Recognition: no theorem link
LLM-X: A Scalable Negotiation-Oriented Exchange for Communication Among Personal LLM Agents
Pith reviewed 2026-05-13 02:44 UTC · model grok-4.3
The pith
LLM-X introduces a scalable exchange where personal LLM agents negotiate and coordinate directly via structured messages and enforced policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
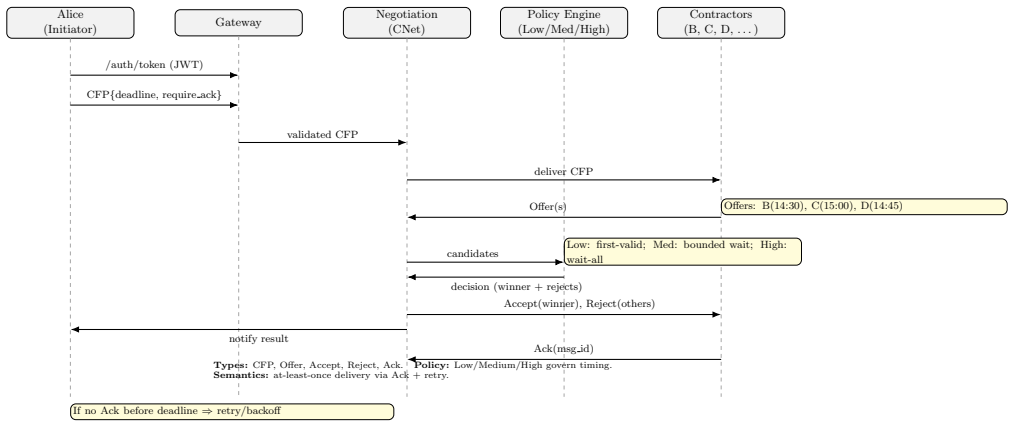
LLM-X is a scalable negotiation-oriented environment that enables direct, structured communication across populations of personal agents (LLMs), each representing an individual user. Unlike existing tool-centric protocols that focus on agent-API interaction, LLM-X introduces a message bus and routing substrate for LLM-to-LLM coordination with guarantees around schema validity and policy enforcement. The architecture comprises federated gateways, topic-based routing, and policy enforcement; it uses a typed message protocol supporting capability negotiation and contract-net-style coordination; and it supplies the first empirical evaluation of LLM-based multi-agent negotiation at scale across 5
What carries the argument
The typed message protocol supporting capability negotiation and contract-net-style coordination, embedded in an architecture of federated gateways, topic-based routing, and policy enforcement.
If this is right
- Stricter policies improve robustness and fairness but raise latencies and message volume.
- The exchange stays stable under sustained load with only bounded latency drift.
- Clear performance trade-offs appear across agent counts and policy levels in both short and long runs.
Where Pith is reading between the lines
- Populations of personal agents could develop coordinated behaviors such as joint resource allocation without central control.
- The protocol could serve as a foundation for open agent marketplaces where contracts are negotiated automatically.
- Testing the same setup with heterogeneous LLM models would reveal how model differences affect adherence rates.
Load-bearing premise
LLMs will reliably adhere to the typed message schemas and negotiation policies without hallucinating or deviating.
What would settle it
A run in which a substantial fraction of agents produce schema-invalid messages or violate policy rules, causing coordination failure or unbounded latency growth.
Figures






read the original abstract
We propose a personal-LLM exchange (LLM-X), a scalable negotiation-oriented environment that enables direct, structured communication across populations of personal agents (LLMs), each representing an individual user. Unlike existing tool-centric protocols that focus on agent-API interaction, LLM-X introduces a message bus and routing substrate for LLM-to-LLM coordination with guarantees around schema validity and policy enforcement. We contribute: (1) an architecture for LLM-X comprising federated gateways, topic-based routing, and policy enforcement; (2) a typed message protocol supporting capability negotiation and contract-net-style coordination; and (3) the first empirical evaluation of LLM-based multi-agent negotiation at scale. Experiments span 5, 9, and 12 agents, under distinct negotiation policies (Low, Medium, High), and across both short-run (minutes) and long-run (2h, 12h) load conditions. Results highlight clear policy-performance trade-offs: stricter policies improve robustness and fairness but increase latencies and message volume. Extended runs confirm that LLM-X remains stable under sustained load, with bounded latency drift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM-X, a scalable negotiation-oriented exchange for direct structured communication among populations of personal LLM agents. It contributes an architecture with federated gateways, topic-based routing, and policy enforcement; a typed message protocol supporting capability negotiation and contract-net-style coordination; and the first empirical evaluation of LLM-based multi-agent negotiation at scale, with experiments using 5/9/12 agents under Low/Medium/High policies in short and long runs (up to 12h) that report policy-performance trade-offs and stability under load.
Significance. If the empirical results hold with verifiable enforcement, this could provide a useful substrate for coordinated multi-agent LLM systems beyond tool-centric protocols, with the scale of the evaluation (multiple agent counts and sustained runs) representing a practical step forward in demonstrating negotiation stability and policy effects.
major comments (2)
- Abstract and evaluation description: the central claim of 'guarantees around schema validity and policy enforcement' through the typed protocol and gateways rests on LLM adherence to schemas, yet no quantitative metrics are reported on message validity rates, rejection frequencies at the enforcement layer, or deviation incidents across the 5/9/12-agent experiments or policy variants. This directly undermines assessment of whether observed robustness reflects enforcement or prompt compliance.
- Experiments/results: while trade-offs (stricter policies improve robustness/fairness but increase latency/volume) and long-run stability (bounded latency drift) are asserted, the description provides no specific quantitative results, error bars, statistical details, or methodology for measuring adherence, making it difficult to evaluate the strength of the 'first empirical evaluation at scale' claim.
minor comments (1)
- The abstract would benefit from a brief statement of the specific quantitative outcomes (e.g., latency values or validity percentages) rather than qualitative highlights only.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We agree that additional quantitative details on enforcement metrics and experimental results would strengthen the manuscript and address the concerns raised. We outline our responses to each major comment below and the revisions we will make.
read point-by-point responses
-
Referee: Abstract and evaluation description: the central claim of 'guarantees around schema validity and policy enforcement' through the typed protocol and gateways rests on LLM adherence to schemas, yet no quantitative metrics are reported on message validity rates, rejection frequencies at the enforcement layer, or deviation incidents across the 5/9/12-agent experiments or policy variants. This directly undermines assessment of whether observed robustness reflects enforcement or prompt compliance.
Authors: We acknowledge this is a valid observation. The manuscript emphasizes the architectural mechanisms for schema validation and policy enforcement via gateways and typed protocols, but does not report granular quantitative metrics such as validity rates or rejection frequencies. In the revised version, we will add a dedicated subsection with these metrics (e.g., percentage of valid messages, rejection counts per policy level, and deviation incidents) across all agent counts and policy variants to allow clearer assessment of enforcement effectiveness versus prompt compliance. revision: yes
-
Referee: Experiments/results: while trade-offs (stricter policies improve robustness/fairness but increase latency/volume) and long-run stability (bounded latency drift) are asserted, the description provides no specific quantitative results, error bars, statistical details, or methodology for measuring adherence, making it difficult to evaluate the strength of the 'first empirical evaluation at scale' claim.
Authors: We agree that the results presentation would benefit from greater specificity. The current manuscript summarizes observed trade-offs and stability from the 5/9/12-agent experiments under Low/Medium/High policies in short and long runs. In the revision, we will expand the evaluation section to include specific quantitative values (e.g., mean latencies, message volumes, fairness/robustness scores), error bars or variance measures, statistical details, and explicit methodology for measuring adherence and stability, thereby strengthening the empirical claims. revision: yes
Circularity Check
No circularity: architecture proposal and empirical evaluation are self-contained
full rationale
The paper proposes an LLM-X architecture with federated gateways, topic-based routing, policy enforcement, and a typed message protocol for negotiation, then reports direct empirical results from experiments varying agent counts (5/9/12), policies (Low/Medium/High), and run durations. No mathematical derivations, predictions from fitted parameters, or load-bearing self-citations appear in the claims. The evaluation consists of observed stability, latency, and trade-offs under load, which do not reduce to the inputs by construction. The noted assumption about LLM schema adherence is a correctness risk rather than a circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Personal LLMs can be made to adhere to typed message protocols and negotiation policies through prompting.
invented entities (1)
-
LLM-X exchange with federated gateways and topic-based routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuntao Bai et al . 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Maciej Besta et al. 2024. Graph of thoughts: solving elaborate problems with large language models. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI’24, Vol. 38). AAAI Press, 17682–17690. doi:10.1609/aaai.v38i16.29720
-
[3]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. arXiv:2308.07201 [cs.CL] https://arxiv. org/abs/2308.07201
work page internal anchor Pith review arXiv 2023
-
[4]
Hyung Won Chung et al. 2024. Scaling Instruction-Finetuned Language Models. Journal of Machine Learning Research25, 70 (2024), 1–53. http://jmlr.org/papers/ v25/23-0870.html
work page 2024
-
[5]
Yilun Du, Le Hou, Yale Song, et al. 2024. Improving Factuality and Reasoning in Language Models through Multiagent Debate. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 11733–11763. https://proceedings.mlr.press/v235/ du24e.html
work page 2024
-
[6]
Significant Gravitas. 2023. AutoGPT. GitHub repository. https://github.com/ Torantulino/Auto-GPT
work page 2023
- [7]
-
[8]
Sirui Hong et al . 2024. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. InThe Twelfth International Conference on Learning Representations (ICLR). 1–26. https://openreview.net
work page 2024
-
[9]
Or Honovich et al. 2023. Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Toronto, Canada, 14409–14428. https://aclanthology. org
work page 2023
-
[10]
Wenlong Huang et al. 2022. Inner Monologue: Embodied Reasoning through Planning with Language Models. InConference on Robot Learning (CoRL) (Proceedings of Machine Learning Research, Vol. 205). PMLR, 1769–1782. https: //proceedings.mlr.press/v205/huang23c.html
work page 2022
-
[11]
Gautier Izacard et al. 2023. Atlas: Few-shot Learning with Retrieval Augmented Language Models.Journal of Machine Learning Research24, 251 (2023), 1–43. http://jmlr.org/papers/v24/23-0037.html
work page 2023
-
[12]
Ziqi Jin and Wei Lu. 2023. Tab-CoT: Zero-shot Tabular Chain of Thought. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 10259–10277. doi:10.18653/v1/ 2023.findings-acl.651
-
[13]
Tianjian Li, Xiao Wang, et al. 2023. CAMEL: communicative agents for "mind" exploration of large language model society(NIPS ’23). Article 2264, 18 pages
work page 2023
- [14]
-
[15]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA, 17...
-
[16]
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Prithviraj Ammanabrolu, Yejin Choi, and Xiang Ren
-
[17]
Swift- sage: A generative agent with fast and slow think- ing for complex interactive tasks
SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks. arXiv:2305.17390 [cs.CL] https://arxiv.org/abs/2305.17390
-
[18]
Xiao Liu et al. 2024. AgentBench: Evaluating LLMs as Agents. InThe Twelfth International Conference on Learning Representations (ICLR). 1–43. https: //openreview.net/forum?id=zAdUB0aCTQ
work page 2024
- [19]
-
[20]
Yohei Nakajima. 2023. BabyAGI. GitHub repository. https://github.com/ yoheinakajima/babyagi
work page 2023
-
[21]
Anton Osika. 2023. GPT Engineer. GitHub repository. https://github.com/ AntonOsika/gpt-engineer
work page 2023
-
[22]
Long Ouyang et al. 2022. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, Vol. 35. 27730–27744. https://proceedings.neurips.cc
work page 2022
-
[23]
Joon Sung Park et al. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. ACM, 1–22. doi:10.1145/3586183.3606763
-
[24]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction Tuning with GPT-4. arXiv:2304.03277 [cs.CL] https://arxiv.org/abs/ 2304.03277
work page internal anchor Pith review arXiv 2023
-
[25]
Rafael Rafailov et al. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neural Information Processing Systems, Vol. 36. 53728–53741. https://proceedings.neurips.cc
work page 2023
- [26]
-
[27]
Noah Shinn, Paul Labash, and Ameet Gopinath. 2023. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Rohan Taori et al. 2023. Stanford Alpaca: Instruction-following LLaMA model. arXiv preprint arXiv:2303.16199(2023)
work page Pith review arXiv 2023
-
[29]
Ruoyao Wang et al. 2022. ScienceWorld: Is Your Agent Smarter than a Fifth Grader?. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 11279– 11298. https://aclanthology.org
work page 2022
- [30]
-
[31]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv:2212.10560 [cs.CL] https: //arxiv.org/abs/2212.10560
work page internal anchor Pith review arXiv 2023
-
[32]
Jason Wei, Xuezhi Wang, Dale Schuurmans, et al . 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models.NeurIPS(2022), 24824– 24837
work page 2022
-
[33]
Qingyun Wu et al. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. InProceedings of the First Conference on Language Modeling (COLM). 1–15. 7
work page 2024
-
[34]
Shuyan Wu et al. 2023. Chatarena: Multi-Agent Language Game Environments for LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, 441–451. https://aclanthology.org
work page 2023
- [35]
-
[36]
Shunyu Yao et al. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations (ICLR). 1–33
work page 2023
-
[37]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Zhao, et al. 2023. Tree of Thoughts: Deliberate problem solving with large language models.arXiv preprint arXiv:2305.10601(2023). A Message Schemas (Sketches) At the core of LLM-X is a schema-validated envelope that ensures interoperability and safety across agents. Each message includes metadata (IDs, sender/recipient, timestamps) and a ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.