Recognition: 2 theorem links
· Lean Theoremvarepsilon-Good Action Identification in Fixed-Budget Monte Carlo Tree Search
Pith reviewed 2026-05-13 01:57 UTC · model grok-4.3
The pith
An algorithm identifies ε-good subtrees in depth-2 max-min trees with fixed samples T without receiving ε as input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In depth-2 max-min trees the ε-agnostic algorithm achieves misidentification probability decaying as exp(−Θ̃(T / H₂(ε))) for every meaningful ε, where H₂(ε) is built from both cross-subtree and within-subtree gaps. When each subtree reduces to a single leaf the bound recovers known ε-good results for halving-style methods and supplies a new one for Successive Rejects. Complementary lower bounds establish that the hardness structure of max-min identification is distinct from that of ordinary K-armed bandits, yielding the first provable fixed-budget guarantee for this setting.
What carries the argument
The ε-agnostic algorithm driven by the combined hardness measure H₂(ε) that aggregates observable gaps across and inside subtrees.
If this is right
- When every subtree contains only one leaf the method reproduces known ε-good bounds for best-arm identification up to acceleration factors.
- The same analysis supplies a previously unavailable ε-good guarantee for the Successive Rejects procedure in the single-leaf case.
- Max-min identification requires a different hardness characterization than standard K-armed bandits because both inter-subtree and intra-subtree gaps matter.
- The result supplies the first rigorous fixed-budget guarantee for ε-good action selection inside max-min trees.
Where Pith is reading between the lines
- Similar gap-combining hardness measures could be derived for deeper trees if the sequential sampling structure is preserved.
- Planning systems that already use Monte Carlo tree search could adopt the algorithm to avoid separate tuning of the tolerance parameter.
- Empirical tests on game trees of moderate depth would reveal whether the exponential decay rate predicted by H₂(ε) continues to hold beyond depth two.
Load-bearing premise
The analysis assumes exactly depth-2 max-min trees whose leaves are sampled one by one and whose hardness can be expressed directly from the observed value gaps.
What would settle it
On a concrete depth-2 tree, measure whether the observed fraction of trials that return a subtree more than ε away from optimal fails to decay at rate roughly exp(−c T / H₂(ε)) for any constant c.
Figures


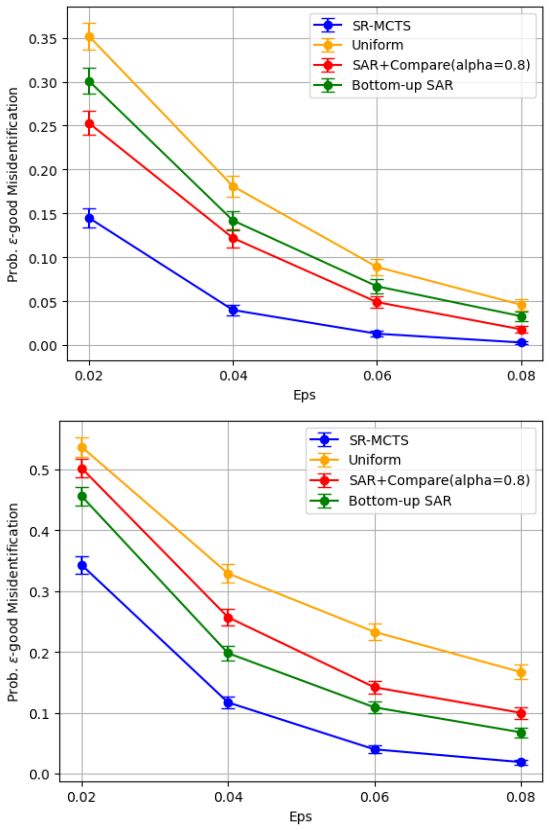




read the original abstract
We study the fixed-budget max-min action identification problem in depth-2 max-min trees, an important special case of Monte Carlo Tree Search. A learner sequentially allocates $T$ samples to leaves and then recommends a subtree whose minimum leaf value is largest. Motivated by approximate planning, we focus on $\varepsilon$-good subtree identification, where any subtree whose min value is within $\varepsilon$ of the optimal maximin value is acceptable. Our main contribution is an $\varepsilon$-agnostic algorithm: it does not require $\varepsilon$ as input, but achieves instance-dependent error bounds for every meaningful $\varepsilon$. We show that the misidentification probability decays as $\exp(-\widetilde{\Theta}(T/H_2(\varepsilon)))$, where $H_2(\varepsilon)$ captures both cross-subtree and within-subtree gaps. When each subtree has a single leaf, the problem reduces to standard fixed-budget best-arm identification, and our analysis recovers, up to accelerating factors, known $\varepsilon$-good guarantees for halving-style methods while giving a new $\varepsilon$-good guarantee for Successive Rejects. On the lower-bound side, we provide complementary positive and negative results showing that max-min identification has a different hardness structure from standard $K$-armed bandits. To our knowledge, this is the first provable fixed-budget algorithmic guarantee for max-min action identification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies fixed-budget ε-good action identification in depth-2 max-min trees, a special case of Monte Carlo Tree Search. It presents an ε-agnostic algorithm that does not take ε as input yet achieves instance-dependent misidentification probability bounds decaying as exp(−Θ̃(T/H₂(ε))) for every meaningful ε, where H₂(ε) incorporates both cross-subtree and within-subtree gaps. When each subtree reduces to a single leaf, the analysis recovers (up to log factors) known ε-good guarantees for halving-style methods and supplies a new guarantee for Successive Rejects. Complementary lower bounds establish that the hardness structure differs from that of standard K-armed bandits, and the work claims to be the first with provable fixed-budget guarantees for this max-min setting.
Significance. If the central claims hold, the result supplies the first rigorous fixed-budget guarantees for ε-good max-min identification in tree search, with the desirable property that a single algorithm works for all ε without prior knowledge of the target accuracy. The recovery of known halving-style bounds and the new Successive Rejects guarantee in the single-leaf reduction, together with the explicit separation from K-armed bandit hardness, are technically useful for approximate planning and could guide the design of practical MCTS variants.
minor comments (3)
- [Introduction / Main Theorem] The definition of H₂(ε) and its explicit dependence on observable gaps should be stated in the introduction or the statement of the main theorem (rather than deferred to the analysis section) to make the instance-dependent rate immediately interpretable.
- [Abstract] The abstract and introduction refer to “accelerating factors” when recovering halving guarantees; a brief sentence clarifying whether these are logarithmic or constant would improve readability.
- [Model section] Notation for the depth-2 max-min tree (subtree roots, leaf values, sequential sampling) is introduced gradually; a single diagram or table summarizing the model parameters would aid readers unfamiliar with the MCTS reduction.
Simulated Author's Rebuttal
We thank the referee for the positive review, the recognition of the novelty of our ε-agnostic fixed-budget algorithm for depth-2 max-min trees, and the recommendation for minor revision. We are pleased that the referee highlights the recovery of known halving bounds, the new Successive Rejects guarantee, and the separation from K-armed bandit hardness.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives its ε-agnostic misidentification bounds exp(−Θ̃(T/H₂(ε))) directly from standard concentration inequalities applied to gap quantities H₂(ε) that are explicitly constructed from the observable leaf values in the depth-2 max-min instance. The central algorithm is shown to achieve these bounds without requiring ε as input, and the single-leaf reduction recovers known halving and Successive Rejects guarantees for best-arm identification without re-deriving or fitting them. Complementary lower bounds establishing a distinct hardness structure are obtained via direct information-theoretic arguments scoped to the model, with no load-bearing self-citation, no fitted parameters renamed as predictions, and no ansatz or uniqueness theorem imported from prior author work. The derivation remains self-contained and externally verifiable against standard bandit analyses.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard sub-Gaussian or bounded concentration inequalities for sample averages
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclearOur main contribution is an ε-agnostic algorithm... misidentification probability decays as exp(−Θ̃(T/H₂(ε))), where H₂(ε) captures both cross-subtree and within-subtree gaps.
Reference graph
Works this paper leans on
-
[1]
J.-Y . Audibert, S. Bubeck, and R. Munos. Best Arm Identification in Multi-Armed Bandits. In Proceedings of the Conference on Learning Theory (COLT), 2010
work page 2010
-
[2]
C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012
work page 2012
- [3]
- [4]
-
[5]
A. Carpentier and A. Locatelli. Tight (lower) bounds for the fixed budget best arm identification bandit problem. InConference on Learning Theory, pages 590–604. PMLR, 2016
work page 2016
- [6]
-
[7]
R. Coulom. Efficient selectivity and backup operators in monte-carlo tree search. InInterna- tional conference on computers and games, pages 72–83. Springer, 2006
work page 2006
-
[8]
R. Degenne. On the existence of a complexity in fixed budget bandit identification. InThe Thirty Sixth Annual Conference on Learning Theory, pages 1131–1154. PMLR, 2023
work page 2023
-
[9]
R. Degenne and W. M. Koolen. Pure exploration with multiple correct answers.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[10]
E. Even-Dar, S. Mannor, and Y . Mansour. Action Elimination and Stopping Conditions for the Multi-Armed Bandit and Reinforcement Learning Problems.Journal of Machine Learning Research, 7:1079–1105, 2006
work page 2006
-
[11]
V . Gabillon, M. Ghavamzadeh, A. Lazaric, and S. Bubeck. Multi-bandit best arm identification. Advances in Neural Information Processing Systems, 24, 2011
work page 2011
-
[12]
A. Garivier, E. Kaufmann, and W. M. Koolen. Maximin action identification: A new bandit framework for games. InConference on Learning Theory, pages 1028–1050. PMLR, 2016
work page 2016
- [13]
- [14]
-
[15]
J. Katz-Samuels and K. Jamieson. The true sample complexity of identifying good arms. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pages 1781–1791, 2020
work page 2020
-
[16]
E. Kaufmann and W. M. Koolen. Monte-carlo tree search by best arm identification. InAdvances in Neural Information Processing Systems (NeurIPS), pages 4897–4906, 2017
work page 2017
-
[17]
E. Kaufmann and W. M. Koolen. Mixture martingales revisited with applications to sequential tests and confidence intervals.Journal of Machine Learning Research, 22(246):1–44, 2021
work page 2021
-
[18]
E. Kaufmann, O. Cappé, and A. Garivier. On the complexity of best-arm identification in multi-armed bandit models.The Journal of Machine Learning Research, 17(1):1–42, 2016
work page 2016
-
[19]
D. E. Knuth and R. W. Moore. An analysis of alpha-beta pruning.Artificial intelligence, 6(4): 293–326, 1975. 11
work page 1975
-
[20]
L. Kocsis and C. Szepesvári. Bandit based monte-carlo planning. InEuropean conference on machine learning, pages 282–293. Springer, 2006
work page 2006
-
[21]
J. Komiyama, T. Tsuchiya, and J. Honda. Minimax optimal algorithms for fixed-budget best arm identification.Advances in Neural Information Processing Systems, 35:10393–10404, 2022
work page 2022
-
[22]
M. Lanctot, A. Saffidine, J. Veness, C. Archibald, and M. H. Winands. Monte carlo*-minimax search.arXiv preprint arXiv:1304.6057, 2013
-
[23]
M. Lanctot, M. H. Winands, T. Pepels, and N. R. Sturtevant. Monte carlo tree search with heuris- tic evaluations using implicit minimax backups. In2014 IEEE Conference on Computational Intelligence and Games, pages 1–8. IEEE, 2014
work page 2014
-
[24]
T. Lattimore and C. Szepesv \’ari. Bandit Algorithms. 2018. URL http://downloads. tor-lattimore.com/book.pdf
work page 2018
-
[25]
R. Munos. From bandits to monte-carlo tree search: The optimistic principle applied to optimization and planning.Foundations and Trends® in Finance, 7(1):1–129, 2014
work page 2014
- [26]
-
[27]
K. Teraoka, K. Hatano, and E. Takimoto. Efficient sampling method for monte carlo tree search problem.IEICE TRANSACTIONS on Information and Systems, 97(3):392–398, 2014
work page 2014
-
[28]
Y . Zhao, C. Stephens, C. Szepesvári, and K.-S. Jun. Revisiting simple regret: Fast rates for returning a good arm. InInternational Conference on Machine Learning, pages 42110–42158. PMLR, 2023. 12 Appendix Table of Contents A Related Work 13 B Proof of Theorem 2 16 B.1 Warmup: Analysis of phase 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16...
work page 2023
-
[29]
give an ε-good analysis of Sequential Halving that holds for every ε although ε is not an input to the algorithm. In the fixed-confidence setting, Degenne and Koolen [9] study pure exploration with multiple correct answers and show that extending Track-and-Stop-style methods to this setting requires care because the answer map can be discontinuous. Our pr...
-
[30]
If ∆(KL) is given by µ1,L −µ 2,1. In this case the condition that |ˆµ−µ|< ∆(KL) 8 for all leaves ensures thatˆµ1,L −ˆµx,1 > 3 4∆(KL) ,∀x̸= 1. If 1 is not the empirically best subtree, then there ∃x̸= 1 such that x is the empirically best subtree, ˆ∆1,L = max(ˆµ1,L−ˆµ1,ˆ1(1),ˆµˆa,ˆ1(ˆa)−ˆµ1,ˆ1(1))≥ˆµ1,L−ˆµ1,ˆ1(1) ≥ˆµ1,L−ˆµx,ˆ1(x) ≥ˆµ1,L−ˆµx,1 > 3 4∆(KL) If...
-
[31]
If ∆(KL) is given by µ1,1 −µ K,1. In this case the condition that |ˆµ−µ|< ∆(KL) 8 for all leaves ensures that ˆµ1,j −ˆµK,1 > 3 4∆(KL) ,∀j∈[L] . Hence, K is not the empirically best subtree, and ˆ∆K,1 = max(ˆµK,1 −ˆµK,ˆ1(K) ,ˆµˆa,ˆ1(ˆa)−ˆµK,ˆ1(K)) ≥ˆµˆa,ˆ1(ˆa)−ˆµK,ˆ1(K) ≥ˆµ1,ˆ1(1) −ˆµK,ˆ1(K) ≥ˆµ1,ˆ1(1) −ˆµK,1 > 3 4∆(KL) Lemma 9.At phase 1, if all leaves sa...
-
[32]
If ˆ∆y,1 is given byˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y), (a) If there exists a leaf(y, j)such thatˆµ y,j >ˆµˆa,ˆ1(ˆa), then ˆ∆y,j = max(ˆµy,j −ˆµy,ˆ1(y),ˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y)) = ˆµy,j −ˆµy,ˆ1(y) >ˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y) = ˆ∆y,1 hence(y,1)will not be eliminated by the single-leaf elimination rule. (b) If all leaves(y, j)’s are such thatˆµy,j ≤ˆµˆa,ˆ1(ˆa), then∀j, ˆ∆y,j = ...
-
[33]
If ˆ∆y,1 is given byˆµy,1 −ˆµy,ˆ1(y), then ˆµy,1 −ˆµy,ˆ1(y) = ˆµy,1 −µ y,1 +µ y,1 −µ y,ˆ1(y) +µ y,ˆ1(y) −ˆµy,ˆ1(y) < ∆(KL) 4 By Lemma 8, ˆ∆max > 3 4∆(KL), hence ˆ∆y,1 < ˆ∆max, and (y,1) will not be eliminated by the single-leaf elimination rule
-
[34]
Ifyis the empirically best subtree and ˆ∆y,1 is given byˆµy,1 −ˆµˆb,ˆ1(ˆb), then ˆµy,1 −ˆµˆb,ˆ1(ˆb) ≤ˆµy,1 −ˆµ1,ˆ1(1) = ˆµy,1 −µ y,1 +µ y,1 −µ 1,ˆ1(1) +µ 1,ˆ1(1) −ˆµ1,ˆ1(1) < ∆(KL) 4 where the first inequality is because y is the empirically best subtree, and hence ˆµˆb,ˆ1(ˆb) ≥ ˆµ1,ˆ1(1). By Lemma 8, ˆ∆max > 3 4∆(KL), hence ˆ∆y,1 < ˆ∆max, and (y,1) will ...
-
[35]
Since|ˆµ−µ|< ∆(KL) 8 for all leaves, we have that ˆµx,L −ˆµx,1 > 3 4∆(KL)
If∆ (KL) is given byµ x,L −µ x,1 for somex̸= 1. Since|ˆµ−µ|< ∆(KL) 8 for all leaves, we have that ˆµx,L −ˆµx,1 > 3 4∆(KL). If it were the case that the subtree x is the empirically best subtree, and subtree 1 gets eliminated, then ˆ∆x,L ≤ ˆ∆1,1. However, ˆ∆x,L = ˆµx,L−ˆµˆb,ˆ1(ˆb) ≥ˆµx,L−ˆµx,ˆ1(x) ≥ˆµx,L−ˆµx,1 > 3 4∆(KL), but ˆ∆1,1 = ˆµx,ˆ1(x)−ˆµ1,1 ≤ˆµx,1...
-
[36]
If∆ (KL) is given byµ 1,L −µ 2,1. In this case the condition that |ˆµ−µ|< ∆(KL) 8 for all leaves ensures that ˆµ1,L −ˆµx,1 > 3 4∆(KL) ,∀x̸=a . If subtree 1 were eliminated, then there ∃x̸= 1 such that x is the empirically best subtree andˆµx,1 ≥ˆµx,ˆ1(x) ≥ˆµ1,L, which leads to a contradiction
-
[37]
If∆ (KL) is given byµ 1,1 −µ K,1. In this case the condition that |ˆµ−µ|< ∆(KL) 8 for all leaves ensures that ˆµ1,j −ˆµK,1 > 3 4∆(KL) ,∀j∈[K] . If subtree 1 were eliminated, then there ∃x̸= 1 such that x is the empirically best subtree and ∀j, ˆ∆1,j = ˆµx,ˆ1(x) −ˆµ1,j = ˆµx,ˆ1(x) −µ x,ˆ1(x) +µ x,ˆ1(x) − µ1,j +µ 1,j −ˆµ1,j ≤ 1 4∆(KL), which leads to a cont...
-
[38]
Subtree 1 remains to be the optimal subtree inν (k)
-
[39]
The min leaf (which defines the sub-optimality of the subtree) is surviving, if the subtree is still active. These are the key structures of a tree that our algorithm maintains with high probability with ε- soundness, so that the residual instance ν(k) does not become “confusing” in terms of the max-min subtree compared to the original tree instance. Lemm...
-
[40]
Proof.The first statement follows directly from items 1 and 3 in Definition 6
For anyi≥2, j∈[L], if(i, j)∈ A (k), then(i,1)∈ A (k). Proof.The first statement follows directly from items 1 and 3 in Definition 6. The second statement follows directly from item 3 in Definition 6. Lemma 13.Let k≤KL−m . Suppose after k−1 phases, the algorithm has not terminated, and phasekisε-sound. Then, for each(i, j)∈ A (k), ∆(k) i,j ≥∆ i,j Proof.Fix...
-
[41]
If∆ (k) max is given byµ x,hx −µ x,1 for somex̸=a. Ifxis not the empirically best subtree, ˆ∆x,hx = max(ˆµx,hx −ˆµx,ˆ1(x),ˆµˆa,ˆ1(ˆa)−ˆµx,ˆ1(x))≥ˆµx,hx −ˆµx,ˆ1(x) ≥ˆµx,hx −ˆµx,1 > 3 4∆(k) max Ifxis the empirically best subtree, ˆ∆x,hx = ˆµx,hx −ˆµˆb,ˆ1(ˆb) ≥ˆµx,hx −ˆµx,ˆ1(x) ≥ˆµx,hx −ˆµx,1 > 3 4∆(k) max Hence ˆ∆max ≥ ˆ∆x,L > 3 4∆(k) max
-
[42]
If ∆(k) max is given by µa,ha −µ b,1. In this case the condition that |ˆµ−µ|< ∆(k) max 8 for all leaves ensures thatˆµa,ha −ˆµx,1 > 3 4∆(k) max,∀x̸=a. If a is not the empirically best subtree, then there ∃x̸=a such that x is the empirically best subtree, ˆ∆a,ha = max(ˆµa,ha −ˆµa,ˆ1(a),ˆµˆa,ˆ1(ˆa)−ˆµa,ˆ1(a))≥ˆµa,ha −ˆµa,ˆ1(a) ≥ˆµa,ha −ˆµx,ˆ1(x) ≥ˆµa,ha −ˆµ...
-
[43]
If ∆(k) max is given by µa,1 −µ z,1. In this case the condition that |ˆµ−µ|< ∆(k) max 8 for all leaves ensures that ˆµa,j −ˆµz,1 > 3 4∆(k) max,∀j such that (a, j)∈ A (k). Hence, z is not the empirically best subtree, and ˆ∆z,1 = max(ˆµz,1 −ˆµz,ˆ1(z),ˆµˆa,ˆ1(ˆa)−ˆµz,ˆ1(z))≥ˆµˆa,ˆ1(ˆa)−ˆµz,ˆ1(z) ≥ˆµa,ˆ1(a) −ˆµz,ˆ1(z) ≥ˆµa,ˆ1(a) −ˆµz,1 > 3 4∆(k) max Therefor...
-
[44]
If ˆ∆y,1 is given byˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y), (a) If there exists a leaf(y, j)such thatˆµ y,j >ˆµˆa,ˆ1(ˆa), then ˆ∆y,j = max(ˆµy,j −ˆµy,ˆ1(y),ˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y)) = ˆµy,j −ˆµy,ˆ1(y) >ˆµˆa,ˆ1(ˆa)−ˆµy,ˆ1(y) = ˆ∆y,1 hence(y,1)will not be eliminated by the single-leaf elimination rule. (b) If all leaves(y, j)’s are such thatˆµy,j ≤ˆµˆa,ˆ1(ˆa), then∀j, ˆ∆y,j = ...
-
[45]
If ˆ∆y,1 is given byˆµy,1 −ˆµy,ˆ1(y), then ˆµy,1 −ˆµy,ˆ1(y) = ˆµy,1 −µ y,1 +µ y,1 −µ y,ˆ1(y) +µ y,ˆ1(y) −ˆµy,ˆ1(y) < ∆(k) max 4 By Lemma 15, ˆ∆max > 3 4∆(k) max, hence ˆ∆y,1 < ˆ∆max, and (y,1) will not be eliminated by the single-leaf elimination rule
-
[46]
Ifyis the empirically best subtree and ˆ∆y,1 is given byˆµy,1 −ˆµˆb,ˆ1(ˆb), then ˆµy,1 −ˆµˆb,ˆ1(ˆb) ≤ˆµy,1 −ˆµa,ˆ1(a) = ˆµy,1 −µ y,1 +µ y,1 −µ a,ˆ1(a) +µ a,ˆ1(a) −ˆµa,ˆ1(a) < ∆(k) max 4 where the first inequality is because y is the empirically best subtree, and hence ˆµˆb,ˆ1(ˆb) ≥ ˆµa,ˆ1(a). By Lemma 15, ˆ∆max > 3 4∆(k) max, hence ˆ∆y,1 < ˆ∆max, and (y,1...
-
[47]
Since |ˆµ−µ|< ∆(k) max 8 for all leaves, we have that ˆµx,hx −ˆµx,1 > 3 4∆(k) max
If∆ (k) max is given byµ x,hx −µ x,1 for somex̸=a. Since |ˆµ−µ|< ∆(k) max 8 for all leaves, we have that ˆµx,hx −ˆµx,1 > 3 4∆(k) max. If it were the case that the subtree x is the empirically best subtree, and subtree a gets eliminated, then, for any (a, j) such that (a, j)∈ A (k) a , ˆ∆x,hx ≤ ˆ∆a,j. However, ˆ∆x,hx = ˆµx,hx −ˆµˆb,ˆ1(ˆb) ≥ ˆµx,hx −ˆµx,ˆ1(...
-
[48]
If∆ (k) max is given byµ a,ha −µ b,1. In this case the condition that |ˆµ−µ|< ∆(k) max 8 for all leaves ensures that ˆµa,ha −ˆµx,1 > 3 4∆(k) max,∀activex̸=a . If subtree a were eliminated, then there ∃activex̸=a such that x is the empirically best subtree andˆµx,1 ≥ˆµx,ˆ1(x) ≥ˆµa,ha, which leads to a contradiction
-
[49]
either all ε/2-good subtrees are nonempty, or all ε-bad subtrees are empty
If∆ (k) max is given byµ a,1 −µ z,1. In this case the condition that |ˆµ−µ|< ∆(k) max 8 for all leaves ensures that ˆµa,j −ˆµz,1 > 3 4∆(k) max,∀j such that (a, j)∈ A (k) a . If subtree a were eliminated, then there∃x̸=a such that x is the empirically best subtree and ∀jsuch that(a, j)∈ A (k) a , ˆ∆a,j = ˆµx,ˆ1(x) −ˆµa,j = ˆµx,ˆ1(x) −µ x,ˆ1(x) +µ x,ˆ1(x) −...
-
[51]
It follows that phase k is sound, completing the induction for k≤KL−m
If phase k−1 is executed, then by Lemma 16, Lemma 17 and Lemma 18, at phase k−1 , the optimal(min) leaf in any suboptimal subtree is not eliminated alone, the optimal subtree does not become empty, and∀s̸= 1 and ε/2-good, (s,1) is not eliminated. It follows that phase k is sound, completing the induction for k≤KL−m. •k > KL−m. –Base case:k=KL−m+ 1
-
[52]
If phase KL−m is not executed, then by the induction on phases k≤KL−m , phase KL−m is sound. Note that if a tree satisfies the soundness condition (Definition 6) for the earlier phasesk≤KL−m , then it also satisfies the soundness condition for the later phases k > KL−m+ 1 . It follows that phase KL−m+ 1 is automatically sound since no operation is done in...
-
[53]
It follows that phaseKL−m+ 1is sound
If phase KL−m is executed, then by Lemma 16, Lemma 17 and Lemma 18, at phase KL−m , the optimal leaf in any suboptimal subtree is not eliminated alone, the optimal subtree does not become empty, and ∀s̸= 1 and ε/2-good, (s,1) is not eliminated. It follows that phaseKL−m+ 1is sound. –Induction case: Assume phasek−1∈[KL−m+ 1, KL−1]is sound
-
[54]
If phase k−1 is not executed, then phase k is automatically sound since no operation is done in phasek−1
-
[55]
either allε/2-good subtrees are nonempty, or allε-bad subtrees are empty
If phase k−1 is executed, then by Lemma 20 and Lemma 21, at phase k−1 , if there exists nonempty ε-bad subtree, then the optimal leaf in any ε-bad subtree is not eliminated alone, and any ε/2-good subtree does not become empty. It follows that phasek+ 1is sound, completing the induction fork > KL−m. Therefore, for any phase k, phase k is sound. Suppose th...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.