Recognition: 2 theorem links
· Lean TheoremChunkFlow: Communication-Aware Chunked Prefetching for Layerwise Offloading in Distributed Diffusion Transformer Inference
Pith reviewed 2026-05-13 01:20 UTC · model grok-4.3
The pith
ChunkFlow makes layerwise offloading for diffusion transformers communication-aware and chunk-granular to hide prefetch latency even under PCIe contention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ChunkFlow treats layerwise offloading as a co-scheduling problem between prefetch and collective communication. A first-order model predicts when prefetch latency can be hidden behind per-layer computation, and the runtime uses chunk granularity plus adaptive yielding to collectives to implement that prediction. On three representative diffusion transformers running with Ulysses sequence parallelism on two H100 GPUs over PCIe, this produces up to 1.28 times faster step times than prior offloading, up to 49 percent lower peak GPU memory than a no-offload baseline at near-identical step time for large workloads, and a tunable memory-latency tradeoff that recovers near-zero overhead in the low-
What carries the argument
ChunkFlow, the communication-aware chunk-granular offloading runtime that adaptively yields prefetch to collective communications according to a first-order analytical latency model.
If this is right
- Up to 1.28x step-time speedup over existing layerwise offloading on two H100 GPUs with Ulysses parallelism.
- Peak GPU memory reduced by up to 49% versus the no-offload baseline while keeping step time nearly identical once the workload is large enough.
- A tunable memory-latency tradeoff that recovers near-zero step-time overhead in the small-workload regime.
- Effective operation on PCIe-only nodes where prefetch and collectives share the same communication path.
Where Pith is reading between the lines
- The same model-guided yielding approach could be applied to other sequence-parallel transformer workloads that offload to host memory.
- Analytical predictions of transfer-compute overlap may help co-schedule memory movement in other heterogeneous memory systems beyond DiT inference.
- Varying chunk sizes dynamically with measured contention could further reduce the residual overhead observed in small-workload cases.
Load-bearing premise
The first-order analytical model accurately predicts when prefetch latency can be hidden by computation even when collectives contend on the same PCIe path, and adaptive yielding adds negligible overhead.
What would settle it
Run the three diffusion transformers on the two-GPU PCIe setup both with and without adaptive yielding enabled, then measure whether observed step-time speedups and memory reductions match the model's predictions across small and large workload regimes.
Figures





read the original abstract
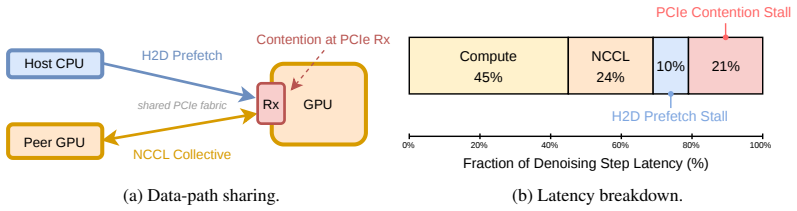
Layerwise offloading reduces the GPU memory footprint of large diffusion transformer (DiT) inference by prefetching upcoming layers from host memory, but its effectiveness hinges on hiding prefetch latency behind per-layer computation. This assumption breaks down when the per-GPU compute workload is small. Moreover, on PCIe-only nodes, prefetch and inter-GPU collective communications such as all-reduce and all-to-all contend on the shared PCIe path, exposing prefetch latency even when compute would otherwise hide it. We revisit layerwise offloading as a co-scheduling problem between prefetch and communication, guided by a first-order analytical model that predicts when prefetch can be hidden by computation. Building on this model, we design ChunkFlow, a communication-aware, chunk-granular offloading runtime that adaptively yields to collective communication and smoothly trades GPU memory for prefetch volume. On three representative diffusion transformers running on two H100 GPUs over PCIe with Ulysses sequence parallelism, ChunkFlow delivers up to 1.28x step-time speedup over SGLang's existing layerwise offloading, reduces peak GPU memory by up to 49% over the no-offload baseline at near-identical step time once the workload is large enough, and exposes a tunable memory-latency tradeoff that recovers near-zero step-time overhead in the small-workload regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ChunkFlow, a communication-aware chunked prefetching runtime for layerwise offloading during distributed diffusion transformer (DiT) inference. It introduces a first-order analytical model to guide co-scheduling of prefetch operations with inter-GPU collectives (all-reduce, all-to-all) under PCIe contention, with adaptive yielding to hide latency. On three representative DiTs using Ulysses sequence parallelism across two H100 GPUs, the system claims up to 1.28x step-time speedup versus SGLang's layerwise offloading, up to 49% peak GPU memory reduction versus no-offload at near-identical step time for large workloads, and a tunable memory-latency tradeoff that approaches zero overhead in small-workload regimes.
Significance. If the first-order model and runtime claims hold under contention, this work provides a practical advance for memory-efficient inference of large generative models in bandwidth-constrained distributed settings. The co-scheduling approach and tunable tradeoff address a real deployment pain point for PCIe-only nodes, and the empirical results on representative DiTs with sequence parallelism demonstrate concrete gains over an existing baseline.
major comments (1)
- [Analytical model and evaluation] The first-order analytical model is load-bearing for the co-scheduling decisions, chunk sizing, and yield points that produce the reported 1.28x speedup and tunable tradeoff. The manuscript does not include a direct side-by-side comparison of the model's predicted prefetch-hiding thresholds versus measured timelines under simultaneous prefetch + collective traffic on the two-H100 PCIe setup (see evaluation section and results figures). Without this validation, it is unclear whether the model underestimates dynamic contention, which would undermine both the speedup numbers and the claim that adaptive yielding adds negligible overhead.
minor comments (2)
- [Abstract] The abstract refers to 'three representative diffusion transformers' without naming them or their sizes; adding the specific model names and parameter counts in the introduction or experimental setup would improve reproducibility.
- [Runtime design] Notation for chunk granularity and the memory-latency tradeoff parameter should be defined more explicitly with an equation or pseudocode early in the runtime description to aid readers following the co-scheduling logic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical relevance of ChunkFlow for memory-efficient DiT inference under PCIe contention. We address the major comment on analytical model validation below.
read point-by-point responses
-
Referee: [Analytical model and evaluation] The first-order analytical model is load-bearing for the co-scheduling decisions, chunk sizing, and yield points that produce the reported 1.28x speedup and tunable tradeoff. The manuscript does not include a direct side-by-side comparison of the model's predicted prefetch-hiding thresholds versus measured timelines under simultaneous prefetch + collective traffic on the two-H100 PCIe setup (see evaluation section and results figures). Without this validation, it is unclear whether the model underestimates dynamic contention, which would undermine both the speedup numbers and the claim that adaptive yielding adds negligible overhead.
Authors: We agree that a direct side-by-side comparison of the first-order model's predicted prefetch-hiding thresholds against measured timelines under concurrent prefetch and collective traffic would strengthen the presentation. The current manuscript demonstrates the model's utility indirectly via end-to-end results: ChunkFlow's chunk sizing and adaptive yielding decisions, derived from the model, produce the reported 1.28x speedup over SGLang and the tunable memory-latency tradeoff on three DiTs with Ulysses sequence parallelism. However, to directly address the concern about potential underestimation of dynamic PCIe contention, we will add a new subsection and figure in the revised evaluation section. This figure will plot the model's predicted hiding thresholds versus empirical timelines collected on the exact two-H100 PCIe setup under simultaneous prefetch + all-reduce/all-to-all traffic, including both small- and large-workload regimes. The added analysis will confirm the model's accuracy for guiding co-scheduling and show that adaptive yielding contributes negligible overhead, thereby supporting the speedup and tradeoff claims. revision: yes
Circularity Check
No significant circularity; first-order model and runtime design remain independent of fitted inputs or self-referential definitions.
full rationale
The abstract and provided excerpts describe a first-order analytical model guiding co-scheduling of prefetch and collectives, followed by implementation of ChunkFlow. No equations or sections are shown that define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on self-citation chains for load-bearing uniqueness claims. The model is presented as predictive rather than tautological, and empirical claims (speedups, memory reductions) are tied to runtime measurements rather than reducing to the model's inputs by construction. This is the expected non-finding for a systems paper whose central contribution is an engineering artifact validated on hardware.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We build an analytical model for two dominant terms... Tcomp(B,S) = Fblock(B,S) / (ηcomp Ppeak) ... Tpref = Bpref / (ηpref BWh2d) ... Fblock(B,S) >= F* ... critical compute workload
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
communication-aware chunked prefetching... adaptively yields to collective communication... chunk-granular partial parameter residency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FLUX.1.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.1.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[2]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. https://openai.com/research/ video-generation-models-as-world-simulators, 2024
work page 2024
-
[3]
Gonzalez, Matei Zaharia, and Ion Stoica
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xiaoxuan Liu, Ying Sheng, Joseph E. Gonzalez, Matei Zaharia, and Ion Stoica. MoE-Lightning: High-throughput MoE inference on memory-constrained GPUs. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025
work page 2025
-
[4]
PixArt- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. PixArt- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[5]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[6]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[8]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[9]
PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
Jiarui Fang et al. PipeFusion: Patch-level pipeline parallelism for diffusion transformers inference.arXiv preprint arXiv:2405.14430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
xdit: an inference engine for diffusion transformers (dits) with massive parallelism,
Jiarui Fang et al. xDiT: an inference engine for diffusion transformers (DiTs) with massive parallelism.arXiv preprint arXiv:2411.01738, 2024
-
[11]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[12]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Demystifying cost- efficiency in llm serving over heterogeneous gpus.ArXiv, abs/2502.00722,
Youhe Jiang, Fangcheng Fu, Xiaozhe Wang, Jiawei Yang, Yang Liu, and Bin Cui. Demystifying cost-efficiency in LLM serving over heterogeneous GPUs.arXiv preprint arXiv:2502.00722, 2025
-
[14]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[15]
Cost-efficient llm serving in the cloud: Vm selection with kv cache offloading, 2025
Kihyun Kim, Jinwoo Kim, Hyunsun Chung, Myung-Hoon Cha, Hong-Yeon Kim, and Youngjae Kim. Cost-efficient llm serving in the cloud: Vm selection with kv cache offloading, 2025
work page 2025
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[18]
ZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates, 2025
Tingfeng Lan, Yusen Wu, Bin Ma, Zhaoyuan Su, Rui Yang, Tekin Bicer, Masahiro Tanaka, Olatunji Ruwase, Dong Li, and Yue Cheng. ZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates, 2025
work page 2025
-
[19]
DistriFusion: Distributed parallel inference for high-resolution diffusion models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming- Yu Liu, Kai Li, and Song Han. DistriFusion: Distributed parallel inference for high-resolution diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[20]
Q-Diffusion: Quantizing diffusion models
Xiuyu Li, Yijiang Liu, Long Lian, Huanrui Yang, Zhen Dong, Daniel Kang, Shanghang Zhang, and Kurt Keutzer. Q-Diffusion: Quantizing diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[21]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[22]
Learning-to-cache: Accelerating diffusion transformer via layer caching
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[23]
DeepCache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. DeepCache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
work page 2023
-
[25]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[26]
ZeRO- Infinity: Breaking the GPU memory wall for extreme scale deep learning
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. ZeRO- Infinity: Breaking the GPU memory wall for extreme scale deep learning. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2021
work page 2021
-
[27]
Jie Ren, Jiaolin Luo, Kai Wu, Minjia Zhang, Hyeran Jeon, and Dong Li. Sentinel: Efficient Tensor Migration and Allocation on Heterogeneous Memory Systems for Deep Learning. In International Symposium on High Performance Computer Architecture (HPCA), 2020
work page 2020
-
[28]
ZeRO-Offload: Democratizing Billion-Scale Model Training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. ZeRO-Offload: Democratizing Billion-Scale Model Training. InUSENIX Annual Technical Conference, 2021
work page 2021
-
[29]
Enabling large dynamic neural network training with learning- based memory management
Jie Ren, Dong Xu, Shuangyan Yang, Jiacheng Zhao, Zhicheng Li, Christian Navasca, Chenxi Wang, Harry Xu, and Dong Li. Enabling large dynamic neural network training with learning- based memory management. InIEEE International Symposium on High Performance Computer Architecture (HPCA), 2024
work page 2024
-
[30]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[31]
FlashAttention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 11
work page 2024
-
[32]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y . Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. FlexGen: High-throughput generative inference of large language models with a single GPU. InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[33]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[34]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[35]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[36]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning (ICML), 2023
work page 2023
-
[37]
The Landscape of GPU-Centric Communication
Didem Unat et al. The landscape of GPU-centric communication.arXiv preprint arXiv:2409.09874, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2017
work page 2017
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express Link
Dong Xu, Yuan Feng, Kwangsik Shin, Daewoo Kim, Hyeran Jeon, and Dong Li. Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express Link. In36th ACM/IEEE International Conference for High Performance Computing, Performance Measurement, Modeling and Tools (SC), 2024
work page 2024
-
[41]
HGCA: Hybrid GPU-CPU attention for long context LLM inference
Dongming Zhang et al. HGCA: Hybrid GPU-CPU attention for long context LLM inference. arXiv preprint arXiv:2507.03153, 2025
-
[42]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 12 A Roofline View of the Overlap Threshold T...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.