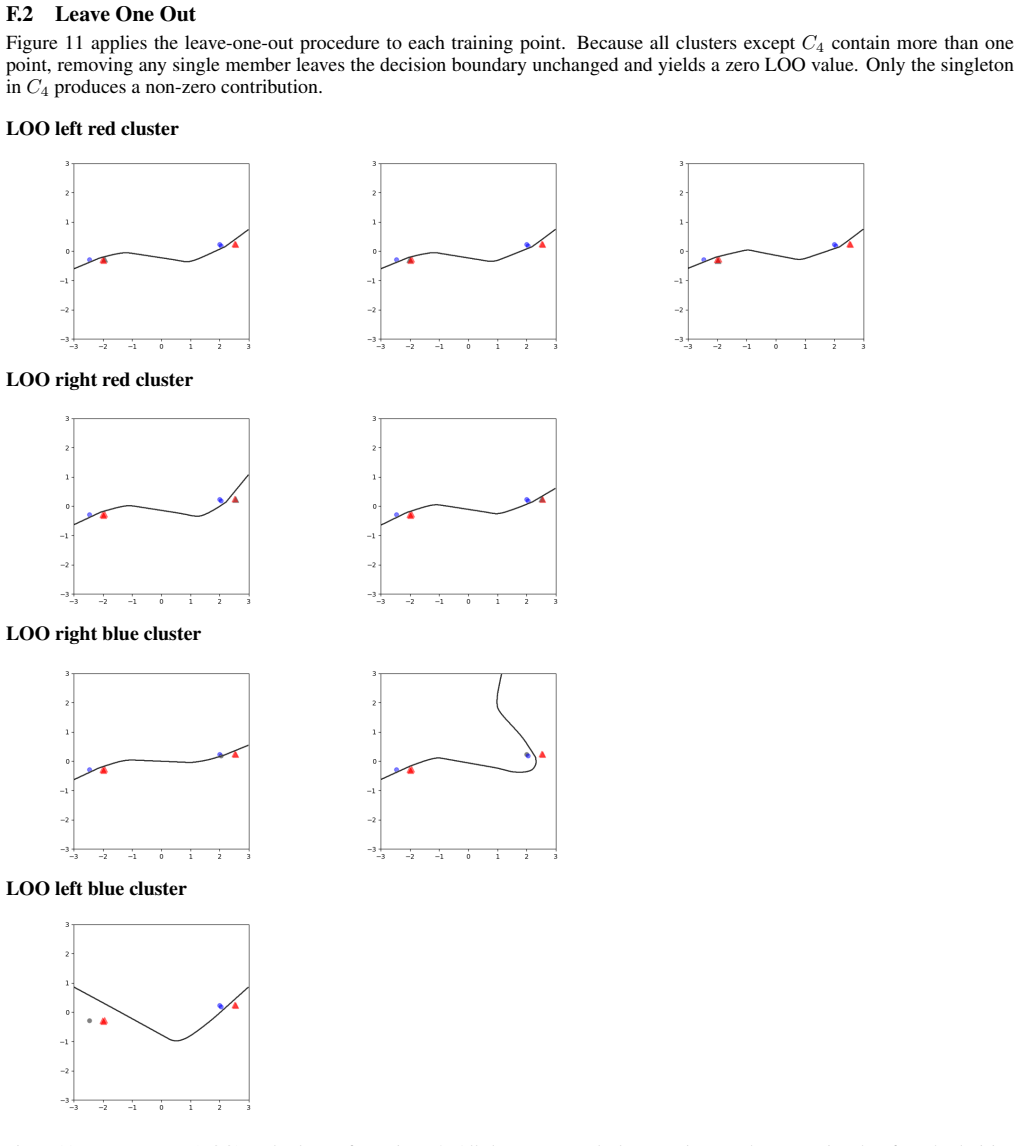

read the original abstract
Attributing model behavior to training data is an evolving research field. A common benchmark is data removal, which involves eliminating data instances with either low or high values, then assessing a model's performance trained on the modified dataset. Many existing studies leverage Shapley-based data values for this task. In this paper, we demonstrate that these data values are not optimally suited for pruning low-value data when only a limited amount of data remains. To address this limitation, we introduce the Constraint-Data-Value-Maximization (CDVM) approach, which effectively utilizes data attributions for pruning in low-data scenarios. By casting pruning as a constrained optimization that both maximizes total influence and penalizes excessive per-test contributions, CDVM delivers robust performance when only a small fraction of the data is retained. On the OpenDataVal benchmark, CDVM shows strong performance and competitive runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Shapley-based data attribution scores are suboptimal for pruning low-value data in low-retention regimes. It introduces Constraint-Data-Value-Maximization (CDVM), which formulates pruning as a constrained optimization problem that maximizes aggregate data influence while penalizing excessive per-test-point contributions. On the OpenDataVal benchmark, CDVM achieves strong performance gains over baselines with competitive runtime when only a small fraction of data is retained.
Significance. If the results hold, the work is significant for data-efficient machine learning and attribution methods. It provides a principled constrained-optimization lens on pruning that directly addresses limitations of direct thresholding on attribution scores in low-data settings. Strengths include the explicit CDVM formulation (constrained maximization of total value with per-test penalties), consistent empirical gains in the low-retention regime on a standard benchmark, competitive runtime, and transparent reliance on pre-computed attributions that is empirically tested.
minor comments (1)
- Abstract: The summary of the method would be clearer if it briefly stated the form of the constraint (e.g., the per-test contribution penalty) rather than only describing its effect.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The referee summary correctly identifies the core contribution of CDVM as a constrained optimization formulation that maximizes aggregate data influence while penalizing excessive per-test-point contributions, along with its empirical advantages in low-retention regimes on the OpenDataVal benchmark.
Circularity Check
No significant circularity detected
full rationale
The paper introduces CDVM as a constrained optimization applied to pre-existing data attribution scores (e.g., Shapley values) for pruning, without deriving or re-fitting those attributions within the method itself. No equations, self-citations, or ansatzes are shown that reduce the optimization outcome or performance claims to tautological restatements of inputs. The approach is explicitly built on external attribution techniques, with empirical results on the OpenDataVal benchmark providing independent validation. This constitutes a standard, non-circular extension of prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Yang, Tianji and Zou, James and Kwon, Yongchan and Jia, Ruoxi , title =
Wang, Jiachen T. and Yang, Tianji and Zou, James and Kwon, Yongchan and Jia, Ruoxi , title =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[2]
Proceedings of the 42nd International Conference on Machine Learning , year =
Yeseul Cho and Baekrok Shin and Changmin Kang and Chulhee Yun , title =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[3]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year =
Muyang He and Shuo Yang and Tiejun Huang and Bo Zhao , title =. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , year =
work page 2024
-
[4]
International Conference on Learning Representations , year =
Tan, Haoru and Wu, Sitong and Huang, Wei and Zhao, Shizhen and Qi, Xiaojuan , title =. International Conference on Learning Representations , year =
-
[5]
International Conference on Learning Representations , year =
Jiang, Wenyu and Liu, Zhenlong and Xie, Zejian and Zhang, Songxin and Jing, Bingyi and Wei, Hongxin , title =. International Conference on Learning Representations , year =
- [6]
-
[7]
The Eleventh International Conference on Learning Representations , year =
Shuo Yang and Zeke Xie and Hanyu Peng and Min Xu and Mingming Sun and Ping Li , title =. The Eleventh International Conference on Learning Representations , year =
-
[8]
shapiq: Shapley Interactions for Machine Learning , booktitle =
Maximilian Muschalik and Hubert Baniecki and Fabian Fumagalli and Patrick Kolpaczki and Barbara Hammer and Eyke H\". shapiq: Shapley Interactions for Machine Learning , booktitle =. 2024 , url =
work page 2024
-
[9]
36th International Conference on Machine Learning, ICML 2019 , year =
Amirata Ghorbani and James Zou , title =. 36th International Conference on Machine Learning, ICML 2019 , year =
work page 2019
-
[10]
34th International Conference on Machine Learning, ICML 2017 , year =
Pang Wei Koh and Percy Liang , title =. 34th International Conference on Machine Learning, ICML 2017 , year =
work page 2017
-
[11]
Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , year =
Dan Feldman , title =. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , year =. doi:10.1002/widm.1335 , issn =
-
[12]
Does learning require memorization? a short tale about a long tail , volume=
Vitaly Feldman , title =. Proceedings of the Annual ACM Symposium on Theory of Computing , year =. doi:10.1145/3357713.3384290 , isbn =
-
[13]
Proceedings of the 35th International Conference on Neural Information Processing Systems , year =
Paul, Mansheej and Ganguli, Surya and Dziugaite, Gintare Karolina , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , year =
- [14]
-
[15]
Jiachen T. Wang and R. Jia , title =. International Conference on Artificial Intelligence and Statistics , year =
-
[16]
Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , year =
Kwon, Yongchan and Zou, James , title =. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , year =
-
[17]
Proceedings of the 40th International Conference on Machine Learning , year =
Kwon, Yongchan and Zou, James , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[18]
The Twelfth International Conference on Learning Representations , year =
Jiayuan Ye and Anastasia Borovykh and Soufiane Hayou and Reza Shokri , title =. The Twelfth International Conference on Learning Representations , year =
-
[19]
Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
Jiang, Kevin Fu and Liang, Weixin and Zou, James and Kwon, Yongchan , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
-
[20]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
Sim, Rachael Hwee Ling and Xu, Xinyi and Low, Bryan Kian Hsiang , title =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , editor =
work page 2022
-
[21]
Proceedings of the 40th International Conference on Machine Learning , year =
Park, Sung Min and Georgiev, Kristian and Ilyas, Andrew and Leclerc, Guillaume and Madry, Aleksander , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[22]
Hammoudeh, Zayd and Lowd, Daniel , title =. Mach. Learn. , year =. doi:10.1007/s10994-023-06495-7 , url =
-
[23]
Revisiting Methods for Finding Influential Examples , journal =
Karthikeyan K and Anders S. Revisiting Methods for Finding Influential Examples , journal =. 2021 , month =
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.